

InnoDB 为了保证并发能力,采取行级加锁策略。为了实现事务的隔离级别,InnoDB 中又引入了各种不同的行级锁机制。不同的加锁顺序、加锁类型、锁的多少以及影响范围将直接影响到整个事务执行效率与执行时间直接影响 MySQL 的吞吐能力,不恰当的加锁策略甚至有可能产生死锁,因此我们又必要对整个过程有所了解。
加锁策略与影响因素
InnoDB 采用了 B+ Tree 的数据结构与聚集索引的数据组织形式,索引在 InnoDB 引擎中占据了非常重要的位置,InnoDB 加锁过程就是对索引进行加锁的一个过程。在分析 InnoDB 加锁之前,我们需要知道 InnoDB 加锁是和什么有关,这一点非常重要。对于不同的事务隔离离别、不同的列 InnoDB 采取的策略与使用的锁的类型都不一样,影响加锁的因素有如下两种:
- 事务隔离级别,对于不同的事务隔离级别,InnoDB 采取的策略不一样。比如对于
select ... from这类语句而言,由于 InnoDB 采取了一致性读策略,一般是不会加锁的,但是在Serialzable级别,InnoDB 会对搜索过程中遇到的二级索引加共享临键锁。对于Read Committed级别不会采取间隙锁的加锁策略。 - 索引,由于InnoDB 采取了聚集索引的数据组织策略,因此对于主键和二级索引,它们的加锁过程是不同的。对于主键索引只需对主键上进行加锁即可,而对于二级索引加锁后还需对其指向数据的主键进行加锁。
- 加锁语句,InnoDB在不同事务隔离级别下,对于不同的加锁语句,采取的策略不同。如对于
update ... from ...语句在Read Repeatable级别下使用了排他临键锁,而在Read Committed级别下使用的是排他行锁。
基本加锁原则
对于 InnoDB 而言,虽然加锁的类别繁多,加锁形式也灵活多样,但也遵循了一些原则:
- 对于
select ... from ...语句,使用快照读,一般情况下不加锁,仅在Serializable级别会加共享读锁 - 对于
select ... from ... lock in share mode语句使用当前读,加共享读锁(S锁) - 对于
select ... from ... for update语句,为当前读,加排他写锁(X锁) - 常见 DML语句(insert、delete、update),使用当前读,加排他写锁(X锁)
- 常见 DDL语句(alter table,create table ...)等,加的是表级锁
接下来我们将按照不同的场景逐个不同语句的加锁过程进行分析。如下为使用到的表格:
CREATE TABLE `t_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`no` char(18) NOT NULL DEFAULT '' COMMENT '身份证',
`name` varchar(50) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(4) NOT NULL DEFAULT '0' COMMENT '年龄',
PRIMARY KEY (`id`),
UNIQUE KEY `no` (`no`),
KEY `name` (`name`)
) ENGINE=InnoDB COMMENT='用户表';
默认插入数据如下:
| id | no | name | age |
|---|---|---|---|
| 1 | 0001 | 张三 | 20 |
| 3 | 0003 | 李四 | 25 |
| 5 | 0005 | 王五 | 50 |
| 7 | 0007 | 王五 | 23 |
| 9 | 0009 | 赵六 | 28 |
Read Uncommitted 级别
Read Uncommitted 级别是事务隔离的最低级别,在此隔离级别下会存在脏读的现象,会影响到数据的正确性,因此我们在日常开发过程中很少使用该隔离级别。在此隔离级别下更新语句采取的是普通的加行锁的机制,Read Committed的加锁过程与Read Uncommitted一致。由于Read Committed使用范围较Read Uncommitted更广,在Read Committed级别下详细分析。
Read Committed 级别
Read Committed级别采取了一致性读策略,解决了事务的脏读问题,我们以下简称为RC级别。在此级别下更新语句加锁与Read Uncommitted一致,可能存在的锁有行锁与意向锁。加锁过程采取了Semi-consistent read优化策略,对于扫描过的数据如若不匹配,加锁后会立即释放。
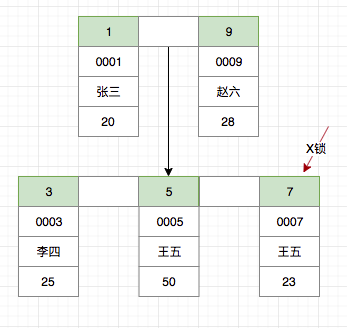
使用主键
假设我们需要在上述t_user表格中,删除ID=7的王五这一条记录,语句为:
delete from t_user where id = 7;
由于使用了主键,只需对该条记录加X锁即可,其加锁过程如下:
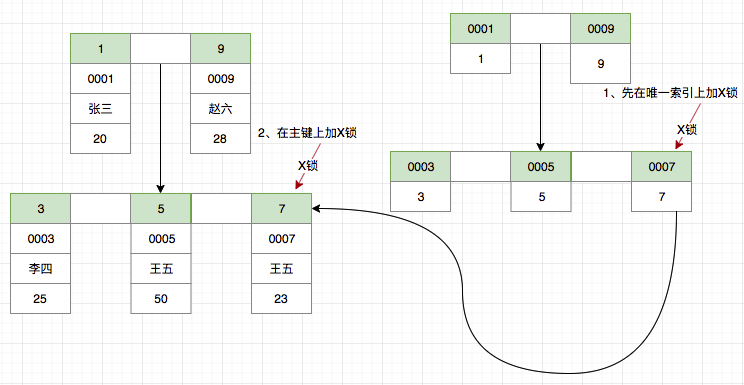
使用唯一索引
假设我们通过身份证no这个唯一索引来删除id=7这条数据会如何加锁呢?
delete from t_user where no = '0007';
由于唯一索引为二级索引,Innodb 首先通过唯一索引对数据进行过滤,对于0007唯一索引加X锁,然后还需要在聚集索引上对主键=7的数据进行加X锁。
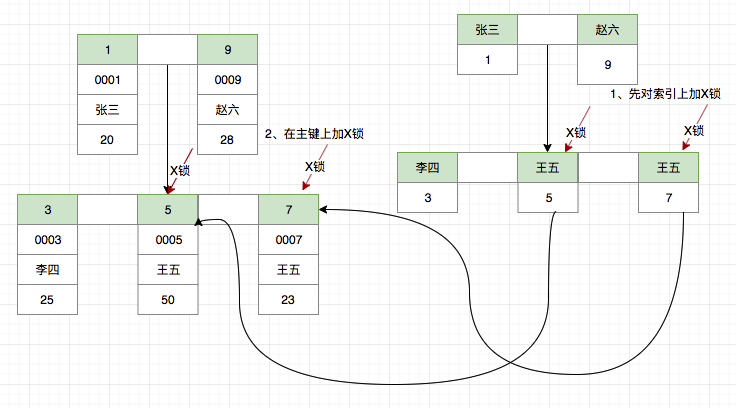
使用非唯一索引
假设我们使用非唯一索引,那么情况又会如何呢?
delete from t_user where name = '王五';
由于唯一索引为二级索引,Innodb 首先通过索引对数据进行过滤,对于王五的两条索引加X锁,然后还需要在聚集索引上对主键=5,7 的数据进行加X锁。
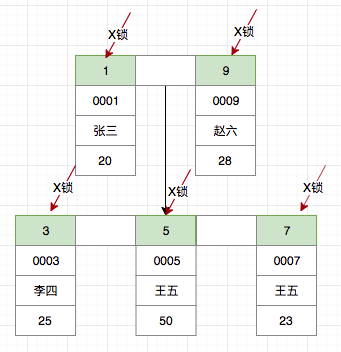
未使用任何索引
如果不使用任何索引,情况会是怎样呢?
delete from t_user where age = 23;
由于删除语句没有使用任何索引,那么 InnoDB 必须进行全表扫描以确定哪条数据需要删除。也就是说首先需要对全表的所有数据进行加锁,InnoDB 在RC级别下的加锁过程采取了Semi-consistent read优化策略,对于扫描过的数据如若不匹配,加锁后会立即释放。
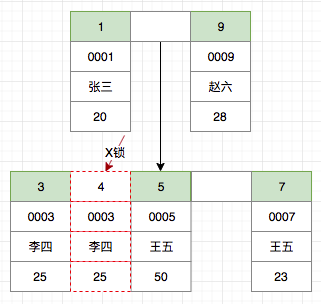
插入过程加锁
那么对于插入过程,RC级别又是如何加锁的呢?
insert into t_user(id,no,name,age) values(4,'00004','小灰灰',8);
InnoDB事实上只对主键加了X锁。
Read Repeatable 级别
Read Repeatable级别引入了间隙锁等一系列机制,来防止其他事务的插入操作,以下简称RR级别。但与此同时间隙锁的范围也带来了很多额外的开销与问题,其中之一就有由于引入了间隙锁加大了锁的粒度范围,使用不当容易造成死锁。由于RR级别下可以通过参数innodb_locks_unsafe_for_binlog来配置是否开启gap锁,在此我们讨论的是开启gap锁的情况。
使用主键
假设我们需要在上述t_user表格中,删除ID=7的王五这一条记录,语句为:
delete from t_user where id = 7;
由于使用了主键,可以唯一确认影响的记录,只需对该条记录加X锁即可,其加锁过程与RC级别下的使用主键加锁过程相同。
使用唯一索引
假设我们通过身份证no这个唯一索引来删除id=7这条数据会如何加锁呢?
delete from t_user where no = '0007';
由于唯一索引为二级索引,Innodb 首先通过唯一索引对数据进行过滤,对于0007唯一索引加X锁,然后还需要在聚集索引上对主键=7的数据进行加X锁。
使用非唯一索引
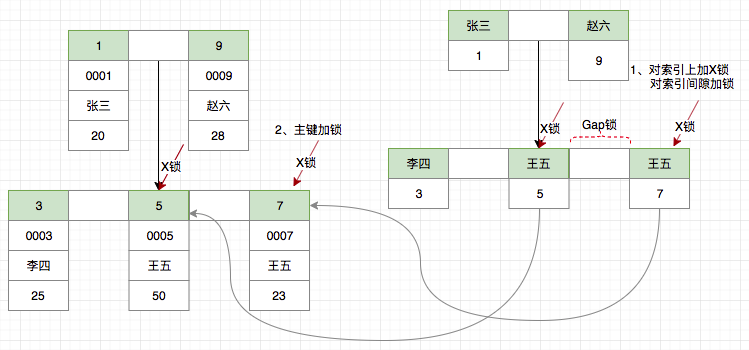
假设我们使用非唯一索引,那么情况又会如何呢?
delete from t_user where name = '王五';
由于使用索引为二级索引,Innodb 首先通过索引对数据进行过滤,由于普通索引不能保证影响数据范围唯一,有可能其他的事务在对二者之间的间隙操作添加新数据,因此还需要对于王五之间的间隙进行加锁,以防有其他事务在事务提交前在此间隙插入数据,最后还需要在聚集索引上对主键=5,7 的数据进行加X锁。
未使用任何索引
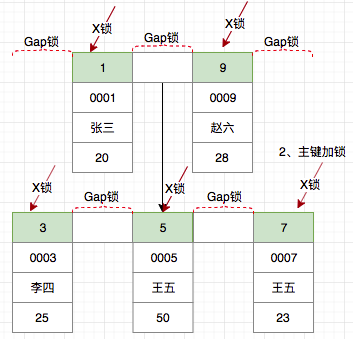
那么在RR级别下,如果不使用索引会导致什么情况呢?
delete from t_user where age = 23;
如若不使用任何索引,InnoDB只能够通过全表扫描以确定需要删除的数据,因此首先会需要对所有数据进行加锁,此外由于需要避免其他事务插入,还需要对所有的间隙进行加锁,这对InnoDB性能影响非常显著。
插入过程
在RR级别下,插入过程是如何加锁的呢?
insert into t_user(id,no,name,age) values(4,'00004','小灰灰',8);
插入过程是不需要增加gap锁的,因此RR级别下的加锁过程与RC级别下的加锁过程差不多。依照官方文档,插入过程隐式的加了插入意向锁,该锁虽然为间隙锁,但大多数时候并不会影响其他行的插入。
Serializable 级别
Serializable 级别是事务隔离的最高级别,在此级别下所有的请求会进行串行化处理。在InnoDB中该级别下的 更新语句加锁过程与Read Repeatable下一致。
