

近年来,Instagram发布了许多功能-我们推出了故事,过滤器,创建工具,通知和消息直递,以及许多其他功能和优化。 但是,随着产品功能的增长,一个不幸的副作用是我们的网络性能开始下降。 在过去的一年中,我们有意识地努力来改善这一状况。 到目前为止,我们的不懈努力已使Feed页的加载时间累计提升了近50%。 这一系列博客文章将概述我们为实现这些改进所做的一些工作。
页面提前渲染推送数据
在第1部分中,我们展示了如何使用链接预加载使我们能够在页面加载的更早阶段,即在启动请求的脚本加载之前就开始发起动态查询请求。 虽然如此,将这些请求作为预加载发出仍然意味着直到HTML页面开始在客户端上渲染之前查询才能开始,这意味着直到2个网络往返完成为止查询都无法开始(再加上生成请求的时间很长) 服务器上的html响应)。 正如我们在下面看到的预加载GraphQL查询一样,尽管这是我们在HTML头中预加载的第一批内容之一,但实际上要花很长时间才能真正开始查询。

理想状态下,我们希望预加载的查询在页面请求到达服务器后立即开始执行。 但是,如何使浏览器在从服务器接收到任何HTML之前请求某些内容呢? 答案是将资源从服务器推送到浏览器,虽然看起来像HTTP / 2推送是此处的解决方案,但实际上有一种非常古老(常常被忽视)的技术可以实现此功能,该技术具有通用的浏览器支持和没有实现HTTP / 2推送的复杂性。 自2010年以来,Facebook一直在成功使用此方法(请参阅BigPipe),其他形式也有众多网站(例如Ebay)尝试过,但是JavaScript SPA的开发人员似乎往往忽略了该技术或未使用该技术。 它有几个名称-early flush,heading flushing,progressive HTML-并通过结合以下两点来工作:
- HTTP分块传输编码
- 浏览器中渐进式HTMl渲染
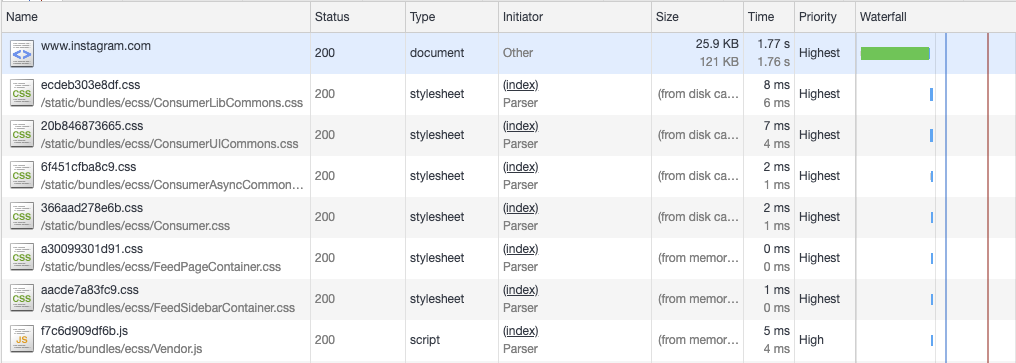
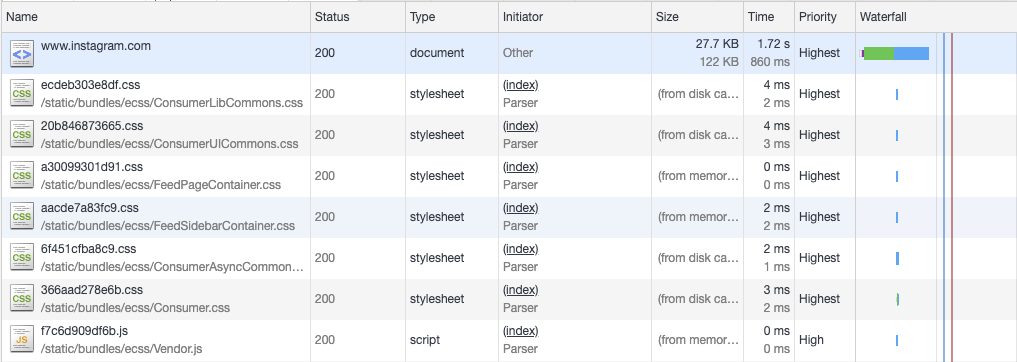
分块传输编码是作为HTTP / 1.1协议中添加的,从本质上讲,它允许将HTTP网络响应分解为多个“块”,这些“块”可以流式传输到浏览器。然后,浏览器在这些块到达最终完成的响应时将它们缝合在一起。尽管这确实涉及在服务器端呈现页面的方式的相当重大的变化,但是大多数语言和框架都支持呈现分块的响应(在Instagram的情况下,我们在Web前端上使用Django,因此我们使用StreamingHttpResponse对象)。之所以有用,是因为它允许我们在页面的每个部分完成时将HTML页面的内容流式传输到浏览器,而不必等待整个响应。这意味着我们可以立即将HTML头刷新到浏览器(因此称为“early flush”),因为它不需要太多的服务器端处理。这允许浏览器在服务器忙于在页面其余部分中生成动态数据时开始下载脚本和样式表。您可以在下面看到此效果。
没有采用early flush
采用了early flush
另外,我们可以使用分块编码在完成时将数据发送到客户端。 对于服务器端呈现的应用程序,它可以采用HTML形式,但是对于诸如instagram.com之类的单页面应用程序,我们可以将JSON数据推送到浏览器。 为了了解其工作原理,让我们看一下单页应用程序启动的传统情况。
首先,将包含呈现页面所需的JavaScript的初始HTML刷新到浏览器。 该脚本解析并执行后,将执行XHR查询,该查询将获取引导页面所需的初始数据。
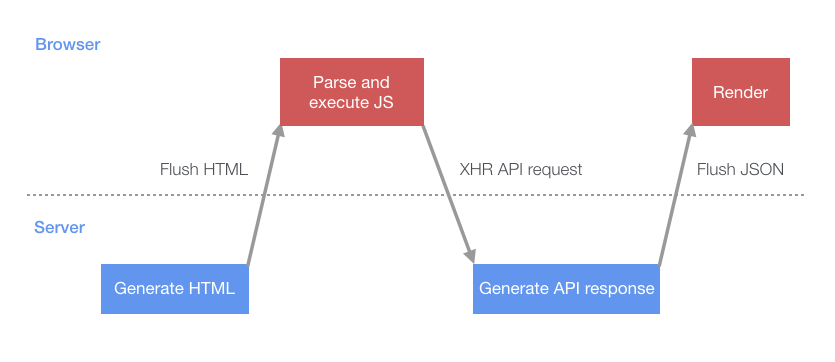
此过程涉及服务器和客户端之间的多次往返,并引入了服务器和客户端都处于空闲状态的时间段。 与其让服务器等待客户端请求API响应,不如让服务器在HTML生成后立即开始生成API响应并将其推送到客户端,而不是让服务器等待。 这意味着到客户端启动时,数据可能已经准备好,而不必等待另一次往返。 进行此更改的第一步是创建一个JSON缓存来存储服务器响应。 我们通过在页面HTML中使用一个小的内联脚本块来实现此目的,该脚本块充当缓存并列出了服务器将添加到此缓存中的查询(下面以简化形式显示)。
<script type="text/javascript">
// the server will write out the paths of any API calls it plans to
// run server-side so the client knows to wait for the server, rather
// than doing its own XHR request for the data
window.__data = {
'/my/api/path': {
waiting: [],
}
};
window.__dataLoaded = function(path, data) {
const cacheEntry = window.__data[path];
if (cacheEntry) {
cacheEntry.data = data;
for (var i = 0;i < cacheEntry.waiting.length; ++i) {
cacheEntry.waiting[i].resolve(cacheEntry.data);
}
cacheEntry.waiting = [];
}
};
</script>
将HTML刷新到浏览器后,服务器可以自行执行API查询,并在完成查询后,将JSON数据作为包含数据的脚本标签刷新到页面。 当浏览器接收并解析此HTML响应块时,它将数据插入JSON缓存中。 使用此方法要注意的关键一点是,浏览器在接收到响应块时将逐渐进行渲染(即,它们将在流式传输时执行完整的脚本块)。 因此,您可能会在服务器上并行生成大量数据,并在每个响应准备好立即在客户端执行时将其刷新到自己的脚本块中。 这是Facebook BigPipe系统背后的基本思想,在该系统中,多个独立的Pagelet并行加载到服务器上,并按它们完成的顺序推送到客户端。
<script type="text/javascript">
window.__dataLoaded('/my/api/path', {
// API json response, wrapped in the function call to
// add it to the JSON cache...
});
</script>
当客户端脚本准备好请求其数据时,而不是发出XHR请求,它首先检查JSON缓存。 如果存在响应(或挂起),则它会立即响应,或者等待挂起的响应。
function queryAPI(path) {
const cacheEntry = window.__data[path];
if (!cacheEntry) {
// issue a normal XHR API request
return fetch(path);
} else if (cacheEntry.data) {
// the server has pushed us the data already
return Promise.resolve(cacheEntry.data);
} else {
// the server is still pushing the data
// so we'll put ourselves in the queue to
// be notified when its ready
const waiting = {};
cacheEntry.waiting.push(waiting);
return new Promise((resolve) => {
waiting.resolve = resolve;
});
}
}
这样页面加载行为就变成了下图:
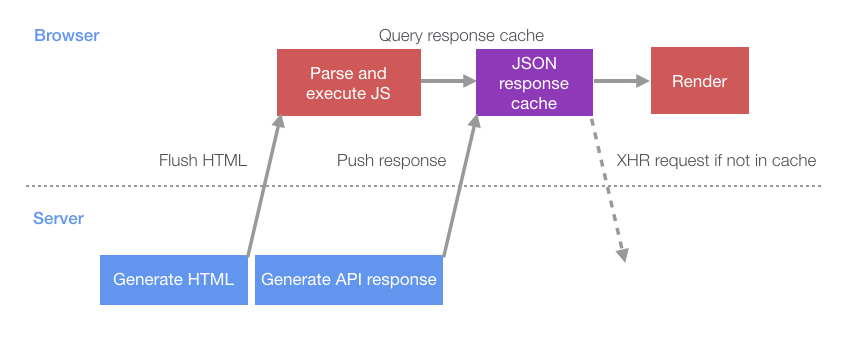
与传统的加载方法相比,服务器和客户端现在可以并行执行更多工作-减少了服务器和客户端彼此等待的空闲时间。 这产生了巨大的影响:桌面用户的页面显示完成时间缩短了14%,而移动用户(具有更高的网络等待时间)则提高了23%。
写在最后
这是Instagram网址优化的第二部,第三部分会介绍基于缓存优先进行渲染,第四部分会介绍优化代码大小和执行优化。请关注奶爸码农公众号,第一时间获得最新信息。

