随着人口红利的慢慢削减,互联网产品的厮杀愈加激烈,大家开始看好下沉市场的潜力,拼多多,趣头条等厂商通过拉新奖励,购物优惠等政策率先抢占用户,壮大起来。其他各厂商也紧随其后,纷纷推出自己产品的极速版,如今日头条极速版,腾讯新闻极速版等,也通过拉新奖励,阅读奖励等政策来吸引用户。
对于这类APP,实时风控是必不可少的,一个比较常见的实时风控场景就是防刷接口作弊。刷接口是黑产的一种作弊手段,APP上的各种操作,一般都会对应后台的某个接口,用户操作APP数据就会通过接口上报到后台,但如果黑产通过破解获取到了APP的新增用户接口,那他们就能跳过登陆APP步骤直接调后台接口构造虚假数据牟利了。对于这类业务,我们可以通过Flink + Redis来实现实时防刷接口的功能。数据流图如下所示: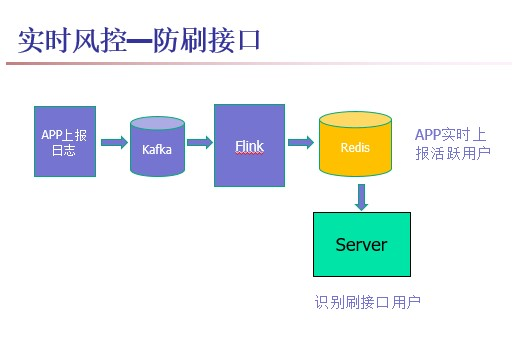 刷接口作弊一般是越过登陆APP操作,直接调Server端的接口发数据,这些用户在APP的上报日志里面就不存在,那我们可以通过Flink将APP实时上报上来的新增用户写入Redis中,然后Server端将接口上报上来的用户与Redis里的用户进行比对,如果不在Redis里面则判为刷接口用户。
刷接口作弊一般是越过登陆APP操作,直接调Server端的接口发数据,这些用户在APP的上报日志里面就不存在,那我们可以通过Flink将APP实时上报上来的新增用户写入Redis中,然后Server端将接口上报上来的用户与Redis里的用户进行比对,如果不在Redis里面则判为刷接口用户。
对于这个需求,得要求实时计算引擎能达到毫秒级延迟,否则会造成用户的误判和影响用户体验。为此我们选择了Flink作为实时计算引擎。
主要代码逻辑如下:
//配置flink运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//val env = StreamExecutionEnvironment.createLocalEnvironment()
env.enableCheckpointing(1000 * 60 * 5)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE)
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(1000 * 60 * 3)
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
env.setStateBackend(new FsStateBackend(checkPointPath))
env.getConfig.setLatencyTrackingInterval(1000)
env.getConfig.registerTypeWithKryoSerializer(classOf[Log], classOf[ProtobufSerializer])
env.setStreamTimeCharacteristic(EventTime)
env.setParallelism(parallel)
env.getConfig.setLatencyTrackingInterval(1000)
//kafka source,实时消费kafka中日志解析出用户id
val stream = env.addSource(new FlinkKafkaConsumer010[Array[Log]](topic, new LogDeserializationSchema(), properties))
val data = stream.flatMap(x => x)
.map(log =>{
val userid = log.getUid.getUuid
val current_time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date())
(userid,current_time)
}).filter(record=>{
val userid = record._1
var flag = false
if(userid != null && !"".equals(userid)){
flag = true
}
flag
})
//redis sink,将APP上报日志的用户id写入redis供server端匹配
data.addSink(new RedisSink[(String, String)](getJedisClusterConfig, new RedisSinkMapper))
env.execute("newsinfo_active_userid_to_redis")其中比较重要的几点:
1 构造kafka source
val stream = env.addSource(new FlinkKafkaConsumer010[Array[Log]](topic, new LogDeserializationSchema(), properties))一般APP上报的都是序列化的数据,我们需要定义反序列化方法,LogDeserializationSchema 是一个protobuf类型的反序列化方法。
//将kafka中的数据解析为google protobuf 的Log,一个message可能包含多条Log
class LogDeserializationSchema extends AbstractDeserializationSchema[Array[Log]] {
override def deserialize(message: Array[Byte]): Array[Log] = {
val data = ArrayBuffer[Log]()
val input = new ByteArrayInputStream(message)
while (input.available() > 0) {
try {
data += Log.parseDelimitedFrom(input)
} catch {
case _: Throwable =>
}
}
input.close()
data.toArray
}
}2 redis sink
这里用的是网上开源的flink-connector-redis依赖库。更多相关内容见:http://bahir.apache.org/docs/flink/current/flink-streaming-redis
Maven依赖如下
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1-SNAPSHOT</version>
</dependency>Redis Sink 提供用于向Redis发送数据的接口的类。接收器可以使用三种不同的方法与不同类型的Redis环境进行通信:单Redis服务器Redis集群Redis Sentinel
Redis Sink 核心类是 RedisMappe 是一个接口,使用时我们要编写自己的redis操作类实现这个接口中的三个方法,如下所示:
class RedisExampleMapper extends RedisMapper[(String, String)]{
override def getCommandDescription: RedisCommandDescription = {
new RedisCommandDescription(RedisCommand.HSET, "HASH_NAME")
}
override def getKeyFromData(data: (String, String)): String = data._1
override def getValueFromData(data: (String, String)): String = data._2
}
val conf = new FlinkJedisPoolConfig.Builder().setHost("127.0.0.1").build()
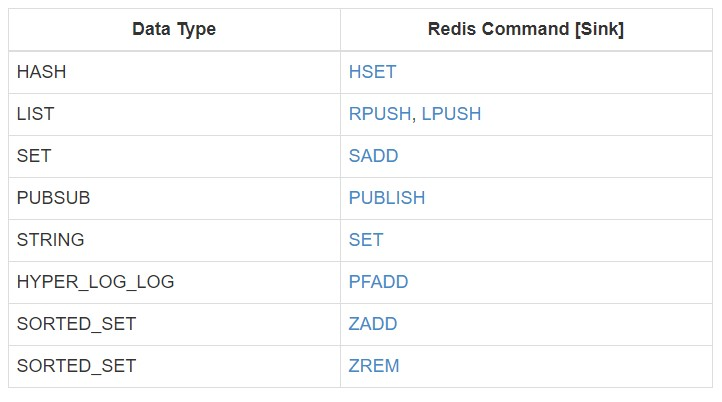
stream.addSink(new RedisSink[(String, String)](conf, new RedisExampleMapper))使用RedisCommand设置数据结构类型时和redis结构对应关系。
以上我们利用 Flink + Redis 实时了一个基本的实时防刷接口模型。
订阅关注微信公众号《大数据技术进阶》,及时获取更多大数据架构和应用相关技术文章!