


作者| 阿里云智能事业群技术专家牛秋霖(冬岛)
导读:从头开发一个Serverless引擎并不是一件容易的事情,今天咱们就从Knative的健康检查说起。通过健康检查这一个点来看看Serverless模式和传统的模式都有哪些不同,以及Knative针对Serverless场景都做了什么思考。
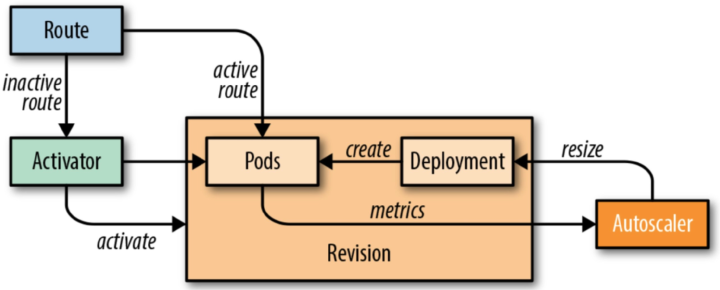
Knative Serving 模块的核心原理如下图所示,图中的 Route 可以理解成是 Istio Gateway 的角色。
- 当缩容到零时进来的流量就会指到 Activator 上面;
- 当 Pod 数不为零时流量就会指到对应的 Pod 上面,此时流量不经过 Activator;
- 其中 Autoscaler 模块根据请求的 Metrics 信息实时动态的扩缩容。
Knative 的 Pod 是由两个 Container 组成的:Queue-Proxy 和业务容器 user-container。架构如下:
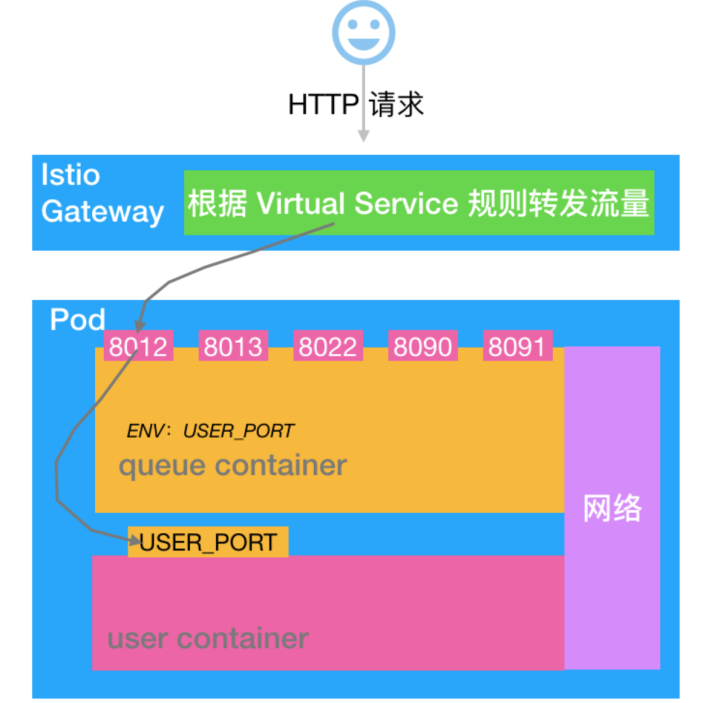
咱们以 http1 为例进行说明:业务流量首先进入 Istio Gateway,然后会转发到 Queue-Proxy 的 8012 端口,Queue-Proxy 8012 再把请求转发到 user-container 的监听端口,至此一个业务请求的服务就算完成了。
粗略的介绍原理基本就是上面这样,现在咱们对几个细节进行深入的剖析看看其内部机制:
- 为什么要引入 Queue-Proxy?
- Pod 缩容到零的时候流量会转发到 Activator 上面,那么 Activator 是怎么处理这些请求的?
- Knative 中的业务 Pod 有 Queue-Proxy 和 user-container,那么 Pod 的 readinessProber 和 LivenessProber 分别是怎么做的?Pod 的 readinessProber、 LivenessProber 和业务的健康状态是什么样的关系?
- Istio Gateway 向 Pod 转发流量的时候是怎么选择 Pod 进行转发的?
为什么要引入 Queue-Proxy
Serverless 的一个核心诉求就是把业务的复杂度下沉到基础平台,让业务代码快速迭代并且按需使用资源。不过现在更多的还是聚焦在按需使用资源层面。
如果想要按需使用资源我们就需要收集相关的 Metrics,并根据这些 Metrics 信息来指导资源的伸缩。Knative 首先实现的就是 KPA 策略,这个策略是根据请求数来判断是否需要扩容的。所以 Knative 需要有一个机制收集业务请求数量。除了业务请求数还有如下信息也是需要统一处理:
- 访问日志的管理;
- Tracing;
- Pod 健康检查机制;
- 需要实现 Pod 和 Activator 的交互,当 Pod 缩容到零的时候如何接收 Activator 转发过来的流量;
- 其他诸如判断 Ingress 是否 Ready 的逻辑也是基于 Queue-Proxy 实现的。
为了保持和业务的低耦合关系,还需要实现上述这些功能,所以就引入了 Queue-Proxy 负责这些事情。这样可以在业务无感知的情况下把 Serverless 的功能实现。
从零到一的过程
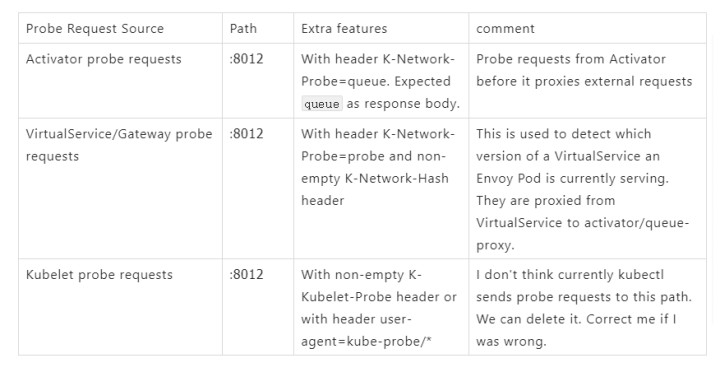
当 Pod 缩容到零的时候流量会指到 Activator 上面,Activator 接收到流量以后会主动“通知”Autoscaler 做一个扩容的操作。扩容完成以后 Activator 会探测 Pod 的健康状态,需要等待第一个 Pod ready 之后才能把流量转发过来。所以这里就出现了第一个健康检查的逻辑:Activator 检查第一个 Pod 是否 ready。
这个健康检查是调用的 Pod 8012 端口完成的,Activator 会发起 HTTP 的健康检查,并且设置 K-Network-Probe=queue Header,所以 Queue Container 中会根据 K-Network-Probe=queue 来判断这是来自 Activator 的检查,然后执行相应的逻辑。
参考阅读
VirtualService 的健康检查
Knative Revision 部署完成后会自动创建一个 Ingress(以前叫做 ClusterIngress), 这个 Ingress 最终会被 Ingress Controller 解析成 Istio 的 VirtualService 配置,然后 Istio Gateway 才能把相应的流量转发给相关的 Revision。
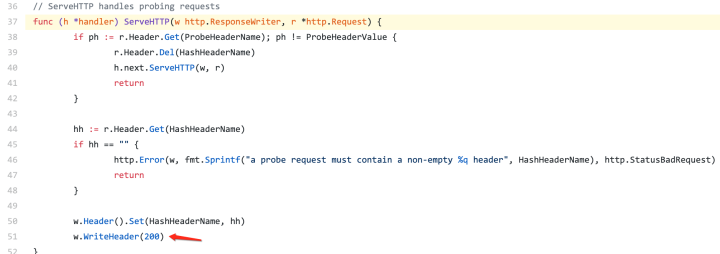
所以每添加一个新的 Revision 都需要同步创建 Ingress 和 Istio 的 VirtualService ,而 VirtualService 是没有状态表示 Istio 的管理的 Envoy 是否配置生效能力。所以 Ingress Controller 需要发起一个 http 请求来监测 VirtualService 是否 ready。这个 http 的检查最终也会打到 Pod 的 8012 端口上。标识 Header 是 K-Network-Probe=probe 。Queue-Proxy 需要基于此来判断,然后执行相应的逻辑。
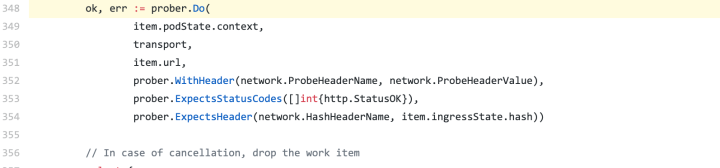
相关代码如下所示:
参考阅读
Gateway 通过这个健康检查来判断 Pod 是否可以提供服务。
Kubelet 的健康检查
Knative 最终生成的 Pod 是需要落实到 Kubernetes 集群的,Kubernetes 中 Pod 有两个健康检查的机制:ReadinessProber 和 LivenessProber。
- 其中 LivenessProber 是判断 Pod 是否活着,如果检查失败 Kubelet 就会尝试重启 Container;
- ReadinessProber 是来判断业务是否 Ready,只有业务 Ready 的情况下才会把 Pod 挂载到 Kubernetes Service 的 EndPoint 中,这样可以保证 Pod 故障时对业务无损。
那么问题来了,Knative 的 Pod 中默认会有两个 Container:Queue-Proxy 和 user-container 。
前面两个健康检查机制你应该也发现了,流量的“前半路径”需要通过 Queue-Proxy 来判断是否可以转发流量到当前 Pod,而在 Kubernetes 的机制中,Pod 是否加入 Kubernetes Service EndPoint 完全是由 ReadinessProber 的结果决定的。而这两个机制是独立的,所以我们需要有一种方案来把这两个机制协调一致。这也是 Knative 作为一个 Serverless 编排引擎时需要对流量做更精细的控制要解决的问题。所以 Knative 最终是把 user-container 的 ReadinessProber 收敛到 Queue-Proxy 中,通过 Queue-Proxy 的结果来决定 Pod 的状态。
另外这个 Issue 中也提到在启动 istio 的情况下,kubelet 发起的 tcp 检查可能会被 Envoy 拦截,所以给 user-container 配置 TCP 探测器判断 user-container 是否 ready 也是不准的。这也是需要把 Readiness 收敛到 Queue-Proxy 的一个动机。
Knative 收敛 user-container 健康检查能力的方法是:
- 置空 user-container 的 ReadinessProber;
- 把 user-container 的 ReadinessProber 配置的 json String 配置到 Queue-Proxy 的 env 中;
- Queue-Proxy 的 Readinessprober 命令里面解析 user-container 的 ReadinessProber 的 json String 然后实现健康检查逻辑,且这个检查的机制和前面提到的 Activator 的健康检查机制合并到了一起。这样做也保证了 Activator 向 Pod 转发流量时 user-container 一定是 Ready 状态。
参考阅读
- Fix invalid helloworld example 这里面有比较详细的方案讨论,最终社区选择的方案也是在这里介绍的。
使用方法
如下所示可以在 Knative Service 中定义 Readiness。
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: readiness-prober
spec:
template:
metadata:
labels:
app: helloworld-go
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:160e4db7
readinessProbe:
httpGet:
path: /
initialDelaySeconds: 3需要说明两点:
- 和原生的 Kubernetes Pod Readiness 配置相比,Knative 中 timeoutSeconds、failureThreshold、periodSeconds 和 successThreshold 如果要配置就要一起配置,并且不能为零,否则 Knative webhook 校验无法通过。并且如果设置了 periodSeconds,那么一旦出现一次 Success,就再也不会去探测 user-container(不建议设置 periodSeconds,应该让系统自动处理)。
- 如果 periodSeconds 没有配置那么就会使用默认的探测策略,默认配置如下:
timeoutSeconds: 60
failureThreshold: 3
periodSeconds: 10
successThreshold: 1从这个使用方式上来看,其实 Knative 是在逐渐收敛 user-container 配置,因为在 Serverless 模式中需要系统自动化处理很多逻辑,这些“系统行为”就不需要麻烦用户了。
小结
前面提到的三种健康检查机制的对比关系:
本文为云栖社区原创内容,未经允许不得转载。
