

看完了《漫画算法—小灰的算法之旅》第一遍,觉得有些意犹未尽,因此第二次重温时,打算开始做一些笔记,这样可以加深自己对算法知识的理解,也能对没有看过这本书的朋友提供一些帮助。本文为了各位看官方便,由一篇该为四篇,这是第二篇———排序算法。
排序算法,我以前只知道二分查找法和冒泡排序法,后来才阅读本章内容的时候才发现原来一个简单的排序有10排序逻辑,根据性能排序如下:
| 排序算法 | 平均时间复杂度 |
|---|---|
| 冒泡排序 | O(n2) |
| 选择排序 | O(n2) |
| 插入排序 | O(n2) |
| 希尔排序 | O(n1.5) |
| 快速排序 | O(N*logN) |
| 归并排序 | O(N*logN) |
| 堆排序 | O(N*logN) |
| 基数排序 | O(d(n+r)) |
以上数据摘自由科普中国审核的百度百科词条
1.什么是冒泡排序?
冒泡排序(
bubble sort)是一种基础的交换排序,具体做法:把相邻的元素两两比较,当一个元素大于右侧相邻元素时,交换它的位置;当一个元素小于或者等于右侧相邻元素时,位置不变。如图所示,遍历数组,将每一个元素按照效果图执行排序即可得到最终的效果。
代码实现:
object BubbleSort {
fun sort(array: IntArray){
for (i in array.indices){
for (j in 0 until array.size-i-1){
if(array[j]>array[j+1]){
var temp = array[j]
array[j] = array[j+1]
array[j+1] = temp
}
}
}
}
}
测试代码:
fun sort1(){
val array = intArrayOf(5,8,6,3,9,4,7,1,2,6)
BubbleSort.sort(array)
println(array.contentToString())
}
运行结果:
[1, 2, 3, 4, 5, 6, 6, 7, 8, 9]
接下来我们继续优化,首先看看整个运行过程:
数据源——5,8,6,3,9,4,7,1,2,6
第一次——5,6,3,8,4,7,1,2,6,9
第二次——5,3,6,4,7,1,2,6,8,9
第三次——3,5,4,6,1,2,6,7,8,9
第四次——3,4,5,1,2,6,6,7,8,9
第五次——3,4,1,2,5,6,6,7,8,9
第六次——3,1,2,4,5,6,6,7,8,9
第七次——1,2,3,4,5,6,6,7,8,9
第八次——1,2,3,4,5,6,6,7,8,9
第九次——1,2,3,4,5,6,6,7,8,9
第十次——1,2,3,4,5,6,6,7,8,9
通过分析发现,第八次到第十次的结果与第七次排序没有差别,换句话说就是第八到第十次排序是徒劳的。这个地方我们看看能不能通过一个标志位来解决徒劳的浪费问题? 代码实现:
// 第一轮优化后的冒泡排序
fun sort2(array: IntArray){
for (i in array.indices){
// 标志位
var isSorted = true
for (j in 0 until array.size-i-1){
if(array[j] > array[j+1]){
var tmp = array[j]
array[j] = array[j+1]
array[j+1] = tmp
// 有元素交换,修改标志位
isSorted = false
}
}
if(isSorted)break
}
}
测试代码与上面相似,且结果是一致的,这里就不贴代码了。上面优化的是外部的大循环,那么里面的小循环能不能优化呢? 我们先看看书上的示例:34215678
再看看运行的动图:
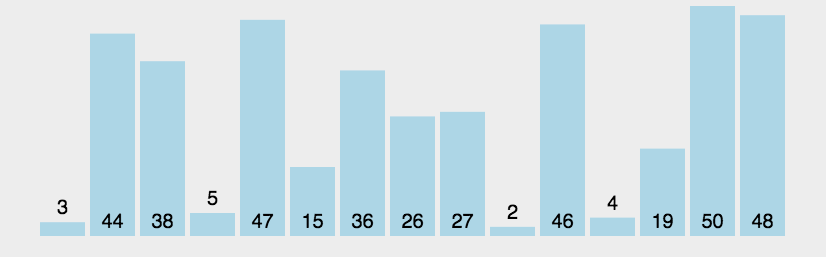
5678忽略?继续看代码实现:
// 第二轮优化 冒泡排序
fun sort3(array: IntArray) {
// 记录最后一次交换的位置
var lastExchangeIndex = 0
// 排序边界
var sortBorder = array.size - 1
for (i in array.indices) {
// 标志位
var isSorted = true
for (j in 0 until sortBorder) {
if (array[j] > array[j + 1]) {
var tmp = array[j]
array[j] = array[j + 1]
array[j + 1] = tmp
// 有元素交换,修改标志位
isSorted = false
// 交换元素的边界
lastExchangeIndex = j
}
}
sortBorder = lastExchangeIndex
if (isSorted) break
}
}
测试代码:
fun sort1(){
val array = intArrayOf(2,4,1,5,3,6,7,8,9)//5,8,6,3,9,4,7,1,2,6
// BubbleSort.sort(array)
// BubbleSort.sort2(array)
BubbleSort.sort3(array)
println(array.contentToString())
}
运行结果:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
一个简单的冒泡排序,我们写了三种。其实还有一种基于冒泡排序的升级排序方法:鸡尾酒排序
鸡尾酒排序(双向冒泡排序)
冒泡排序是依次从左至右的单向排序,而鸡尾酒排序则是从左至右,然后从右至左的钟摆式双向排序,具体过程见下面
gif动图图片源自 blog.csdn.net/sgn132/arti…


知道具体原理了,接下来我们再看看代码如何实现?
// 双向排序 鸡尾酒排序
fun sort4(array: IntArray){
var tmp = 0
for (i in 0 until array.size/2){
// 标志位
var isSorted = true
for (j in i until array.size-i-1){
if(array[j] > array[j+1]){
tmp = array[j]
array[j] = array[j+1]
array[j+1] = tmp
isSorted = false
}
}
if(isSorted)break
isSorted = true
for (k in array.size-i-1 downTo i+1){
if(array[k] < array[k-1]){
tmp = array[k]
array[k] = array[k-1]
array[k-1] = tmp
isSorted = false
}
}
if(isSorted)break
}
}
代码测试:
fun sort1(){
val array = intArrayOf(2,4,1,5,3,6,7,8,9)//5,8,6,3,9,4,7,1,2,6
// BubbleSort.sort(array)
// BubbleSort.sort2(array)
// BubbleSort.sort3(array)
BubbleSort.sort4(array)
println(array.contentToString())
}
测试结果:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
2.什么是快速排序?
快速排序(
Quicksort)和冒泡排序一样,都是交换排序,在每一轮挑选一个基准元素,并让其它比它大的元素移动到数列的一边,比它小的元素移动到数列的另一边,从而把数列拆解成两个部分。这个思路称之为分治法。
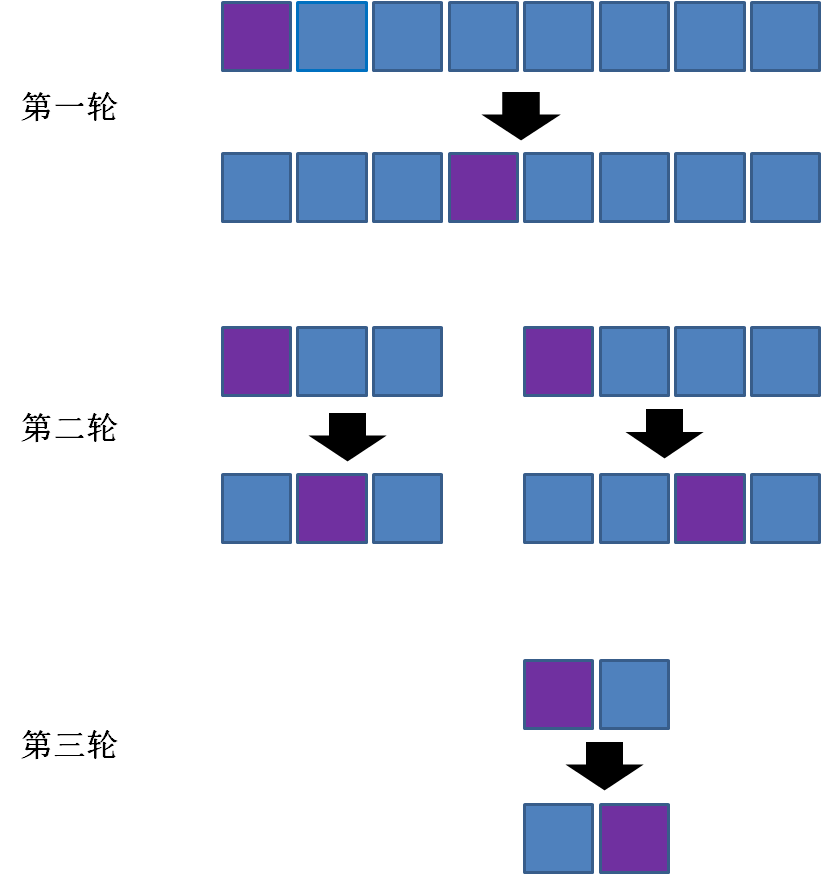
单边循环法
如果觉得这个概念比较绕,你可以直接理解为将数组分成一半,然后对一半再分成一半的递归。如果实在不能理解,那我们来看看代码是怎么解释这件事的:
/**
* <p>文件描述:快速排序的实现<p>
* <p>@author 烤鱼<p>
* <p>@date 2019/11/01 0027 <p>
* <p>@update 2019/11/01 0027<p>
* <p>版本号:1<p>
*
*/
object QuickSort {
// 快速排序
fun sort(array: IntArray, startIndex: Int, endIndex: Int) {
// 递归结束条件
if (startIndex >= endIndex) return
val pivotIndex = partition(array, startIndex, endIndex)
// 根据基准元素,对分成两部分的数组进行递归排序
sort(array, startIndex, pivotIndex - 1)
sort(array, pivotIndex + 1, endIndex)
}
// 获取基准元素
// arr 需要排序的数组
// startIndex 获取基准元素的起点边界
// endIndex 获取基准元素的终点边界
private fun partition(array: IntArray, startIndex: Int, endIndex: Int): Int {
// 获取基准元素 默认获取第一个,也可获取其它任意元素
// 根据数据情况选择不同的基准元素可以提高效率
val pivot = array[startIndex]
var mark = startIndex
for (i in startIndex+1..endIndex){
if(array[i] < pivot){
mark++
val tmp = array[mark]
array[mark] = array[i]
array[i] = tmp
}
}
array[startIndex] = array[mark]
array[mark] = pivot
return mark
}
}
接下来测试一波,看看效果:
fun quickSort(){
val array = intArrayOf(4,6,5,2,8,9,7,5,1,3)
QuickSort.sort(array,0,array.size-1)
println(array.contentToString())
}
测试结果:
[1, 2, 3, 4, 5, 5, 6, 7, 8, 9]
上面的代码结合示意图应该很好的理解,但是不知道各位童鞋发现没有,这个过程和冒泡排序很类似,都是一轮一轮的不断交换顺序,那么我们能不能像鸡尾酒一样从两端钟摆式的双向循环呢?答案是肯定的!
双边循环法
先看看一个示例图:





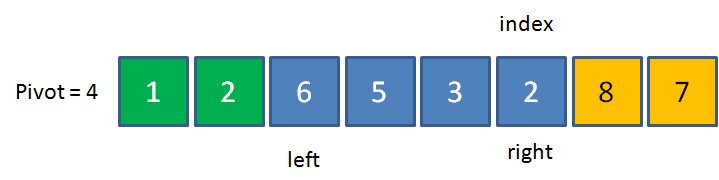
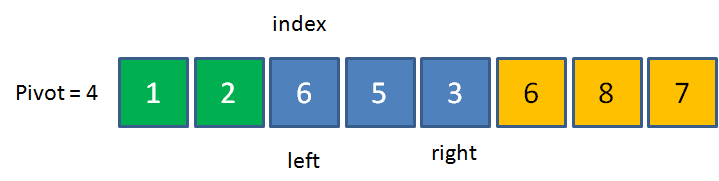
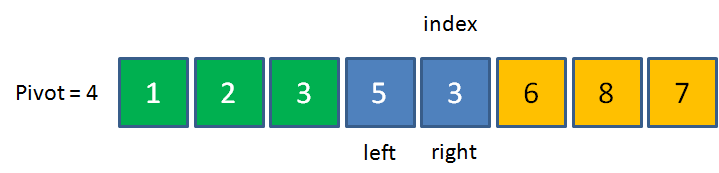
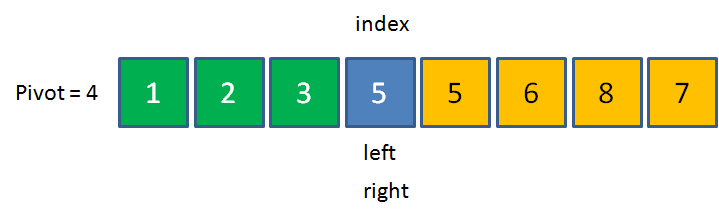
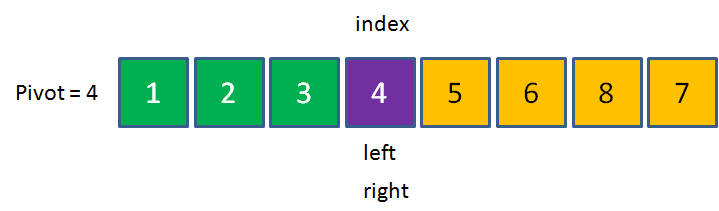
知道是怎么一回事了吗?不知道的话,我们再看看代码怎么实现?
// 快速排序
fun sort(array: IntArray, startIndex: Int, endIndex: Int,isDouble:Boolean) {
// 递归结束条件
if (startIndex >= endIndex) return
val pivotIndex = if(isDouble){
partitionWithDouble(array, startIndex, endIndex)
}else{
partition(array, startIndex, endIndex)
}
// 根据基准元素,对分成两部分的数组进行递归排序
sort(array, startIndex, pivotIndex - 1,isDouble)
sort(array, pivotIndex + 1, endIndex,isDouble)
}
// 获取双边循环的基准元素
// arr 需要排序的数组
// startIndex 获取基准元素的起点边界
// endIndex 获取基准元素的终点边界
private fun partitionWithDouble(array: IntArray, startIndex: Int, endIndex: Int): Int{
// 获取基准元素 默认获取第一个,也可获取其它任意元素
// 根据数据情况选择不同的基准元素可以提高效率
val pivot = array[startIndex]
var left = startIndex
var right = endIndex
while (left!=right){
// 控制right指针比较并左移
while (left<right && array[right] > pivot){
right--
}
// 控制left指针比较并右移
while (left<right && array[left] <= pivot){
left++
}
if(left<right){
val tmp = array[left]
array[left] = array[right]
array[right] = tmp
}
}
// pivot和指针重合点交换
array[startIndex] = array[left]
array[left] = pivot
return left
}
测试代码:
fun quickSort(){
var array = intArrayOf(4,6,5,2,8,9,7,5,1,3)
QuickSort.sort(array,0,array.size-1,false)
println(array.contentToString())
array = intArrayOf(4,8,6,7,4,2,1,5,3,9,5)
QuickSort.sort(array,0,array.size-1,true)
println(array.contentToString())
}
运行结果:
[1, 2, 3, 4, 5, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 9]
从代码来看,单边循环法获取元素是通过每轮从左到右的依次比较来获取,而双边循环法是每一轮从左到右,然后再从右到左的循环回来,缩小循环的边界。具体过程可以跟着断点仔细看一看。 上面的快速排序都是通过递归来实现的,那么能不能通过其它方式实现呢?这个答案也是肯定的,这里也通过栈来实现!
非递归实现
非递归排序说来很简单,就是把每次递归的方法自己用栈来封装,而非每次通过调用自身的递归方式来实现。概念太抽象了,我们看看代码的实现?
// 非递归方式实现排序
fun sort(array: IntArray, startIndex: Int, endIndex: Int){
val quickSortStack = Stack<Map<String,Int>>()
// 整个数列的起止下标,以哈希的形式入栈
val rootParam = HashMap<String,Int>()
rootParam["startIndex"] = startIndex
rootParam["endIndex"] = endIndex
quickSortStack.push(rootParam)
while (quickSortStack.isNotEmpty()){
val param = quickSortStack.pop()
val pivotIndex = partitionWithDouble(array,param["startIndex"]?:0,param["endIndex"]?:0)
if(param["startIndex"]?:0< pivotIndex-1){
val leftParam = HashMap<String,Int>()
leftParam["startIndex"] = param["startIndex"]?:0
leftParam["endIndex"] = pivotIndex-1
quickSortStack.push(leftParam)
}
if(pivotIndex+1 < param["endIndex"]?:0){
val rightParam = HashMap<String,Int>()
rightParam["startIndex"] = pivotIndex+1
rightParam["endIndex"] = param["endIndex"]?:0
quickSortStack.push(rightParam)
}
}
}
其实和上面的递归逻辑几乎一致,不一样的地方是对栈的封装,以及在这里的判断,避免栈的无限循环。我们接下来测试看看?
fun quickSort(){
var array = intArrayOf(4,6,5,2,8,9,7,5,1,3)
QuickSort.sort(array,0,array.size-1,false)
println(array.contentToString())
array = intArrayOf(4,8,6,7,4,2,1,5,3,9,5)
QuickSort.sort(array,0,array.size-1,true)
println(array.contentToString())
array = intArrayOf(8,4,3,9,5,7,2,6,5,1,8,4)
QuickSort.sort(array,0,array.size-1)
println(array.contentToString())
}
测试结果:
[1, 2, 3, 4, 5, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 8, 9]
3.什么是堆排序?
堆排序 指的是利用最大(小)堆的特性,每次“删除”堆顶元素,然后通过堆的自我调整,接着再“删除”堆顶元素,直至堆元素被“删除”完了,这样被“删除”元素就是一个有序数组。
代码实现:
/**
* <p>文件描述:堆排序的实现<p>
* <p>@author 烤鱼<p>
* <p>@date 2019/11/02 0027 <p>
* <p>@update 2019/11/02 0027<p>
* <p>版本号:1<p>
*
*/
object HeapSort {
fun sort(array: IntArray) {
// 把无序数组构建成堆
for (i in (array.size - 2) / 2 downTo 0) {
downAdjust(array, i, array.size, false)
}
// BinaryHeap.upAdjust(array)
// 循环删除堆顶元素,移到集合尾部,调整堆产生新的堆顶
for (i in array.size - 1 downTo 1) {
// 最后一个元素和第一个元素交换
val tmp = array[i]
array[i] = array[0]
array[0] = tmp
// 下沉调整最大堆
downAdjust(array, 0, i, false)
}
}
// “下沉”调整 (删除节点)
// isMax true 最大堆 false 最小堆
private fun downAdjust(array: IntArray, index: Int, length: Int, isMax: Boolean) {
var parentIndex = index
var temp = array[parentIndex]
var childIndex = 2 * parentIndex + 1
while (childIndex < length) {
if (isMax) {
if (childIndex + 1 < length && array[childIndex + 1] > array[childIndex]) {
childIndex++
}
if (temp >= array[childIndex]) {
break
}
} else {
if (childIndex + 1 < length && array[childIndex + 1] < array[childIndex]) {
childIndex++
}
if (temp <= array[childIndex]) {
break
}
}
array[parentIndex] = array[childIndex]
parentIndex = childIndex
childIndex = 2 * childIndex + 1
}
array[parentIndex] = temp
}
}
测试一波:
fun heapSort(){
val array = intArrayOf(2,4,1,5,3,6,7,8,9)
HeapSort.sort(array)
println(array.contentToString())
}
测试结果:
[9, 8, 7, 6, 5, 4, 3, 2, 1]
特别需要注意的是,将数组构建成最小堆是降序,构建成最大堆是升序,且构建后“删除”堆顶元素后自我调整的时候也要遵循前面的规则。
4.计数排序
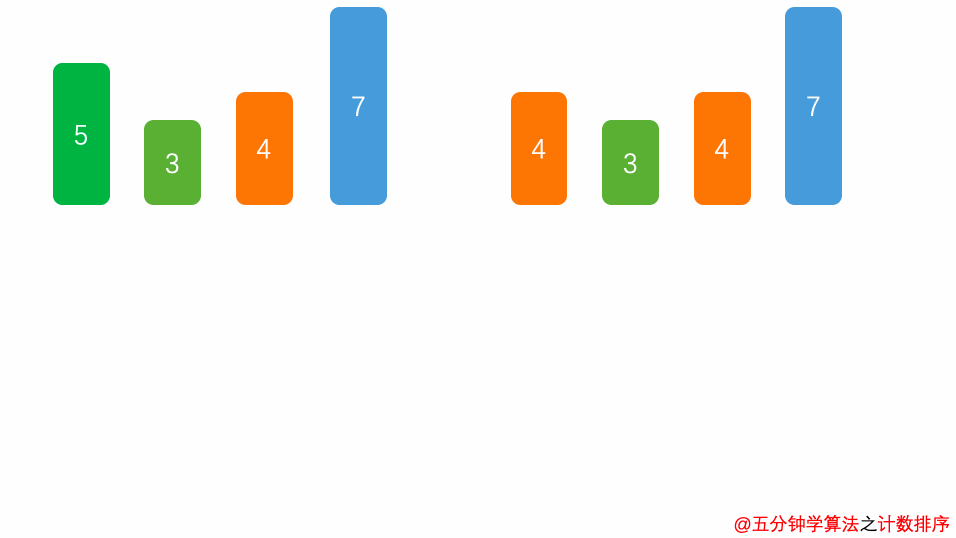
计数排序是一个非基于比较的排序算法,它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法。步骤如下:
- 计算数列的最大值
- 根据最大值确定统计数组长度
- 遍历数列,填充统计数组
- 遍历统计数组 输出结果
图片源自https://www.itcodemonkey.com/article/11750.html
代码实现:
/**
* <p>文件描述:计数排序的实现<p>
* <p>@author 烤鱼<p>
* <p>@date 2019/11/2 0002 <p>
* <p>@update 2019/11/2 0002<p>
* <p>版本号:1<p>
*
*/
object CountSort {
fun sort(array: IntArray):IntArray{
// 计算数列的最大值
var max = array[0]
for (i in 1 until array.size){
if(array[i]>max){
max = array[i]
}
}
// 根据最大值确定统计数组长度
val countArray = IntArray(max+1)
// 遍历数列,填充统计数组
for(i in array){
countArray[i]++
}
// 遍历统计数组 输出结果
var index = 0
val resultData = IntArray(array.size)
for (i in countArray.indices){
for (j in 0 until countArray[i]){
resultData[index++] = i
}
}
return resultData
}
}
测试一波:
fun countSort(){
println(CountSort.sort(intArrayOf(8,4,5,2,1,5,6,2,5,9,4,7,1,6,2,3,4,5)).contentToString())
}
测试结果:
[1, 1, 2, 2, 2, 3, 4, 4, 4, 5, 5, 5, 5, 6, 6, 7, 8, 9]
看来确实挺快的,但是好像还有优化的空间,就是统计数组的长度,比如999,990,992,994,996,997,992,998,999,993,996,我们的统计数组长度完全有必要进一步优化的,下面是代码实现:
// 计数排序 优化
fun sort2(array: IntArray):IntArray{
// 计算数列的最大值、最小值、以及差值
var max = array[0]
var min = array[0]
for (i in 1 until array.size){
if(array[i]>max){
max = array[i]
}
if(array[i]<min){
min = array[i]
}
}
val d = max-min
// 根据最大值确定统计数组长度
val countArray = IntArray(d+1)
// 遍历数列,填充统计数组
for(i in array){
countArray[i-min]++
}
for (i in 1 until countArray.size){
countArray[i]+=countArray[i-1]
}
// 遍历统计数组 输出结果
val resultData = IntArray(array.size)
for (i in array.size-1 downTo 0){
resultData[countArray[array[i]-min]-1] = array[i]
countArray[array[i]-min]--
}
return resultData
}
测试一波:
fun countSort(){
println(CountSort.sort(intArrayOf(8,4,5,2,1,5,6,2,5,9,4,7,1,6,2,3,4,5)).contentToString())
println(CountSort.sort2(intArrayOf(99,110,115,105,107,92,111,106,98,108)).contentToString())
}
测试结果:
[1, 1, 2, 2, 2, 3, 4, 4, 4, 5, 5, 5, 5, 6, 6, 7, 8, 9]
[92, 98, 99, 105, 106, 107, 108, 110, 111, 115]
注意:
- 如果最大值和最小值之间的差值过大时,不建议使用,如
2,4,7,10000000000 - 当元素不是整数,也不适合,如
10.2,11.5,12,13.5,14.3,因为非整数无法创建统计数组
5.桶排序(Bucket sort)
桶排序 是一个排序算法,工作的原理是将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。
以上内容来自百度百科
以上演示图源自https://blog.csdn.net/developer1024/article/details/79770240
如果对概念和演示图都看不懂,那也没有关系,我们还有代码。写了这么多以后,发现之前自己本来不怎么熟悉的思路,现在跟着代码一遍一遍的运行下来,基本上都知道是怎么一回事了。言归正传,我们看代码:
/**
* <p>文件描述:桶排序的实现<p>
* <p>@author 烤鱼<p>
* <p>@date 2019/11/2 0002 <p>
* <p>@update 2019/11/2 0002<p>
* <p>版本号:1<p>
*
*/
object BucketSort {
fun sort(array: DoubleArray):DoubleArray{
// 得到数列的最大值、最小值、差值
var max = array[0]
var min = array[0]
for (i in 1 until array.size){
if(array[i]>max){
max = array[i]
}
if(array[i]<min){
min = array[i]
}
}
val d = max-min
// 初始化桶
val bucketNumber = array.size
val buicketList = mutableListOf<LinkedList<Double>>()
for (i in 0 until bucketNumber){
buicketList.add(LinkedList())
}
// 遍历原始数组
for (i in array){
val num = ((i-min)*(bucketNumber-1)/d).toInt()
buicketList[num].add(i)
}
// 对每个桶内部进行排序
for (i in buicketList){
// JDK 底层采用了归并排序或者归并的优化版本
i.sort()
}
// 输出全部元素
val resultData = DoubleArray(array.size)
var index = 0
for (list in buicketList){
for (i in list){
resultData[index] = i
index++
}
}
return resultData
}
}
测试一波:
// 桶排序
fun bucketSort(){
println(BucketSort.sort(doubleArrayOf(3.2,4.2,6.5,5.1,15.2,11.5,12.6,4.8,6.4,9.9,1.5,10.2)).contentToString())
}
测试结果:
[1.5, 3.2, 4.2, 4.8, 5.1, 6.4, 6.5, 9.9, 10.2, 11.5, 12.6, 15.2]
上面的思路其实也是分治法的思路,只是有自己的发挥。
其实不管什么算法,都有自身的局限性,不同的数据有不同的算法更适合它,并没有一招鲜吃遍天的招式。我们选择具体的算法时,应该充分考虑到平均时间复杂度、最坏时间复杂度,空间复杂度,是否稳定排序(即顺序在能不调换的时候则不调换),然后有针对性的选择最合适的算法。
后记
1----本文由苏灿烤鱼整理编写,转载请注明
2----如果有什么想要交流的,欢迎留言。也可以加微信:Vicent_0310
3----个人能力有限,如有不正之处欢迎大家批评指证,必定虚心改正
