

1.多分类逻辑回归问题
数据介绍:ex3data1中有5000个训练实例。其中每个训练实例是一个20像素乘20像素灰度图像的数字。每个像素由一个浮点数表示,表示该位置的灰度强度。这个20x20的像素网格被“展开”成一个400维的向量。这些训练示例中的每一个都变成了数据矩阵X中的单行。这就得到了一个5000×400矩阵X,其中每一行都是一个手写数字图像的训练示例。
1.1 展示原始数据
数据集是在MATLAB的本机格式,所以要加载它在Python,我们需要使用一个SciPy库。
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
from scipy.io import loadmat
# 加载数据
data = loadmat('ex3data1.mat')
X, y = data['X'], data['y']
- 画单张图片
画出图片的函数:
# 数据展示
def plot_fig():
"""
原始数据可视化
"""
# 一个随机数
row = np.random.randint(0, 4999)
# 取第row行,所有列
fig_data = X[row:row + 1,:]
# 对于该数据集来说需要转置一下才是正常的图形
fig_data = fig_data.reshape((20,20)).T
# 绘图
fig, ax = plt.subplots(figsize=(1,1))
# cmap=matplotlib.cm.binary:灰度颜色表
ax.matshow(fig_data, cmap=matplotlib.cm.binary)
# 去掉刻度线
plt.xticks([])
plt.yticks([])
# 取真实y值
y_true = y[row:row + 1,:][0][0]
# 该数据集中0是用10来表示的
if y_true == 10:
y_true -= 10
print("这个数应该是:{}".format(y_true) )
plt.show()
运行结果:

- 画100张图片
def plot_100figs():
"""
画100幅图
"""
# 随机100个索引,不重复
sample_list = np.random.choice(np.arange(X.shape[0]), 100, replace=False)
# 从数据中取出这100个值
sample_data = X[sample_list, :]
# 画图, sharex,sharey:子图共享x轴,y轴, ax_array:一个10*10的矩阵
fig, ax_array = plt.subplots(nrows=10, ncols=10, sharex=True, sharey=True, figsize=(8, 8))
# 画子图
for r in range(10):
for c in range(10):
ax_array[r, c].matshow(sample_data[10 * r + c, :].reshape((20, 20)).T,
cmap=matplotlib.cm.binary)
# 去掉刻度线
plt.xticks([])
plt.yticks([])
plt.show()
np.random.choice(a,b,c):从第一个参数的范围内抽取b个值,且不允许出现重复值。
运行结果:

1.2 定义sigmoid函数、损失函数和梯度下降函数
这里所用的三个函数与二分类正则化逻辑回归相同,请见我的上一篇文章机器学习练习二:用Python实现逻辑回归。
1.3 模型训练
现在我们已经定义了代价函数和梯度函数,是构建分类器的时候了。 对于这个任务,我们有10个可能的类,并且由于逻辑回归只能一次在2个类之间进行分类,我们需要多类分类的策略。 在本练习中,我们的任务是实现一对一全分类方法,其中具有k个不同类的标签就有k个分类器,每个分类器在“类别 i”和“不是 i”之间决定。 我们将把分类器训练包含在一个函数中,该函数计算10个分类器中的每个分类器的最终权重,并将权重返回为k *(n + 1)数组,其中n是样本特征值数量。
# 使用 scipy.optimize.minimize 去寻找参数
import scipy.optimize as opt
def one_vs_all(X, y, k, lambd):
"""
模型训练
"""
rows = X.shape[0]
params = X.shape[1]
# theta是一个(k,n+1)的矩阵,k是分类数,n是样本的特征数量
all_theta = np.zeros((k, params + 1))
# 插入全1列x0
X = np.insert(X, 0, values=np.ones(rows), axis=1)
# 训练
for i in range(1, k + 1):
# 其中的一组theta
theta = np.zeros(params + 1)
# 生成单个类别的二分类矩阵
y_i = np.array([1 if label == i else 0 for label in y])
y_i = np.reshape(y_i, (rows, 1))
# 得到使得所有样本为第i类损失最小的theta值
fmin = opt.minimize(fun=cost, x0=theta, args=(X, y_i, lambd), method='TNC', jac=gradient)
all_theta[i-1,:] = fmin.x
return all_theta
这里的for i in range(1, k + 1):之所以加1是为了与目标值1,2,3...10相对应,而每一个循环都是为了计算使得所有样本为第i类的损失最小的theta值,最终得到10分类的theta值。
1.4 计算准确率
我们现在准备好最后一步,使用训练完毕的分类器预测每个图像的标签。 对于这一步,我们将计算每个类的类概率,对于每个训练样本(使用当然的向量化代码),并将输出类标签为具有最高概率的类。
简言之,需要将每个样本中概率最大的值找出来,其索引就是所预测的类。
# 获取训练集预测结果
def predict(all_theta, X):
# y_predict_re = []
# 插入全1列x0
X = np.insert(X, 0, values=np.ones(X.shape[0]), axis=1)
all_theta = np.mat(all_theta)
# y_predict --> (5000,10)
y_predict = np.array(sigmoid(X @ all_theta.T))
"""
for i in range(y_predict.shape[0]):
for j in range(y_predict.shape[1]):
if y_predict[i][j] == max(y_predict[i]):
y_predict_re.append(j + 1)
"""
# 按行取最大值索引
y_predict_re = np.argmax(y_predict,axis=1) + 1
return y_predict_re
np.argmax():按行取最大值索引,矩阵形状变化(5000,10) --> (1,5000),加1是为了与目标值类别(1,2,3...10)相对应。
判断准确度:
# 判断准确度
y_pre = np.mat(predict(all_theta, X)) # 预测值矩阵
y_true = np.mat(data['y']).ravel() # 真实值矩阵
# 矩阵进行比较返回各元素比对布尔值矩阵,列表进行比较返回整个列表的比对布尔值
accuracy = np.mean(y_pre == y_true)
print('accuracy = {}%'.format(accuracy * 100))
结果:
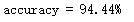
2.前馈算法
2.1 模型图示
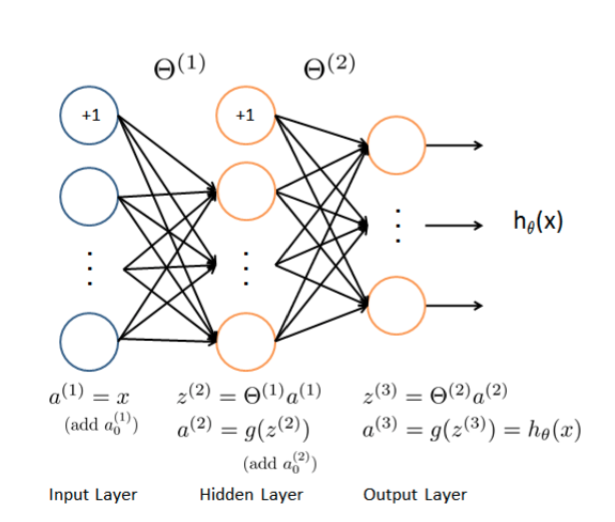

2.2 前馈预测(feed forward prediction)
# 第一层 --> 第二层
a1 = X
a1 = np.insert(a1, 0, values=np.ones(a1.shape[0]), axis=1) # 加入+1单元
z2 = X @ theta1.T
a2 = sigmoid(z2)
a2 = np.insert(a2, 0, values=np.ones(a2.shape[0]), axis=1) # 加入+1单元
此时a2.shape为(5000,26)。
# 第二层 --> 第三层
z3 = a2 @ theta2.T
a3 = sigmoid(z3)
a3.shape
此时a3.shape为(5000,10),已经算出每个样本属于各个类别的概率。
2.3 计算准确度
# 计算准确度
y_predict = np.mat(np.argmax(a3,axis=1) + 1) # 预测值矩阵
y_true = np.mat(y).ravel() # 真实值矩阵
# 矩阵进行比较返回各元素比对布尔值矩阵,列表进行比较返回整个列表的比对布尔值
accuracy = np.mean(y_predict == y_true)
print('accuracy = {}%'.format(accuracy * 100))
结果:
accuracy = 97.52%
结论: 可将前馈预测过程看做多层多分类逻辑回归问题相叠加。
