昨天娱乐圈又又又爆雷了,lixiaolu 和 pg1 的抖音视频疯传网络,看来嫂子就要成内子了。
警告:本教程仅用作学习交流,请勿用作商业盈利,违者后果自负!如本文有侵犯任何组织集团公司的隐私或利益,请告知联系删除!!!
挺好的,这很 pg1 啊

今天我们作为纯正的吃瓜群众,怎么能不来围观下呢,还是到娱乐圣地“微博”搞起,不管它里面到底有多少xujia流量,反正我估计骂人的流量不会太假,啊哈哈哈哈

我们使用的爬取工具还是前面文章提到的微博轮子,具体的使用方法可以查看这里
而我们爬取的微博就是“娱乐有饭”最新发的那个视频,如果你还没看,建议在饭前观看!

我们先来简单看下这篇微博下的盛况吧
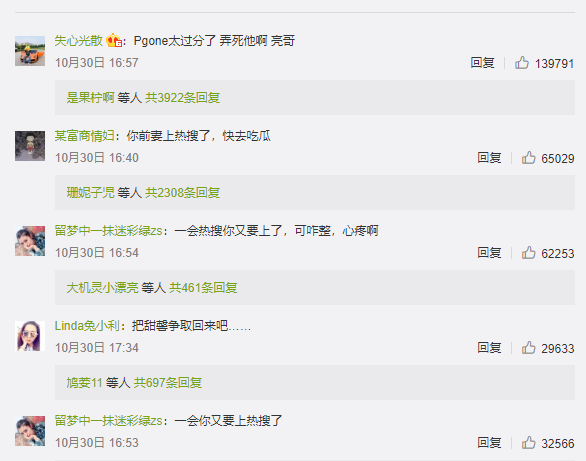
亲情演绎型
哈哈,说过要饭前观看喽
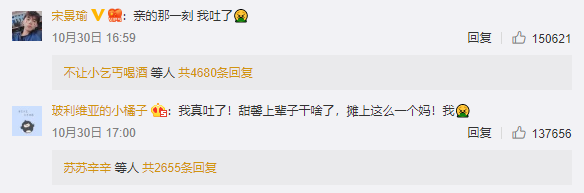
暴躁粗口型

说实在的,出不出娱乐圈和我们瓜民有啥关系?
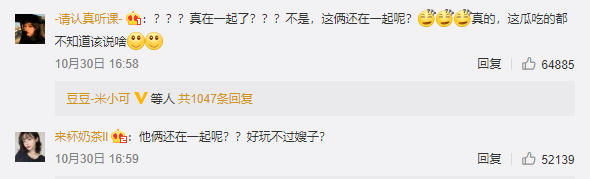
淡定吃瓜型
没事儿,生活那么平淡,不来点瓜怎么过的去呢
诗情画意型

骚年,要是在唐朝,你肯定赛过李太白啊!
最后,一图胜千言,看尽人间百态
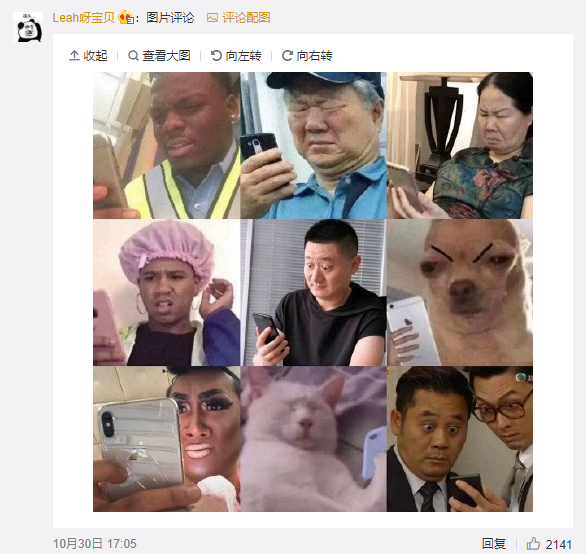
不过这么看,毕竟只能看到一小部分,下面就通过微博轮子,抓取该微博下所有的评论,看看广大群众们的吃瓜能量。
我们通过程序,可以成功抓取对应的评论信息,并得到一个 csv 文件,里面的内容如下

接下来就是通过 jieba 做分词,然后生成词云
import jieba
import pandas as pd
from wordcloud import WordCloud
import numpy as np
from PIL import Image
font = r'C:\Windows\Fonts\FZSTK.TTF'
STOPWORDS = {"回复", }
def wordcloud(file, name, pic=None):
df = pd.read_csv(file, usecols=[1])
df_copy = df.copy()
df_copy['comment'] = df_copy['comment'].apply(lambda x: str(x).split()) # 去掉空格
df_list = df_copy.values.tolist()
comment = jieba.cut(str(df_list), cut_all=False)
words = ' '.join(comment)
img = Image.open(pic)
img_array = np.array(img)
wc = WordCloud(width=2000, height=1800, background_color='white', font_path=font, mask=img_array,
stopwords=STOPWORDS, contour_width=3, contour_color='steelblue')
wc.generate(words)
wc.to_file(name + '.png')
if __name__ == '__main__':
wordcloud("1572486436comment.csv", "lixiaolu2", 'xinsui.jpg')
我们得到词云图如下

可以看到,在评论的高频词汇中,孩子占比还是蛮高的,确实,无论如何孩子都是无辜的,事情到了这个地步,保护好孩子才是最重要的。至于到底是做嫂子还是做内子,who care?
最后我又打开了亮哥的微博,心疼,保重!