最近几年,业界不断涌现出很多各种各样的NoSQL产品,那么如何才能正确地使用好这些产品,最大化地发挥其长处,是我们需要深入研究和思考的问题,在实际应用中做到扬长避短.
1. redis中常用的数据类型
1.1 String类型
Strings 数据结构是简单的key-value类型,key是字符串类型,value可以是String(简单的字符串、复杂的字符串(xml、json),也可以是数字(整数、浮点数)、二进制(图片、音频、视频)),但最大不能超过512M.
常用命令: set,get,decr,incr,mget 等。
 常用功能
常用功能:
String是最常用的一种数据类型,普通的key/ value 存储都可以归为此类.还可以享受Redis的定时持久化。除了提供get、set、incr、decr 等操作外,Redis还提供了下面一些操作:
- 获取字符串长度
- 往字符串append内容
- 设置和获取字符串的某一段内容
- 设置及获取字符串的某一位(bit)
- 批量设置一系列字符串的内容
实现方式:
String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr,decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
常用场景:
缓存功能:字符串最经典的使用场景,redis最为缓存层,Mysql作为储存层,绝大部分请求数据都是
redis中获取,由于redis具有支撑高并发特性,所以缓存通常能起到加速读写和降低 后端压力的作用。
计数器:许多运用都会使用redis作为计数的基础工具,他可以实现快速计数、查询缓存的功能,
同时数据可以一步落地到其他的数据源。
如:视频播放数系统就是使用redis作为视频播放数计数的基础组件。
共享session:出于负载均衡的考虑,分布式服务会将用户信息的访问均衡到不同服务器上,
用户刷新一次访问可能会需要重新登录,为避免这个问题可以用redis将用户session集中管理,
在这种模式下只要保证redis的高可用和扩展性的,每次获取用户更新或查询登录信息
都直接从redis中集中获取。
限速:处于安全考虑,每次进行登录时让用户输入手机验证码,为了短信接口不被频繁访问,
会限制用户每分钟获取验证码的频率。
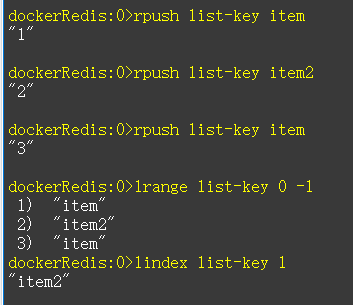
1.2 List类型
常用命令:
lpush,rpush,lpop,rpop,lrange等。
 实现方式
实现方式:
列表类型是用来储存多个有序的字符串,列表中的每个字符串成为元素(element),一个列表最多可以储存2的32次方-1个元素,list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
在redis中,可以队列表两端插入(pubsh)和弹出(pop),还可以获取指定范围的元素
列表、获取指定索引下表的元素等,列表是一种比较灵活的数据结构,它可以充当栈和队列的角色,在实际开发中有很多应用场景。
优点:
1.列表的元素是有序的,这就意味着可以通过索引下标获取某个或某个范围内的元素列表。
2.列表内的元素是可以重复的。
应用场景:
Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现。
Lists 就是链表,相信略有数据结构知识的人都应该能理解其结构。使用Lists结构,我们可以轻松地实现最新消息排行等功能。Lists的另一个应用就是消息队列,可以利用Lists的PUSH操作,将任务存在Lists中,然后工作线程再用POP操作将任务取出进行执行。Redis还提供了操作Lists中某一段的api,你可以直接查询,删除Lists中某一段的元素。
常用技巧:
lpush+lpop=Stack(栈)
lpush+rpop=Queue(队列)
lpush+ltrim=Capped Collection(有限集合)
lpush+brpop=Message Queue(消息队列)
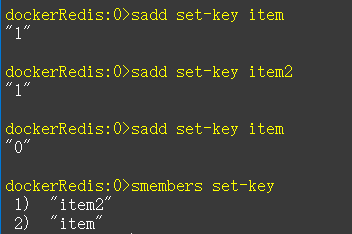
1.3 Set类型
集合类型也是用来保存多个字符串的元素,但和列表不同的是集合中不允许有重复的元素,并且集合中的元素是无序的,不能通过索引下标获取元素,redis除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集,并合理的使用好集合类型,能在实际开发中解决很多实际问题。
常用命令:
sadd,spop,smembers,sunion 等。
 常用场景:
常用场景:
标签(tag):集合类型比较典型的使用场景,如一个用户对娱乐、体育比较感兴趣,另一个可能对新闻感兴趣,这些兴趣就是标签,有了这些数据就可以得到同一标签的人,以及用户的共同爱好的标签, 这些数据对于用户体验以及曾强用户粘度比较重要。(用户和标签的关系维护应该放在一个事物内执行,防止部分命令失败造成数据不一致)
常用技巧:
sadd=tagging(标签)
spop/srandmember=random item(生成随机数,比如抽奖)
sadd+sinter=social Graph(社交需求)
1.4 Hash类型
在redis中哈希类型是指键本身又是一种键值对结构,如 value={{field1,value1},......{fieldN,valueN}}
常用命令:
hget,hset,hgetall 等。
 使用场景:
使用场景:
哈希结构相对于字符串序列化缓存信息更加直观,并且在更新操作上更加便捷。
所以常常用于
用户信息等管理,但是哈希类型和关系型数据库有所不同,哈希类型是稀疏的,而关系型数据库是完全结构化的,关系型数据库可以做复杂的关系查询,而redis去模拟关系型复杂查询开发困难,维护成本高。
1.5 有序集合类型
有序集合和集合有着必然的联系,他保留了集合不能有重复成员的特性,但不同得是,有序集合中的元素是可以排序的,但是它和列表的使用索引下标作为排序依据不同的是,它给每个元素设置一个分数,作为排序的依据。
常用命令:
zadd,zrange,zrem,zcard等
 实现方式:
实现方式:
Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
使用场景:
Redis有序序列的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
另外还可以用Sorted Sets来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。


