本篇涉及到分布式事务的原理与Spanner事务实现,需要大概理解单机数据库事务,如果还不理解,可以先看看之前的两篇:
为了让下面的阅读不那么枯燥,先抛出几个问题大家可以思考一下:
- 分布式事务相比单机事务,有何难点?如何解决?
- 为什么在同一个Spanner事务中,提交之前完全读不到自己的写入?
- 什么是外部一致性?
- Spanner事务有哪些类型?分别适用于什么场景?
- Spanner读取是加锁还是MVCC?
- Spanner每个Paxos Group的每秒事务吞吐量是否有限制?
一、分布式事务原理
要理解一个特定技术,就先理解这个技术所基于的通用原理,所以这里不马上开始讲Spanner的事务实现,而是先讲分布式事务的原理。
1. 分布式事务所面临的问题
在事务的ACID中,对于单机数据库,A(原子性)、C(一致性)是很容易被满足的,基于undo log满足A,基于redo log、加锁满足C,但是对于分布式数据库却比较困难,不止是由于从单机到多机,复杂性的提高,还因为中间有“网络”这个不稳定因素。
挑战1:原子性
事务需要满足A:要么全部失败,要么全部成功,对于单机数据库,只要将事务写入日志,就能够保证此事务可以全部回滚或者可以全部提交,而分布式事务是多机事务,每个机器的情况不同,有的机器可能写日志成功,有的机器可能写日志失败(比如因为获取锁失败),也就是会出现部分成功部分失败的情况,因此分布式数据库该如何保证原子性,是一个挑战。
挑战2:事务顺序
后开始的事务要能够读到在它开始前已经结束的事务的写,为了正确的MVCC,事务需要有单调递增(Monotonically Increasing)的时间戳或者事务序号保证逻辑顺序。
在单机数据库要保证单调递增不是个问题,但是分布式数据库多点的,要如何保证为冲突事务分配的序号是单调递增就是个问题。
挑战3:不稳定的网络
单机的通讯是稳定的,一个操作无论失败还是成功,调用者都知道自己能够在未来的某个点得到确定的回复,而分布式数据库则只能通过网络通讯,网络是不稳定的,可能对方收不到你的指令,或者你收不到对方的回复,该怎么保证分布式事务的可用性,也就是在用户能够容忍的时间内得到确定的答复。
2. 分布式事务解决思路
二阶段提交(2PC)
对于上面说的原子性与不稳定的网络这两个挑战,目前分布式事务比较通用的解决方案是二阶段提交(Tow-Phase Commit),缩写为2PC,Spanner、TiDB都使用二阶段提交,它将提交分为准备和最终提交两个阶段,注意这里说的“最终提交”和“提交”的区别,为了避免混淆,“提交”还是原本的语义,代表着client发出的commit,而“最终提交”是指2PC中的提交阶段,是被DB发起的,不是被client。
分布式事务往往意味着有2个或以上的DB参与,2PC中会有不同的角色分工,其中有一台机器是协调者(Coordinator),可以理解为Team Leader,其余的都是参与者(Participant)。
第一阶段:准备(prepare)
当client发起提交后,开始进入2PC的第一阶段——准备,也叫投票(Vote),协调者通知参与者开始准备,每个参与者都在本机执行事务,注意,这里只是执行,不是提交,执行意味着可能只是获取锁、写日志,而不是apply这些变更(mutation),参与者负责确认属于自己的写入能否成功,如果可以,则需要向协调者返回yes,如果无法在本机成功执行事务,则返回no。
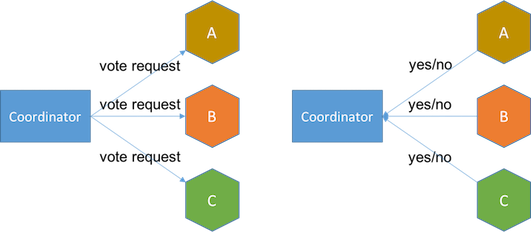
在协调者发出prepare的指令后,会根据参与者的情况作出提交(commit)还是中止(abort)的决定,有两个因素决定最后的选择:
- 等待期
- 参与者的回复
关于等待期,由于网络的不确定性,协调者发出的指令可能不能被每个参与者都收到,或者参与者发出的回复不能被协调者收到,并且这个不稳定性是一直存在的,不能确定在client可接受的时间内一定能得到答复,超出client可接受的时间是不满足可用性(CAP中的A)的,因此协调者不能一直等下去,需要设置一个等待期,超出等待期还未得到所有参与者的回复,就直接认为未回复的参与者是say no而不是yes,协调者会直接作出abort的决定。
关于第二点——参与者的回复,如果协调者在等待期内如果成功收到所有参与者的答复,则开始下一步判断,如果全部say yes,也就是回答“可以提交”,并且协调者自己也处于可提交状态,那么就会作出commit决定,如果有任何一个参与者返回了无法提交,或者协调者自己无法提交,那么协调者会作出abort决定。
第二阶段:最终提交(final commit)
协调者作出决定后进入第二阶段——最终提交,注意这个“最终提交”,并不是说它一定会commit,而只是说这是一个最终执行决定的阶段,最终提交阶段可能有两种结果:commit与abort,也就是提交或者中止,提交会apply所有变更,中止则仅仅释放锁,不apply变更,就像事务没有发生。
对于参与者来说,当它对第一阶段作出了yes or no的响应后,它就已经进入了第二阶段,等待协调者的决定,并执行决定。这个阶段可以是协调者主动将决定发送给参与者,也可以是参与者主动轮询,2PC是一种算法,具体实现不同。
协调者作出决定后进入第二阶段,它会将决定写入日志,写入成功后,提交自己的事务,然后向client返回成功。注意这里,协调者无需等待参与者成功,可以直接向client返回,参与者通过接收协调者指令或者自己轮询获得协调者的决定后,异步提交即可。
为什么可以允许参与者异步提交?
很简单因为每个参与者都已经成功执行了事务写入了日志,一旦日志落盘,就代表事务已经保证100%可以成功,那么协调者的决定只是将事务的变更正式apply并释放锁,释放锁与apply都可以是异步,不影响这个事务能够“成功”的保证,因此可以放心地返回给client。
2PC主要的思想就是先确定大家都能成功,才作出提交决定,如果有任意参与者可能无法成功,就作出中止决定。
二、Spanner事务实现
Spanner事务模型是2PC的实现,所以在看下去之前,务必对2PC有一定的理解。
1. 外部一致性(External Consistency)
我们先由远及近地看Spanner,从Spanner的表现到Spanner的实现。**外部一致性(External Consistency)**是Google提出来的概念,这里所说的外部可以理解为client,也就是对于client来说,它观察到的两个事务的顺序一定与它们的提交顺序相同,因此如果事务1在事务2之前commit,那么事务2一定能够读取到事务1的变更。如下图:
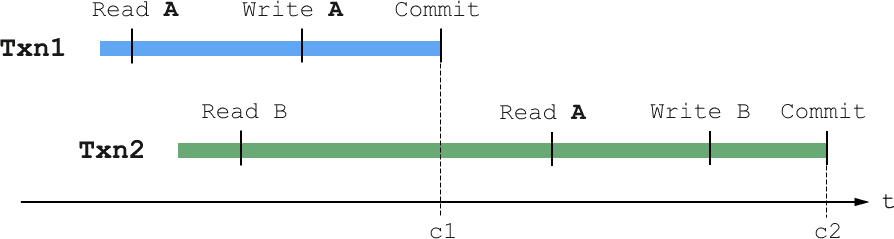
虽然事务2在事务1提交前就已开始,但是它的commit更晚,一定能够读到事务1的变更。
外部一致性只是基于Spanner事务模型最后的结果,是表现,而不是原因,因此这里只需要知道Spanner事务最后是这样的表现即可,为的是让大家自顶向下带着问题去反向思考如何实现这个效果。
2. TrueTime
分布式事务一定需要解决上面说到的3个挑战,这里先来说说挑战2——事务顺序,在分布式中如何保证事务序号是递增的呢,很容易想到授权一个单点去分配事务序号,每个事务都从这个单点拿序号,在Google Percolator这个事务模型中,就有一个全局的授时服务器(TSO),所有事务都从TSO获取一个时间戳作为自己的序号,因此它一定是单调递增的,当然为了保证可用性,这个单点本身也可以是一个集群,比如TiDB就将PD集群作为TSO。
但是Spanner并不使用全局发号器的方式,因为他有一个黑科技——TrueTime,这是靠硬件实现的,每个数据中心都有一些time master,大多数master都配置了GPS,剩下的少数master配置了原子钟,通过一定的算法与校准,它们的时间与真实的绝对时间几乎完全相同,所有DB会每30秒去向这些服务器校准一次自己的时间,以保证自己的时间也与真实绝对时间几乎完全相同,这就保证了每台DB server的时间与真实绝对时间的误差都在几毫秒内,而传统NTP校准的误差则在几百毫秒,因此TrueTime保证了DB server都几乎接近于准确时间,因此完全不需要全局发号器,因为每台server的时间都几乎相同。
TrueTime是一套API,调用TT.now()则会返回一个[earliest, latest],表示此时真实的绝对时间最早是什么时候,最晚是什么时候,时间一定落在这个区间内。

3. 事务分类
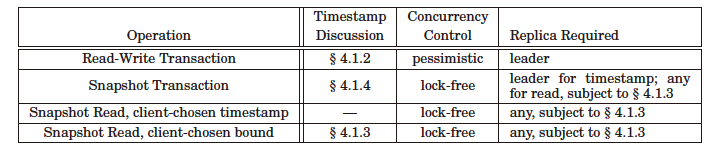
Spanner将事务分为两类读写事务(Read Write Transaction)与只读事务(Read Only Transaction)。
只读事务又分为
- Snapshot Transaction(强读)
- Client-chosen Timestap Read(client指定过期的某个timestamp去读取)
- Client-chosen Bound Read(client指定一个不能超过的最早timestamp去读取)
只读事务都是基于Snapshot的Transaction,它们都是无锁(lock-free)的。
读写事务中无论读写都会上锁,基于悲观锁。
3. 读写事务(Read Write Transaction)
Spanner并不是所有事务都使用2PC,针对Single Split事务,可以退化为单机事务,使用1PC,在效率上是一种优化,因此对于Single Split与Multiple Split事务,Spanner分别采用了1PC与2PC,下面我们分别来讨论。
Single Split Transaction(1PC)
1PC与2PC本质上并没有区别,都将提交分为了两步走(这里不说两段,只说两步,是为了与二阶段提交中的阶段区分开),第一步是获取锁、写日志,第二步是apply变更、释放锁,唯一的区别是2PC在第一步与第二步之间有一个复杂的决定与通知的过程,要保证所有Split都做出相同的响应:提交或中止。而1PC只是少了中间这个复杂的决定与通知的过程,其他几乎没有区别。
对于Single Split Transaction,其实与一般的单机数据库的事务已经很相似,不过还有一个明显的不同点,那就是Spanner事务模型中,每次Write不是在client API那边执行了SQL就被发送到DB server的,而是全部被缓存在本地,这与MySQL等单机数据库完全不同,对于MySQL,每执行一条Write SQL,都会马上发送到server并且尝试加锁、写日志,而Spanner client会缓存在本地,只有当client调用commit方法时,才会一次性将所有Writes发送到Spanner。由于这种缓存机制,在事务被commit前,都不能读到它自己的任何Writes。
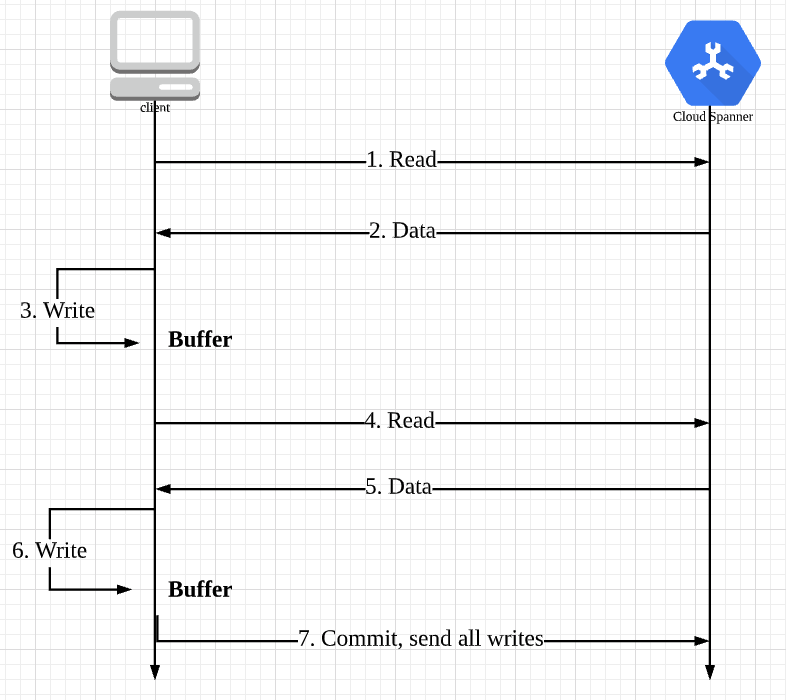
来看一下Spanner的1PC流程:
- Client读数据,立即将读取请求发送到Spanner
- Spanner收到读取请求,为数据加读锁,加锁时如果发现此数据已经被上了写锁,则不能立即上锁,需要等待上了写锁的事务提交后才能继续上锁
- Client写数据,此时只写到本地buffer
- Client完成读写,也就是在SDK中调用commit时,会由client将buffer中的所有Writes发到Spanner
- Spanner开始获取写锁并写日志
- 写锁获取完成并写完日志后,再次检查读锁是否还存在(因为可能已经被伤停等待机制给abort掉了),如果不存在,此事务应该abort
- 主副本(leader replica)使用TrueTime为此次事务生成一个timestamp,作为commit timestamp
- Leader replica(读写事务只能发生在Leader)将log复制给其他replica,同时进行commit-wait,因为TrueTime是一段时间区间,是有误差的,为了保证外部一致性,也就是它提交后,对所有服务器,这个事务都是过去时了,才能提交,commit-wait的实际开销并不大,因为在commit-wait的同时也在进行log的复制,其中空转的时间是非常少的,当大多数replica都复制成功后,并且commit-wait结束,可以向client返回事务已经成功commit,同时apply事务变更到状态机并释放锁。
伤停等待(Wound-Wait)
Spanner是不可能出现死锁的,得益于伤停等待机制。
在获取锁的过程中可能会遇到有的记录已经被加上锁,如果被持有的是写锁,则需要等待持有锁的事务commit或abort,如果被持有的是读锁,则使用伤停等待(wound-wait),首先Spanner会进行死锁检测,如果这里不存在死锁,那么事务等待这个读锁释放,如果存在死锁,那么判断目前持有读锁的事务是比自己年轻还是年老,如果比自己年轻,则直接abort这个读锁,如果比自己年老,则需要等待年老事务主动释放锁。伤停等待完全避免了死锁,同时也避免了饿死现象。
Multiple Split Transaction(2PC)
Multiple Split Transaction使用2PC,但是和1PC差别并不大,主要是由于单Paxos Group的事务变成了多Paxos Group事务,需要增加协调者,会增加以下步骤:
- client会负责发起2PC,在发送Writes到Spanner时,client会先查找到自己应该分别把Writes发送到哪些服务器,将Writes分别发送给他们,并且client会从这些Leader Replica中选一个作为Coordinator(读写事务只能发生在Leader,因此这里不讨论其他replica)。
- 在每个Participant成功获取所有写锁后,会生成一个prepare timestamp,然后通过Paxos将log(其中包含了锁),复制到大多数副本,然后将prepare timestamp发送给Coordinator,表示自己ok
- Coordinator收到所有Participant的prepare timestamp后,会生成一个commit timestamp,这个timestamp一定会大于所有prepare timestamp,并大于TT.now().latest
- Coordinator会在commit-wait结束之后才将commit指令发给Participant
commit-wait局限性
因为选择commit timestamp S 时必须保证 S 大于TT.now().latest,然后真正的提交时间又需要大于 S.latest,如果TrueTime的误差为 ε ,因此这里进行了 2ε 的wait,TrueTime的平均误差是4ms,因此一个Paxos Group每秒吞吐量是 1000 / 2*4 = 125 事务/s,TrueTime误差越小,吞吐量越高。
这里也引发一个思考,由于吞吐量被commit-wait限制,如果不恰当的表设计导致热点(Hotspot),那么大量的读写事务会到达同一个Split,因此会导致每秒吞吐量很低,对于较多读写事务的表,应该特别注意避免热点。
4. 只读事务(Read Only Transaction)
只读事务都基于时间戳,也就是基于MVCC,因此它们都是无锁的(lock-free),其中强读(Strong Read)不需要client提供timestamp,因此Spanner是需要在Replica Leader先获取目前最新数据的timestamp,然后在任何replica读取。除强读之外,其他都可以称作过时读取(Stale Read),都由client指定了想要读取的timestamp或者可以容忍的最早timestamp,因此都不用先经过Leader获取timestamp,可以在任意replica完成。
不过以上3种读取,在完成读取前,replica会先检查自己是否有足够新的数据能够满足读取,如果不够,会向Leader同步。
并不是整个事务周期中只有读取就算是只读事务,而是需要client事先声明开启的这个事务是只读的,否则会被当做读写事务执行。例外情况是,执行不被显式放进事务的单条读取,不需要显式声明,也会被当作只读事务对待。
5. 盲写(Blind Write)
当一个读写事务中没有任何读取,只有写入时,称为盲写,Spanner对于盲写有优化,它不为盲写加排他(exclusive)写锁,加的是共享写锁(share write),共享写锁完全兼容,它们按照commit timestamp排序执行,共享写锁也与读锁兼容,因此不会锁住其他事务的读取,提高并发。