

通过一道题进入浏览器事件循环原理:
console.log('script start')
setTimeout(function () {
console.log('setTimeout')
}, 0);
Promise.resolve().then(function () {
console.log('promise1')
}).then(function () {
console.log('promise2')
})
console.log('script end')
可以先试一下,手写出执行结果,然后看完这篇文章以后,在运行一下这段代码,看结果和预期是否一样
单线程
定义
单线程意味着所有的任务需要排队,前一个任务结束,才能够执行后一个任务。如果前一个任务耗时很长,后面一个任务不得不一直等着。
原因
javascript的单线程,与它的用途有关。作为浏览器脚本语言,javascript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定javascript同时有两个线程,一个在添加DOM节点,另外一个是删除DOM节点,那浏览器应该应该以哪个为准,如果在增加一个线程进行管理多个线程,虽然解决了问题,但是增加了复杂度,为什么不使用单线程呢,执行有个先后顺序,某个时间只执行单个事件。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,运行javascript创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个标准并没有改变javascript单线程的本质
浏览器中的Event Loop
事件循环这个名字来源于它往往这么实现:
while(queue.waitForMessage()) {
queue.processNextMessage();
}
这个模型的优势在于它必须处理完一个消息(run to completion),才会处理下一个消息,使程序可追溯性更强。不像C语言可能随时从一个线程切换到另一个线程。但是缺点也在于此,若同步代码阻塞则会影响用户交互
macroTask和microTask
宏队列,macroTask也叫tasks。包含同步任务,和一些异步任务的回调会依次进入macro task queue中,macroTask包含:
- script代码块
- setTimeout
- requestAnimationFrame
- I/O
- UI rendering
微队列, microtask,也叫jobs。另外一些异步任务的回调会依次进入micro task queue,等待后续被调用,这些异步任务包含:
- Promise.then
- MutationObserver
下面是Event Loop的示意图
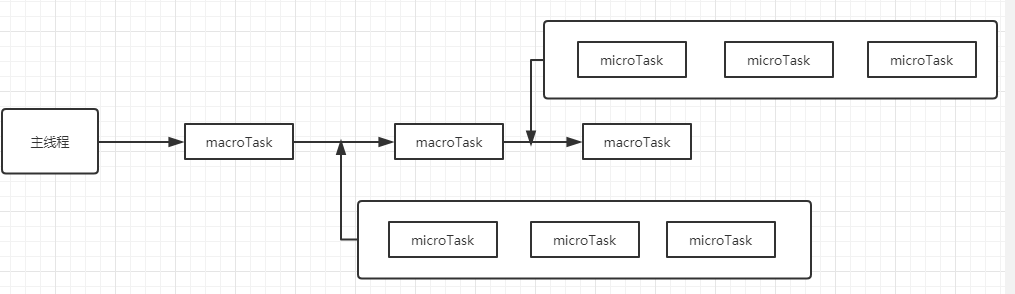
javascript执行的具体流程就是如下:
- 首先执行宏队列中取出第一个,一段
script就是相当于一个macrotask,所以他先会执行同步代码,当遇到例如setTimeout的时候,就会把这个异步任务推送到宏队列队尾中。 - 当前
macrotask执行完成以后,就会从微队列中取出位于头部的异步任务进行执行,然后微队列中任务的长度减一。 - 然后继续从微队列中取出任务,直到整个队列中没有任务。如果在执行微队列任务的过程中,又产生了
microtask,那么会加入整个队列的队尾,也会在当前的周期中执行 - 当微队列的任务为空了,那么就需要执行下一个
macrotask,执行完成以后再执行微队列,以此反复。
总结下来就是不断从task队列中按顺序取task执行,每执行完一个task都会检查microtask是否为空,不让过不为空就执行队列中的所有microtask。然后在取下一个task以此循环
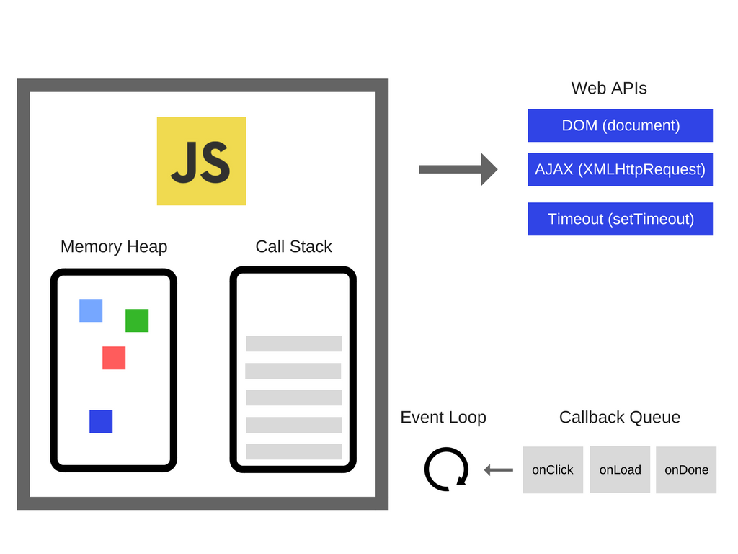
调用栈和任务队列
调用栈是一个栈结构,函数调用会形成一个栈帧。栈帧:调用栈中每个实体被称为栈帧,帧中包含了当前执行函数的参数和局部变量等上下文信息,函数执行完成后,它的执行上下文会从栈中弹出。 下面是调用栈和任务队列的关系:
debugger,结合chrome的call stack进行分析:
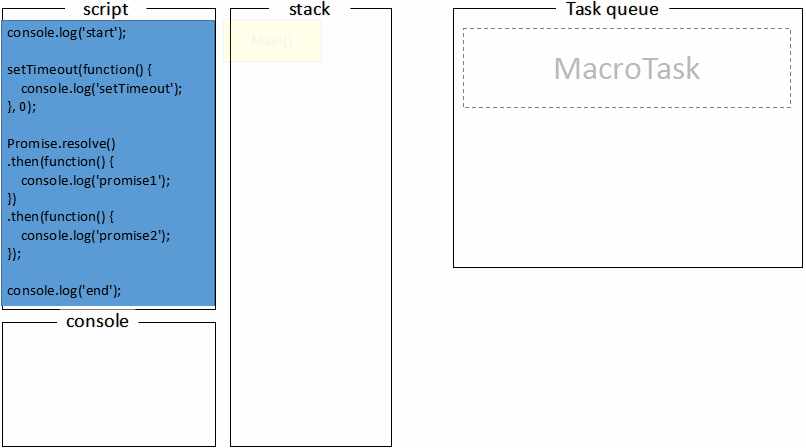
call stack表示调用栈,macroTasks表示宏队列,microTasks表示微队列:
- 首先代码执行之前都是三个队列都是空的:
callStack: []
macroTasks: [main]
microTasks: []
在前面提到,整个代码块就相当于一个macroTask,所以首先向callStack中压入main(),main相当于整个代码块
2. 执行main,输出同步代码结果:
callStack: [main]
macroTasks: []
microTasks: []
在遇到setTimeout和promise的时候会向macroTasks与microTasks中分别推入
3. 此时的三个队列分别是:
callStack: [main]
macroTasks: [setTimeout]
microTasks: [promise]
当这段代码执行完成以后,会输出:
script start
script end
- 当
main执行完成以后,会取microTasks中的任务,放入callStack中,此时的三个队列为:
callStack: [promise]
macroTasks: [setTimeout]
microTask: []
当这个promise执行完成后会输出
promise1
后面又有一个then,在前面提到如果还有microtask就在微队列队尾中加入这个任务,并且在当前tick执行。所以紧接着输出promise2
5. 当前的tick也就完成了,最后在从macroTasks取出task,此时三个队列的状态如下:
callStack: [setTimeout]
macroTasks: []
microTask: []
最后输出的结果就是setTimeout。
所谓的事件循环就是从两个队列中不断取出事件,然后执行,反复循环就是事件循环。经过上面的示例,理解起来是不是比较简单
Event Loop使用
本部分需要对Vue源码有一定的了解,如果不了解,可以跳过。
nextTick原理
Vue内部实现了nextTick函数,传入一个cb函数,这个cb会存储到一个队列中,在下一个tick中触发队列中所有的cb事件。
首先定义一个数组callbacks来存储下一个tick需要执行的任务,pending是一个标志位,保证在下一个tick之前只执行一次。timeFunc是一个函数指针,针对浏览器支持情况,使用不同的方法
function nextTick() {
const callbacks = [];
let pending = false;
let timeFunc
}
function nextTickHandler() {
pending = false;
const copies = callbacks.slice(0)
callbacks.length = 0
for (let i = 0; i < copies.length; i++) {
copies[i]()
}
}
nextTickHandler的作用就是将callbacks存储的函数都调用一遍。下面再来看timeFunc的实现:
if (typeof Promise !== 'undefined') {
timeFunc = () => {
Promise.resolve()
.then(nextTickHandler)
}
} else if (typeof MutationObserver !== 'undefined') {
// ...
} else {
timeFunc = () => {
setTimeout(nextTickHandler, 0)
}
}
优先使用Promise、MutationObserver因为这两个方法的回调函数都会在microtask中执行,他们会比setTimeout更早执行,所以优先使用。下面是MutationObserver的实现:
const counter = 1;
const observer = new MutationObserver(nextTickHandler)
const textNode = document.createTextNode(counter)
observer.observe(textNode, {
characterData: true,
})
timeFunc = () => {
couter = (counter + 1) % 2;
textNode.data = String(counter)
}
每次调用timeFunc,都会更改counter的值,改变DOM的值后,触发observer从而实现回调。
如果上述两种方法都不支持的环境则会使用setTimeout。setTimeout会在下一个tick中执行。为什么使用这种方式,根据HTML Standard,每个task运行完以后,UI都会重新渲染,那么在microtask中完成数据更新,当前task结束后就可以得到最新的UI了,否则就需要等到下一个tick进行数据更新,但是此时已经渲染了两次
Vue的批量异步更新策略
注意:这个部分需要对Vue源码有一定的了解
下面有一个示例,点击按钮,会让count从0增加到1000。如果每次count的修改都会触发DOM的更新,那么DOM都会更新1000次,那手机就卡死了。
<div>{{count}}</div>
<button @click="addCount">click</button>
data () {
return {
count: 0,
}
},
methods: {
addCount() {
for (let i = 0; i < 1000; i++ ){
this.count += 1;
}
}
}
那么Vue是如何避免这种事情的,每次触发某个数据的setter方法后,对应的Watcher对象就会被push进一个队列queue中,Watcher对象用来触发真实DOM的更新。
let id = 0;
class Watcher {
constructor() {
this.id = id++;
}
update() {
console.log('update:' + id);
queueWatcher(this);
}
run() {
console.log('run:' + id);
}
}
当触发setter会触发Watcher对象的update,run方法用来更新页面。
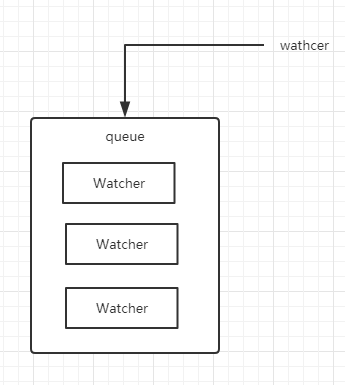
queue中加入属于这个数据的watcher,每个watcher都有专属的id,这样就避免重复添加同一个watcher。waiting是一个标志位,在下一个tick的时候执行flushSchedulerQueue来执行队列queue中所有的watcher对象的run方法
const has = {};
const queue = [];
let waiting = false;
function queueWatcher(watcher) {
const id = watcher.id;
if (has[id] == null) {
queue.push(watcher)
has[id] = true;
}
if (!waiting) {
waiting = true;
nextTick(flushScheulerQueue)
}
}
function flushScheulerQueue() {
for (index = 0; index < queue.length; index++) {
watcher = queue[index]
id = watcher.id;
has[id] = null;
watcher.run();
}
wating = false;
}
这样当一个值多次发生改变时,实际上只会往这个queue队列中加入一个,然后在nextTick中进行回调,遍历queue对页面进行更新,这样也就实现了多次更改data的时候只会更新一次DOM,但是在项目中也需要尽量避免这种多次更改的情况。
例如以下代码:
const watcher1 = new Watcher();
const wather2 = new Watcher();
watcher1.update();
watcher2.update();
watcher2.update();
一个watcher触发了两次update,但是输出结果如下:
update: 1
update: 2
update: 2
run: 1
run: 2
虽然watcher2触发了两次update,但是因为Vue对相同的Watcher进行了过滤,所以在queue中只会存在一个watcher。run方法的调用会在nextTick中调用,也就是先前提到的microtask中进行调用。从而输出了上面的结果
本文讲了js的事件轮询机制,是不是对同步异步了解的更加清晰。学一个知识点最重要的对其进行落地,可以自己多尝试一下,更加深入了解事件轮询机制。github求关注,感谢。
