

工作日记是笔者记录在日常工作中对负责的前端项目和任务的总结和提炼,在工作中寻乐趣,在代码中找灵魂,输出工作中有价值有意思的沉淀,用娱乐精神分享知识。
wx:wxid_wdjyyo939vja22
很多朋友都知道我们团队是在智能音箱上开发语音技能业务,问答类和剧情类是语音技能中常见的两大类,其中剧情类是我们家游戏重中之重。
剧情游戏的数据结构是树,称为剧情树。上线游戏之前,得先在后台手动录入剧情树,包括创建剧情节点、填入语料信息、关键词等等。故事内容小的不出一百个剧情节点,大的还要划分章节,剧情节点总数可达千级以上。
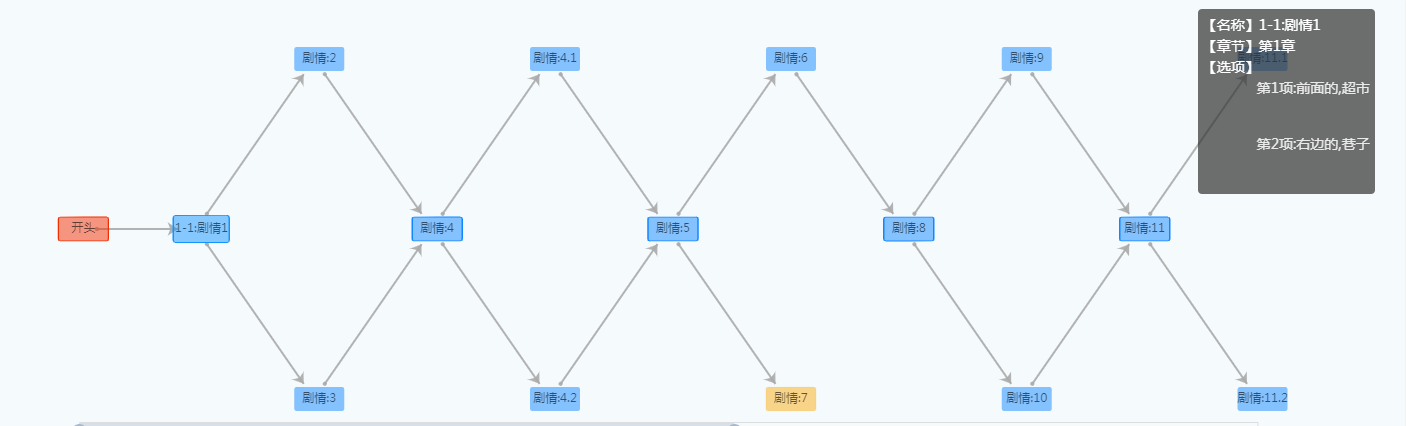
那么人工录入这颗庞大的剧情树的时间成本会制约剧情游戏上线时间,况且这么多数据靠人工操作,那人岂不是要心态爆炸。
有大佬说过:有麻烦的地方,就有机会。谁说的我想不起来。

况且不忍心看着运营妹子把青春都浪费在重复无价值的工作上,于是就有了我,一位技术不咋地但乐善好施的前端专业切图手,挺身而出,做了以下事情。

工作流分析
把录入剧情树的工作流程画成图来表达会更加容易说明问题:
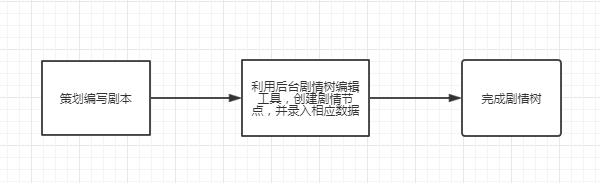
很简单的一个工作流,把效率不高的环节拆分成多个组合因素,这里的目的主要是录入剧情树的相关信息,把信息分类如下:
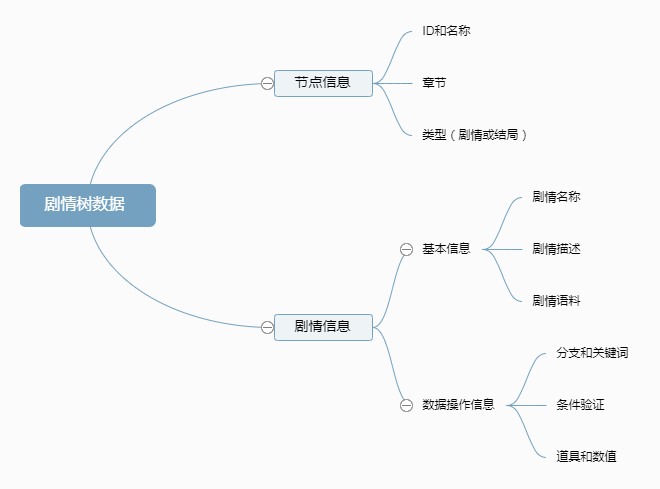
其中有些信息是可以直接从剧本中去是识别提炼出来形成结构化数据,将这个任务自动化,交给机器来处理,人工只负责剧本不需要出现、数据操作类的信息,那么一下步就是按自动/人工的范畴来重整信息。
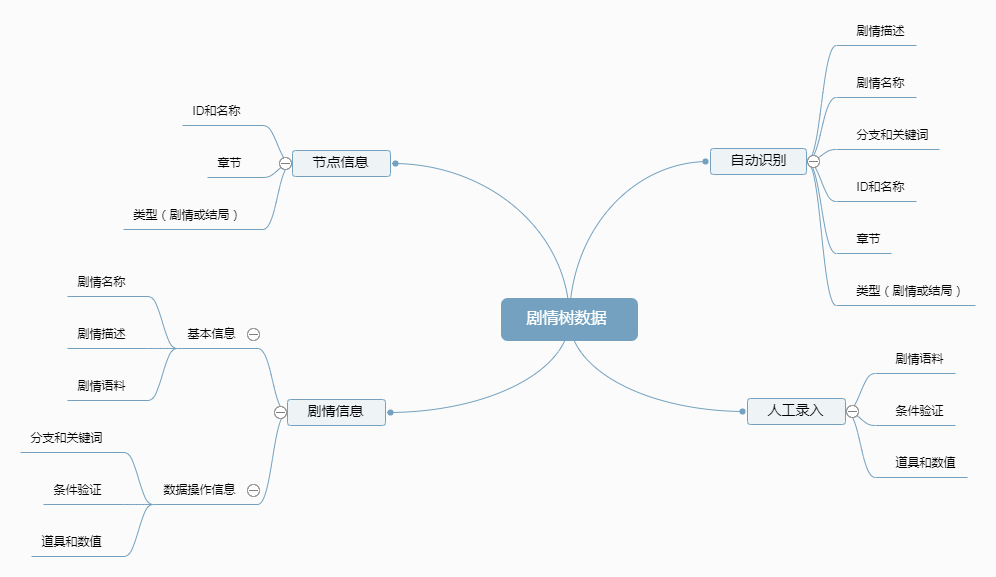
右边的就是重整后的信息分类,两个分类可以演化成两个新阶段,机器分析剧本自动化阶段和人工补全阶段,替换掉前面效率低下的部分就可以形成新的工作流:
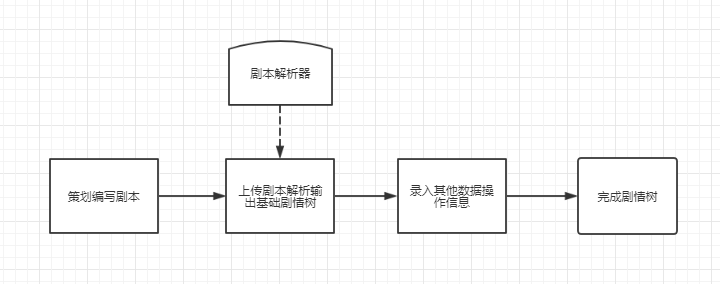
优化升级后的工作流需要一个剧本分析器来为它赋能。
现在的感觉就像仿佛看见了曙光。

你以为我会现在马上动手做吗?不,这仅仅是我歪歪的一个东西,并没有经过各方面的认同,需要请求下产品和技术老大的意见,否者辛辛苦苦做出来,得不到大家认同,没有功劳更没有苦劳。
项目立项
在周会上回报工作情况时候,顺水推舟的拿出上面的工作流分析,向组内提出了这个优化方案。大伙也没啥意见,反正不用他们搬砖,真是替你们有我这么个好伙伴感到开心。

接着找到产品,需要确定两点:
- 剧情剧本的统一格式(假如策划伙伴每人各持一套,兼容代码会让人写到吐)
- 解析器具体的功能点
最终这个项目的面貌逐渐清晰:
- 剧本格式
第一章 互动
...
1. 已经是晚上11点了
你的女神突然很想吃宵夜
你会帮她叫外卖还是让她赶紧睡觉?
(1-1: 帮她叫外卖,叫外卖,外卖。1-2: 让她赶紧睡觉,赶紧睡觉,睡觉)
...
- 功能
- 上传.docx文档剧本
- 解析提出信息
- 验证剧情树结构
- 输出结构化数据
实现需求
这里我们直接看关键功能:解析剧本提炼信息。这里就包含两个步骤:解析docx文档和识别提炼信息。
- 解析docx文档
自己实现个解析docx文档程序?一般人不会那么干,那是牛人做的事情。

mammoth.js可以解决这个问题。
Mammoth is designed to convert .docx documents, such as those created by Microsoft Word, and convert them to HTML.
意思是主要用于将word的.docx文档转换成HTML文档,除此之外mammoth有个extractRawText方法可以转换成row text行文本,以换行符划分。
将解析文档功能封装成函数:
const mammoth = require('mammoth');
/**
* 解析docx文本内容并导出
*
* @param {String} path .docx 路径
*/
const extractRawText = function (file) {
const opt = {};
if (file instanceof Buffer) {
opt.buffer = file;
} else if (typeof file === 'string') {
opt.path = file;
} else {
global.log_debug.error(`[parseDocxScript]:${file} 未知类型`);
throw new Error(`${file} 未知类型`);
}
return new Promise(resolve => {
mammoth.extractRawText(opt)
.then(function (result) {
resolve(result); // {value, message}
});
});
};
文档内容以String类型存在于result.value中,其中换行符会被转换成\n\n。
- 识别并提炼信息
识别就是字符串遍历和检测,利用正则表达式足以解决,其实就是使用标记法,待识别的数据有其相关的标记。
根据剧本格式,需要正则识别的信息有:
- 章节:第一章
/第(.*)章(.*)$/
- 剧情编号(ID):2. 2-1.
/^([\d\-]+)\./
- 分支:(5:回复,回。6:不理会)
/^[(\()](.*)[)\)]$/
- 分支中的剧情编号
/([\d\-]+)/
可以以\n\n为分隔符将内容切分成数组,遍历去逐行识别检验。
code
/**
* 解析剧本,结构化信息
*
* @param {String} path .docx 路径
* @param {Object} opt 拼装数据需要的参数sceneId
*/
const parseScript = function (file, opt = {}) {
return extractRawText(file)
.then(result => {
var text = result.value;
var aSource = text.split('\n\n');
var temp = aSource.filter(v => !!v);
var dialog = {},
dialogs = [],
chapters = [],
currId,
currChar;
console.log(temp);
temp.forEach(v => {
var matchIdReg = /^([\d\-]+)\./, // 2 2-1
matchNextIdReg = /([\d\-]+)/,
matchChooseText = /^[(\()](.*)[)\)]$/,
matchChapText = /第(.*)章(.*)$/,
res;
// 解析章节
res = v.trim().match(matchChapText);
if (res) {
var chapNo = currChar = zhDigitToArabic(res[1]);
var isExit = !!chapters.find(v => v.chapNo === chapNo);
!isExit && chapters.push({
chapNo,
title: res[2].trim()
});
}
// 识别节点
res = v.match(matchIdReg);
if (res) {
dialog = {};
currId = dialog.id = res[1];
currChar && (dialog.chapNo = currChar);
v = v.replace(matchIdReg, '');
}
// 判断分支语句
res = v.match(matchChooseText);
if (res) {
const t = res[1];
t.split(/[。;]/).forEach(v => {
// v => 2:xxx || 接4
var item = {},
keyword;
res = v.match(matchNextIdReg);
if (res === null) return;
item.nextId = res[1];
keyword = v.split(':')[1];
keyword && (item.keywords = keyword.trim().split(','));
!dialog.children && (dialog.children = []);
dialog.children.push(item);
});
} else {
// 处理内容语句
if (currId === dialog.id && !/【全文完】/.test(v)) {
if (dialog.content === undefined) dialog.content = '';
dialog.content += `${v}\n\n`;
}
}
// 装载dialog
if (dialog.id && dialog.content && !dialogs.includes(dialog)) dialogs.push(dialog);
});
return { dialogs, chapters }
};
效果和收益
当打通流程之后,只需轻轻点击上传剧本,弹指一挥间,一棵可爱的剧情树已经出现在你面前,处理时间平均200+ms,整个过程1s不到。
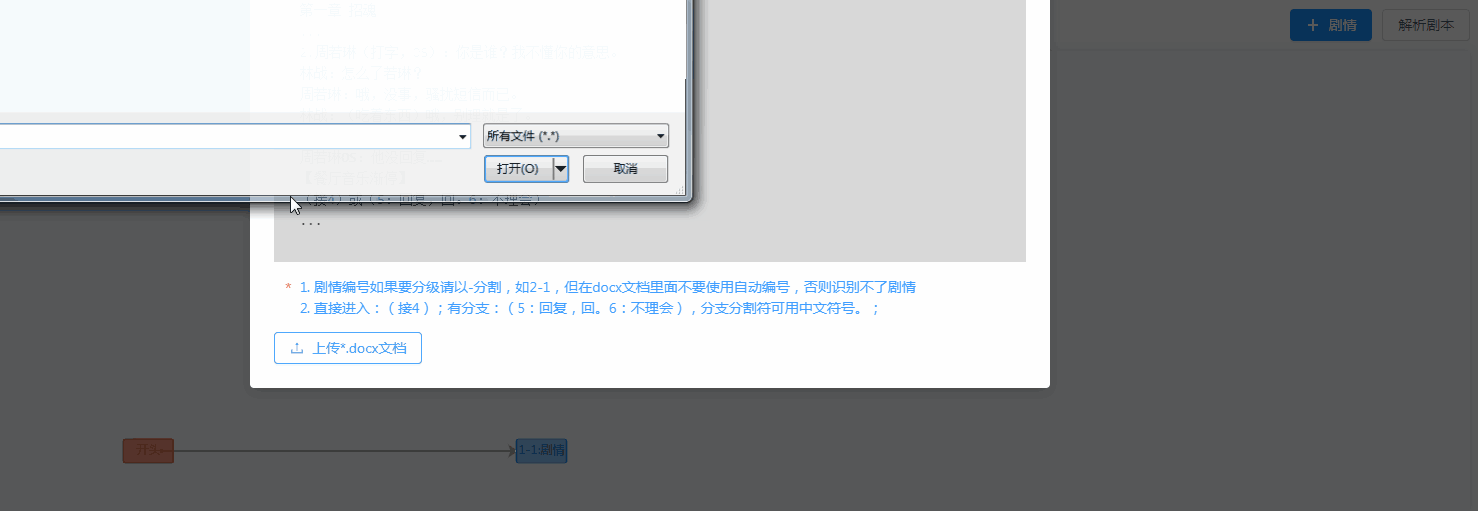
之前完整的配一个复杂的剧情树要配一天,目前只需要两小时不到。在效率上得到了大幅度的提升,对于运营伙伴来说简直是如获至宝,用他们的话来说就是大快人心。

