

上一篇我们介绍了 redis 中的整数集合这种数据结构的实现,也谈到了,引入这种数据结构的一个很大的原因就是,在某些仅有少量整数元素的集合场景,通过整数集合既可以达到字典的效率,也能使用远少于字典的内存达到同样的效果。
我们本篇介绍的压缩列表,相信你从他的名字里应该也能看出来,又是一个为了节约内存而设计的数据结构,它的数据结构相对于整数集合来说会复杂了很多,但是整数集合只能允许存储少量的整型数据,而我们的压缩列表可以允许存储少量的整型数据或字符串。
这是他们之间的一个区别,下面我们来看看这种数据结构。
一、基本的结构定义

- ZIPLIST_BYTES:四个字节,记录了整个压缩列表总共占用了多少字节数
- ZIPLIST_TAIL_OFFSET:四个字节,记录了整个压缩列表第一个节点到最后一个节点跨越了多少个字节,通故这个字段可以迅速定位到列表最后一个节点位置
- ZIPLIST_LENGTH:两个字节,记录了整个压缩列表中总共包含几个 zlentry 节点
- zlentry:非固定字节,记录的是单个节点,这是一个复合结构,我们等下再说
- 0xFF:一个字节,十进制的值为 255,标志压缩列表的结尾
其中,zlentry 在 redis 中确实有着这样的结构体定义,但实际上这个结构定义了一堆类似于 length 这样的字段,记录前一个节点和自身节点占用的字节数等等信息,用处不多,而我们更倾向于使用这样的逻辑结构来描述 zlentry 节点。
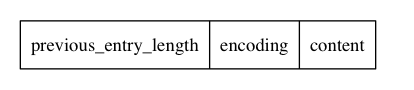
这种结构在 redis 中是没有具体结构体定义的,请知悉,网上的很多博客文章都直接描述 zlentry 节点是这样的一种结构,其实是不准确的。
简单解释一下这三个字段的含义:
- previous_entry_length:每个节点会使用一个或者五个字节来描述前一个节点占用的总字节数,如果前一个节点占用的总字节数小于 254,那么就用一个字节存储,反之如果前一个节点占用的总字节数超过了 254,那么一个字节就不够存储了,这里会用五个字节存储并将第一个字节的值存储为固定值 254 用于区分。
- encoding:压缩列表可以存储 16位、32位、64位的整数以及字符串,encoding 就是用来区分后面的 content 字段中存储于的到底是哪种内容,分别占多少字节,这个我们等下细说。
- content:没什么特别的,存储的就是具体的二进制内容,整数或者字符串。
下面我们细说一个 encoding 具体是怎么存储的。
主要分为两种,一种是字符串的存储格式:
| 编码 | 编码长度 | content类型 |
|---|---|---|
| 00xxxxxx | 一个字节 | 长度小于 63 的字符串 |
| 01xxxxxx xxxxxxxx | 两个字节 | 长度小于 16383 的字符串 |
| 10xxxxxx xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx | 五个字节 | 长度小于 4294967295 的字符串 |
content 的具体长度,由编码除去高两位剩余的二进制位表示。
| 编码 | 编码长度 | content类型 |
|---|---|---|
| 11000000 | 一个字节 | int16_t 类型的整数 |
| 11010000 | 一个字节 | int32_t 类型的整数 |
| 11100000 | 一个字节 | int64_t 类型的整数 |
| 11110000 | 一个字节 | 24 位有符号整数 |
| 11111110 | 一个字节 | 8 位有符号整数 |
注意,整型数据的编码是固定 11 开头的八位二进制,而字符串类型的编码都是非固定的,因为它还需要通过后面的二进制位得到字符串的长度,稍有区别。
这就是压缩列表的基本的结构定义情况,下面我们通过节点的增删改查方法源码实现来看看 redis 中具体的实现情况。
二、redis 的具体源码实现
1、ziplistNew
我们先来看看压缩列表初始化的方法实现:
unsigned char *ziplistNew(void) {
//bytes=2*4+2
//分配压缩列表结构所需要的字节数
//ZIPLIST_BYTES + ZIPLIST_TAIL_OFFSET + ZIPLIST_LENGTH
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
unsigned char *zl = zmalloc(bytes);
//初始化 ZIPLIST_BYTES 字段
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
//初始化 ZIPLIST_TAIL_OFFSET
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
//初始化 ZIPLIST_LENGTH 字段
ZIPLIST_LENGTH(zl) = 0;
//为压缩列表最后一个字节赋值 255
zl[bytes-1] = ZIP_END;
return zl;
}
2、ziplistPush
接着我们看新增节点的源码实现:
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s
,unsigned int slen, int where) {
unsigned char *p;
//找到待插入的位置,头部或者尾部
p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl);
return __ziplistInsert(zl,p,s,slen);
}
解释一下 ziplistPush 的几个入参的含义。
zl 指向一个压缩列表的首地址,s 指向一个字符串首地址),slen 指向字符串的长度(如果节点存储的值是整型,存储的就是整型值),where 指明新节点的插入方式,头插亦或尾插。
ziplistPush 方法的核心是 __ziplistInsert:
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789;
zlentry tail;
//prevlensize 存储前一个节点长度,本节点使用了几个字节 1 or 5
//prelen 存储前一个节点实际占用了几个字节
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLength(ptail);
}
}
if (zipTryEncoding(s,slen,&value,&encoding)) {
//s 指针指向一个整数,尝试进行一个转换并得到存储这个整数占用了几个字节
reqlen = zipIntSize(encoding);
} else {
//s 指针指向一个字符串(字符数组),slen 就是他占用的字节数
reqlen = slen;
}
//当前节点存储数据占用 reqlen 个字节,加上存储前一个节点长度占用的字节数
reqlen += zipStorePrevEntryLength(NULL,prevlen);
//encoding 字段存储实际占用字节数
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
//至此,reqlen 保存了存储当前节点数据占用字节数和 encoding 编码占用的字节数总和
int forcelarge = 0;
//当前节点占用的总字节减去存储前一个节点字段占用的字节
//记录的是这一个节点的插入会引起下一个节点占用字节的变化量
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
if (nextdiff == -4 && reqlen < 4) {
nextdiff = 0;
forcelarge = 1;
}
//扩容有可能导致 zl 的起始位置偏移,故记录 p 与 zl 首地址的相对偏差数,事后还原 p 指针指向
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
if (p[0] != ZIP_END) {
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
//把当前节点占用的字节数存储到下一个节点的头部字段
if (forcelarge)
zipStorePrevEntryLengthLarge(p+reqlen,reqlen);
else
zipStorePrevEntryLength(p+reqlen,reqlen);
//更新 tail_offset 字段,让他保存从头节点到尾节点之间的距离
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
zipEntry(p+reqlen, &tail);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
//是否触发连锁更新
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
//将节点写入指定位置
p += zipStorePrevEntryLength(p,prevlen);
p += zipStoreEntryEncoding(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
具体细节我不再赘述,总结一下整个插入节点的步骤。
- 计算并得到前一个节点的总长度,并判断得到当前待插入节点保存前一个节点长度的 previous_entry_length 占用字节数
- 根据传入的 s 和 slen,计算并保存 encoding 字段内容
- 构建节点并将数据写入节点添加到压缩列表中
ps:重点要去理解压缩列表节点的数据结构定义,previous_entry_length、encoding、content 字段,这样才能比较容易理解节点新增操作的实现。
三、连锁更新
谈到 redis 的压缩列表,就必然会谈到他的连锁更新,我们先引一张图:
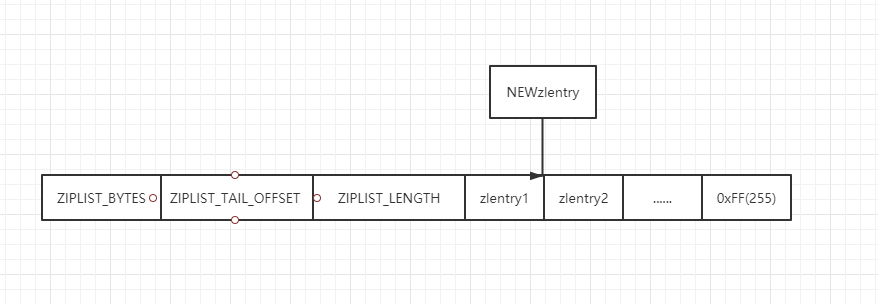
假设原本 entry1 节点占用字节数为 211(小于 254),那么 entry2 的 previous_entry_length 会使用一个字节存储 211,现在我们新插入一个节点 NEWEntry,这个节点比较大,占用了 512 个字节。
那么,我们知道,NEWEntry 节点插入后,entry2 的 previous_entry_length 存储不了 512,那么 redis 就会重分配内存,增加 entry2 的内存分配,并分配给 previous_entry_length 五个字节存储 NEWEntry 节点长度。
看似没什么问题,但是如果极端情况下,entry2 扩容四个字节后,导致自身占用字节数超过 254,就会又触发后一个节点的内存占用空间扩大,非常极端情况下,会导致所有的节点都扩容,这就是连锁更新,一次更新导致大量甚至全部节点都更新内存的分配。
如果连锁更新发生的概率很高的话,压缩列表无疑就会是一个低效的数据结构,但实际上连锁更新发生的条件是非常苛刻的,其一是需要大量节点长度小于 254 连续串联连接,其二是我们更新的节点位置恰好也导致后一个节点内存扩充更新。
基于这两点,且少量的连锁更新对性能是影响不大的,所以这里的连锁更新对压缩列表的性能是没有多大的影响的,可以忽略,但需要知晓。
同样的,如果觉得我写的对你有点帮助的话,顺手点一波关注吧,也欢迎加作者微信深入探讨,我们逐渐开始走近 redis 比较实用性的相关内容了,尽请关注。
关注公众不迷路,一个爱分享的程序员。 公众号回复「1024」加作者微信一起探讨学习! 每篇文章用到的所有案例代码素材都会上传我个人 github github.com/SingleYam/o… 欢迎来踩!

