

故事
现在,假设阅读此文的你穿越回了小学二年级的时光,此时的你正在不断的追求着隔壁班的班长小红,恨不得把家里所有东西都送给TA。那么问题来了,如果你要把家里东西都搬光送给小红,你有几种办法?以下是我想到
- 一件一件的搬,如果搬不动那就拆分(不排除你被你父母揍一顿的可能性)
- 试图通过吃药让自己变成大力士
上述例子看似滑稽,但其实这是一直以来人类解决大规模数量问题的解决方案,即要么提升自身的能力以应付大规模的数量,要么进行拆分,分而治之。
对应到IT行业,由于传统小型机处理能力有限于是便有了大型机。如果不用大型机那咋办吗?只好拆分服务,于是便有了微服务。
经典面试题
面试官:假设你只有100M的内存可用,现在有一个大小为1G的文件,里面存放着整数,每个整数用4个字节来存储,要你对这个这个文件中数据进行排序,你有什么解决方案?
我:打电话找行政的妹子跟她要一条8G的DDR4内存条,为了表示感谢顺便约她去吃饭, 说不定还能顺利脱单。
面试官:emmm….., 回去等通知吧
解决方案
我:要解决这个问题,首先我们需要分为两种情况:
数据不重复 如果数据不重复我们可以使用位图来标记相应的数据,在需要输出结果的时候遍历位图即可(此方案较为简单,不在本文的讨论范围内)
数据重复 由于只有100M的内存可用,完全利用这100M内存的情况下意味着我们一次可以对26214400个整数(100 * 1024 * 1024 / 4 ) 进行排序, 这意味着我们要分次读取文件并对读取的内容进行排序,并将每一次排序的结果保存到文件系统中,之后再对这些文件进行合并。
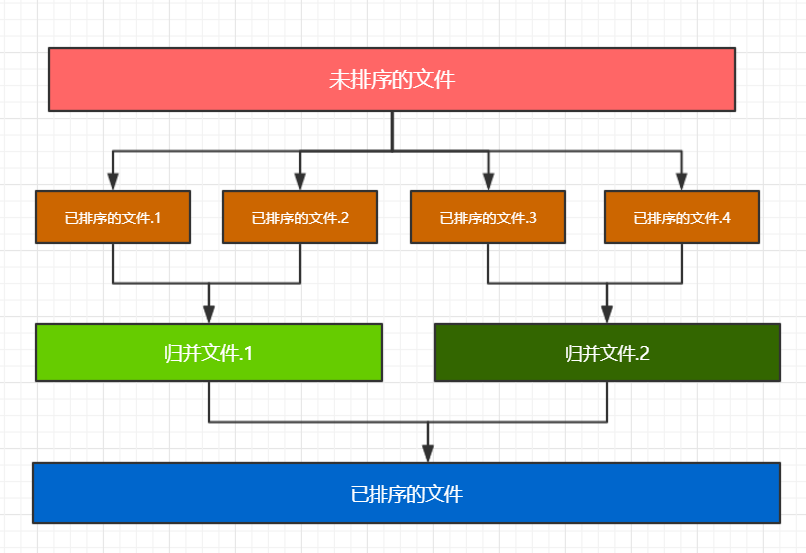
面试官:可以用画图表示一下吗?
我:过程如下图所示
面试官:可以,要不你现场写一下代码吧
解决方案的实现
解决方案的实现总的来说有以下几步
根据缓冲区的大小读入相应的数据量,并把他们转为整数数组,进行排序,并写入文件,重复这一步直到原始数据文件中没有数据可读。
合并这些已排序的文件直到只剩一个文件
将问题拆分开来看的话,我们需要解决以下子问题
- 由于我们采用4个字节的数据来保存整数,因此我们需要解决整数按字节存取的问题
你可以考虑一下为什么我们要用四个字节来存取整数?而不是将其转为字符串
- 合并已排序的文件的算法
方案一、预读取一部分的数据写入缓存中,然后进行归并排序(拆分之后的文件中的数据都是有序的),当数据用完时再去文件中读取,重复此步骤直到没有数据可读
方案二、每次只从两个文件中读取一个整数,进行比较,然后将较大/较小(取决于你要增序还是降序)的数据写入文件中
方案一,相对来说比较简单并且速度比较快留给大家实现。
对于方案二,由于最近开发中有涉及状态机,因此对于方案二我采用了状态机的设计模式来实现。
该状态机如下所示
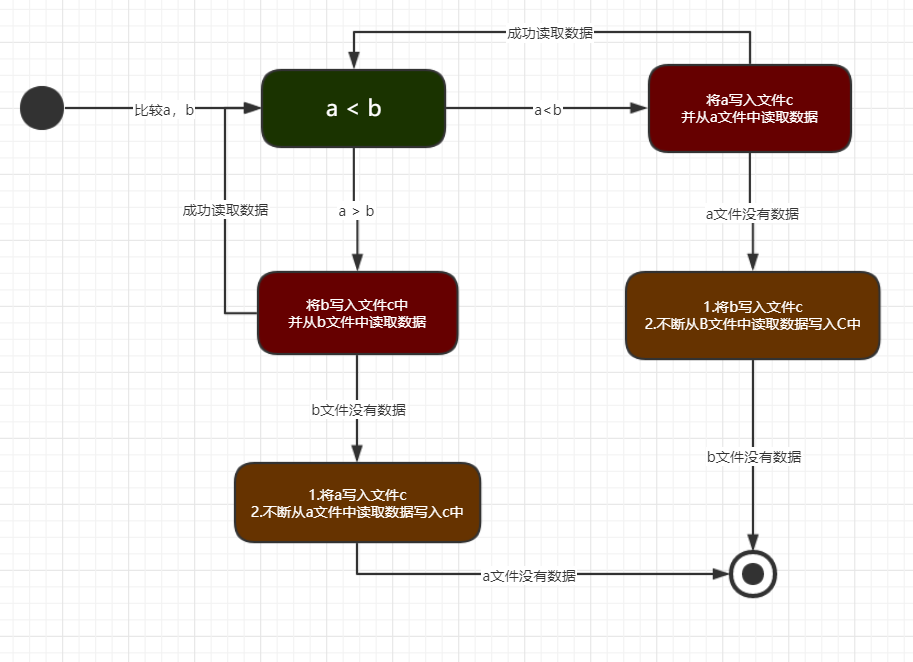
给大伙提供个参考,我实现的方案还有进一步优化的空间😄
测试
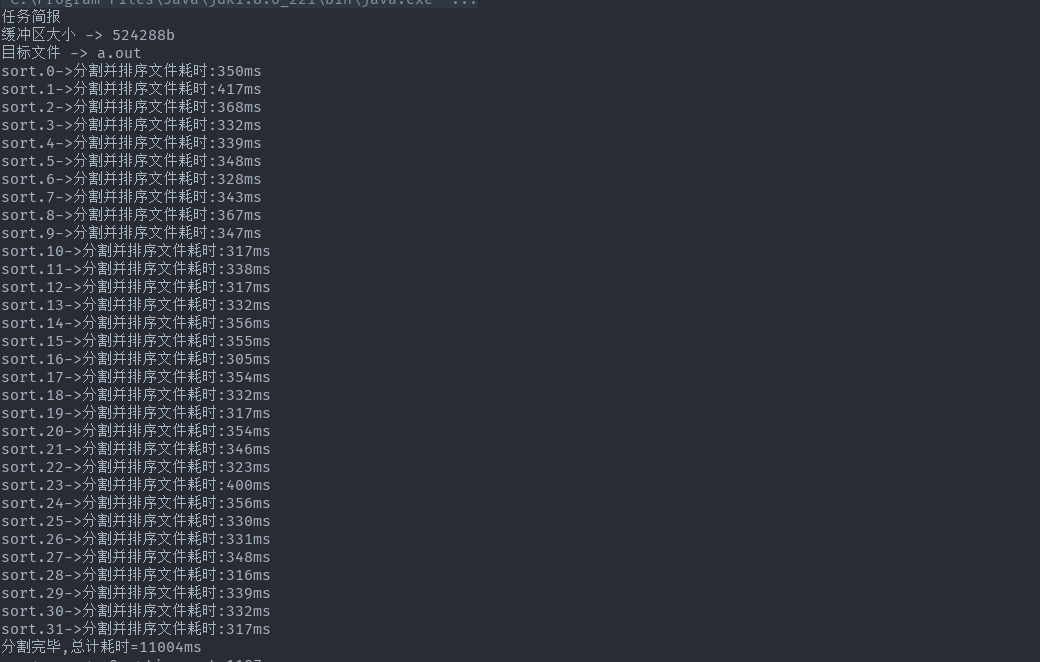
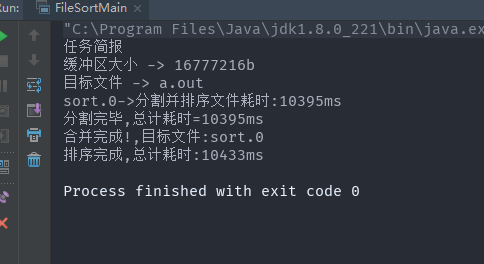
为了有一个直观的印象,我们对一个16MB的文件进行排序,缓冲区设置为512kb.
以下为测试结果
文件分割阶段,可以看出文件分割的时候所用时间都是差不多的
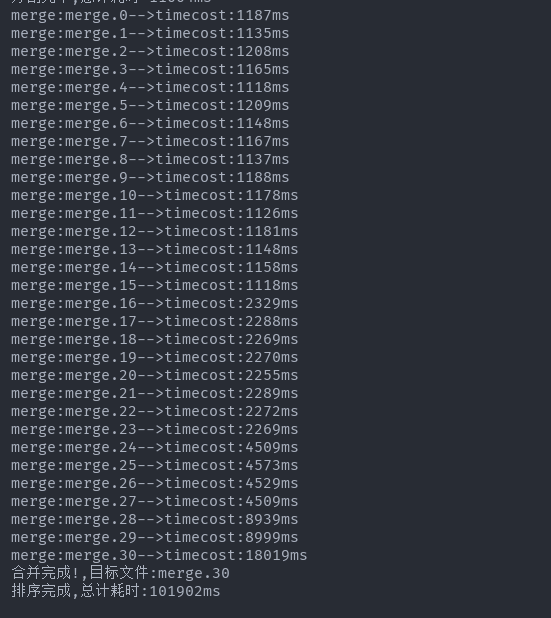
合并阶段,可以看出合并已排序的文件所用的耗时是不断递增的因为并合并的文件体积在不断的递增
如果我们直接将缓冲区设置为16MB呢?以下为测试结果,连合并阶段都不用了。
面试官: 很好,那你能说出应用场景吗?
我:利用文件(file)进行排序(sort)工作 = filesort,好像在哪里见过…
面试官: 提示你一个单词explain
FileSort
我:想起来了,假设我们有一张表
CREATE TABLE `users` (
`id` int(11) NOT NULL,
`account` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL,
`nickname` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL,
`password` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
如果我们需要根据某一个字段继续排序并且没有添加索引的话,那么使用explain对该SQL进行查询的话就会在Extra中看到filesort
如下图所示

这意味着,MySQL无法根据索引对数据进行排序(如果有索引的话直接取就好了,不需要排序操作)。
只好对要排序字段的进行排序了,但是生产环境中数据量可能会非常大,如果全部加载到内存中,必然会引起内存不足进而导致数据库崩溃,因此必须划出一块专门的内存区域以供排序,而这块内存区域很可能装不下这巨大的数据量,必然要借助外部文件系统进行排序,这就是filesort的由来
面试官:很好,那你知道怎么看这块内存的大小吗?
我: 缓冲区 = buffer,根据mysql的一贯传统,以下语句应该可以查到
show variables like '%buffer%'
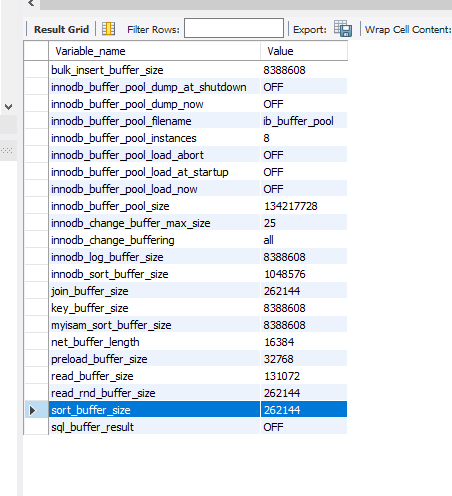
(图中蓝色标注的区域,即
sort_buffer_size)
面试官:很好,那你知道怎么优化吗?
我: 加索引呗,还能咋样,要不叫运维给服务器再加个内存条?或者把牙膏厂(Intel)的CPU换成农厂的CPU(AMD!YES)
面试官:只要你喜欢AMD,我们就是异父异母的亲兄弟。哦,不对我是想问该怎么加索引
我:我们知道索引是有顺序的,如果索引上信息已经满足了我们的需求,那么就不需要使用filsort了。
比如上文中所提到的users表
我们创建了一个index
alter table users add index(nickname, account)
考虑以下语句是否需要filesort
select nickname,account from users order by nickname
select * from users order by nickname
select * from users order by account
答案是
- 第一条语句不需要filesort,因为索引中已经包含了我们所需要的信息
- 第二条语句可以直接使用索引(索引有序存储),在读取到索引对应的主键值后取相应的数据并直接返回给客户端即可,不需要使用到
sort_buffer
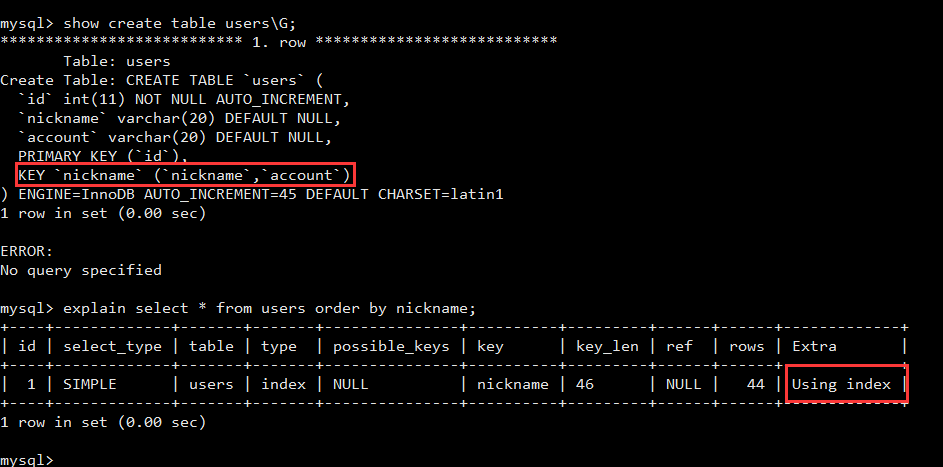
- 第三条语句需要
filesort, 但由于account和nickname组合成了索引,每一个nickname对应的account都是有序,因此不同的nickname对应的account可以用来做归并排序(如上文所提到的合并阶段)

总结
今天的总结就三张图



附录
Q1: 为什么用4个字节来存整数
节省空间,用字符串来存的话,你整数多长就得多少个字节
Q2: 怎么使用本文提供得外部排序DEMO
源码中的三个文件分别是
- 打印文件中的数据
- 对指定文件进行排序
- 生成随机数文件
Q3: 为什么要使用状态机来实现归并排序
不得不说,用状态机来梳理逻辑是比较清晰的,建议你也尝试一下。但在本例中如果你使用缓冲区来保存整数数组的话性能会快很多。
参考资料
《高性能MySQL(第三版)》
索引相关的部分
《MySQL王者晋级之路》
3.4节
