

文章作者:「夜幕团队 NightTeam」 - 张冶青
润色、校对:「夜幕团队 NightTeam」 - Loco
前言
自动化测试对于软件开发来说是一个很重要也很方便的东西,但是自动化测试工具除了能用来做测试以外,还能被用来做一些模拟人类操作的事情,所以一些 E2E 自动化测试工具(例如:Selenium、Puppeteer、Appium)因为其强大的模拟功能,经常还被爬虫工程师们用来抓取数据。
网上有很多将自动化测试工具作为爬虫的抓取教程,不过仅仅都限于如何获取数据,而我们知道这些基于浏览器的解决方案都有较大的性能开销,而且效率不高,并不是爬虫的最佳选择。
本篇文章将介绍自动化测试工具的另一种用法,也就是用来自动化一些人工操作。我们使用的工具是谷歌开发并开源的测试框架 Puppeteer ,它会操作 Chromium (谷歌开发的开源浏览器)来完成自动化。我们将一步一步介绍如何利用 Puppeteer 在掘金上自动发布文章。
自动化测试工具的原理
自动化测试工具的原理是通过程式化地操作浏览器,与其进行模拟交互(例如点击、打字、导航等等)来控制要抓取的网页。自动化测试工具通常也能获取网页的 DOM 或 HTML,因此也可以轻松的获取网页数据。
此外,对于一些动态网站来说,JS 动态渲染的数据通常不能轻松获取,而自动化测试工具则可以轻松的做到,因为它是将 HTML 输入浏览器里运行的。
Puppeteer 简介
这里摘抄 Puppeteer 的 Github 主页上的定义(英文)。
Puppeteer is a Node library which provides a high-level API to control Chrome or Chromium over the DevTools Protocol. Puppeteer runs headless by default, but can be configured to run full (non-headless) Chrome or Chromium.
翻译过来大致是: Puppeteer 是一个 Node.js 库,提供了高级 API 来控制 Chrome 或 Chromium (通过开发工具协议); Puppeteer 默认的运行模式是无头的,但是可以被配置成非无头的模式。
Loco注:无头指的是不显示浏览器的GUI,是为了提升性能而设计的,因为渲染图像是一件很消耗资源的事情。
以下是 Puppeteer 可以做的事情:
- 生成截图和页面 PDF ;
- 抓取单页应用,产生预渲染内容(即 SSR ,服务端渲染);
- 自动化表单提交、 UI 测试、键盘输入等等;
- 创建一个最新的、自动化的测试环境;
- 捕获网站的时间线来帮助诊断性能问题;
- 测试 Chrome 插件;
- ...
Puppeteer 安装
安装 Puppeteer 并不难,只需要保证你的环境上安装了 Node.js 以及能够运行 NPM。
由于官方的安装教程没有考虑到已经安装了 Chromium 的情况,我们这里使用一个第三方库 puppeteer-chromium-resolver,它能够自定义化 Puppeteer 以及管理 Chromium 的下载情况。
运行以下命令安装 Puppeteer:
npm install puppeteer-chromium-resolver --save
puppeteer-chromium-resolver 的详细用法请参照官网:www.npmjs.com/package/pup…。
Puppeteer 常用命令
Puppeteer 的官方API文档是 pptr.dev/ ,文档里有详细的 Puppeteer 的开放接口,可以进行参考,这里我们只列出一些常用的接口命令。
生成/关闭浏览器
// 引入puppeteer-chromium-resolver
const PCR = require('puppeteer-chromium-resolver')
// 生成PCR实例
const pcr = await PCR({
revision: '',
detectionPath: '',
folderName: '.chromium-browser-snapshots',
hosts: ['https://storage.googleapis.com', 'https://npm.taobao.org/mirrors'],
retry: 3,
silent: false
})
// 生成浏览器
const browser = await pcr.puppeteer.launch({...})
// 关闭浏览器
await browser.close()
生成页面
const page = await browser.newPage()
导航
await page.goto('https://baidu.com')
等待
await page.waitFor(3000)
await page.goto('https://baidu.com')
获取页面元素
const el = await page.$(selector)
点击元素
await el.click()
输入内容
await el.type(text)
执行Console代码(重点)
const res = await page.evaluate((arg1, arg2, arg3) => {
// anything frontend
return 'frontend awesome'
}, arg1, arg2, arg3)
这应该是 Puppeteer 中最强大的 API 了。任何熟悉前端技术的开发者都应该了解 Chrome 开发者工具中的 Console,任何 JS 的代码都可以在这里被运行,其中包括点击事件、获取元素、增删改元素等等。我们的自动发文程序将大量用到这个 API 。
可以看到 evaluate 方法可以接受一些参数,并作为回调函数中的参数作用在前端代码中。这让我们可以将后端的任何数据注入到前端 DOM 中,例如文章标题和文章内容等等。
另外,回调函数中的返回值可以作为 evaluate 的返回值,赋值给 res,这经常被用作数据抓取。
注意,上面的这些代码都用了 await 这个关键字,这其实是 ES7 中的 async/await 新语法,是 ES6 的 Promise 的语法糖,让异步代码更容易阅读和理解。如果对 async/await 不理解的同学,可以参考这篇文章:juejin.cn/post/684490…。
Puppeteer 实战:在掘金上自动发布文章
常言说:Talk is cheap, show me the code。
下面,我们将用一个自动发文章的例子来展示 Puppeteer 的功能。本文中用来作为示例的平台是掘金。
为什么选择掘金呢?这是因为掘金的登录并不像其他某些网站(例如 CSDN )要求输入验证码(这会增大复杂度),只要求输入账户名和密码就可以登录了。
为了方便新手理解,我们将从爬虫基本结构开始讲解。(限于篇幅考虑,我们将略过浏览器和页面的初始化,只挑重点讲解)
基础结构
为了让爬虫显得不那么乱七八糟,我们将发布文章的各个步骤抽离了出来,形成了一个基类(因为我们可能不止掘金一个平台要抓取,使用面向对象的思想编写代码的话,其他平台只需要继承基类就可以了)。
这个爬虫基类大致的结构如下:
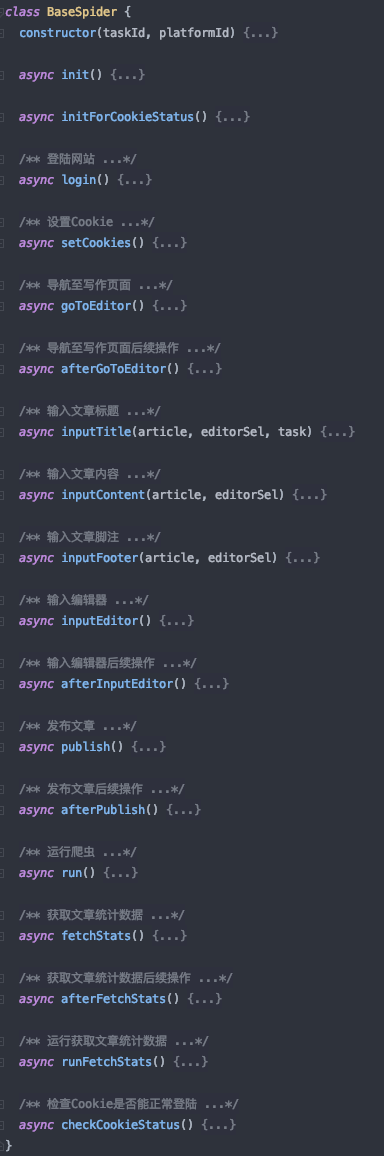
我们不用理解所有的方法,只需要知道我们启动的入口是 run 这个方法就好了。
所有方法都加上了 async,表示这个方法将返回 Promise,如果需要以同步的形式调用,必须加上 await 这个关键字。
run 方法的内容如下:
async run() {
// 初始化
await this.init()
if (this.task.authType === constants.authType.LOGIN) {
// 登陆
await this.login()
} else {
// 使用Cookie
await this.setCookies()
}
// 导航至编辑器
await this.goToEditor()
// 输入编辑器内容
await this.inputEditor()
// 发布文章
await this.publish()
// 关闭浏览器
await this.browser.close()
}
可以看到,爬虫将首先初始化,完成一些基础配置;然后根据任务的验证类别(authType )来决定是否采用登录或 Cookie 的方式来通过网站验证(本文只考虑登录验证的情况);接下来就是导航至编辑器,然后输入编辑器内容;接着,发布文章;最后关闭浏览器,发布任务完成。
登录
async login() {
logger.info(`logging in... navigating to ${this.urls.login}`)
await this.page.goto(this.urls.login)
let errNum = 0
while (errNum < 10) {
try {
await this.page.waitFor(1000)
const elUsername = await this.page.$(this.loginSel.username)
const elPassword = await this.page.$(this.loginSel.password)
const elSubmit = await this.page.$(this.loginSel.submit)
await elUsername.type(this.platform.username)
await elPassword.type(this.platform.password)
await elSubmit.click()
await this.page.waitFor(3000)
break
} catch (e) {
errNum++
}
}
// 查看是否登陆成功
this.status.loggedIn = errNum !== 10
if (this.status.loggedIn) {
logger.info('Logged in')
}
}
掘金的登录地址是 juejin.im/login,我们先将浏…
这里我们循环 10 次,尝试输入用户名和密码,如果 10 次都失败了,就设置登录状态为 false;反之,则设置为 true。
接着,我们用到了 page.$(selector) 和 el.type(text) 这两个 API ,分别用于获取元素和输入内容。而最后的 elSubmit.click() 是提交表单的操作。
编辑文章
这里我们略过了跳转到文章编辑器的步骤,因为这个很简单,只需要调用 page.goto(url) 就可以了,后面会贴出源码地址供大家参考。
输入编辑器的代码如下:
async inputEditor() {
logger.info(`input editor title and content`)
// 输入标题
await this.page.evaluate(this.inputTitle, this.article, this.editorSel, this.task)
await this.page.waitFor(3000)
// 输入内容
await this.page.evaluate(this.inputContent, this.article, this.editorSel)
await this.page.waitFor(3000)
// 输入脚注
await this.page.evaluate(this.inputFooter, this.article, this.editorSel)
await this.page.waitFor(3000)
await this.page.waitFor(10000)
// 后续处理
await this.afterInputEditor()
}
首先输入标题,调用了 page.evaluate 这个前端执行函数,传入 this.inputTitle 输入标题这个回调函数,以及其他参数;接着同样的原理,调用输入内容回调函数;然后是输入脚注;最后,调用后续处理函数。
下面我们详细看看 this.inputTitle 这个函数:
async inputTitle(article, editorSel, task) {
const el = document.querySelector(editorSel.title)
el.focus()
el.select()
document.execCommand('delete', false)
document.execCommand('insertText', false, task.title || article.title)
}
我们首先通过前端的公开接口 document.querySelector(selector) 获取标题的元素,为了防止标题有 placeholder,我们用 el.focus()(获取焦点)、el.select()(全选)、document.execCommand('delete', false)(删除)来删除已有的 placeholder。然后我们通过 document.execCommand('insertText', false, text) 来输入标题内容。
接下来,是输入内容,代码如下(它的原理与输入标题类似):
async inputContent(article, editorSel) {
const el = document.querySelector(editorSel.content)
el.focus()
el.select()
document.execCommand('delete', false)
document.execCommand('insertText', false, article.content)
}
有人可能会问,为什么不用 el.type(text) 来输入内容,反而要大费周章的用 document.execCommand 来实现输入呢?
这里我们不用前者的原因,是因为它是完全模拟人的敲打键盘操作的,这样会破坏已有的内容格式。而如果用后者的话,可以一次性的将内容输入进来。
我们在基类 BaseSpider 中预留了一个方法来完成选择分类、标签等操作,在继承后的类 JuejinSpider 中是这样的:
async afterInputEditor() {
// 点击发布文章
const elPubBtn = await this.page.$('.publish-popup')
await elPubBtn.click()
await this.page.waitFor(5000)
// 选择类别
await this.page.evaluate((task) => {
document.querySelectorAll('.category-list > .item').forEach(el => {
if (el.textContent === task.category) {
el.click()
}
})
}, this.task)
await this.page.waitFor(5000)
// 选择标签
const elTagInput = await this.page.$('.tag-input > input')
await elTagInput.type(this.task.tag)
await this.page.waitFor(5000)
await this.page.evaluate(() => {
document.querySelector('.suggested-tag-list > .tag:nth-child(1)').click()
})
await this.page.waitFor(5000)
}
发布
发布操作相对来说比较简单了,只需要点击发布的那个按钮就可以了。代码如下:
async publish() {
logger.info(`publishing article`)
// 发布文章
const elPub = await this.page.$(this.editorSel.publish)
await elPub.click()
await this.page.waitFor(10000)
// 后续处理
await this.afterPublish()
}
this.afterPublish 是用来处理验证发文状态和获取发布 URL 的,这里限于篇幅不详细介绍了。
源码
当然,本篇文章由于篇幅原因,介绍的并不是所有的自动发文功能,如果你想了解更多,可以发送消息【掘金自动发文】到我们的微信公众号【NightTeam】获取源码地址。
总结
本篇文章介绍了如何使用 Puppeteer 来操作 Chromium 浏览器在掘金上发布文章。
很多人用 Puppeteer 来抓取数据,但我们认为这种效率较低,而且开销较大,不适合大规模抓取。
相反, Puppeteer 更适合做一些自动化的工作,例如操作浏览器发布文章、发布帖子、提交表单等等。
Puppeteer 自动化工具很类似 RPA(Robotic Process Automation),都是自动化一些繁琐的、重复性的工作,只不过后者不仅限于浏览器,其范围(Scope)是基于整个操作系统的,功能更强大,但是开销也更大。
Puppeteer 作为相对轻量级的自动化工具,很适合用来做一些网页自动化操作作业。本文介绍的 Puppeteer 实战内容也是开源一文多发平台项目 ArtiPub 的一部分,有兴趣的同学可以去尝试一下。
夜幕团队成立于 2019 年,团队包括崔庆才、周子淇、陈祥安、唐轶飞、冯威、蔡晋、戴煌金、张冶青和韦世东。
涉猎的编程语言包括但不限于 Python、Rust、C++、Go,领域涵盖爬虫、深度学习、服务研发、对象存储等。团队非正亦非邪,只做认为对的事情,请大家小心。

本篇文章由一文多发平台ArtiPub自动发布
