

前言
我们知道RocketMQ以性能强劲著称,本篇文章我们就底层存储原理并结合代码,了解下RocketMQ高性能的秘密武器到底都有啥。
开源项目推荐
Pepper Metrics是我与同事开发的一个开源工具(github.com/zrbcool/pep…),其通过收集jedis/mybatis/httpservlet/dubbo/motan的运行性能统计,并暴露成prometheus等主流时序数据库兼容数据,通过grafana展示趋势。其插件化的架构也非常方便使用者扩展并集成其他开源组件。
请大家给个star,同时欢迎大家成为开发者提交PR一起完善项目。
底层存储核心原理概述
我们就这张图来解释一下(本文部分图片来自于艾瑞克的技术江湖)
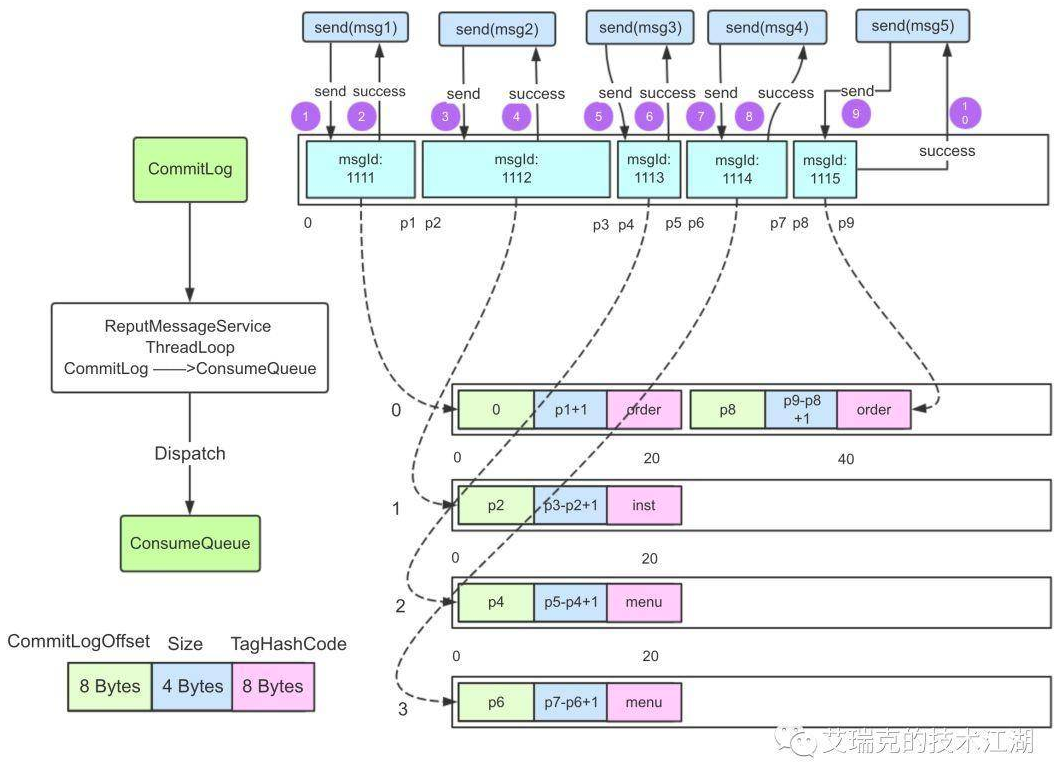
- 简单来说,RMQ的所有的消息存储在一个文件当中,这个文件就是图中的CommitLog,由于磁盘顺序写特性(无论是机械磁盘或SSD固态硬盘,顺序写的速度都远大于随机写)所以RMQ可很好的利用操作系统特性,将消息内容写入内存成功后即返回,这部分写入内存成功但还未刷入硬盘的数据,在内核当中被称为脏页(Dirty Page),操作系统会根据特定的情况定时或当脏页超过阈值时触发一次回写,而这个过程当中对磁盘的写相当于批量并且是顺序写,这就是RMQ在写消息时能够高性能的原因之一。
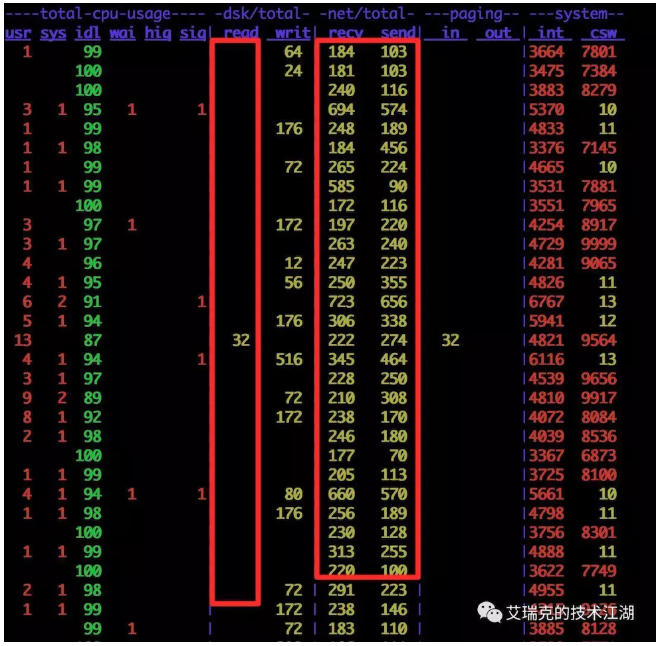
- 我们再来说下读消息,看图右下侧,消息在逻辑抽象上变成多个队列,这些队列被称为ConsumeQueue,根据名字就可以猜出这些队列是为读服务的,我们写入CommitLog的消息的消息ID及偏移量等信息,被均匀的写入到多个ConsumeQueue当中,这些队列在磁盘上也对应着相应的文件,而我们知道一般来说消息的消费者有多个或者多线程,这样就可以并发的从这些ConsumeQueue中读取消息的位置,然后再去CommitLog当中读取具体的消息内容,而由于一般情况下消息队列的读写都能够命中内存当中的缓存,所以正常情况下读操作其实就是读内存而已,当然性能高了。例如下面的图示就能够看到,当RMQ高性能读写时,磁盘读是非常少的
结合源码分析
CommitLog
前面我们简单说了RMQ,下面我们结合源码深入挖掘一下,到底黑科技是如何实现的
org.apache.rocketmq.store.CommitLog就是RMQ对CommitLog的抽象封装,我们来重点关注putMessage方法,也就是写消息的方法,该方法有两个实现
public PutMessageResult putMessage(final MessageExtBrokerInner msg) {
//单个消息
}
public PutMessageResult putMessages(final MessageExtBatch messageExtBatch) {
//批量消息
}
下面我们以单个消息为例看下代码
public PutMessageResult putMessage(final MessageExtBrokerInner msg) {
// ...
//获取内存映射文件句柄
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();
//加锁
putMessageLock.lock(); //spin or ReentrantLock ,depending on store config
try {
//...省略部分代码
//重点来了,调用MappedFile.appendMessage方法将消息字节追加到共享内存中,由操作系统或者后台刷盘线程完成刷盘的动作
result = mappedFile.appendMessage(msg, this.appendMessageCallback);
//...省略部分代码
} finally {
//解锁
putMessageLock.unlock();
}
//...省略部分代码
//触发刷盘动作,根据配置不同选择同步或者异步刷盘
handleDiskFlush(result, putMessageResult, msg);
handleHA(result, putMessageResult, msg);
return putMessageResult;
}
可以看到putMessage最终调用到了MappedFile的appendMessage方法,完成消息字节到内存映射文件的追加,这个内存映射文件又是什么鬼?
内存映射文件(mmap)简而言之,将文件直接映射到用户态的内存地址,这样对文件的操作不再是write/read,而是直接对内存地址的操作。具体可以参考这几篇博文,写的很详细
Java文件映射[mmap]全接触
java中的mmap实现
深度分析mmap:是什么 为什么 怎么用 性能总结
MappedFile
接下来我们需要重点聊下MappedFile,因为RMQ真正高性能的黑科技在于合理的利用了mmap内存映射文件技术及堆外内存操作ByteBuffer,这些操作都被封装到了这个类当中。
初始化,在RMQ启动时相应的线程会构建MappedFile完成内存映射操作,下面两行便是关键代码
this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
//进行mmap操作得到映射内存mappedByteBuffer
this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
可见在程序开始时便预先完成了内存映射操作,fileChannel.map实际上最终通过JNI调用了C库当中的mmap方法,具体可以参考文章:Java文件映射[mmap]全接触
上一节讲到的mappedFile.appendMessage(msg, this.appendMessageCallback)调用关系实际为:
appendMessage->appendMessagesInner->cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos, messageExt)
我们先简单看一下appendMessagesInner,我挑关键代码列一下:
//得到当前位置
int currentPos = this.wrotePosition.get();
ByteBuffer byteBuffer = writeBuffer != null ? writeBuffer.slice() : this.mappedByteBuffer.slice();
//定位到写位置
byteBuffer.position(currentPos);
//调用具体实现追加消息到内存
if (messageExt instanceof MessageExtBrokerInner) {
result = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos, (MessageExtBrokerInner) messageExt);
} else if (messageExt instanceof MessageExtBatch) {
result = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos, (MessageExtBatch) messageExt);
} else {
return new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR);
}
//移动写位置,增加写入字节数为偏移量
this.wrotePosition.addAndGet(result.getWroteBytes());
可以看到,MappedFile就是不停的写内存,然后移动末尾指针来实现消息内容到内存映射的追加的,而内存映射文件的实际文件写入时机可能是操作系统定期调用,脏页过大,程序主动调用byteBuffer.force方法
而cb这个callback回调其实还是在CommitLog的内部类DefaultAppendMessageCallback定义的,我们就来看下关键部分的代码:
byteBuffer.put(this.msgStoreItemMemory.array(), 0, msgLen);
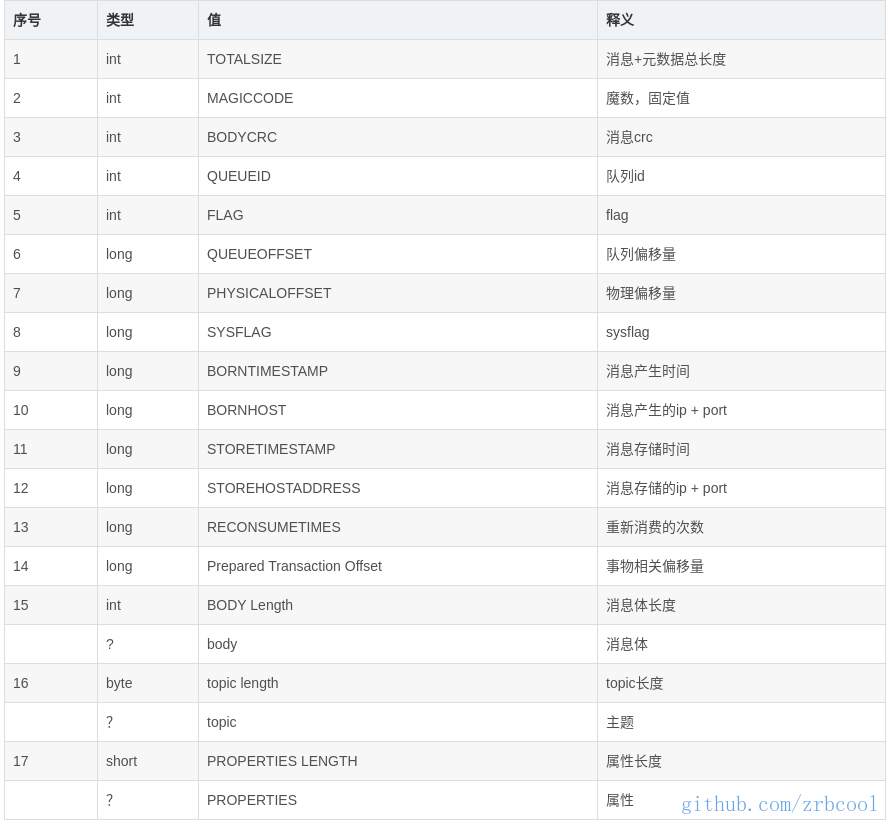
没错,虽然方法中代码很多,但紧扣本篇的主题实际上关键的只有这一句,msgStoreItemMemory也是一个ByteBuffer,它用于临时保存当前消息的字节数组,消息的元数据定义可以参考下图:
加餐PutMessageLock
前面代码中我们看到操作写消息时进行了加锁操作,这里RMQ自己实现了一个PutMessageLock接口,有两种实现PutMessageReentrantLock及PutMessageSpinLock,其中PutMessageReentrantLock就是直接使用jdk重入锁的实现,我们重点说下PutMessageSpinLock
我们知道Java的锁(重量级锁)底层实际上是调用pthread的mutex方法竞争锁,而这是一个内核函数,也就是说会产生大量的上下文切换,另外,如果没抢到锁线程进入阻塞状态,到收到信号唤醒工作也有延迟。在这里SpinLock的方式,利用CAS加自旋强行让当前CPU空跑等待抢锁成功,这样就避免了上下文切换的损失,但是代价就是大量的空操作浪费CPU时间片,造成CPU使用率高的现象,我们来看下代码:
public class PutMessageSpinLock implements PutMessageLock {
//true: Can lock, false : in lock.
private AtomicBoolean putMessageSpinLock = new AtomicBoolean(true);
@Override
public void lock() {
boolean flag;
do {
//自旋 + CAS
flag = this.putMessageSpinLock.compareAndSet(true, false);
}
while (!flag);
}
@Override
public void unlock() {
this.putMessageSpinLock.compareAndSet(false, true);
}
}
总结
小结一下,本篇文章我们从底层实现原理讲了RocketMQ高性能的原因及背后的黑科技,但是RMQ的性能优化部分相信远不止于此,今天就先写到这里,后面作者再进行发掘后整理成文章发布。
作者其他文章
微信订阅号

