


render-html.js
render-html.js是截取来自template字符串匹配出标签和它上面的属性等,然后生成一个node后变成一棵nodesTree。
一开始定义了tagStart,tagEnd,commentStart,commentEnd几个常量,分别代表
this.tagStart = '<' //普通标签开始
this.tagEnd = '>' //普通标签结束
this.commentStart = '<!--' //注释标签开始
this.commentEnd = '-->' //注释标签结束
this.voidTags = []//想要过滤掉的标签
我们来理一下思路,编写html一般有以下几个场景:
- 纯文本
- 注释标签
<!-- 注释内容 --> - 普通标签
<开始 tag [定义的属性,class,style等] 结束> </tag>
最简单的是纯文本,当str.indexOf(this.tagStart) === -1时,该str就是一段纯文本。还有一种情况当str.indexOf(this.tagStart)有具体值时,说明在标签前,有一段纯文本。
这里定义文字的node是一个type=text,content=文本内容
if(nextTag == -1){
//文本
nodes.push({
type:'Text',
content:str
})
str = ''
break;
}
if(nextTag){
//如果有下标,说明在这下标前有一段文本,我们将截取到这个标签前的文本,储存成text
let content = str.slice(0,nextTag)
if(content.trim() !== ''){
nodes.push({
type:'Text',
content:content
})
}
str = str.slice(nextTag) // 重新截取文本,然后再次进入函数
continue; //continue语句的作用是跳过本次循环体中余下尚未执行的语句,立即进行下一次的循环条件判定,
}
接下来就是注释标签,当 startsWithCommentStart(str)为true,说明这里有一段注释。
startsWithCommentStart(s){
return (
s.charAt(0) === '<' &&
s.charAt(1) === '!' &&
s.charAt(2) === '-' &&
s.charAt(3) === '-');
}
nodes.push({
type: 'Comment',
content:str.slice(this.commentStart,end+3) //这里的+3是因为 -->
})
这里定义注释的node是一个type=Comment,content=注释内容
最后,既不是文本也不是注释,定义普通标签node是一个type=Element,tagName=标签,attributes=属性,chidren=[子元素]
接下来,我们具体讲解普通标签的解析。首先要获取到他的标签类型,例如div、p。
思路:找到结束标签的index,判断是否有空格,如果有空格,则取index和空格最小的index,不然就是闭合标签的位置,取到对应的标签,不管大小写,全部变成小写。
parseTag():解析标签
let idxTagEnd = str.indexOf(this.tagEnd)
let idxSpace = str.indexOf(' ')
let tagNameEnd = (~idxTagEnd && ~idxSpace) ? Math.min(idxTagEnd,idxSpace):idxTagEnd
let tagName = str.slice(1,tagNameEnd)
let lowTagName = tagName.toLowerCase();
let attrs = this.parseAttrs(str.slice(tagNameEnd)); //解析了标签上的属性
let tag = {
tagName: lowTagName,
attributes: attrs.attributes,
};
接下来,我们要去处理标签上的一些属性,列入class、<input type='text' placeholde='请输入'> ,而处理这些的函数是parseAttrs()
思路:这里的str是被截取的标签上的属性,利用tagPairs()和splitHead()解析成属性键值对的形式,循环处理属性键值对,去匹配对象的属性类型。
str = str.trim()
let results = this.tagPairs(str, 0);
str = str.slice(results.cursor);//
let _this = this
let attributes = results.kvs.map(function(pair) {
let kv = _this.splitHead(pair.trim(), '=');
kv[1] = kv[1] ? _this.unquote(kv[1]) : kv[0];
return kv;
}).reduce(function(attrs,kv){
let property = kv[0] //属性
let value = kv[1] //属性值
switch(property){
case 'class' : //属性是否是class
attrs.class = value.split(' ');
break;
case 'style':
attrs.style = _this.parseStyle(value);
break;
case _this.startsWithDataDash(property): //判断是否是data-的属性格式
attrs.dataset = attrs.dataset || {};
var key = property.slice(5);
attrs.dataset[key] = _this.castValue(value);
break;
default:
attrs[property] = _this.castValue(value);
}
return attrs;
},{})
return {
str: str,
attributes: attributes
}
tagPairs()将属性变成属性对
let words = [] //用于保存属性的键值对,let quote = null //引用,let cursor = index //一开始是0,用来解析传进来的字符串、let wordBegin = cursor //index作为word开始、let len = str.length //截取字符串的长度
while( cursor < len ){
let char = str.charAt(cursor); //查找 index的位置上的字符串
let isTagEnd = !quote && (char === '/' || char === this.tagEnd); //首先判断 引用没有并且chat等与/和或者等于>
//如果已经到了标签的尾部
if(isTagEnd){
if(cursor !== wordBegin){ //进不来这个判断,这就说明这个标签上没有属性
words.push(str.slice(wordBegin, cursor)) //说明已经把这个标签上的属性都遍历完了
}
break;
}
let isWordEnd = !quote && char === ' ' ; // 如果没有引用指针,且碰到了空格
if (isWordEnd) { //如果是
if (cursor !== wordBegin) {
words.push(str.slice(wordBegin, cursor));
}
wordBegin = cursor + 1; // 开始的指针等于当前的指针 +1
cursor++; // 当前的指针也++
continue;
}
let isQuoteEnd = char === quote;//当 char又一次等于了 quote 就说明结束啦
if (isQuoteEnd) {
quote = null; //
cursor++;
continue;
}
let isQuoteStart = !quote && (char === "'" || char === '"'); //检测到了 '"',"'" 就说明后面的就是属性值啦
if (isQuoteStart) {
quote = char;
cursor++;
continue;
}
cursor++;
}
最后循环words,生成类似attrs=['xxx=123','aaa=111'],
let attrs = [];
let wLen = words.length;
for(let i=0; i< wLen; i++){
let word = words[i]
if (!(word && word.length)) continue;
let isNotPair = word.indexOf('=') === -1; //如果没有等号 =
if (isNotPair) {
let secondWord = words[i + 1];
let thirdWord = words[i + 2];
let isSpacedPair = secondWord === '=' && thirdWord; //是否是因为有空格
if (isSpacedPair) {
let newWord = word + '=' + thirdWord;
attrs.push(newWord);
i += 2;
continue;
}
}
attrs.push(word);
}
解析到这里,回到parseTag(),首先判断是否是自闭合标签,如果不是的话,再判断是否是需要隔离的标签,如果都不是则进入下一轮的循环,并将生成子node元素。
if(this.startsWithSelfClose(str)){
str = str.slice(2);
}else{
str = str.slice(1);
if(!~this.voidTags.indexOf(lowTagName)){ //
let results = this.parseAllNodes(str, stack.concat(tagName));
tag.children = results.nodes;
str = results.str;
stack = results.stack;
}
}
return {
tag: tag,
str: str,
stack: stack
}
在parseAllNodes()里每次循环都是先去判断时候当前是否到了结束标签,在这里就会退出循环,这里也是一个标签的解析结束。
var isClosingTag = str.charAt(nextTag + 1) === '/';
if(isClosingTag){ //</div>
let endTagEnd = str.indexOf(this.tagEnd)
let innerTag = str.slice(2, endTagEnd);
let tagName = innerTag.trim().split(' ')[0];
str = str.slice(endTagEnd + 1);
var loc = stack.lastIndexOf(tagName);
if (~loc) {//如果有index 则截取出对应的内容赋值到stack里 退出本次循环
stack = stack.slice(0, loc);
break;
}
continue;
}
最终,生成nodesTree如下图
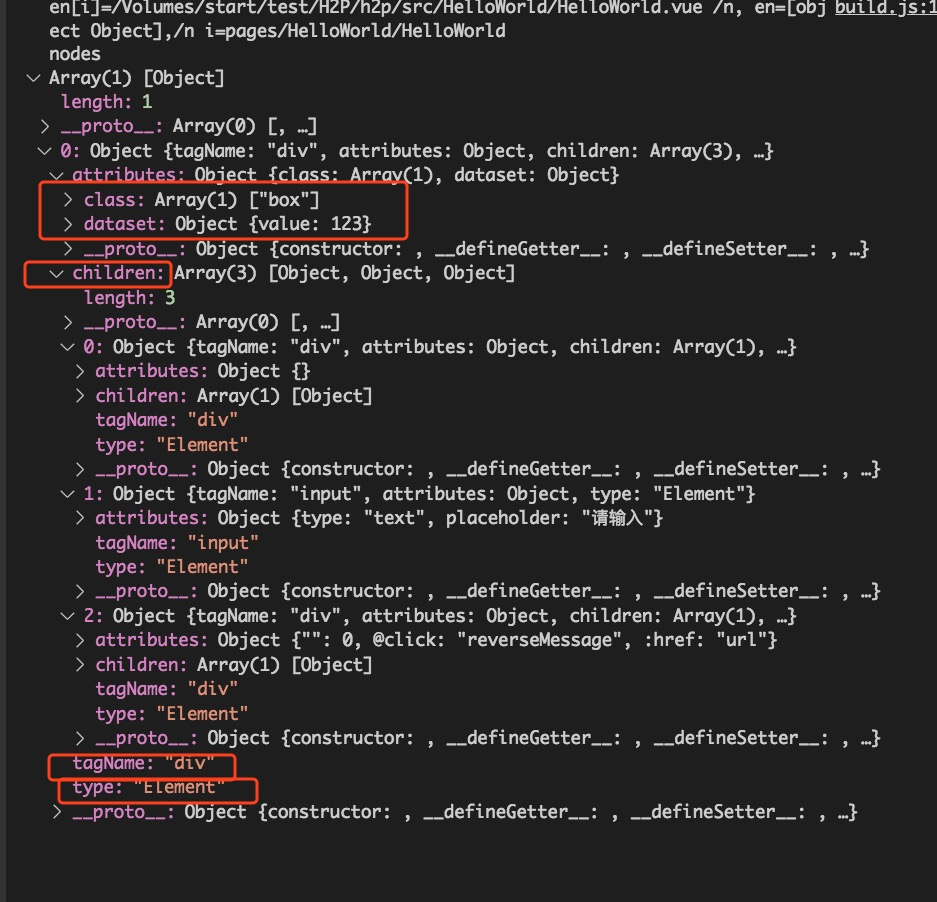
接下来到了将nodesTree转成原生小程序,也就是template.js.
template.js
首先,将nodeTree里文本经过parseText()后decode处理,属性经过parseElement()拼接成字符串。
nodes.map(item => {
let {
type,
content,
children = []
} = item
if (type === 'Text') {
let c = this.parseText(content)//处理文本
item.content = c
}
if (type === 'Comment') {
item.content = content
}
if (type === 'Element') {
let {
wxTag,
attrStr
} = this.parseElement(item)
item.wxTag = wxTag
item.attrStr = attrStr //将属性都拼接好
if (children && children.length > 0) {
this.parseWxml(children)
}
}
})
return nodes
parseText(c) {
return html5Entities.decode(c)
}
parseElement(item) {
let wxTag = '',
attrStr = '',
c = ''
let {
tagName,
attributes,
content
} = item
if (['i', 'span', 's'].indexOf(tagName) !== -1) {
wxTag = 'text'
} else if (tagName === 'a') {
wxTag = 'navigator'
} else if (tagName === 'img') {
wxTag = 'image'
} else if (['input', 'button', 'checkbox', 'checkbox-group', 'form', 'label', 'textarea'].indexOf(tagName) !== -1) {
wxTag = tagName
} else {
wxTag = 'view'
}
if (attributes) {
let styleStr = ''
for (let attr in attributes) {
let style = attributes['style']
if (attr === 'style') {
for (let s in style) {
styleStr += `${s}:'${style[s]}'; `
}
attrStr += `style="${styleStr}"`
} else {
attrStr += `${attr}="${attributes[attr]}" `
}
}
}
return {
wxTag: wxTag,
attrStr: attrStr
}
}
后续,处理好的nodeTrees利用循环递归输出成模版~
template(nodes) {
let str = this.childrenTemplate(nodes)
this.wxml = ` <view name="html-view-nodes">${str}</view>`
}
childrenTemplate(childrenNodes) {
let str = ''
childrenNodes.map((item, index) => {
let {
type = ''
} = item
let text = '',
view = ''
if (type === 'Text') {
text = `${item.content}`
str = `${text}`
} else {
view = this.viewTemplate(item)
str += `${view}`
}
})
return str
}
viewTemplate(item) {
let {
children = []
} = item
let str = `${item.wxTag !== 'text' ?
`<${item.wxTag} ${item.attrStr}>
${children.length >0 ? this.childrenTemplate(item.children):''}
</${item.wxTag}>` :''}
${item.wxTag === 'text' ?
`<text ${item.attrStr}>
${children.length >0 ? this.childrenTemplate(item.children):''}
</text>` :''} `
return str
}
最终,生成的模版如下图
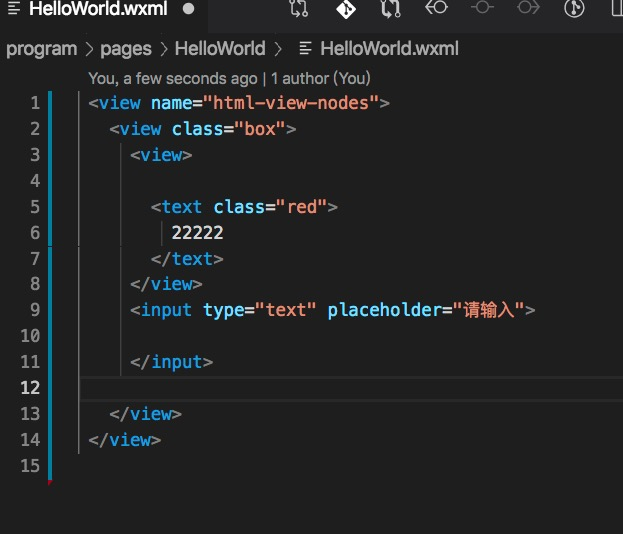
到这里终于结束了。。。(是的,国庆假期也结束了。。。)

总结
这个小项目,我写了差不多1个多星期,其实一开始也是一拍脑门埋头干,写出了很多bug,到后面慢慢修,去看早就忘记的一些html,js基础。
还是学到不少东西,第一篇文章发出去的时候,有人问我,都有mpvue,你为啥还要做这些东西?
其实我觉得,大厂的东西是很好,靠我一个人也绝对做不出那么好。(希望有小伙伴也能加入进来 ⭐️。⭐️)就像开汽车,会开汽车是一回事,学造汽车也是一回事。都是兴趣所趋~ 任重而道远 ~ 开心就好~
Future
不知道写不写的完,但是flag还是要立的!
- v-**标签转各种小程序里的标签
- vue里自己开发的组件模版该如和处理

