

在我们日常的开发中,会经常与数据库打交道。对于 java 开发者来说,经常会使用jdbc来与数据库进行交互。我们可能会看到这样的代码:
try(
Connection conn = ...;
PreparedStatement stmt = conn.prepareStatement(sql);
){
...
catch(SQLException se){
se.printStackTrace();
}catch(Exception e){
e.printStackTrace();
}
对于生产环境来说,我们常常会使用连接池技术来提高性能。那么为什么连接池可以提高性能呢?
为何需要连接池?
首先我们来看看数据库连接池在一个常见的分布式架构系统中的位置。
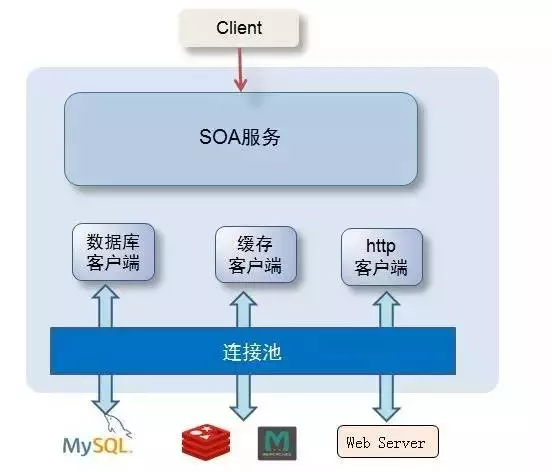
从图上可以看出,连接池位于程序与数据库之间,起着数据库沟通的桥梁关键作用。
我们通常使用数据库的流程为:

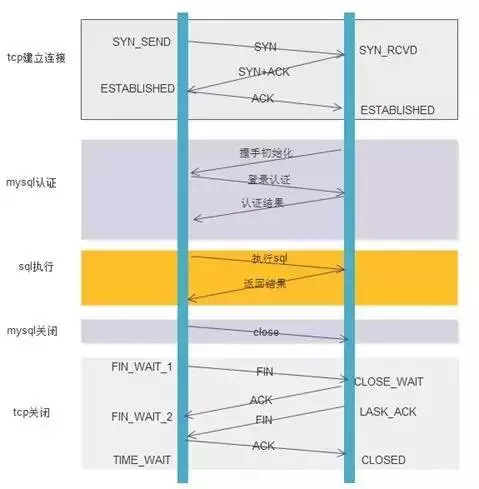
- 第一步:数据库tcp连接(3次握手)
- 第二步:mysql权限认证
- 第三步:执行sql,获得结果
- 第四步:关闭mysql
- 第五步:数据库tcp关闭(4次挥手)
可以看到,一个sql操作需要进行这么多的网络交互操作,如果我们能够减少其中的一些步骤的话那么将可以大大提升我们的程序性能。那么我们使用了连接池后的情况是怎么样的呢?
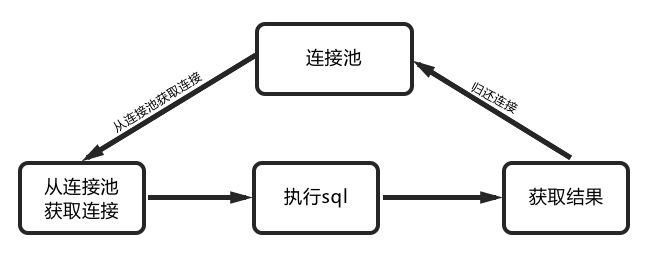
因此,我们可以得到结论:数据库连接池技术本质上为网络资源的复用。
数据库连接池与线程池的比较
在工作中,大家经常也会使用线程池技术来提升程序的性能,那么线程池与连接池它们又有何异同呢?
从本质上讲,线程池与连接池并无太大的区别,它们都是一种资源复用的技术,都需要对使用的资源进行管理,比如最大、最小连接数 ...
它们唯一的区别在于管理的资源对象不同:
- 线程池管理的是线程资源,本质上来讲是cpu、内存等资源的复用
- 连接池管理的是网络资源,本质上为网络资源的复用
常见连接池
现在的连接池已经有很多种选择,从开始的c3p0,dbcp,到Druid、HikariCP,连接池技术越来越丰富,我们可能会好奇不就是一个连接池吗,为什么还要有这么多的连接池方案? wenshao(Druid作者,编者注)又是如何看待Druid、HikariCP的?
其实连接池技术与互联网发展密不可分,连接池的发展就是互联网发展的一个缩影。从这中的历程我们可以感受到近15年来蓬勃发展的互联网。
- 为何 Druid、HikariCP 会比 c3p0 快?
- c3p0 在某些条件下为何会存在 Deadlock 问题?
- HikariCP 为何又号称最快的连接池,它是如何做到的?
- Druid又为什么号称最好的java线程池?
只有深入这些连接池的源码,看看它们的具体模型与架构方案,我们才能一一解答上述疑问,从中感受到这些作者的架构思想,并将这些思想与架构融入我们的日常的思维与开发中,提升我们的代码质量及内力。在使用遇到问题的时候我们也可以从中发现问题根源、从而进行解决。
求知若渴,虚心若愚。
在网络上已经可以看到很多分析Druid、HikariCP 的源码的文章,很多文章写的很好,如果想要详细了解的话可以参考如下文章:
受限于本文的篇幅,对于线程池最核心的部分莫过于获取连接的过程,在这里我主要大致分析两款数据库连接池 Druid 与 HikariCP 的核心逻辑。
Druid 连接池分析
Druid基于java原生提供的相关内容进行的开发,Druid 在获取连接的时候使用了ReentrantLock 来对线程池扩容过程进行加锁,Druid 线程池使用了两个线程来管理整个过程,分别为创建线程和销毁线程,创建线程负责连接扩容、销毁线程负责收缩销毁,具体获取连接过程如下:
- 1、检查池中是否有可用连接
- 2、如若池中有可用连接,则直接返回连接
- 3、若池中没有可用连接,则发送emty信号唤醒创建线程,等待创建线程发送notEmpty信号,创建完成后取出线程池中最后的连接并返回
如下为初始化过程:
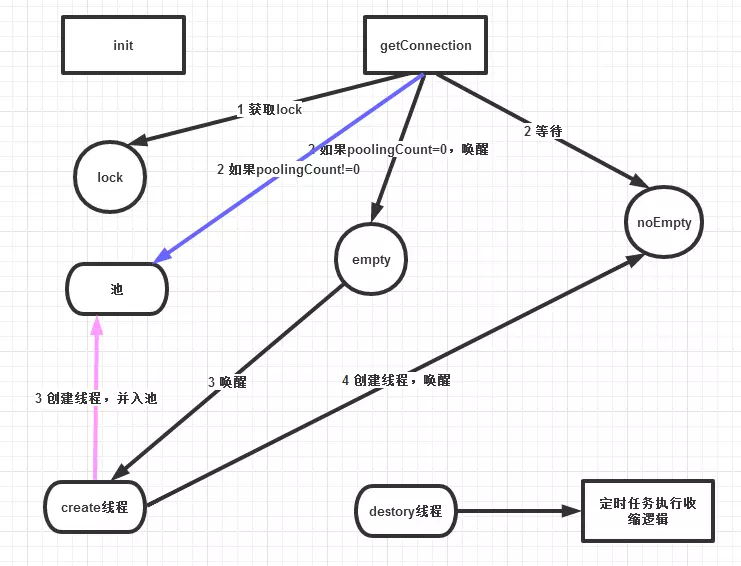
关键获取线程池代码如下:
DruidConnectionHolder takeLast() throws InterruptedException, SQLException {
try {
while (poolingCount == 0) {
emptySignal(); // send signal to CreateThread create connection
notEmptyWaitThreadCount++;
if (notEmptyWaitThreadCount > notEmptyWaitThreadPeak) {
notEmptyWaitThreadPeak = notEmptyWaitThreadCount;
}
try {
notEmpty.await(); // signal by recycle or creator
} finally {
notEmptyWaitThreadCount--;
}
notEmptyWaitCount++;
if (!enable) {
connectErrorCount.incrementAndGet();
throw new DataSourceDisableException();
}
}
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to non-interrupted thread
notEmptySignalCount++;
throw ie;
}
decrementPoolingCount();
DruidConnectionHolder last = connections[poolingCount];
connections[poolingCount] = null;
return last;
}
HikariCP 分析
HikariCP 也是基于java进行开发,但进行了很多细节方面的优化,比如ConcurrentBag无锁化来减轻创建锁开销,自定义FastList进一步精简代码降低jdk自实现的CopyOnWriteArrayList开销,使用 Javassist 委托实现动态代理在字节码层面进行优化等等。在这里我们来看一下 ConcurrentBag 是如何做到无锁化的?
ConcurrentBag 内部同时使用了 ThreadLocal 和 CopyOnWriteArrayList 来存储元素:
- 1、尝试从 ThreadLocal中获取属于当前线程的元素来避免锁竞争
- 2、如果没有可用元素则扫描公共集合、再次从共享的 CopyOnWriteArrayList 中获取。ThreadLocal 和 CopyOnWriteArrayList 在 ConcurrentBag 中都是成员变量,线程间不共享,避免了伪共享。使用专门的AbstractQueuedLongSynchronizer来管理跨线程信号。
获取连接的核心过程大致如下:
- 1、尝试从当前线程的ThreadLocal获取连接
- 2、ThreadLocal获取失败则尝试从CopyOnWriteArrayList中获取
- 3、尝试通过CAS自旋方式创建新的连接
通过ThreadLocal缓存、CopyOnWriteArrayList 再次缓存的方式来实现无锁化,获取连接的核心代码如下:
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// Try the thread-local list first
final List<Object> list = threadList.get();
for (int i = list.size() - 1; i >= 0; i--) {
final Object entry = list.remove(i);
@SuppressWarnings("unchecked")
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry;
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
// Otherwise, scan the shared list ... then poll the handoff queue
final int waiting = waiters.incrementAndGet();
try {
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
// If we may have stolen another waiter's connection, request another bag add.
if (waiting > 1) {
listener.addBagItem(waiting - 1);
}
return bagEntry;
}
}
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
return null;
}
finally {
waiters.decrementAndGet();
}
}
连接池对于分布式应用的一些思考及延伸
从上述源码分析来看,为了更好的利用连接池,大家对与线程池模型进行了大量的优化。
当前应用规模越来越大,为了更好的解决这些问题涌现的如容器化编排、微服务、service mesh等技术。很遗憾现实没有银弹,虽然连接池很好,在当前大规模部署的环境下,动则成千上万的服务很多微小的问题也浮现了出来。
高性能数据库连接池的内幕一文中指出了在分布式大规模应用中线程池的一些问题:
1、线程数过多
在分库分表的场景下,比如128个分库:32个服务器,每个服务器有4个schema,便会新建128个独立数据库连接池。假如使用Druid作为线程池,光是线程池就将产生256个线程。线程数过多将会导致内存占用较大: 默认1个线程会占用1M的空间,如果是512个线程,则会占用1M*512=512M上下文切换开销。
2、连接数过多
数据库的连接资源比较重,并且随着连接的增加,数据库的性能会有明显的下降。DBA一般会限制每个DB建立连接的个数,比如限制为3K 。假设数据库单台限制3K,32台则容量为3K32=96K。如果应用最大,最小连接数均为10,则每个应用总计需要12810=1.28K个连接。那么数据库理论上支持的应用个数为96K/1.28K= 80 台
3、连接不能复用
同一个物理机下面不同的schema完全独立,连接不能复用。
因此在分布式大规模的场景下,对于连接池模型还有更进一步的优化的空间。唯品会进行的一系列尝试对于我们有着很大的启发与借鉴意义。从互联网发展趋势来看,目前服务正在朝着单一化职责的方向发展,微服务、容器化为超大规模服务提供了有力的支撑,service mesh 进一步加强了这一趋势,也对我们提出了更大的挑战。
