

作为业务开发者,对各种技术组件都要有比较扎实的了解,这样在各种复杂的业务面前,才能更好更快制定安全有效的技术方案。所以,本人准备总结一个专栏,解决在各种技术方面一个厉害的、业务开发应该具备什么样的“专业性常识“。文章基于多年大厂一线开发的实际经验、官方文档、个人实验和源码分析;并在个人的思考上进行了总结、提炼和升华。希望能帮到大家
(A) 本文的内容和知识基础
消息中间件丢消息需要补偿方案估计是业务开发在选用queue方案时不可避免的话题,所以首先分析这个问题。丢消息问题也可以称为数据安全问题,或者说消息队列的可靠性问题。(这里学习两个单词:data safety,reliability)。本文以rabbitmq为引子开始讨论这个问题,在之后的几篇文章对比kafka、activeMq,rocketMq和zeroMq,最后在对比的基础上总结一下消息队列丢消息的综合考量因素。
后面内容的理解建立在读者对rabbitmq最最基本概念的理解的基础上(比较深入的话题本文会展开分析比如channel的概念),所以建议没有用过rabbitmq的花半小时时间去官网读rabbitmq的get started部分。文末有汇总所有用到的rabbitmq黑心概念,核心概念本文直接使用英文避免翻译过来造成混淆。
(B)rabbitmq中为啥会丢消息
首先说一下丢消息的根源(1)来核心来自于现实世界的不可靠,来自于(2)rabbimtq消息中间件的设计不如innodb能可靠。所以rabbitmq会在现实世界出现异常的消息重复或者消息丢失。现实世界的不可靠体现在:复杂的网络环境、硬件、容器当然还有开发的错误使用。
所以注意(1)rabbitmq要理解现实世界会出现什么样的异常,在这些异常下(2)rabbitmq的为什么会丢消息,(3)rabbitmq如何解决这种丢消息的方法,(4)其他消息的队列的改进。
(C)rabbitmq中哪些环节会丢消息
Data safety is a joint responsibility of RabbitMQ nodes, publishers and consumers.
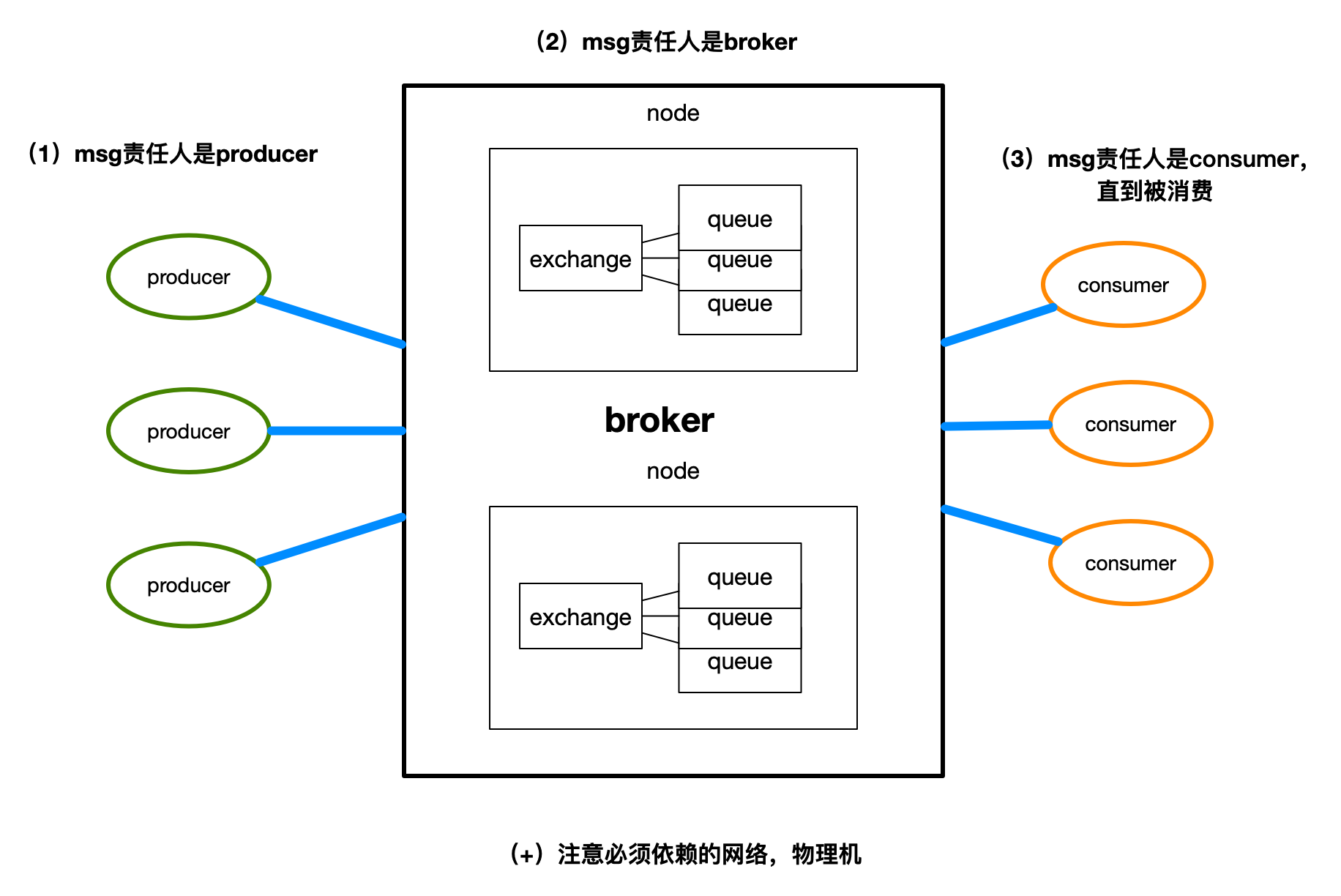
分析是不是会丢消息有一个核心的方法论是:Message的一生经过publisher(也是producer),broker,consumer三个阶段,所以message的安全性要从三个阶段逐一考虑。另一种比较有趣的说法是,publisher,broker nodes和consumer是message的三个监护人,如果消息丢失要分析是在哪个监护人上会丢失。这种通过数据链路经过的不同节点来分析数据可靠性的方法具有通用性,笔者认为首先在rabbitmq丢消息队列这里要记住这个思路,然后学会这个思维框架是并举一反三的。
上图是我对rabbitmq集群模式下画的简图,并标注了每个消息的责任人。下面就从消息的一生开始逐一分析丢消息的责任界定范围、原因和解决方案。
