

上周我突然意识到,我在grafana上写的 sql 语句存在多处硬编码。这篇笔记将记录如何实现没有硬编码的 sql 语句,以及自学编程过程中如何应对自己的笨拙代码和难题不断的状况。
1、有效但粗笨的硬编码
所谓硬编码,大意是指代码中出现很多具体的取值,每个取值都是手动赋值的。比如:
-- 达成某个成就的用户数
select
count(user_id) as 用户数
from
achivement_table
where
achivement_name= '牛刀小试'
以我家产品 xue.cn 的成就系统为例,我们首个版本仅有10个成就,我要拷贝粘贴修改成就名称达10次。最近成就升级到V2版本,有17个成就,未来还会有更多成就。再比如习题和章节,每本书的章节数和习题数,都是几十个起。至于统计每本书的阅读用户数,每个章节的留言数,每个成就的达成用户数……这类实现太频繁了。
如果全部采用硬编码,我意识到这将低效粗笨。
在初学编程时,你我总会写出一些低效但生效的代码。随着编程水平提升或需求变得复杂,我们将有机会迭代自己的代码。迭代是好事,但这不意味着之前的低效但有效的代码是坏事。——**接纳自己早期的笨拙,并追求持续的进步。咱们不需要为自己初学阶段的代码感到不好意思或羞愧,而是要视之为提升的机会。**这个心态令我在自学编程的路上几乎无所畏惧。
2、知道,但用时忘
如何实现代码自动获取每个取值,并按该值分别统计呢?我搜索到一些代码,却看不懂:
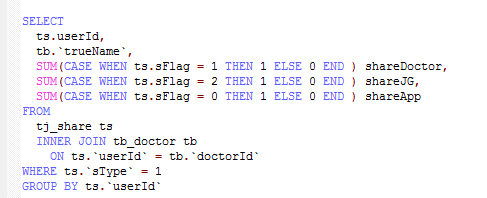
不得已,我准备好问题描述,并发红包在编程学习群里请教。群友给出的答案让我哭笑不得:
特么这方法我不是会吗!?鬼打墙啦。
这种现象在初学技能时,是不是挺常见的!?知道,但不熟练。知道知识点,但实战时可能想不起来。或者知道某一种实战情境,换到其它实战情境就忘了……嗯,本质上还是重复的不够,熟练度不行啊。
既然是我已知的知识点,立即实操吧。
情境A:字段取值范围在同一表格
想要统计的原数据,和该字段的所有取值范围,在同一张数据表时,代码简单如下。
-- 所有成就的完成用户数
select
achivement_name as 成就名称,
count(user_id) as 用户数
from
achivement_table
group by
成就名称
order by
成就名称
情境B:字段取值范围在另一表格
想要统计的原数据,和该字段的所有取值范围,不在同一张数据表时,代码仅稍微复杂一点点。
-- 所有成就的完成用户数
select
achivements.name as 成就名称,
count(achivement_event.user_id) as 用户数
from
achivement_event,achivements
where
achivement_event.name = achivements.name
group by
成就名称
order by
成就名称
3、解决一个难题,新的困惑到来
硬编码的问题现在倒是解决了,但实现数据可视化时,又有新的情况产生。
之前的硬编码风格,在 grafana 上通过 add query 完成,该操作是新增数据列,使得数据结果是一行多列,每个成就名就是一列。
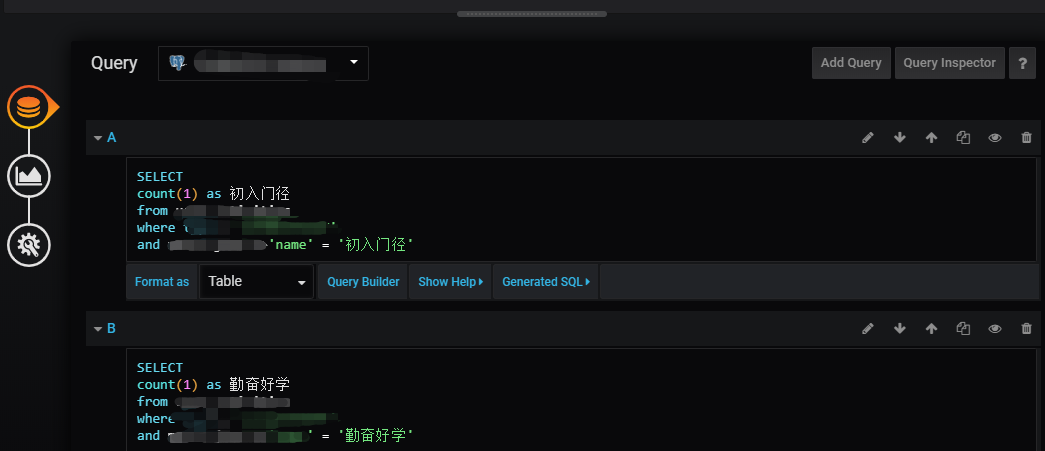

这种数据,用 grafana 的 bar gauge 图表类型展示效果很不错。

之后没有硬编码的sql语句,得到的数据结果是多行2列,首列是成就名,次列是用户数。相当于之前数据结果的倒置。
行列倒置在 python pandas中,就是对dataframe数据一个T操作而已。但在 grafana 上如何灵活地操作行列,我还有不少困惑要解决。——这并非我的不足,这是我将要提升的机会,对不?
小结
在这篇笔记中,我不仅记录了自己如何完成按某个字段的取值范围进行统计的需求,既有早期的硬编码风格,也有升级版的语句。我还分享了自己如何看待初学编程时的笨拙代码,如何应对一个难题接着一个难题的编程自学过程。希望我的笔记,带给你启发和力量。
