

随着互联网的普及,越来越多的用户已经习惯在网络上发表评论。这些评论表达了用户的情感倾向,无论对于公司还是个人,这样的信息都具备很高的价值。
然而,面对海量的用户评论数据时,想要通过纯人工的方式进行情感分析,几乎是不可能完成的任务。所以,我们需要使用NLP的技术来处理这个任务。
情感分析:对包含主观信息的文本进行情感色彩(褒贬)判断,以确定该文本的观点、喜好、情感倾向。
情感分析主要有3个要素,如下图所示:
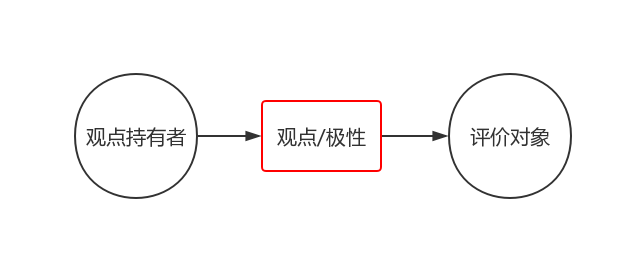
- 观点持有者:指发表评论的用户,如:大众点评的用户
- 观点/极性:正向和负向的评论,如:好吃、难看
- 评价对象:一般包括实体和属性,如:KFC的就餐环境
其中,很多情感分析也会把“时间”这个维度考虑进去,按照不同的时间段分别进行分析,这样可以更客观地评估用户的情感倾向,比如:使用Twitter的情感分析预测股市行情。
目前情感分析主要有两种方法:
- 基于情感词典,是指根据已构建的情感词典,抽取待分析文本的情感词,然后计算其情感倾向。
- 基于机器学习的情感分析,是指选取情感词作为特征词,将待分析文本向量化,利用分类器(LR、SVM等)进行分类。
本文我们重点讲讲基于情感词典的情感分析,因为其方法相对更简单一些,更容易上手,不需要掌握机器学习的相关知识,也不需要大量带标注的训练数据,而其效果取决于情感词典的完善性。
情感词典
情感词典一般主要包括:情感词和程度词。用户用情感词表达自己的态度,比如:喜欢、讨厌等;而用户用程度词表达强弱程度,比如:非常,一般等。
网上会有一些开源的中文情感词典可以直接使用,但质量一般参差不齐。如果想要高质量的、有针对性的中文情感词典,那么就需要自己动手进行生成,自然就离不开中文分词技术,这里安利大家一本掘金小册《深入理解NLP的中文分词:从原理到实践》,让你可以从零开始掌握中文分词技术。
假设我们已经有了一份中文情感词典,大概如下所示:
| 情感词 | 数值 |
|---|---|
| 喜欢 | 1 |
| 爱 | 2 |
| 缺点 | -1 |
| 失望 | -2 |
其中,数值为正的情感词表达的是正向的,反之表达的是负向的。不同的情感词所传递的程度也是不同的,比如:喜欢就是淡淡的爱,爱就是深深的喜欢。
而程度词典则如下所示:
| 程度词 | 数值 |
|---|---|
| 有一点 | 1 |
| 非常 | 2 |
| 极其 | 3 |
用户会用形容词来进一步传递自己的情感倾向,我们还可以引入一些符号来扩充程度词,比如:感叹号(!)。
现在,我们可以开始处理待分析的文本了,收集了一份关于旅店的用户评价数据,罗列几条如下:
- 前台楼层服务员不错,房间安静、整洁,唯一卫生间地漏设计不好,导致少量积水。
- 位置不错市中心,房间一如既往干净。
- 半夜没暖气住 ! ! ! ! ! ! ! ! ! !
其中,像“不”和“没”都是一些反转词,我们把这样的词设置成-1,可以改变原有的情感词取值符号。
我们先对这些句子进行分词,会得到如下的结果:
1. 前台 楼层 服务员 很 不错 房间 安静 整洁 唯一 卫生间 地漏 设计 不好 导致 少量 积水
2. 位置 不错 市中心 房间 一如既往 干净
3. 半夜 没 暖气 住 ! ! ! ! ! ! ! ! ! !
根据情感词典匹配分词结果里面的词,而数值计算可以分成正向和负向,我们拿其中一个为例:
1. 前台 楼层 服务员 不错 房间 安静 整洁 唯一 卫生间 地漏 设计 不好 导致 少量 积水
正向匹配结果:
很: 1 # 程度词
不错: 1
安静: 1
整洁: 1
正向数值结果: 1 + 1 + 1 + 1 = 4
负向匹配结果:
不好: -1
积水: -1
负向数值结果:|-1| + |-1| = 2
最后情感倾向结果:(4, 2),综合数值为 4 - 2 = 2
以上就是基于情感词典的情感分析的方法,不难发现中文分词对最后的结果影响很大。有了这样的情感分析方法,我们就可以自动化,批量地对用户评论进行分析,快速得到用户真实的反馈信息,并据此调整产品逻辑或个人购买意愿。
关于基于机器学习的情感分析,简单介绍一下:
- 首先,需要人工标注好的情感分类数据,正向标注为1,负向标注为0,分成训练数据和测试数据。
- 然后,选取文本中的“特征词”,比如商品的描述词(简约,时尚)等等,将词转化成向量,形成词的矩阵。
- 最后,使用分类器模型(LR、SVM、NB)对训练数据进行学习,得到模型后,用测试数据进行预测,选取效果最优的模型。
本文浅谈了如何做情感分析,基本满足了大家日常对情感分析的需求,如果想了解一些进阶的方法,大家可以关注我的专栏,后面会再更新相关内容。大家如果对中文分词感兴趣,还请多多支持我的掘金小册《深入理解NLP的中文分词:从原理到实践》,多谢多谢!
