

去年应公司业务需求,分析师们给了我几张关于各类公司的数据表、包括中国企业500强、创投公司、上市公司等几十万家公司数据。要求我抓取这些公司的招聘信息。此项目是我大三实习时独立开发的一个较为满意的项目,今日在硬盘里发现了其中部分代码,自认为此项目挺有意思,因此把整个项目思路和过程整理下来。
项目要求与抓取数据源确定
要求
要求从boss直聘、前程无忧、智联招聘、中华英才网四大招聘网站里选取其中一个招聘网站抓取数据。首先实现全量数据抓取,接着增量数据抓取,以后每日自动更新数据库数据。
抓取网站选型
为了不给后续抓取过程中留坑,也为了能够尽快完美的完成任务,选择一个易于抓取和稳定的网站至关重要。花了2-3天研究了四大招聘网站的特点。
boss直聘:数据量较为丰富,岗位搜索结果较为准确,IP地址容易被封,而且解封需要24小时(这里真得吐槽下,我人为用浏览器手动搜索,翻了几十个页面就把我IP封了,这样做很容易中伤用户,不过今年遇到一个boss直聘开发人员,说是网站已经改了这些反爬措施)
智联招聘:数据量较少 ,海量快速抓取过程中可能存在触发验证码登录
中华英才网:数据量较少,岗位搜索结果特别不准确
前程无忧:数据量较为丰富,岗位搜索结果较为准确,反爬措施较少。
对各大招聘网站使用单ip发送请求,结果发现,在ip被封之前前程无忧的访问量最多。 所以,从数据量、数据准确性、抓取难度等几个方面综合考虑,前程无忧是最佳选择。
列表页信息抓取
在这之前,我本想着去网上找个抓取源码借鉴一下,虽然发现网上是有一些关于前程无忧的抓取代码。但是发现这些代码基本都是'随便写写',几乎没有借鉴之处。主要问题在于,网上的抓取源码都是以招聘岗位进行抓取,只抓取某一个岗位的招聘信息,数据量很少,一次入库,而且只有一套页面解析规则,很多细节之处没有处理,数据存在严重错误以及缺漏。我自己分析了一下我的这个项目的不同之处以及网站的页面,是按照公司名称进行抓取,数据量较大,每日定时自动抓取,而且每个岗位信息详情页并不都是千篇一律的构造,需要针对实际情况多写几套解析规则,才能抓取到特殊页面的信息。
模块导入
# -*- coding: utf-8 -*-
#这里的agent_proxy模块是自己另外写的请求头和IP代理随机获取模块
from agent_proxy import get_random_agent,get_useful_proxy
import requests
from bs4 import BeautifulSoup
import threading
import HTMLParser
import datetime
import pymysql
import re
import ssl
import time
import random
import sys
from Queue import Queue
reload (sys)
sys.setdefaultencoding ("utf-8")
ssl._create_default_https_context = ssl._create_unverified_context
URL解码
因为是以公司名称为关键词来查找招聘信息,所以要找出关键词公司名称和url的对应变化关系。
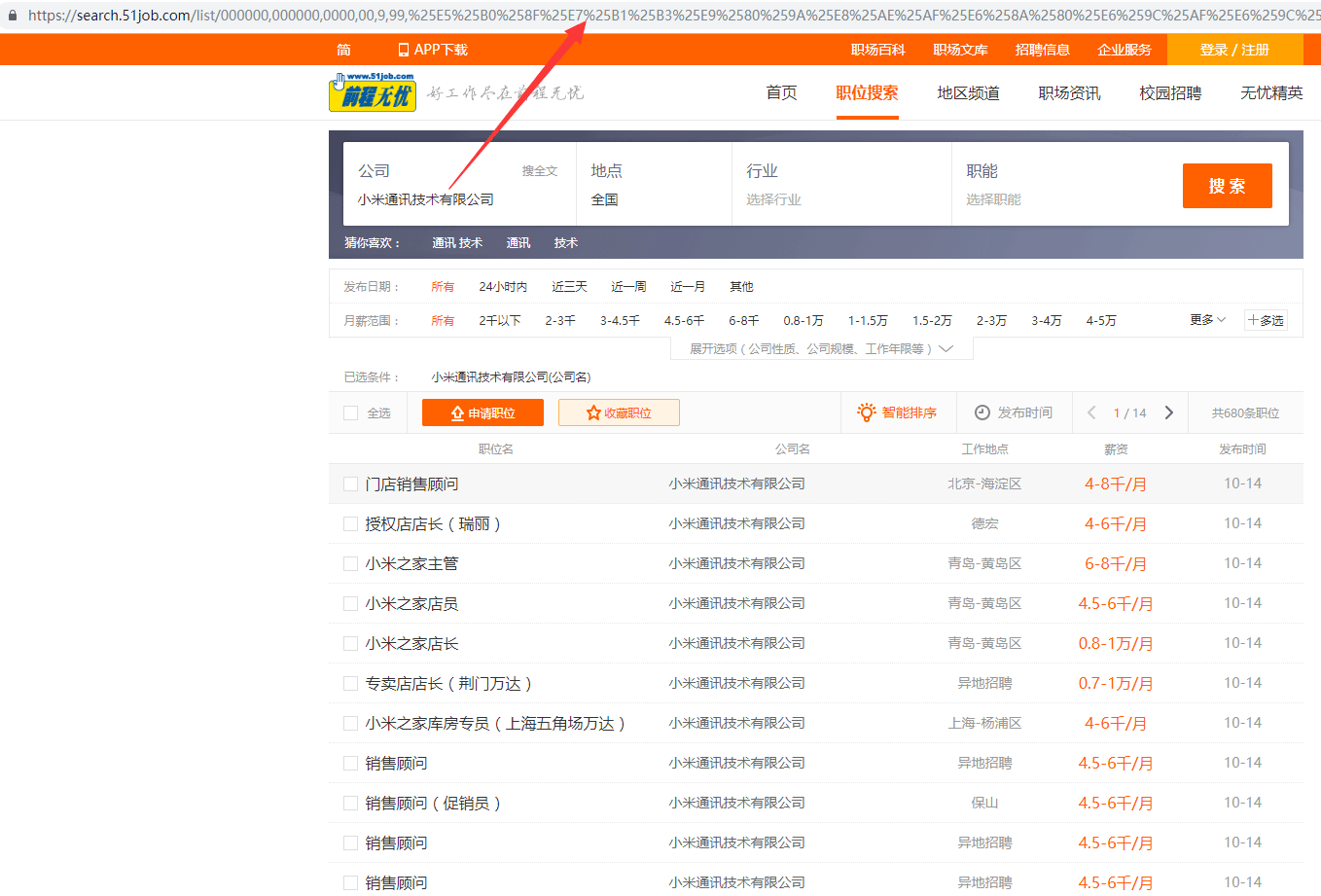
看着很多参数,无规律可言,但是把这个链接解码两次:
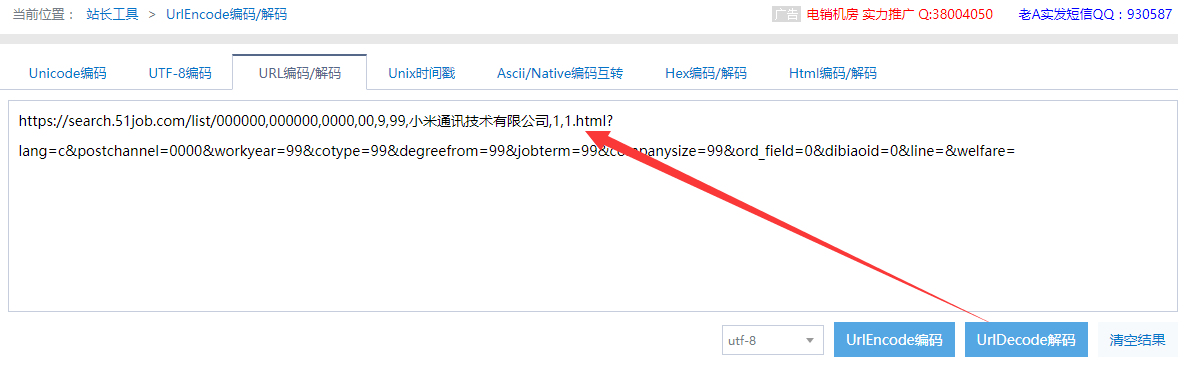
按照同样的方式解码‘字节跳动’url:
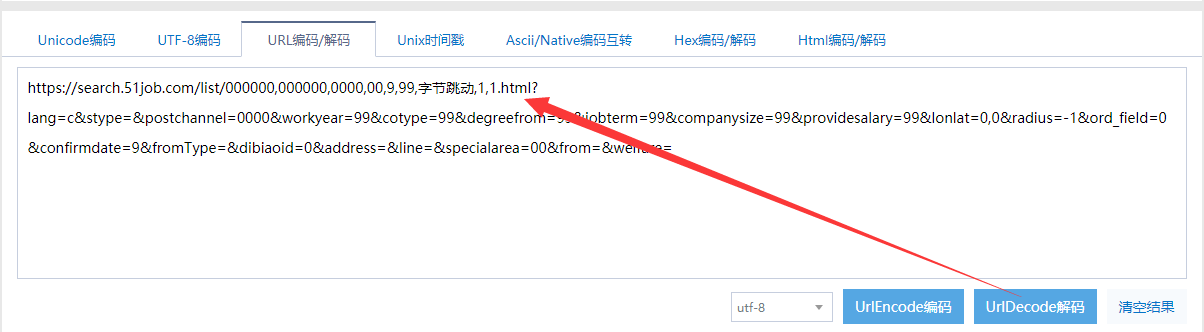
仔细一对比,发现变化公司名称,对应的url里只是换了公司名一个参数,其他都一样。
使用解码后的url,去掉多余参数进行搜索: search.51job.com/list/000000…?
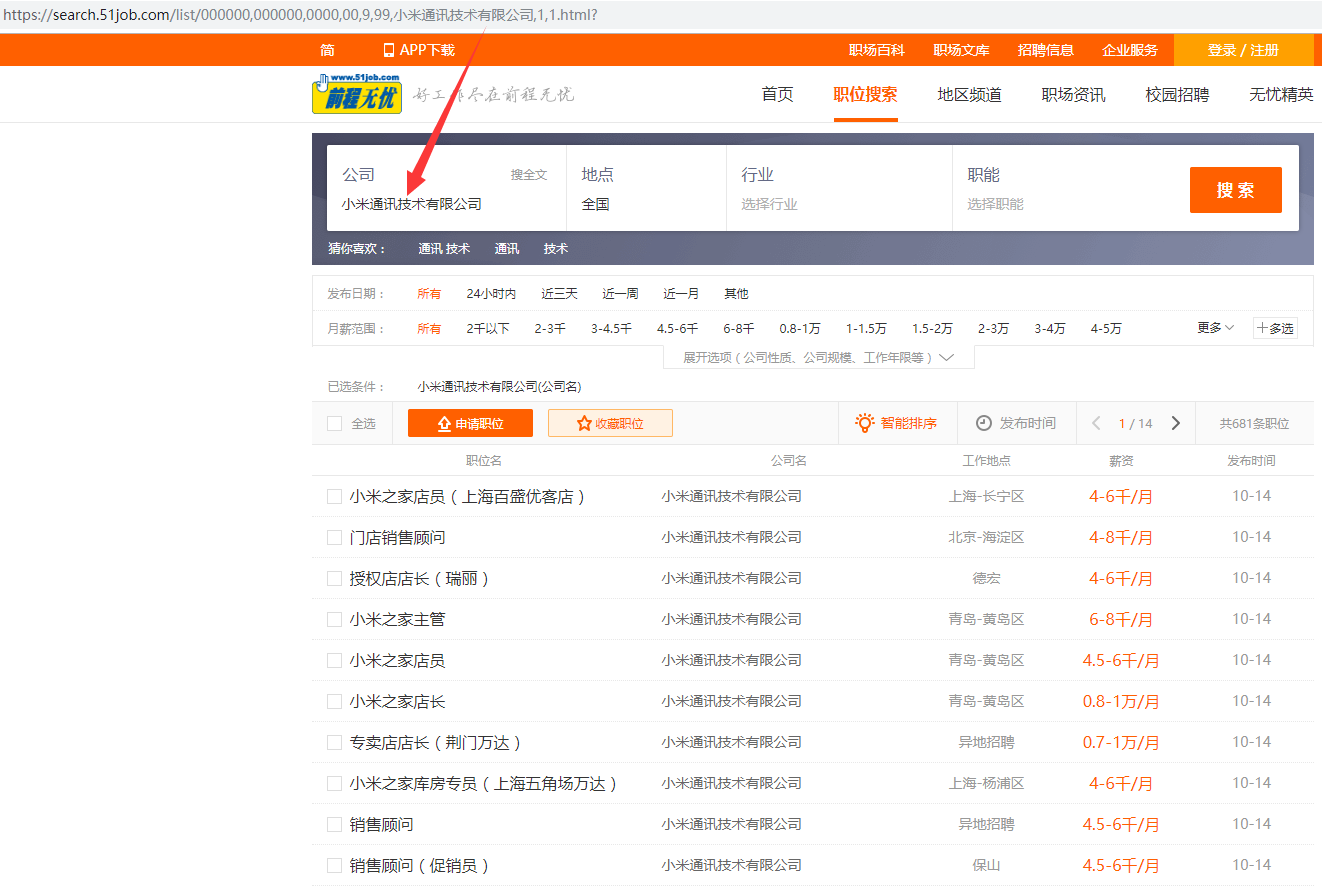
发现和原来的搜索结果是一致的。
所以后续的公司招聘信息页面可通过这个URL更改company字段得到:
‘search.51job.com/list/000000…',1,1.html?’
列表页信息获取
从数据库获取到公司名,通过公司名称获取对应公司招聘信息列表页
page_url='https://search.51job.com/list/000000,000000,0000,00,9,99,'+each_company+',1,1.html?'
try:
res=requests.get(page_url,headers =headers,proxies=page_proxie)
soup = BeautifulSoup (res.content, 'html.parser', from_encoding='utf8')
url_tag = soup.find_all ('p', class_="t1")
except Exception as e:
pass
# 如果没有符合条件的职位信息,调用delete_com_tail继续获取信息
if not url_tag:
delete_com_tail (each_company,each_id,page_proxie)
#如果有符合条件的职位信息,调用parse_index_page进一步处理包含信息的url_tag标签
else:
parse_index_page (soup,url_tag,each_company,each_id,page_proxie)
前程无忧里的搜索机制是有缺陷的,很多公司的名称全称后缀一般都带有'控股有限公司'、'股份有限公司'、'有限公司'这些词,比如阿里巴巴集团,一般我们说他的全称是'阿里巴巴集团控股有限公司',包括我数据库里的名称也是'阿里巴巴集团控股有限公司',但是当我用这个名称查询对应的招聘信息的时候,返回结果为空,如下所示:
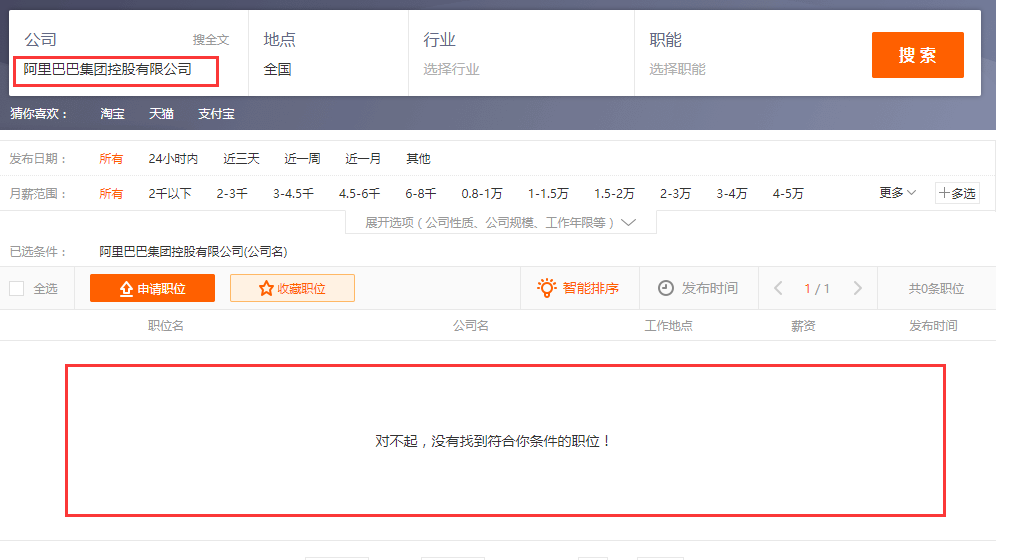
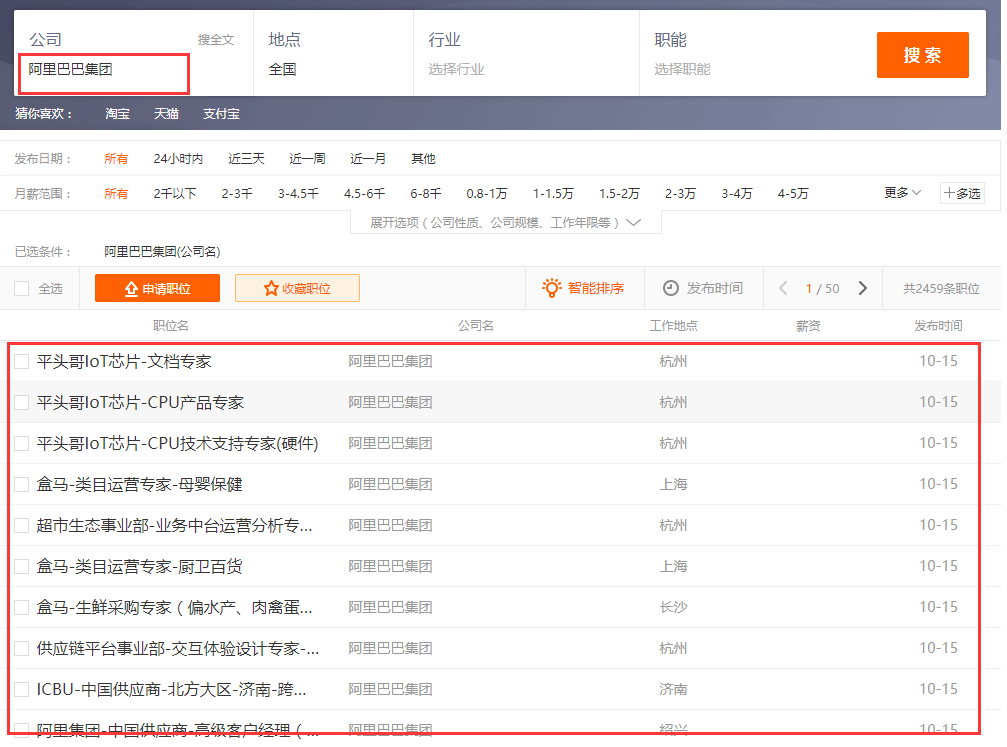
if '控股有限公司' in each_company:
each_company = each_company.replace, "")
elif '股份有限公司' in each_company:
each_company = each_company.replace ("股份有限公司", "")
elif '有限公司' in each_company:
each_company = each_company.replace ("有限公司", "")
if each_company == '北京':
return
然后用新的公司名each_company获取新的页面并重新解析。
列表页翻页处理
有些公司的招聘信息较少,总数据量一页不到,有些比较多,需要判断是一页数据还是多页数据,然后分别解析。
def parse_index_page(soup,url_tag,each_company,each_id,page_proxie):
"""
解析列表页,判断是否需要翻页,并进行进一步处理
:param soup:
:param url_tag:
:param each_company:
:param each_id:
:param page_proxie:
:return:
"""
page_num = soup.find ('span', class_="td").text
page_num = re.findall ("\d+", page_num)[ 0 ]
if int(page_num)!=1:#页数>1
try:
for page in range(2,int(page_num)+1):
if 'strong class="title' not in str(url_tag):
next_page_url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,'+str(each_company)+',1,' + str(page) + '.html?'
res = requests.get (next_page_url, headers=headers, proxies=proxies)
soup = BeautifulSoup (res.content, 'html.parser', from_encoding='utf8')
url_tag = soup.find_all ('p', class_="t1")
else:
next_page_url='https://mq.51job.com/joblist.php?keyword='+str(each_company)+'&jobarea=000000&lang=c&page='+str(page)
res = requests.get (next_page_url, headers=headers, proxies=proxies)
soup = BeautifulSoup (res.content, 'html.parser', from_encoding='utf8')
url_tag = soup.find_all ('strong', class_="title")
print next_page_url
page_proxie=get_useful_proxy()
parse_tag_url (url_tag, each_company, each_id, page_proxie)
except Exception as e:
pass
else:#页数=1
parse_tag_url (url_tag, each_company, each_id, page_proxie)
查重(判断数据是否已经被抓取)
有些数据可能被抓取过,每条页面都对应一个唯一的URL,所以用URL在数据库中进行索引查询,如果不存在,则继续抓取
def parse_tag_url(url_tag,each_company,each_id,page_proxie):
"""
#处理列表页的每个标签,取出详情页url,根据url在mysql进行去重
:param url_tag:
:param each_company:
:param each_id:
:param page_proxie:
:return:
"""
for each in url_tag:
each_url = each.a[ 'href' ]
# 根据job_url去重
sql = "select job_url from ntf_tyc_com_job where job_url = ('%s')" % (each_url)
try:
db2.ping (reconnect=True)
res = cursor2.execute (sql)
if res:
print "数据存在:" + each_url
continue
except:
print "Error"
detail_page (each_url, each_company, each_id, page_proxie)
详情页解析
终于到了我们需要获取的最终数据的详细页面,抓取数据如下:
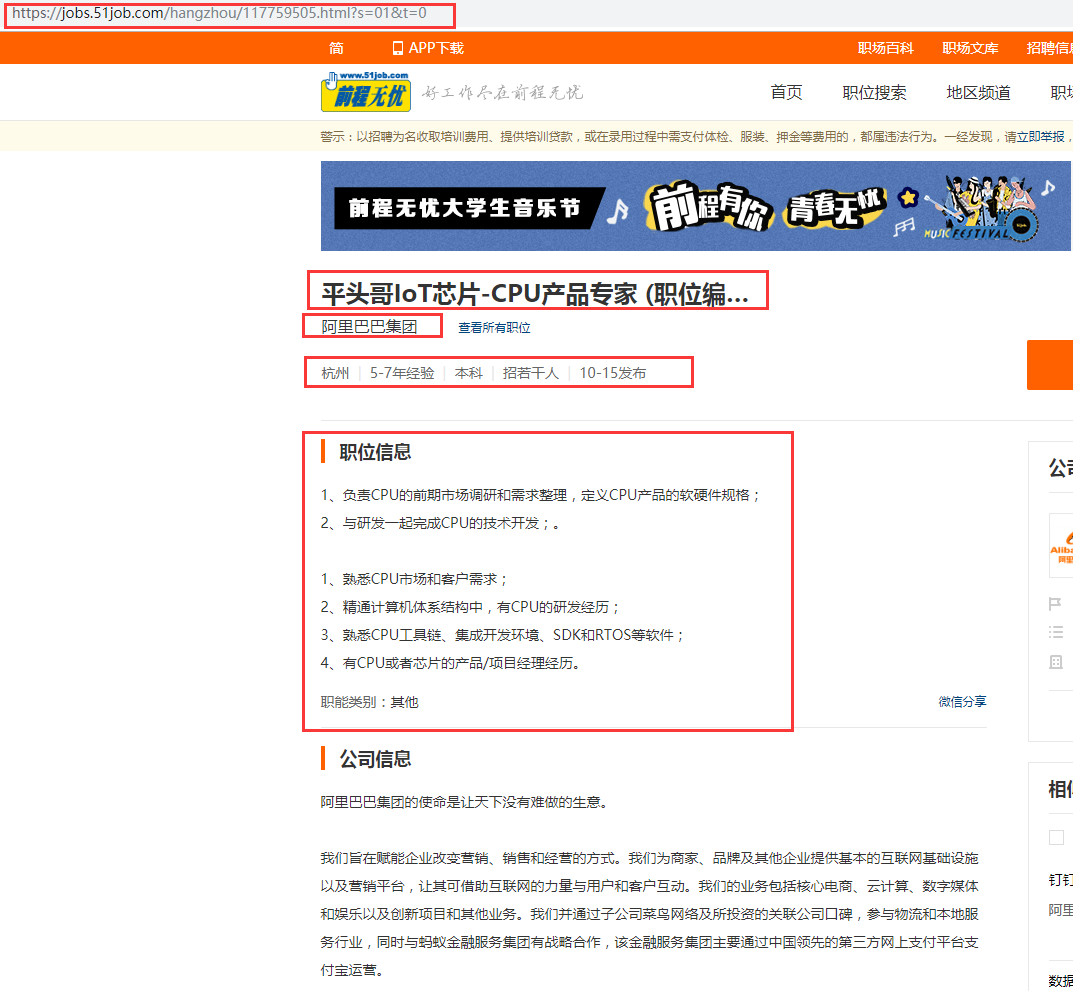
公司名、数据源、数据库关联、url、公司名称、岗位抓取
def detail_page (each_url,each_company,each_id,page_proxie):
"""
#解析详情页,取出需要信息
:param each_url:
:param each_company:
:param each_id:
:param page_proxie:
:return:
"""
time.sleep (0.001)
try:
res = requests.get (each_url, headers = headers, proxies=page_proxie)
soup = BeautifulSoup (res.content, 'html.parser', from_encoding='utf8')
#p判断是否是测试的岗位,如果是,丢弃
test_job = soup.find ('div', class_='bmsg inbox')
if test_job and '测试使用' in str(test_job):
return
job_info = {}
job_info[ 'com_name' ] = each_company # 公司名称
job_info[ 'come_source' ] = u'前程无忧'#数据源
job_info[ 'com_id' ] = each_id #公司id,和天眼查公司关联取id
job_info[ 'job_url' ] = each_url # 来源url
job_info[ 'com_sname' ] = soup.find ('p', class_="cname").text # 招聘公司名称
job_info[ 'job_name' ] = soup.find ('h1').text # 招聘岗位
job_info[ 'job_salary' ] = soup.find ('div', class_="cn").strong.text # 薪资
info = soup.find_all ('span', class_="sp4")
详情页工作经验、(有无)学历要求、招聘人数、发布时间、截止时间的抓取
if len (info) == 4:
job_info[ 'work_exp' ] = info[ 0 ].text # 工作经验
job_info[ 'job_edu' ] = info[ 1 ].text # 学历要求
job_info[ 'recruit_number' ] = info[ 2 ].text.replace("招","") # 招聘人数
pub_time = info[ 3 ].text.replace ("发布", "")
pub_time_v2 = '2018-' + str (pub_time)
job_info[ 'stat_date' ] = pub_time_v2.replace ("-", "/") # 招聘发布时间
d = datetime.datetime.strptime (pub_time_v2, '%Y-%m-%d')
seven_day = datetime.timedelta (days=7)
da_days = d + seven_day
job_info[ 'closing_date' ] = da_days.strftime ('%Y-%m-%d').replace ("-", "/")# 招聘截止时间
# 详情页只有工作经验、招聘人数、发布时间、没有学历的情况
else:
job_info[ 'work_exp' ] = info[ 0 ].text# 工作经验
job_info[ 'recruit_number' ] = info[ 1 ].text # 招聘人数
pub_time = info[ 2 ].text.replace ("发布", "")
pub_time_v2 = '2018-' + str (pub_time)
job_info[ 'stat_date' ] = pub_time_v2.replace ("-", "/")# 招聘发布时间
d = datetime.datetime.strptime (pub_time_v2, '%Y-%m-%d')
seven_day = datetime.timedelta (days=7)
da_days = d + seven_day
job_info[ 'closing_date' ] = da_days.strftime ('%Y-%m-%d').replace ("-", "/") # 招聘截止时间
这里值得一提的是,因为页面里并没有招聘截止日期这一数据,但是一个岗位的招聘肯定具有时效性,一个岗位不可能一直招聘,存在数据库里时间久了会成为失效数据。所以在数据表中添加一个招聘截止时间。
招聘截止时间=招聘发布时间+七天
所以在后面,当当前日前大于招聘截止时间时,就自动删除数据库中的这条招聘数据。保证了招聘数据的时效性。
城市以及区域抓取
job_info[ 'city' ]=soup.find ('div', class_="cn").span.text#城市
if '-' in job_info['city']:#有“-”符号,取出城市下面的区
city_area = job_info[ 'city' ]
job_info[ 'city' ] = job_info[ 'city' ].split ('-')[ 0 ]
job_info[ 'area' ] = city_area.split ('-')[ 1 ] #城市下面的区域
职位详情抓取以及无用信息标签、外链标签的处理
job_des_tag = soup.find ('div', class_="bmsg job_msg inbox")
parser = HTMLParser.HTMLParser ()
node = parser.unescape (job_des_tag)
job_belong_tag = node.find ('div', class_="mt10")
if job_belong_tag:
job_belong_tag.decompose () # 去除包含工作类别、关键字等无用信息标签
share_tag = node.find ('div', class_="share")
share_tag.decompose () # 去除分享外链的标签
job_info[ 'job_des' ] = node.text
数据入库
def insert_mysql(job_info):
"""
#数据插入mysql数据库
:param job_info:
:return:
"""
# lock.acquire()
keys = ','.join (job_info.keys ())
values = ','.join ([ '%s' ] * len (job_info))
sql = 'INSERT INTO ntf_tyc_com_job({keys}) values({values})'.format (keys=keys, values=values)
db2.ping (reconnect=True)
try:
if cursor2.execute (sql, tuple (job_info.values ())):
print 'Data insert Succesful'
db2.commit ()
except:
print "Data insert Failed"
db2.rollback ()
db2.close ()
程序每日对前程无忧会有100W+的访问,前几日每日数据库更新数据量为10W+
程序加速
多线程加速
sql = 'SELECT com_name,com_id FROM abc_company_top500 WHERE id <= 500'
db.ping (reconnect=True)
cursor.execute (sql)
rowQueue = Queue(500)
rows = cursor.fetchall ()
for row in rows:
rowQueue.put(row)
threadcrawl = []
while True:
if threading.active_count() < 10:
try:
t = threading.Thread (target=get_page_url, args=(rowQueue.get(False),))
t.setDaemon (True)
threadcrawl.append(t)
t.start ();
except:
pass
for thread in threadcrawl:
thread.join()
写到这里我才发现这版代码是初代代码,不是最终的代码,最终的挂到服务器上的代码留上家公司了没copy下来,这版代码还是有点问题,多线程对于python的计算型的指令并不能明显提速,爬虫程序里的多线程应该写在I/O密集操作的部分,比如数据库的插入部分。记得终版代码里就是将多线程写在数据库的插入部分,开了8-10条线程、速度提高了6-8倍。其实还可以写多进程、协程提速的,想想当时大三,技术真是菜的一批。
数据库查找加速
这里是抓取500的这张数据表的数据,数据量较小。在获取别的公司表数据的时候,一个表几十万,几百万数据。每次从数据库里依次取1000条数据加入迭代器里进行抓取,开始sql查询语句是用的between ...and, 后来发现用分页查询limit start count,在数据表很大的情况下,能够明显提高查询速度。
抓取时间问题
毕竟自己是只有道德的爬虫,把爬虫程序放大服务器上后,为了不给对方服务器造成太大压力(仔细想想应该也没啥压力,对于这类大型的招聘网站,一天几十万几百万的访问量应该也不算啥),在访问量高的白天限速抓取,在访问量低的晚上高速抓取。
最后总结
写个小爬虫程序挺容易,但是当数据量大、页面结构复杂多变的时候就比较麻烦了,既要提高抓取速度,同时也要考虑避免触发反爬机制,如果要将数据抓取全面时,需要考虑很多细节,并且一个个处理掉,否则数据里会出现错误或者纰漏等问题。程序写起来花了2天,但是检查数据,修正细节花了3天。最后才能放心的连接数据库、放到服务器上实现全量+增量抓取。
最后代码奉上: github.com/jiahaoabc/z…
技术比较菜,献丑了,各位大佬见谅
