

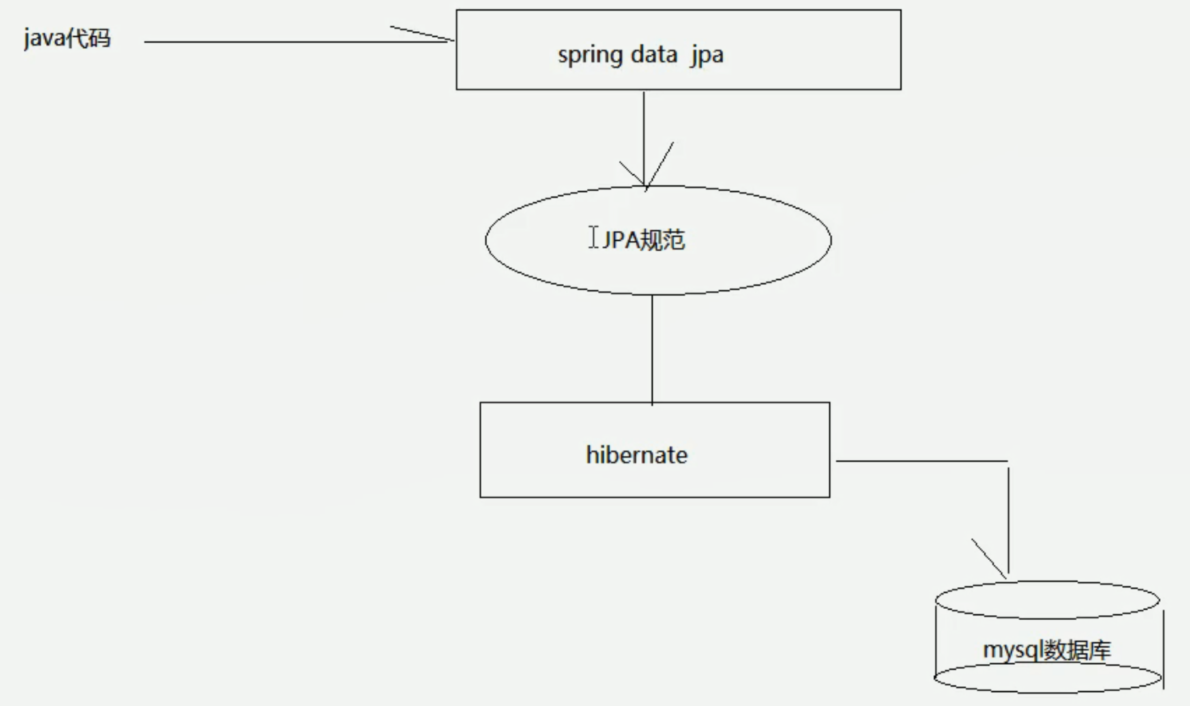
一、SpringDataJpaSpring Data JPA
让我们解脱了DA0层的操作,基本上所有CRUD都可以依赖于它来实现,在实际的工作工程中,推荐使用Spring Data JPA+ORM(如:hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦。
把JPA规范的代码封装起来,真正进行查询的还是hibernate或mybatis >>(封装了jdbc操作),然后进行查询或操作数据库。
二、SpringDataJpa入门操作(搭建环境)
创建工程,导入坐标
项目所需的依赖坐标配置Spring的配置文件
1 <!--创建entityManagerFactory对象交给Spring容器管理-->
2 <bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"> (权限定位类名)
3 <property name="dataSource" ref="dataSource"/> (依赖注入)
4 <property name="packagesToScan " value="cn.itcast.domain"/> (配置的扫描的包,实体类所在的包)
5 <property name="persistenceProvider"> (JPA的实现厂家)
6 <bean class="org.hibernate.jpa.HibernatePersistenceProvider"/>
7 </property>
8
9 <!--jpa的供应商适配器-->
10 <property name="jpaVendorAdapter">
11 <bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
12 <!--配置是否自动创建数据库表-->
13 <property name="generateDdl" value="false"/>
14 <!--指定数据库类型-->
15 <property name="database" value="MYSQL"/>
16 <!--数据库方言:支持的特有语法(不同数据库有不同的语法)-->
17 <property name="databasePlatform" value="org.hibernate.dialect.MySQLDialect"/>
18 <!--是否显示sql-->
19 <property name="showSql" value="true"/>
20 </bean>
21 </property>
22
23 <!--jpa的方言 :高级特性(配置了谁就拥有了谁的高级特性)-->
24 <property name="jpaDialect">
25 <bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect"></bean>
26 </property>
27 </bean>
28 <!--2.创建数据库连接池-->
29 <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
30 <property name="user" value="root"></property>
31 <property name="password" value="123456"></property>
32 <property name="jdbcUrl" value="jdbc:mysq1:///jpa"></property>
33 <property name="driverClass" value="com.mysql.jdbc.Driver"></property>
34 </bean>
35 (以下的不需要特别记忆)>>>
36 <!--3.整合spring dataJpa-->
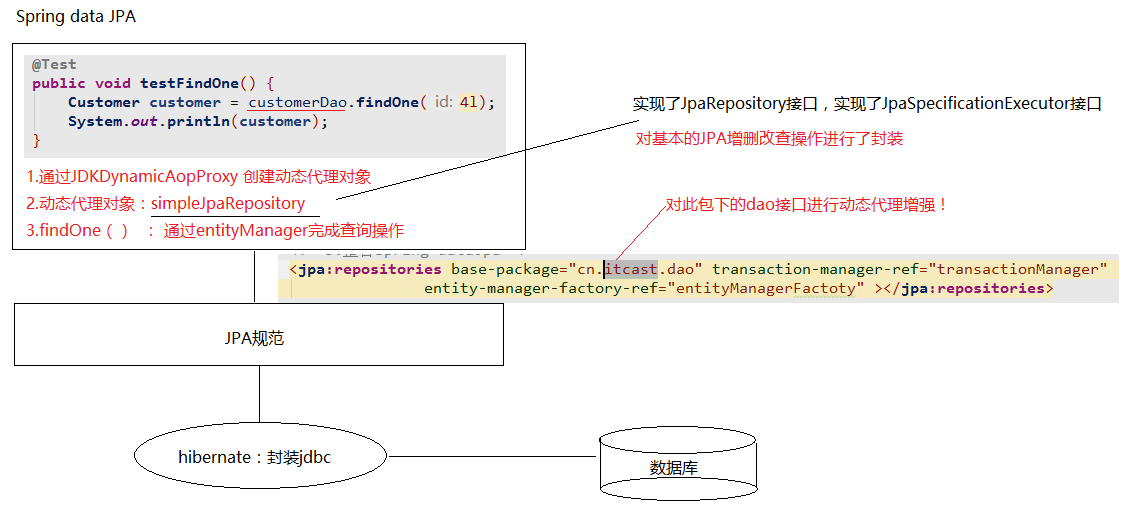
37 <jpa:repositories base-package="cn.itcast.dao" transaction-manager-ref="transactionManager"
38 entity-manager-factory-ref="entityManagerFactory"></jpa:repositories>
39 <!--4.配置事务管理器-->
40 <bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
41 <property name="entityManagerFactory" ref="entityManagerFactory"></property>
42 </bean>
43 <!--5.声明式事务-->
44 <!--6.配置 包扫描-->
45 <context:component-scan base-package="cn.itcast"></context:component-scan>
46 </beans>三、编写符合SpringDataJpa规范的dao层接口
1 package cn.itcast.dao;
2
3 import cn.itcast.domain.Customer;
4
5 import org.springframework.data.jpa.repository.JpaRepository;
6 import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
7 /**
8 * 符合springDataJpa的dao层接口规范
9 * JpaRepository<操作的实体类类型,实体类中主键属性的类型) >>>封装了基本的CRUD操作
10 * JpaSpecificationExecutor<操作的实体类类型> >>>封装了复杂查询()
11 */
12 public interface CustomerDao extends JpaRepository<Customer, Long>, JpaSpecificationExecutor<Customer> {}
四、完成客户的增删改查操作
根据id查询
- findOne
em.find() 立即加载
- getOne
@Transactional:保证getOne正常运行
em.getReference() 延迟加载 >>返回的是一个客户的动态代理对象,什么时候用、什么时候查询
1 @Test
2 public void testFindOne() {
3 Customer customer = customerDao.findOne(3l);
4 System.out.println(customer);
5 }保存和更新(sava)
- 如果没有id主键属性:>> 保存
1 @Test
2 public void testSave() {
3 Customer customer = new Customer();
4 customer.setCustname("黑马程序员");
5 customer.setCustaddress("北京");
6 customer.setCustindustry("IT教育");
7 customerDao.save(customer);
8 }- 存在id主键属性: >> 根据id查询数据,更新数据
1 @Test
2 public void testUpdate() {
3 Customer customer = new Customer();
4 customer.setCustid(1l);
5 customer.setCustname("播客");
6 customer.setCustindustry("黑马程序员很厉害");
7 customerDao.save(customer);
8 }
根据id删除(delete)
1 @Test
2 public void testDelete() {
3 Customer customer = new Customer();
4 customerDao.delete(1l);
5 }
查询所有客户(findAll)
1 @Test
2 public void findAll(){
3 List<Customer> list = customerDao.findAll();
4 for (Customer customer : list) {
5 System.out.println(customer);
6 }
五、SpringDataJpa的运行过程和原理剖析
1. 通过JdkDynamicAopProxy的 invoke 方法创建了一个动态代理对象
2. simpleJpaRepository当中封装了 JPA的操作(借助JPA的api完成数据库的CRUD)
3. 通过 hibernate完成数据库操作(封装了jdbc)
六、复杂查询
借助接口中的定义好的方法完成查询
findone(id):根据id查询
测试统计查询:查询客户的总数量
1 @Test
2 public void testdount() {
3 long count = customerDao.count();//查询全部的客户数量System.out.println(count);
4 System.out.println(count);
5 }测试:判断id为3的客户是否存在
- 可以查询以下id为3的客户
如果值为空,代表不存在,如果不为空,代表存在
- 判断数据库中id为3的客户的数量
如果数量为0,代表不存在(false),如果大于0,代表存在(true)
1 @Test
2 public void testExists() {
3 boolean exists = customerDao.exists(3l);
4 System.out.println(exists);
5 }
jpql的查询方式
jpql:jpa query language( jpq查询语言 )
特点:语法或关键字和sql语句类似
查询的是类和类中的属性
需要将JPQL语句配置到接口方法上
1 .特有的查询:需要在dao接口上配置方法
2. 在新添加的方法上,使用注解的形式配置jpql查询语句
3. 注解:@Query
案例:根据客户名称查询名称 >> 使用Jpql的形式查询
CustomerDao
1 public interface CustomerDao extends JpaRepository<Customer, Long>, JpaSpecificationExecutor<Customer> {
2 /**
3 * 案例:根据客户名称查询名称
4 * 使用Jpql的形式查询
5 * jpql: from Customer where custName = ?
6 */
7 @Query(value = "from Customer where custname = ?")
8 public Customer findJpql(String custname);
9 }
JpqlTest
1 @Test
2 public void testFindJpql(){
3 Customer customer = customerDao.findJpql("传智");
4 System.out.println(customer);
5 }
案例:根据客户名称和客户id查询客户 >> 使用Jpql的形式查询
- 对于多个占位符参数: 赋值的时候,默认的情况下,占位符的位置需要和方法参数中的位置保持一致 [ custName >> String name custId >> Long id ]
@Query(value="from Customer where custName=? and custId=?")
public Customer findCustNameAndId (String name , Long id );
- 也可以指定占位符参数的位置 : ?索引的方式,指定此占位的取值来源
@Query (value=" from Customer where custName = ?2 and custId = ?1 ")
public Customer findCustNameAndId ( Long id , String name );
CustomerDao
1 @Query(value = "from Customer where custname = ? and custid = ?")
2 public Customer findCustNameAndId(String custname, long id);JpqlTest
1 @Test
2 public void testCustNameAndId(){
3 Customer customer = customerDao.findCustNameAndId("黑马",2l);
4 System.out.println(customer);
5 }使用jpql完成更新操作案例:根据id更新更新2号客户的名称,将名称改为“黑马程序员”
CustomerDao
1 @Query(value = " update Customer set custname = ?2 where custid = ?1 ") //代表的是进行查询
2 @Modifying //当前执行的是一个更新操作
3 //更新不需要返回值 选择void
4 public void UpdateCustomer( long custid,String custname);JpqlTest
1 @Test
2 @Transactional //添加对事务的支持
3 @Rollback(value = false) //设置是否自动回滚
4 public void testUpdateCustomer(){
5 customerDao.UpdateCustomer(2l,"黑马程序员");
6 }执行结束后,默认回滚事务,可以通过@Rollback 设置是否自动回滚 >> false | true
SQL查询方式.
1 .特有的查询:需要在dao接口上配置方法
2. 在新添加的方法上,使用注解的形式配置sql查询语句
3. 注解:@Query
value: jsql | sql
nativeQuery : fals(使用jpql查询) l true(使用本地查询:sql查询)
CustomerDao
1 @Query(value = "select * from cst_customer",nativeQuery = true)
2 public List<Object[]>findSql();JpqlTest
1 @Test
2 public void testfindSql(){
3 List<Object[]> list = customerDao.findSql();
4 for (Object[] obj : list) {
5 System.out.println(Arrays.toString(obj));//每一个里面都还是object数组,所以需要借助Arrays.toString()方法打印数组
6 }方法命名规则查询
>1: findBy +属性名(首字母大写)
public Customer findByCustname(String custname);
1 @Test
2 public void testNaming(){
3 Customer customer = customerDao.findByCustname("传智");
4 System.out.println(customer);
5 }
>2: findBy + 属性名(首字母大写)+ “查询方式”
public List<Customer> findByCustnameLike(String custname);1 @Test
2 public void testfindByCustnameLike(){
3 List<Customer> list = customerDao.findByCustnameLike("黑马%");
4 for (Customer customer : list) {
5 System.out.println(customer);
6 } }
>3: findBy + 属性名(首字母大写)+ “查询方式” + “多条件的连接符(and | or)” + 属性名 + “查询方式”
使用客户名称模糊匹配和客户所属行业精准匹配的查询
public List<Customer> findByCustnameLikeAndCustindustry(String custname, String custindustry); //结果可能是一个或多个,所以选择List<Customer>1 @Test
2 public void testFindByCustnameLikeAndCustindustry(){
3 List<Customer> list = customerDao.findByCustnameLikeAndCustindustry("黑马%","it教育");
4 for (Customer customer : list) {
5 System.out.println(customer);
6 } }
七、Specifications动态查询
- root :查询的根对象(查询的任何属性都可以从根对象中获取)
- cirteriaQuery:顶层查询对象,自定义查询方式(了解,一般不用)
- cirteriaBuilder:查询的构造器,封装了很多查询条件
public Predicate toPredicate(Root<Customer> root , CriteriaQuery<?> query , CriteriaBuilder cb) { } //封装查询条件
查询客户名为 “传智” 的客户
1 @Test
2 public void testSpec() {
实现Specification接口( 提供泛型 :查询的对象属性)
3 Specification<Customer> spec = new Specification<Customer>() {
实现toPredicate方法(构造查询条件)
4 public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
5 //1.获取比较的属性
6 Path<Object> custname = root.get("custname");
7 //2.构造查询条件
8 Predicate predicate = cb.equal(custname, "传智"); //进行精准的匹配(custname:比较的属性 , “传智”:比较的属性取值)
9 return predicate;
10 }};
11 Customer customer = customerDao.findOne(spec);
12 System.out.println(customer);
13 }查询客户名为 “黑马2” 并且行业为 "it教育" 的的客户
1 @Test
2 public void testSpec1() {
3 Specification<Customer> spec = new Specification<Customer>() {
4 public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
5 //1.获取比较的属性
6 Path<Object> custname = root.get("custname");
7 Path<Object> custindustry = root.get("custindustry");
8 //2.构造查询条件
9 Predicate p1 = cb.equal(custname, "黑马2");
10 Predicate p2 = cb.equal(custindustry, "it教育");
and(与关系):满足条件1并且满足条件2 or(或关系):满足条件1或满足条件2
11 Predicate and = cb.and(p1, p2);
12 return and;
13 }
14 };
15 Customer customer = customerDao.findOne(spec);
16 System.out.println(customer);
17 }
案例:完成根据客户名称的模糊匹配,返回客户列表 >>客户名称以 “传智播客” 开头
equal:直接得到 path对象(属性),然后进行比较即可
gt(大于),lt(小于),ge(大于等于),le(小于等于),like:得到path对象,根据path指定比较的参数类型,再去进行比较
指定参数类型:path.as(类型的字节码对象)
1 @Test
2 public void testSpec2() {
3 Specification<Customer> spec = new Specification<Customer>() {
4 public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
5 Path<Object> custname = root.get("custname"); //查询属性:客户名
6 Predicate predicate = cb.like(custname.as(String.class), "传智播客%"); //查询方式:模糊匹配
7 return predicate;
8 }
9 };
10 List<Customer> list = customerDao.findAll(spec);
11 for (Customer customer : list) {
12 System.out.println(customer);
13 } }添加排序 >>创建排序对象,需要调用构造方法实例化sort对象
第一个参数:排序的顺序(倒序,正序)
- Sort.Direction.DESC:倒序
- Sort.Direction.ASC:升序
第二个参数:排序的属性名称
1 Sort sort = new Sort(Sort.Direction.DESC, "custid");
2 List<Customer> list = customerDao.findAll(spec, sort);
分页查询
- 不带参数的分页查询
创建PageRequest的过程中,需要调用他的构造方法传入两个参数
第一个参数:当前查询的页数(从e开始)
第二个参数:每页查询的数量
1 @Test
2 public void testSpec3() {
3 Specification spec = null; //不带参数
4 Pageable pageable = new PageRequest(0, 2);
5 //分页查询
6 Page<Customer> page = customerDao.findAll(null, pageable);
7 System.out.println(page.getContent());//得到数据集合列表
8 System.out.println(page.getTotalElements());//得到总条数
9 System.out.println(page.getTotalPages());//得到总页数
10 }
- 带参数分页查询
1 @Test
2 public void testSpec4() {
3 Specification spec = new Specification() {
4 public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder criteriaBuilder) {
5 Path custname = root.get("custname");
6 Predicate predicate = criteriaBuilder.equal(custname, "传智播客");
7 return predicate;
8 }};
9 Pageable pageable = new PageRequest(0, 2);
10 //分页查询
11 Page<Customer> page = customerDao.findAll(spec, pageable);
12 System.out.println(page.getContent());//得到数据集合列表
13 System.out.println(page.getTotalElements());//得到总条数
14 System.out.println(page.getTotalPages());//得到总页数
15 }最后
欢迎大家有兴趣的可以关注我的公众号【java小瓜哥的分享平台】,文章都会在里面更新,还有各种java的资料都是免费分享的。
