

HashMap 是后端面试的常客,比如默认初始容量是多少?加载因子是多少?是线程非安全的吗?put 操作过程复述下?get 操作复述下?在 jdk 1.7 和 1.8 实现上有什么不同?等等一系列问题,可能这些问题你都能对答如流,说明对 HashMap 还是比较理解的,但最近我们团队的同学做了一个技术分享,其中有几点我挺有收获的,我给大家分享下
我们每周五都会进行技术分享,大家轮流分享,其实这种机制挺好的,大家坐在一起深入讨论一个知识点,进行思维的碰撞,多赢
抛出两个问题,看你能否回答出来?
- 如何找到比设置的初始容量值大的最小的 2 的幂次方整数?
- HashMap 中对 key 做 hash 处理时,做了什么特殊操作?为什么这么做?
先自己思考下,再往下阅读效果更佳哦!
下面的分析都是针对 jdk 1.8
分析
问题1:如何找到比设置的初始容量值大的最小的 2 的幂次方整数?
我们在用 HashMap 的时候,如果用默认构造器,就会建一个初始容量为 16,加载因子为 0.75 的 HashMap。这样做有个缺点,就是在数据量比较大的时候,会进行频繁的扩容操作,扩容会发生数据的移位,为了避免扩容,提高性能,我们习惯预估下容量,然后通过带容量的构造器创建,看下源码
public HashMap(int initialCapacity, float loadFactor) {
...
// 如果设置的初始容量大于最大容量就默认为最大容量 2^30
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
...
this.loadFactor = loadFactor;
// tableSizeFor 方法主要就是计算比给定的初始容量值大的最小的 2 的幂次方整数
this.threshold = tableSizeFor(initialCapacity);
}
通过源码我们可知,容量最大值为 2^30,也就是说 HashMap 的数组部分的长度的范围为[0,2^30],然后计算比初始容量大的最小的2的幂次方整数,其中 tableSizeFor 方法是重点,我们看下源码
// Returns a power of two size for the given target capacity
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
这个方法设计的非常巧妙,因为 HashMap 要保证容量是 2 的整数次幂,该方法实现的效果就是如果你输入的 cap 本身就是 2 的整数次幂,那么就返回 cap 本身,如果输入的 cap 不是 2 的整数次幂,返回的就是比 cap 大的最小的 2 的整数次幂
为什么容量要是 2 的整数次幂?
因为获取 key 在数组中对应的下标是通过 key 的哈希值与数组长度 -1 进行与运算,如:tab[i = (n - 1) & hash]
- n 为 2 的整数次幂,这样 n-1 后之前为 1 的位后面全是 1,这样就能保证 (n-1) & hash 后相应的位数既可能是 0 又可能是 1,这取决于 hash 的值,这样能保证散列的均匀,同时与运算效率高
- 如果 n 不是 2 的整数次幂,会造成更多的 hash 冲突
该方法首先执行了 cap -1 操作,这样做的好处是避免输入的 cap 是 2 的整数次幂,最后计算的数是 cap 的 2 倍的情况,因为设置 cap 已经满足 HashMap 的要求了,没有必要初始化一个 2 倍容量的 HashMap 了,看不明白不急后面有示例分析
前面我们已经介绍 HashMap 的最大容量为 2^30,所以容量最大就是 30 bit 的整数,我们就用 30 位的一个数演示下算法中的移位取或操作,假设 n = 001xxx xxxxxxxx xxxxxxxx xxxxxxxx (x 代表该位上是 0 还是 1 我们不关心)
第一次右移 n |= n >>> 1 ,该操作是用 n 本身 和 n 右移 1 位后的数进行或操作,这样可以实现把 n 的最高位的 1 紧邻的右边一位也置为 1
n 001xxx xxxxxxxx xxxxxxxx xxxxxxxx
n >>> 1 0001xx xxxxxxxx xxxxxxxx xxxxxxxx
| 或操作 0011xx xxxxxxxx xxxxxxxx xxxxxxxx
结果就是把 n 的最高位为 1 的紧邻的右边的 1 位也置为了 1,这样高位中有连续两位都是 1
第二次右移 n |= n >>> 2
n 0011xx xxxxxxxx xxxxxxxx xxxxxxxx
n >>> 2 000011 xxxxxxxx xxxxxxxx xxxxxxxx
| 或操作 001111 xxxxxxxx xxxxxxxx xxxxxxxx
结果就是 n 的高位中有连续 4 个 1
第三次右移 n |= n >>> 4
n 001111 xxxxxxxx xxxxxxxx xxxxxxxx
n >>> 4 000000 1111xxxx xxxxxxxx xxxxxxxx
| 或操作 001111 1111xxxx xxxxxxxx xxxxxxxx
结果就是 n 的高位中有连续 8 个 1
第四次右移 n |= n >>> 8
n 001111 1111xxxx xxxxxxxx xxxxxxxx
n >>> 8 000000 00001111 1111xxxx xxxxxxxx
| 或操作 001111 11111111 1111xxxx xxxxxxxx
结果就是 n 的高位中有连续 16 个 1
第五次右移 n | n >>> 16
n 001111 11111111 1111xxxx xxxxxxxx
n >>> 16 000000 00000000 00001111 11111111
| 或操作 001111 11111111 11111111 11111111
结果就是 n 的高位1后面都置为 1
最后会对 n 和最大容量做比较,如果 >= 2^30,就取最大容量,如果 < 2^30 ,就对 n 进行 +1 操作,因为后面位数都为1,所以 +1 就相当于找比这个数大的最小的 2的整数次幂
011111 11111111 11111111 11111111,这个值就是比给的值大的最小的 2 的整数次幂
下面我们用一个具体说演示下,比如 cap = 18
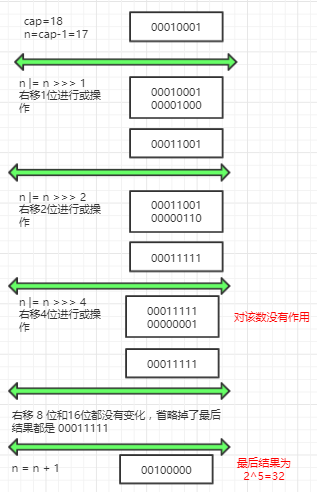
我们输入的是 18,输出的是 32,正好是比 18 大的最小的 2 整数次幂
如果 cap 本身就为 2的整数次幂,输出结果为什么?
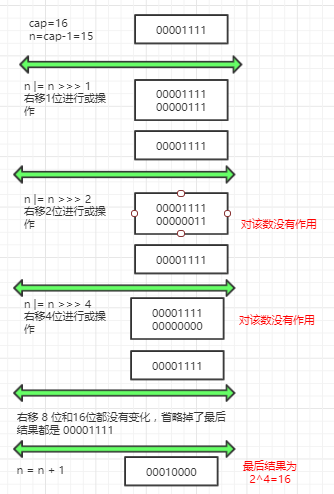
通过演示可见,cap 本身就是 2 的整数次幂的输出结果为其本身
上面还遗留了个问题,就是先对 cap -1,我解释说为了避免输出的是偶数,最后计算的结果为 2*cap,浪费空间,看下面的演示
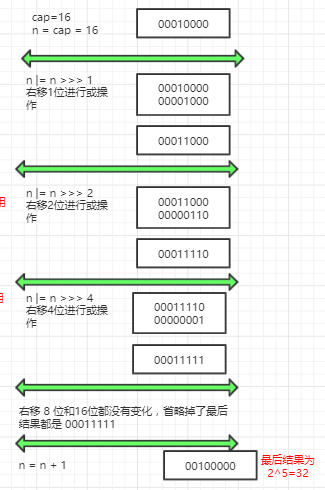
通过演示,我们可以看出,输入的是 16,最后计算的结果却是 32,这就会浪费空间了,所以说算法很牛,先对 cap 做了减一操作
问题2:HashMap 中对 key 做 hash 处理时,做了什么特殊操作?为什么这么做?
首先我们知道 HashMap 在做 put 操作的时候,会先对 key 做 hash 操作,直接定位到源码位置
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
可以看到再对 key 做 hash 操作时,执行了 (h = key.hashCode()) ^ (h >>> 16)
原 hashCode 值: 10110101 01001100 10010101 11011111
右移 16 位后的值: 00000000 00000000 10110101 01001100
异或后的值: 10110101 01001100 00100000 10010011
这个操作是把 key 的 hashCode 值与 hashCode 值右移 16 位做异或(不同为 1,相同为 0),这样就是把哈希值的高位和低位一起混合计算,这样就能使生成的 hash 值更离散
这里需要我解释下,通过前面的介绍,我们知道数组的容量范围是 [0,2^30],这个数还是比较大的,平时使用的数组容量还是比较小的,比如默认的大小 16,假设三个不同的 key 生成的 hashCoe 值如下所示:
19305951 00000001 00100110 10010101 11011111
128357855 00000111 10100110 10010101 11011111
38367 00000000 00000000 10010101 11011111
他们三个有个共同点是低 16 位完全一样,但高 16 位不同,当计算他们在数组中所在的下标时,通过 (n-1)&hash,这里 n 是 16,n-1=15,15 的二进制表示为
00000000 00000000 00000000 00001111
用 19305951、128357855、38367 都与 15 进行 & 运算,结果如下
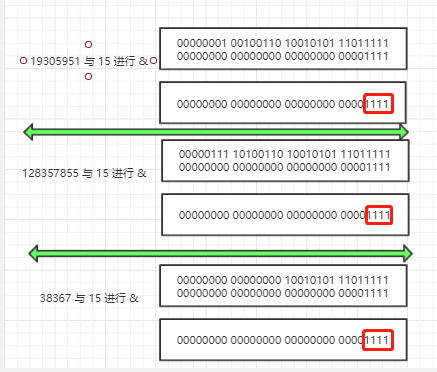
通过计算后发现他们的结果一样,也就是说他们会被放到同一个下标下的链表或红黑树中,显然不符合我们的预期
所以对 hash 与其右移 16 位后的值进行异或操作,然后与 15 做与运算,看 hash 冲突情况
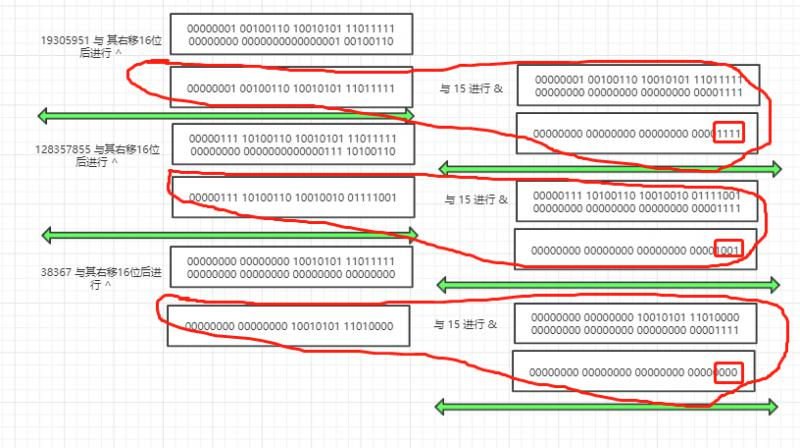
可见经过右移 16位后再进行异或操作,然后计算其对应的数组下标后,就被分到了不同的桶中,解决了哈希碰撞问题,思想就是把高位和低位混合进行计算,提高分散性
总结
其实 HashMap 还有很多值得研究的点,上面两个点搞明白后,会感叹作者写代码的能力真是牛,我们在工作中要借鉴这些思想,希望通过我的讲解,你能掌握这两个知识点,如果有不懂的可以留言或私聊我
欢迎关注公众号 【每天晒白牙】,获取最新文章,我们一起交流,共同进步!
