

本篇文章将阐述Hadoop的一些基本概念,并解释MapReduce的局限,从而引出Spark的核心思想。
本文首发于微信公众号【面向数据编程】
Hadoop当初作为一种大数据技术横空出世,经过多年的发展,Hadoop已经不单单指某一个技术,而是一个完整的大数据生态。
Hadoop的本质是分布式系统,因为单台机器无法完成大数据的存储、处理,所以需要将数据分别存放在不同的机器,并且能够让用户像访问单台机器的数据一样去访问、操作这些数据。为了实现这个任务,Hadoop当年提出了两个概念:HDFS与MapReduce。
HDFS
即分布式的数据存储方案,它的作用是将大量数据存放在一个由多台机器组成的集群中,每个机器存放一部分数据。
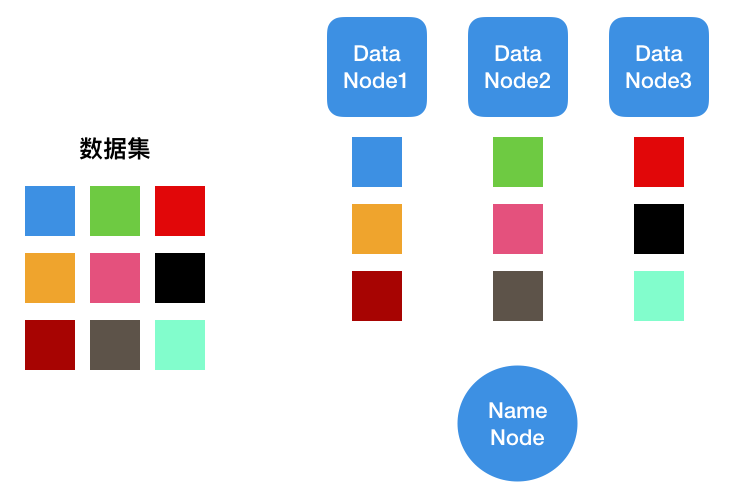
假设左边是我们要存储的数据集,HDFS集群包含存储的节点,即右边的Data Node1、2、3,以及一个Name Node,用于存放各个数据块所在的位置。比如我们现在需要访问蓝色数据块以及绿色数据块,分为以下几个步骤:
-
客户端向Name Node发出请求,获取蓝色数据块与绿色数据块的位置
-
Name Node返回Data Node1与Data Node2的地址
-
客户端访问Data Node1与Data Node2
如果我们要在集群中增加一个数据,步骤如下:
-
客户端向Name Node发出写入请求
-
Name Node确认请求,并返回Data Node地址
-
开始向目的地址写入数据,相应的机器在写入成功后返回写入成功的确认信息
-
客户端向Name Node发送确认信息
可以看出,整个集群最关键的节点是Name Node,它管理了整个文件系统的信息,以及相应的文件操作的调度。当然一个集群不一定只有一个Name Node,如果仅有一个Name Node,它无法服务时整个集群就都停止工作了。
上述的概念与数据存放访问等操作仅仅是最简单的情况,实际情况复杂的多,例如集群还需要进行数据备份,当新写入数据时,对备份数据的写入也有一个复杂的流程。
MapReduce
MapReduce是一个抽象的编程模型,它将分布式的数据处理简化为两个操作,Map与Reduce。在MapReduce出现前,分布式集群对数据的处理是很复杂的,因为如果我们要让分布式集群完成一个任务,首先需要将这些任务分解成很多子任务,然后要将这些子任务分配至不同的机器,最后完成了子任务后,需要将子任务产生的结果进行合并、汇总等操作。
而MapReduce抽象了这个流程,它将机器分为两类,分别是Master和Worker。Master负责调度工作,Worker是实际执行任务的机器。Worker也可以分为两种,Mapper和Reducer。Mapper主要负责子任务的执行,Reducer负责汇总各个Mapper的执行结果。
我们可以用一个简单的例子来解释这个过程,例如现在我们需要从一堆扑克牌中数出A的数量,那么我们会将扑克牌分成几份,每个人(Mapper)在分到的牌中数出A的数量,有个人数牌堆1,有个人数牌堆2。最后每个人数完了,将结果汇总(Reduce)起来,就是整堆牌中A的数量。
当然,真正的任务也不止这两个操作,还包含Split,即切割数据,Shuffle,即归类数据等操作。这些操作的设计也是特别精妙的,如果设计的不好,很可能影响整个系统的性能。

- Reduce需要在Map后完成,如果数据没有合理的分割,则整个流程将会大大延时
- Map与Reduce在处理复杂逻辑上有些力不从心
- 性能瓶颈,因为MapReduce处理的中间结果需要存放在HDFS上,所以写入写出时间大大影响了性能
- 每次任务的延时巨大,只适合批量数据的处理,不太能处理实时数据
Spark
Spark的出现一定程度上解决了上述的问题,可以作为MapReduce的替代品。其速度远远超过Hadoop的MapReduce,
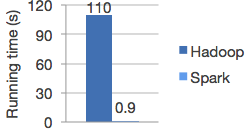
为了完成这个一步到位,不需要硬盘多次读写的任务,Spark提出了新的思想,即RDD,基于分布式内存的数据抽象。
RDD的全称叫做Resilient Distributed Datasets,即弹性分布式数据集,基于RDD,Spark定义了很多数据操作,比起MapReduce,大大提高了逻辑的表示能力。
当然,RDD这个概念十分难以理解,它并不是一个实际存在的东西,而是一个逻辑上的概念,在实际的物理存储中,真实的数据仍然是存放在不同的节点中。它具有以下几个特性:
- 分区
- 不可变
- 能并行操作
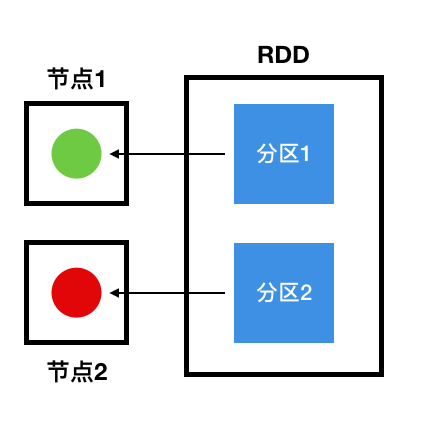
分区
分区的意思是,同一个RDD中的数据存储在集群不同的节点中,正是这个特性,才能保证它能够被并行处理。前面提到,RDD是一个逻辑上的概念,它只是一种数据的组织形式,我们可以用下图来说明这个组织结构:
不可变
每一个RDD都是只读的,包含的分区信息不可以被改变。因为已有的RDD无法被改变,所以每次对数据的操作,会产生新的RDD作为结果。每次产生的新RDD,我们需要记录它是通过哪个RDD进行转换操作得来,因此新老RDD存在依赖关系,这样做的一个好处是不需要将每一步产生的数据结果进行存储,如果某一步失败了,只需要回滚至它的前一步RDD再次进行操作,而不需要重复所有的操作。具体依赖的细节这里不再阐述,实现逻辑比较复杂,之后会有文章专门讲解。
并行操作
之前提到同一个RDD中的数据存储在集群不同的节点中,正是这个特性,才能保证它能够被并行处理。因为不同节点的数据可以被分别处理,
比如现在一群人手中都分别拿着几种水果,如果现在要给这些水果按照种类顺序削皮,例如先削苹果,后削梨,最后削桃子,肯定是一种水果分别在不同的人手上才能完成并行的任务。如果一个人手上都是苹果,一个人手上都是梨,那只能等一个人削完另一个人才能继续。
总结
相比MapReduce,Spark做出了几个改进,从而获得了性能大幅度的提升。
- Spark将操作的数据放入内存中,而不是硬盘,这让读写速度大大提升
- Spark任务中每一步操作产生的结果并不需要写入硬盘,而是只记录操作之间的依赖关系,因此提高了容错率,并大大降低了恢复任务的成本
- 使用分区的方式,让数据能够并行处理
