


- 冬来冬往,越来越喜欢软绵绵的被窝了。a
- 厌倦了夏天的酷热,秋天的浮躁,来一首冬天的安静。
一、服务器崩溃的思考
老板说,他要做个现场营销活动,线上线下都要参与推广,这个活动参与人数可能很大哦···
果然,由于不是我写的代码,所以那天服务器就崩了,崩的时候很安静,写代码的那个人一个人走的,走的时候很安详。
💡: 当请求量到达百万级时候,为啥会崩溃呢?

微服务中是通过接口去向服务提供者发起http请求或者rpc(tcp)请求去获取数据,事实上大量请求中,服务端能处理的请求数量有限,服务中充斥着大量的线程,以及数据库等的连接也会被占用完,导致请求响应速度也越来越慢。
🌱:
- 响应速度和我们的数据层有关系吗?
- 能不能去添加服务端服务器呢?
- 如果能减少客户端向服务端的请求就好了?
- 限流吗?当前场景能限流吗?
- 每个线程去查询数据,每次都只查询某一个结果,是不是太浪费了?
- 我们能不能想办法,提升我们系统的调用性能?
二、有人想看请求合并,今天她来了
上面的一些思路可以用加缓存,加MQ的方式去解决。但是缓存有限,MQ是个队列,有限流的效果。那么,如何才能提高系统的调用能力,我们学习一下,请求合并,结果分发。
- 正常的请求都是一个请求一个线程,到后台触发相关的业务需求,去调用数据获取业务。
- 当请求合并后,我们要将多个多个请求合并后统一去批量去调用。
大概的设计思路便是如下图所示:
常规请求

常规请求 请求合并
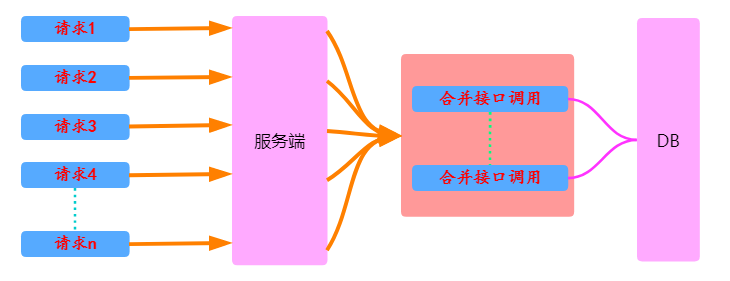
说下我们的思路
- 解决请求调用多,比如调用商品数据,经过的服务多,调用链很长,所以查询数据库的次数也就非常多,数据库连接池很快就被用光,导致很多请求被阻塞,也导致应用整体线程数非常高。虽然通过增加数据库连接池大小可以缓解问题,并且可以通过压力测试,但这治标不治本。
- 查询商品信息的时候,如果同一商品同一时刻有100个请求,那么其中的99次查询是多余的,可以把100个请求合并成一个真实的后台接口调用,只要控制好线程安全即可。我的想法是使用并发计数器来实现再配合本地缓存,计数器可直接用JDK提供的`AtomicInteger`,线程安全又提供原子操作。
- 以获取商品信息为例,每个商品id对应一个计数器,计数器初始值默认是0,当一个请求过来后通过`incrementAndGet()`使计数器自增1并返回自增后的值。当该值等于1,表明该线程在这个时间点上是第一个到达的线程,然后就去调用真实的业务逻辑,在查询到结果后放入到本地缓存中。当该值大于1的时候,表明之前已有线程正在调用业务逻辑,则进入等待状态,并循环的查询本地缓存中是否已有数据可用。获取到结果后都调用`decrementAndGet()`使计数器减1,计数器被减到0的时候就回到了初始状态,并且当减到0(代表最后一个线程)时清除缓存。
- 那还有在1000次请求中,请求的数据id不同,但是使用的服务接口相同,都是查询商品库的商品`id`从`1~1000`的数据,都是从表里面查询,`queryDataById(dataId)`,那我也可以合并这些请求,改为批量查询,然后将数据分发返回。思路就是设计每个请求携带一个请求`唯一的traceId`,有点像链路跟踪的感觉,简单点可以使用查询的id进行最为跟踪id,将请求放入一个队中,使用定时任务,比如每隔10ms去扫描队列,将这些业务合并请求统一去请求数据库层。
- 此方案有个数据延迟的地方,就是每次循环时的等待状态的时间。因为一次包含多次查库的业务调用,耗时基本都在几十毫秒,甚至是上百毫秒,可以把该等待睡眠设置小一点,比如10毫秒。这样即不会浪费CPU时间,实时性也比较高,但然也可以通过主动唤醒等待线程的方式,这个操作起来就比较复杂些。在这其中还可以添加一些异常处理、超时控制、最大重试次数,最大并发数(超时最大并发数就快速失败)等。
三、开始演练
- 模拟一个远程调用接口
1import org.springframework.stereotype.Service;
2
3import java.util.*;
4
5/**
6 * 模拟远程调用ShopData接口
7 * @author Lijing
8 */
9@Service
10public class QueryServiceRemoteCall {
11
12 /**
13 * 调用远程的商品信息查询接口
14 *
15 * @param code 商品编码
16 * @return 返回商品信息,map格式
17 */
18 public HashMap<String, Object> queryShopDataInfoByCode(String code) {
19 try {
20 Thread.sleep(50L);
21 } catch (InterruptedException e) {
22 e.printStackTrace();
23 }
24 HashMap<String, Object> hashMap = new HashMap<>();
25 hashMap.put("shopDataId", new Random().nextInt(999999999));
26 hashMap.put("code", code);
27 hashMap.put("name", "小玩具");
28 hashMap.put("isOk", "true");
29 hashMap.put("price","3000");
30 return hashMap;
31 }
32
33 /**
34 * 批量查询 - 调用远程的商品信息查询接口
35 *
36 * @param codes 多个商品编码
37 * @return 返回多个商品信息
38 */
39 public List<Map<String, Object>> queryShopDataInfoByCodeBatch(List<String> codes) {
40 List<Map<String, Object>> result = new ArrayList<>();
41 for (String code : codes) {
42 HashMap<String, Object> hashMap = new HashMap<>();
43 hashMap.put("shopDataId", new Random().nextInt(999999999));
44 hashMap.put("code", code);
45 hashMap.put("name", "棉花糖");
46 hashMap.put("isOk", "true");
47 hashMap.put("price","6000");
48 result.add(hashMap);
49 }
50 return result;
51 }
52}
- 使用CountDownLatch模拟并发请求的公共测试类
1@RunWith(SpringRunner.class)
2@SpringBootTest(classes = MyBotApplication.class)
3public class MergerApplicationTests {
4
5 long timed = 0L;
6
7 @Before
8 public void start() {
9 System.out.println("开始测试");
10 timed = System.currentTimeMillis();
11 }
12
13 @After
14 public void end() {
15 System.out.println("结束测试,执行时长:" + (System.currentTimeMillis() - timed));
16 }
17
18 // 模拟的请求数量
19 private static final int THREAD_NUM = 1000;
20
21 // 倒计数器 juc包中常用工具类
22 private CountDownLatch countDownLatch = new CountDownLatch(THREAD_NUM);
23
24 @Autowired
25 private ShopDataService shopDataService;
26
27 @Test
28 public void simulateCall() throws IOException {
29 // 创建 并不是马上发起请求
30 for (int i = 0; i < THREAD_NUM; i++) {
31 final String code = "code-" + (i + 1);
32 // 多线程模拟用户查询请求
33 Thread thread = new Thread(() -> {
34 try {
35 // 代码在这里等待,等待countDownLatch为0,代表所有线程都start,再运行后续的代码
36 countDownLatch.await();
37 // 模拟 http请求,实际上就是多线程调用这个方法
38 Map<String, Object> result = shopDataService.queryData(code);
39 System.out.println(Thread.currentThread().getName() + " 查询结束,结果是:" + result);
40 } catch (Exception e) {
41 System.out.println(Thread.currentThread().getName() + " 线程执行出现异常:" + e.getMessage());
42 }
43 });
44 thread.setName("price-thread-" + code);
45 thread.start();
46 // 启动后,倒计时器倒计数 减一,代表又有一个线程就绪了
47 countDownLatch.countDown();
48 }
49
50 System.in.read();
51 }
52
53}
- 先来个普通调用演示
1/**
2 * 商品数据服务类
3 * @author lijing
4 */
5@Service
6public class ShopDataService {
7 @Autowired
8 QueryServiceRemoteCall queryServiceRemoteCall;
9
10 // 1000 用户请求,1000个线程
11 public Map<String, Object> queryData(String shopDataId) throws ExecutionException, InterruptedException {
12 return queryServiceRemoteCall.queryShopDataInfoByCode(shopDataId);
13 }
14}
- 查询结果展示
1开始测试
2price-thread-code-3 查询结束,结果是:{code=code-3, shopDataId=165800794, price=3000, isOk=true, name=小玩具}
3price-thread-code-994 查询结束,结果是:{code=code-994, shopDataId=735455508, price=3000, isOk=true, name=小玩具}
4price-thread-code-36 查询结束,结果是:{code=code-36, shopDataId=781610507, price=3000, isOk=true, name=小玩具}
5price-thread-code-993 查询结束,结果是:{code=code-993, shopDataId=231087525, price=3000, isOk=true, name=小玩具}
6
7....... 省略代码中。。。。
8
9price-thread-code-25 查询结束,结果是:{code=code-25, shopDataId=149193873, price=3000, isOk=true, name=小玩具}
10price-thread-code-2 查询结束,结果是:{code=code-2, shopDataId=324877405, price=3000, isOk=true, name=小玩具}
11
12.......共计1000次的查询结果
13
14结束测试,执行时长:150
- 那么我们发现我们可以用
code作为一个追踪traceId,然后使用ScheduledExecutorService,CompletableFuture,LinkedBlockingQueue等一些多线程技术,就可以实现这个请求合并,请求分发的简单实现demo.
1import javax.annotation.PostConstruct;
2import java.util.ArrayList;
3import java.util.HashMap;
4import java.util.List;
5import java.util.Map;
6import java.util.concurrent.*;
7
8/**
9 * 商品数据服务类
10 *
11 * @author lijing
12 */
13@Service
14public class ShopDataService {
15
16 class Request {
17 String shopDataId;
18 CompletableFuture<Map<String, Object>> completableFuture;
19 }
20
21 // 集合,积攒请求,每N毫秒处理
22 LinkedBlockingQueue<Request> queue = new LinkedBlockingQueue<>();
23
24 @PostConstruct
25 public void init() {
26 ScheduledExecutorService scheduledExecutorPool = Executors.newScheduledThreadPool(5);
27 scheduledExecutorPool.scheduleAtFixedRate(() -> {
28 // TODO 取出所有queue的请求,生成一次批量查询
29 int size = queue.size();
30 if (size == 0) {
31 return;
32 }
33 System.out.println("此次合并了多少请求:" + size);
34 // 1、 取出
35 ArrayList<Request> requests = new ArrayList<>();
36 ArrayList<String> shopDataIds = new ArrayList<>();
37 for (int i = 0; i < size; i++) {
38 Request request = queue.poll();
39 requests.add(request);
40 shopDataIds.add(request.shopDataId);
41 }
42 // 2、 组装一个批量查询 (不会比单次查询慢很多)
43 List<Map<String, Object>> mapList = queryServiceRemoteCall.queryShopDataInfoByCodeBatch(shopDataIds);
44
45 // 3、 分发响应结果,给每一个request用户请求 (多线程 之间的通信)
46 HashMap<String, Map<String, Object>> resultMap = new HashMap<>(); // 1000---- 007
47 for (Map<String, Object> map : mapList) {
48 String code = map.get("code").toString();
49 resultMap.put(code, map);
50 }
51
52 // 1000个请求
53 for (Request req : requests) {
54 Map<String, Object> result = resultMap.get(req.shopDataId);
55 // 怎么通知对应的1000多个线程,取结果呢?
56 req.completableFuture.complete(result);
57 }
58 }, 0, 10, TimeUnit.MILLISECONDS);
59 }
60
61
62 @Autowired
63 QueryServiceRemoteCall queryServiceRemoteCall;
64
65 /**
66 * 1000 用户请求,1000个线程
67 *
68 * @param shopDataId
69 * @return
70 * @throws ExecutionException
71 * @throws InterruptedException
72 */
73 public Map<String, Object> queryData(String shopDataId) throws ExecutionException, InterruptedException {
74 Request request = new Request();
75 request.shopDataId = shopDataId;
76 CompletableFuture<Map<String, Object>> future = new CompletableFuture<>();
77 request.completableFuture = future;
78 queue.add(request);
79 // 等待其他线程通知拿结果
80 return future.get();
81 }
82}
- 测试结果
1开始测试
2结束测试,执行时长:164
3
4此次合并了多少请求:63
5此次合并了多少请求:227
6此次合并了多少请求:32
7此次合并了多少请求:298
8此次合并了多少请求:68
9此次合并了多少请求:261
10此次合并了多少请求:51
11
12price-thread-code-747 查询结束,结果是:{code=code-747, shopDataId=113980125, price=6000, isOk=true, name=棉花糖}
13price-thread-code-821 查询结束,结果是:{code=code-821, shopDataId=568038265, price=6000, isOk=true, name=棉花糖}
14price-thread-code-745 查询结束,结果是:{code=code-745, shopDataId=998247608, price=6000, isOk=true, name=棉花糖}
15
16....... 省略代码中。。。。
17
18price-thread-code-809 查询结束,结果是:{code=code-809, shopDataId=479029433, price=6000, isOk=true, name=棉花糖}
19price-thread-code-806 查询结束,结果是:{code=code-806, shopDataId=929748878, price=6000, isOk=true, name=棉花糖}
可以看到我们将1000次请求进行了合并,数据也是正常的模拟到了。
四、总结
弊端:
- 启用请求的成本是执行实际逻辑之前增加的延迟。
- 如果平均仅需要5毫秒的执行时间,放在一个10毫秒的做一次批处理的合并场景下,则在最坏的情况下,执行时间可能会变为15毫秒。(一定不适合低延迟的RPC场景、一定不适合低并发场景)
场景:
- 如果很少有超过1或2个请求会并发在一起,则没有必要用。
- 一个特定的查询同时被大量使用,并且可以将几+个甚至数百个批处理在一起,那么如果能接受处理时间变长一点点,用来减少网络连接欲,这是值得的。(典型如:数据库、Http接口)
扩展:
- 我们不重复造轮子,在SpringCloud的组件
spring-cloud-starter-netflix-hystrix中已经有封装好的轮子Hystrix的HystrixCollapser来实现请求的合并,以减少通信消耗和线程数的占用。 - 当然他的组件比较复杂,也更全面,支持异步,同步,超时,异常等的处理机制。
- 但是,从底层思路来说,无非是线程之间的通信,线程的切换,队列等一些并发编程相关的技术,只要我们高度封装和抽象,那也可以手撸一个合并请求的框架处理。
那今日份的讲解就到此结束,具体的代码请移步我的gitHub的mybot项目master分支查阅,fork体验一把,或者评论区留言探讨,写的不好,请多多指教~~

