

mysql聚簇索引和非聚簇索引
这篇文章主要介绍mysql中innodb的聚簇索引和非聚簇索引,那首先我们要先看下聚簇索引和非聚簇索引的概念是什么,是干什么用的.
聚簇索引和非聚簇索引的概念
我们先引用官网上的一段话来看看它们是干嘛的
Every InnoDB table has a special index called the clustered index where the data for the rows is stored. Typically, the clustered index is synonymous with the primary key. To get the best performance from queries, inserts, and other database operations, you must understand how InnoDB uses the clustered index to optimize the most common lookup and DML operations for each table.
When you define a PRIMARY KEY on your table, InnoDB uses it as the clustered index. Define a primary key for each table that you create. If there is no logical unique and non-null column or set of columns, add a new auto-increment column, whose values are filled in automatically.
If you do not define a PRIMARY KEY for your table, MySQL locates the first UNIQUE index where all the key columns are NOT NULL and InnoDB uses it as the clustered index.
If the table has no PRIMARY KEY or suitable UNIQUE index, InnoDB internally generates a hidden clustered index named GEN_CLUST_INDEX on a synthetic column containing row ID values. The rows are ordered by the ID that InnoDB assigns to the rows in such a table. The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in insertion order.
有耐性的朋友可以自己翻译看看,这里咱们大概翻译了一下,总结出上面这段话的意思:
每个InnoDB表都有一个特殊的索引,称为聚簇索引,用于存储行数据。
1.如果创建了一个主键,InnoDB会将其用作聚簇索引(如果主键没有逻辑唯一且非空的列或列集,最好是设置成自动递增的)
2.如果没有为表创建主键,则MySQL会在所有键列都不为NULL的情况下找到第一个UNIQUE索引,InnoDB会将其用作聚集索引
3.如果表没有PRIMARY KEY或合适的UNIQUE索引,则InnoDB在包含行ID值的合成列上内部生成一个名为GEN_CLUST_INDEX的隐藏的聚集索引(隐藏的是看不到的,也就是说不会出现在desc table中,行ID是一个6字节的字段,随着插入新行而单调增加)
从这三种情况来看的话,就是说不管你有没有创建主键,mysql都会给你弄一个聚簇索引给安排上,你创建了就用你设置的主键为聚簇索引,没有创建就给你来个隐藏的.
聚簇索引(也称为主键索引)就是携带了行数据的索引,非聚簇索引就是除了聚簇索引之外的索引.这样说起来可能有点干巴巴的,咱们画个图来理解一下.
假设有一张表test
create table test(
id int primary key,
age int not null,
name varchar(16),
PRIMARY KEY (`id`),
KEY `idx_age` (`age`) USING BTREE,
KEY `idx_name` (`name`) USING BTREE,
)engine=InnoDB;
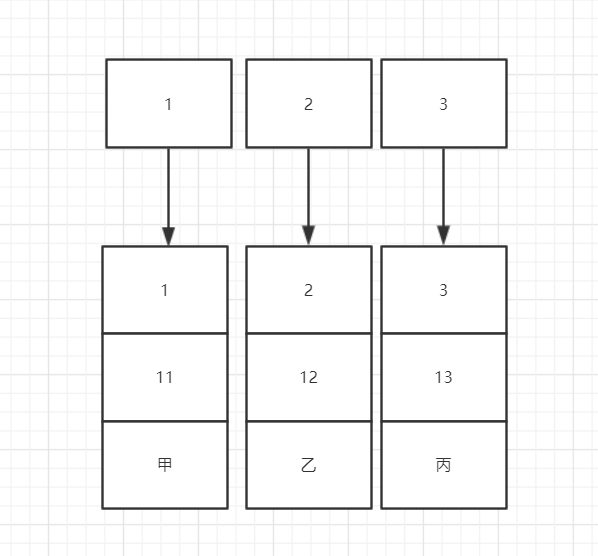
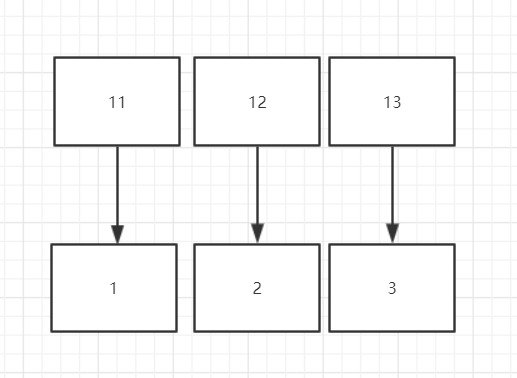
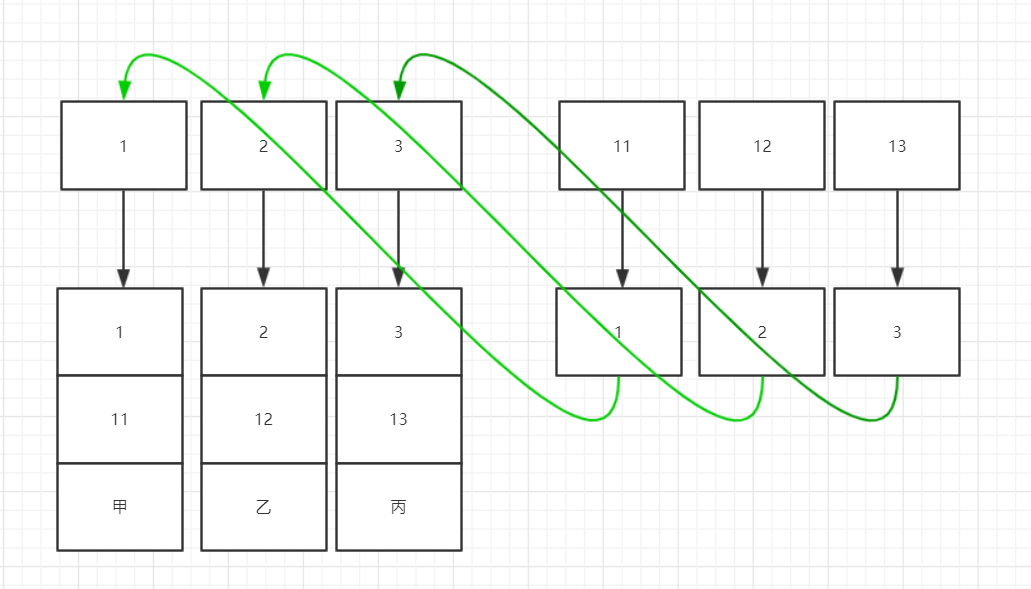
主键是id,然后有两个普通索引idx_age,idx_name(btree类型的索引),使用的是innodb引擎. 我们知道id就是聚簇索引,idx_age,idx_name是非聚簇索引. 现在有三条数据(1,11,'甲'),(2,12,'乙'),(2,13,'丙').那么他们在数据库中存储的形式是,如下: 聚簇索引:
覆盖索引
我们上面说到如果是非聚簇索引的话会需要回表,查询两次,但是如果要查询得字段,数据直接就在索引上是可以不需要回表的.这种索引称为覆盖索引. 比如我们要查询上面的test表中的age和name两个字段.
select id,age,name from test where age = 13;
直接查询的话,会根据age的索引找到id的key,然后再用id去查询出数据.
但是如果我们创建一个(age,name)的联合索引,情况就不一样了.
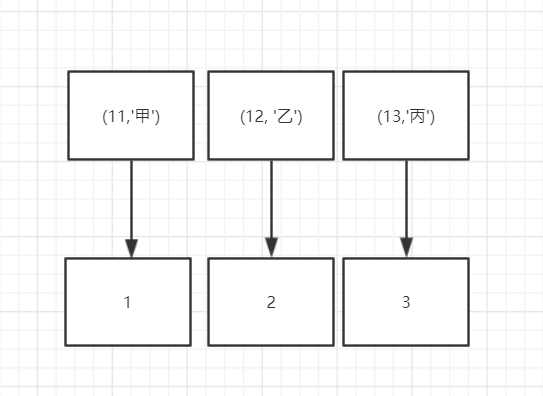
当然这个查询要比较频繁,使用率比较高,毕竟创建索引也是要消耗资源的,实际情况要根据查询频率和索引大小来做出判断.
有联合索引存在的情况下能走覆盖索引当然是最好的,提高了查询效率.
注:还有在某些count聚合函数使用的时候可以使用覆盖索引来优化count,比如说select count(age) from test.
因为age是有索引了,直接使用到的也是age,所以覆盖索引了,无需回表.
总结:
1.聚簇索引和非聚簇索引,查询得时候使用聚簇索引能提高查询效率,尽量避免走非聚簇索引回表的耗时操作
2.覆盖索引能提高查询效率,主要是避免了回表的操作,查询得时候根据具体情况建立合适的索引走覆盖索引提高查询速度
参考资料:
1.dev.mysql.com/doc/refman/…
2.mp.weixin.qq.com/s/y0pjtNUZh…
