背景
传统项目数据集中存储在单节点数据库中,在性能、可用性、运维性上都存在诸多的不便。
从性能上来说,当数据量达到一定程度后,数据库的性能将会降低,即使增加了索引也不能提高性能,因为大多数关系型数据库的索引采用B+数结构,当数据达到阈值时,树的高度增加后,IO次数增加一样会导致性能降低,在高并发情况下,完全不够看。
从可用性来说,单一节点如果遇到宕机的情况,系统就不可用,风险极高。
从运维上来说,当数据量达到一定程度时,DBA对于数据库的备份和恢复的时间都将随着节点数据量的增加而增加。
数据分片是以某种纬度将原本存储单一节点中的数据保存到多个节点中以达到提高系统性能和可用性的效果。数据分片的有效手段是对关系型数据库进行分库分表。分库和分表能有效防止因为数据量达到阈值导致的性能瓶颈,分库还能分散单点的访问量,分表虽然无法缓解数据库性能,但是能尽量将分布式事务转化为本地事务。
垂直分片又称业务分片,表示根据业务划分成不同的库,每个表也根据业务划分到相对应的库中,这样虽然缓解了数据量和访问量带来的问题,但是仍无法解决单点的性能瓶颈问题。
水平分片表示根据表中字段以某种策略进行分片,将数据分散保存到不同的库或表中,可以有效解决单点的性能瓶颈问题。
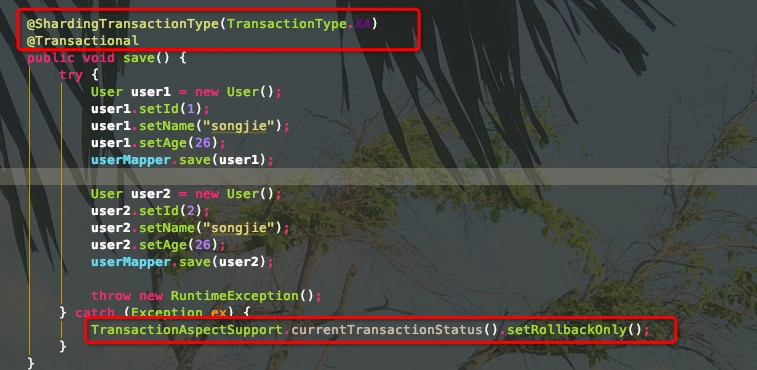
数据分片虽然可以解决性能瓶颈、可用性的问题,但是也引入了新的问题。面对散落的多个库多个表,对于操作数据库也是非常麻烦的,需要确定在某个库以及某个表中,以及在查询时可能导致分页、排序等问题,最重要的是存在分布式事务问题。
概念&功能
核心概念
分片键
用于数据库分片的字段,根据字段以某种策略进行分片。sql查询时如果没有该字段,将进行全量路由,性能低下。
分片算法
- 精确分片算法PreciseShardingAlgorithm,用于处理单一键分片的=或in的场景
- 范围分片算法RangeShardingAlgorithm,用于处理单一键分片的between and的场景
- 复合分片算法ComplexKeysShardingAlgorithm,用于处理多键分片的场景
- hint分片算法HintShardingAlgorithm,用于处理hint行分片的算法,表示分片字段非sql语句,由外置条件决定
分片策略,包括分片键和分片算法
- 标准分片策略StandardShardingStrategy,提供sql语句中=、in或between and的分片支持。属于单一键分片,提供PreciseShardingAlgorithm、RangeShardingAlgorithm算法
- 复合分片策略ComplexShardingStrategy,提供ComplexKeysShardingAlgorithm算法,处理多键分片场景
- 行表达式分片策略InlineShardingStrategy,仅支持单一键分片,提供=、in分片操作支持。如:
t_user_$->{u_id % 8}表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7 - Hint分片策略HintShardingStrategy
- 无分片策略NoneShardingStrategy
分片策略配置包括数据源DatabaseShardingStrategy、数据表TableShardingStrategy两个纬度展开配置。

原理解析
解析引擎
- 词法解析:按照顺序将sql语句解析成N个原子词法Token,Token包括标记类型、字面值和结束的位置。并根据不同数据库提供的字典,归类为关键词、表达式、字面量和操作符
- 语法解析: 提取上下文,标记需要改写的sql部分。供分片使用的上下文包括表信息table、查询项selectItems、分片条件sharding condition、分组项groupbyItems、排序项orderbyItems、分页项Limititems
路由引擎——根据上下文(库和表信息)和分片策略,生成路由路径
- 直接路由:在只分库不分表的前提下,直接设置Hint分片方式
- 标准路由:用于没有关联查询或仅包含绑定表关系的关联查询sql。当分片运算符是=号时,将落入单库;当是between或in时,可能落入多个库表
- 笛卡尔路由:当存在多表关联查询或者无绑定关系表关联查询,将按照所有情况进行处理
- 广播路由:当查询条件中不存在分片字段
改写引擎——开发中书写的面向逻辑库的sql语句是无法执行,需要根据实际库的情况改写成真实库才能执行
- 标志符改写,包括表名称、索引名称
- 补列,面对group by、order by如果返回字段中缺少字段,将自动补列,因为在合并数据的时候需要用到
- 分页修正,多数据源分页与单库分页是有区别的,多数据源的情况下,取limit后的数据再进行合并有的时候是无法获取正确结果的;需要从0开始,所以偏移量越靠后,效率将会越低;解决方法:1、建立索引 2、在分页时使用上次分页最后一条数据的id来作为查询条件
执行引擎——将路由和改写后的sql发送到底层数据库执行
归并引擎——将多数据源返回的数据结果集,合并成正确的结果集返回给客户端
分库分表

主从分离

分布式事务