

前言
如果是第一次看到这篇的,建议先去补一下以往的5篇基础,会对你理解起来有很大帮助哦
从上一年开始鸽了好久的源码篇,终于也是给整了一下。其实一方面也是,怕自己整理不好,看的云里雾里,那也没什么意思,所以还是花了些时间准备,也是希望能够和大家一起进步吧。注意,本文篇幅非常长,建议结合PC端的右侧导航观看,效果更佳。好的!话不多说,开始吧!
二、Producer的初始化核心流程
把源码导进来,这里需要有一段时间去下载依赖,导完了就可以看到整个源码的结构是这样的
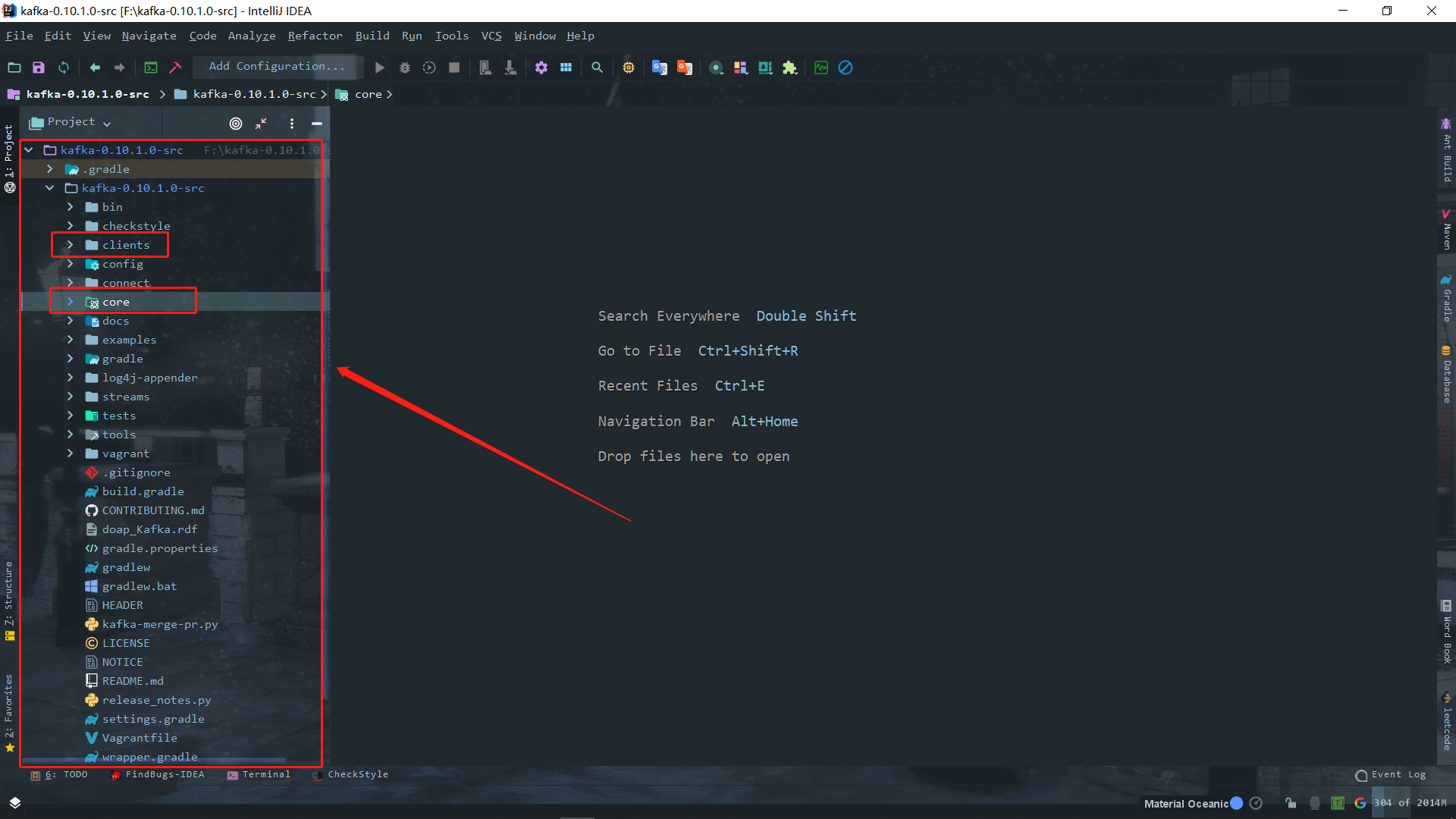
如果要一个一个类地去说明,那肯定会非常乱套的,所以要借助场景驱动。巧了,这个场景甚至还不需要我来写。看见源码里面有个example包了吗?大部分的大数据框架都是开源的,为了推广,首先官方文档要写的详细,而且还得自己提供一些不错的示例包才方便。
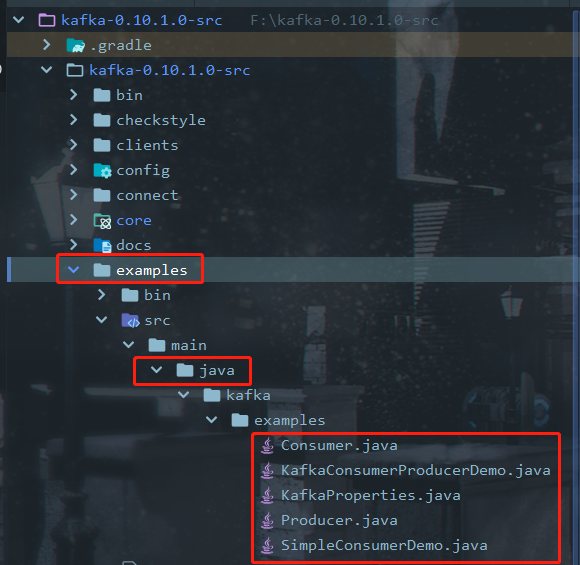
2.1 源码中自带的Producer.java例子
此时点开Producer.java,是否发现在它的构造器中,这段代码我们有点似曾相识,甚至可以说非常熟悉
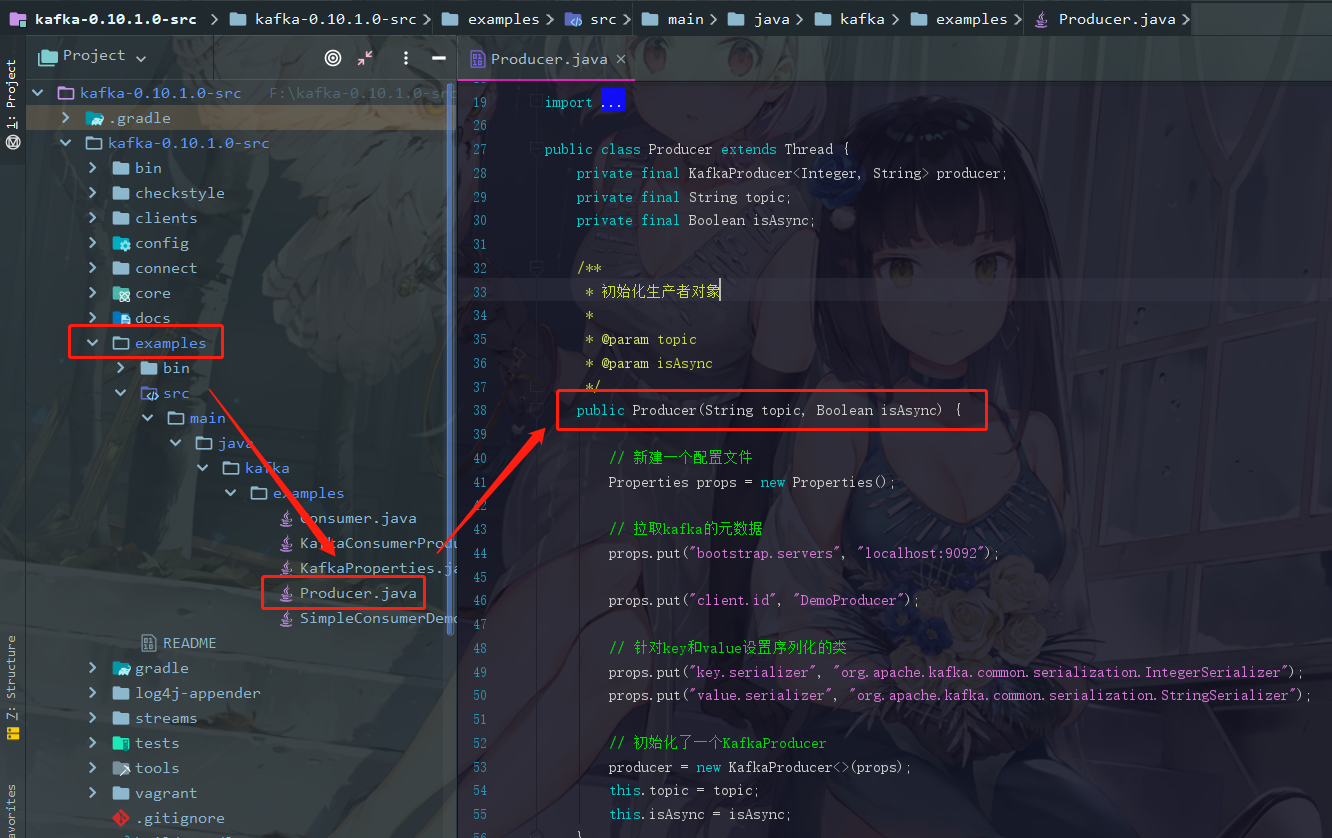
/**
* 初始化生产者对象
*
* @param topic
* @param isAsync
*/
public Producer(String topic, Boolean isAsync) {
// 新建一个配置文件
Properties props = new Properties();
// 拉取kafka的元数据
props.put("bootstrap.servers", "localhost:9092");
// 这个参数先无视(client.id是管理权限用的)
props.put("client.id", "DemoProducer");
// 针对key和value设置序列化类
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 使用上方的参数初始化了一个KafkaProducer
producer = new KafkaProducer<>(props);
this.topic = topic;
this.isAsync = isAsync;
}
甚至说你会觉得当时 插曲:Kafka的生产者原理及重要参数说明 我们来模拟生产者的时候做的配置更多,那是因为当时多了调优部分的参数。这个只是最基础的。
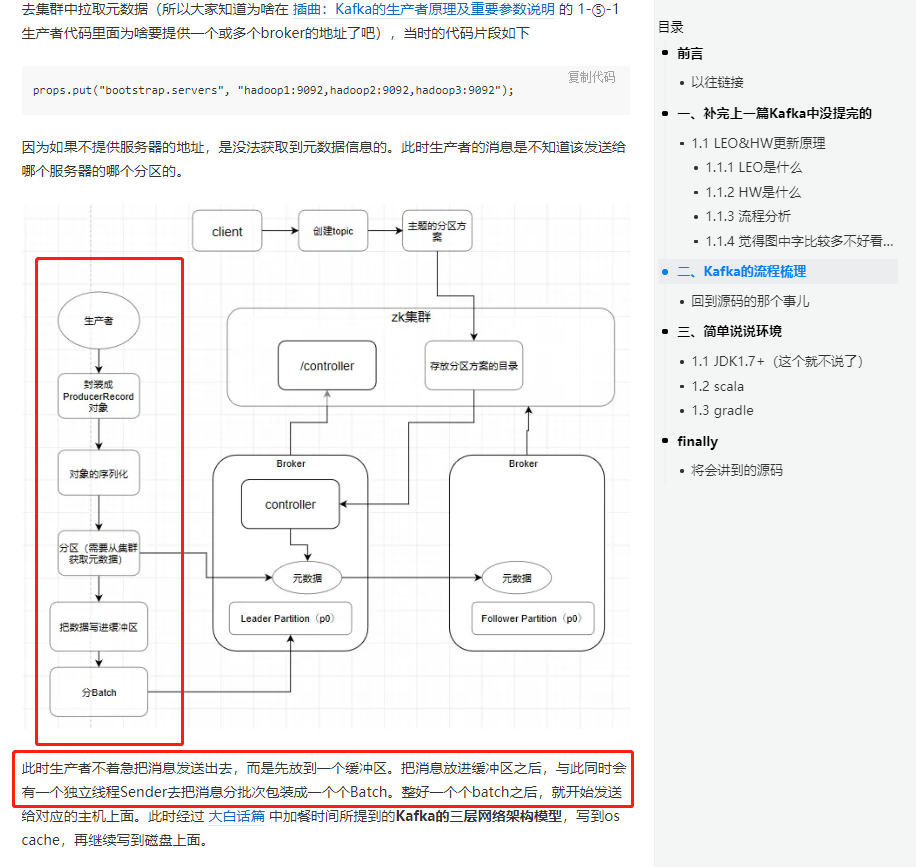
补充一下对 “拉取kafka的元数据” 的说明
因为之前的文章曾经有小伙伴对 props.put("bootstrap.servers", "localhost:9092"); 有疑问,这里再补充两句。集群中每一个broker的元数据都是一致的,我指定的那个localhost:9092不一定是leader,我获取到了集群元数据,自然就知道leader partition在哪里了,消费者和生产者都只会和leader打交道。然后通过leader我才知道该发去哪里。所以,指定地址(这个地址可指定多个)是为了找到一个broker拿到元数据,从而得知leader在哪里而已。
用作场景驱动的 run 方法
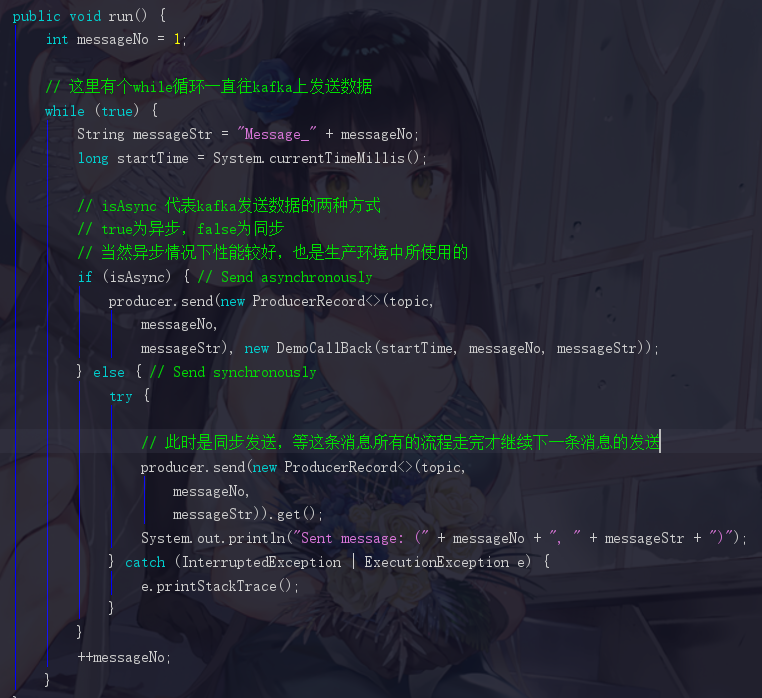
紧接着有一个run方法,模拟数据传入的
2.2 Kafka的初始化方法
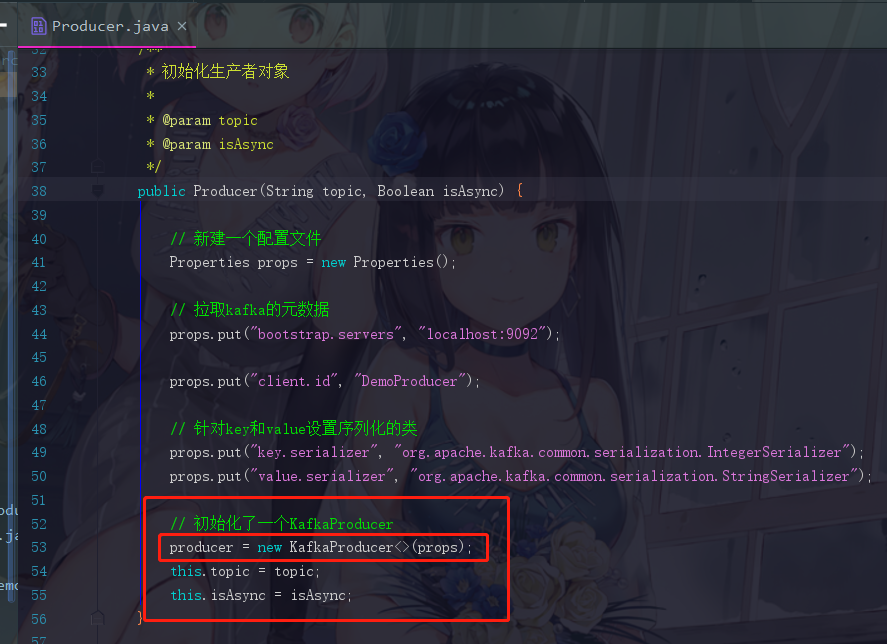
此时我们把目光聚焦在这个初始化方法,看它都干了些神马事情,此时会跳转到KafkaProducer.java,将近188行的那一个
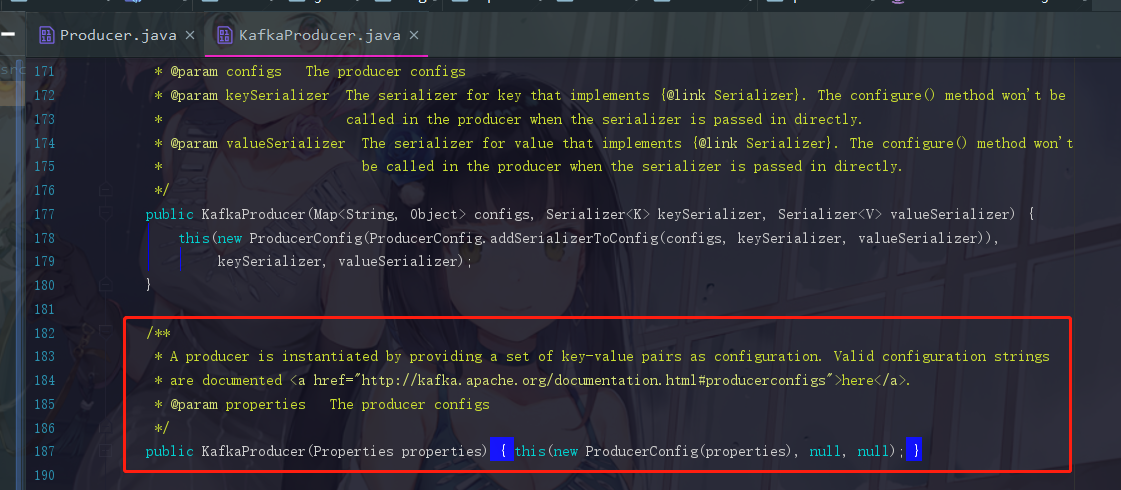
点进去this,我们就可以找到Kafka的构造函数了
2.3 Kafka的构造函数(原理分析)
此时我们先撇开源码不说,先来画个原理图。这整一个流程,和当时我们在 分析生产者的那一篇 中是一样的。
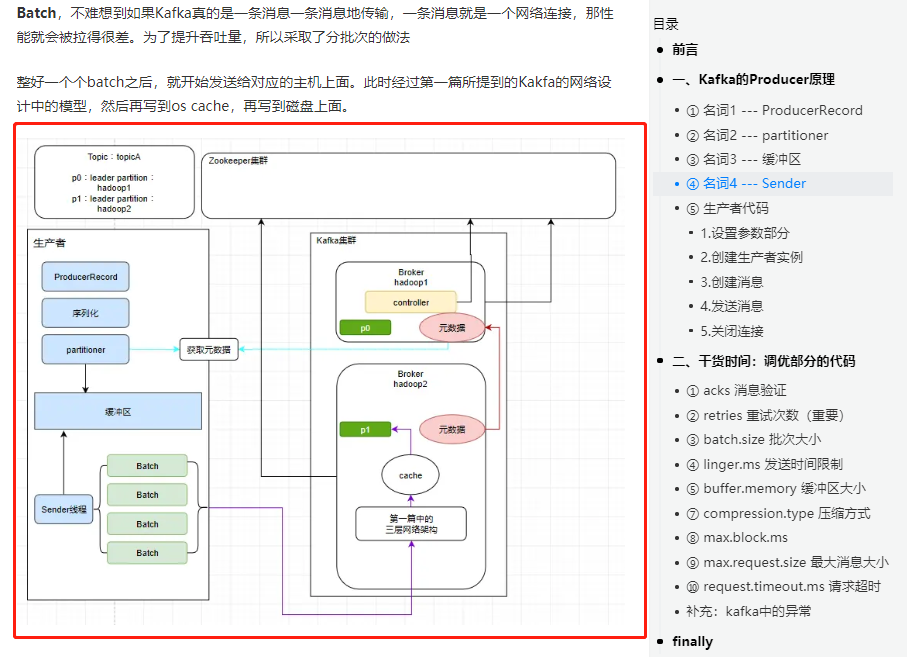
在 Kafka的运行流程总结和源码前准备 也有提到,如果对这块还不了解的朋友,可以跳转到这两篇中阅读,整理一下思路
2.3.1 丢进缓冲区前的操作
首先我们现在是初始化了一个 KafkaProducer 对吧。然后会有一个 ProducerInterceptors ,看这个英文像是拦截器,它会把我们的消息根据一定的规则去过滤掉。但是这个东西其实作用不大,因为我通过if-else都可以代替它的作用,所以就是比较鸡肋。所以发送消息前会用它进行一个消息的过滤,结束后会对消息进行 序列化 。序列化结束,就找到 Partitioner分区器 (要知道该发送到哪一台服务器上的哪一个分区)进行分区。
所以我们现在得到的四个关键词是

2.3.2 缓冲区的结构
此时发送之前,我们要先把消息放入一个缓冲区里面,那么这个缓冲区其实是叫 RecordAccumulator ,缓冲区里面会存在多个deque队列,之前的文章中也提到过,kafka的消息并不是逐条发送的,而是会打包成一个个批次(每个批次默认16K)发送。这些队列里面的封装好的消息批次会依次发送给不同的分区(图中仅列出1,2,3),比如下图
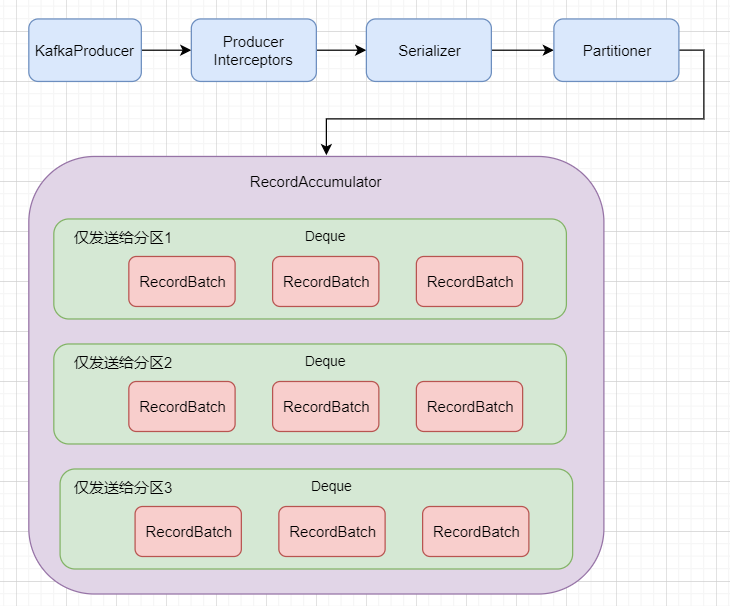
第一个deque就只负责发送给分区1,第二个deque就仅发送给分区2···依次类推
2.3.3 Sender线程的结构
真正发送数据的其实就是这个Sender线程,如下图
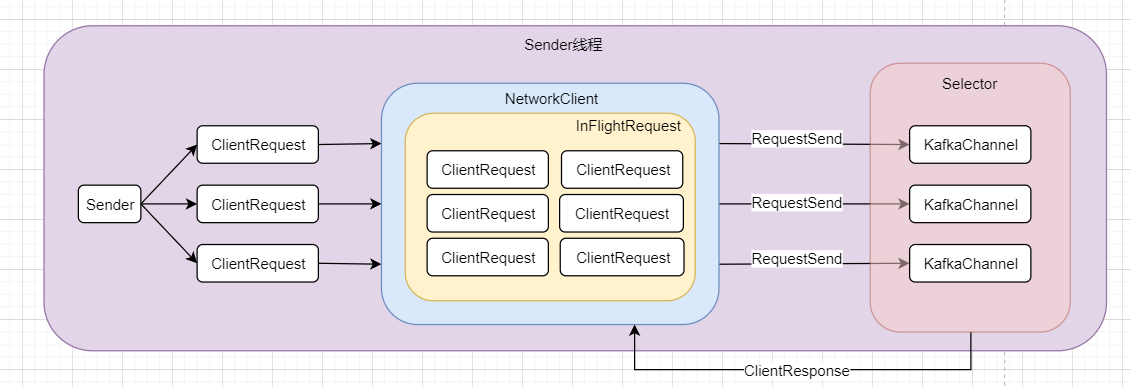
Sender启动起来之后会创建请求ClientRequest,这里的ClientRequest并不是完全一样的。因为发往不同的服务器应该是各种不同的请求。创建请求完成后,会发送给NetWorkClient,它是管理Kafka网络的非常重要的组件。它会在它的里面暂存请求,至于为何需要这样,我们之后说明。
后面的selector里的KafkaChannel其实就是类似于我们在 NIO 中所提到的SocketChannel,之后selector会发送消息给Kafka,这个过程是客户端向服务端发送消息,此时服务端,也就是Kafka会再返回响应,这个响应也仍旧是这个KafkaChannel接收,然后返回给NetworkClient,经过处理后返回给客户端。
2.3.4 原理分析总图
所以整个流程走下来应该就是这样的一张图。图中已经用数字1~12标好流程,当然也可以增加一个
13.NetworkClient返回结果给客户端
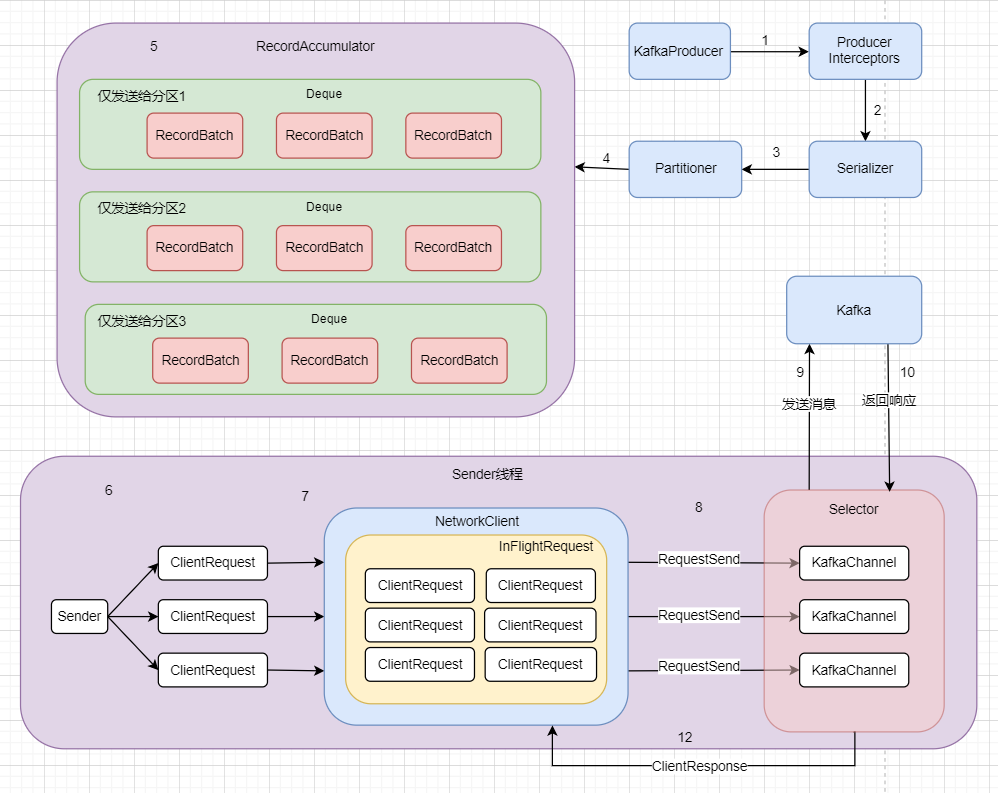
这个图也是非常非常粗略的一个流程说明,Kafka的源码细节远比这个图来的细致,所以大家看到这里如果觉得似懂非懂也是正常,后面结合源码说明一定能更加清楚。
2.4 构造函数源码
说白了源码我们讲到的部分就是我们刚刚画好的图的第一步,KafkaProducer的初始化操作。源码非常的长,所以我们会以小段截取的方式讲解,此时回到KafkaProducer.java,注意,不是主要逻辑部分,就会标明非重点
2.4.1 配置用户自定义的参数(非重点)
2.4.2 clientId(非重点)

2.4.3 metric(非重点)
metric是监控方面的,不是我们关心的逻辑部分

2.4.4 分区器

当时我们也有所提及,可以给每一个消息设置一个key,也可以不指定,这个key跟我们要把这个消息发送到哪个主题的哪个分区是有关系的。而分区器就是为了处理这些事情,这里默认你们忘了,截取以前的文章片段,是 Kafka的生产者案例和消费者原理解析 中的
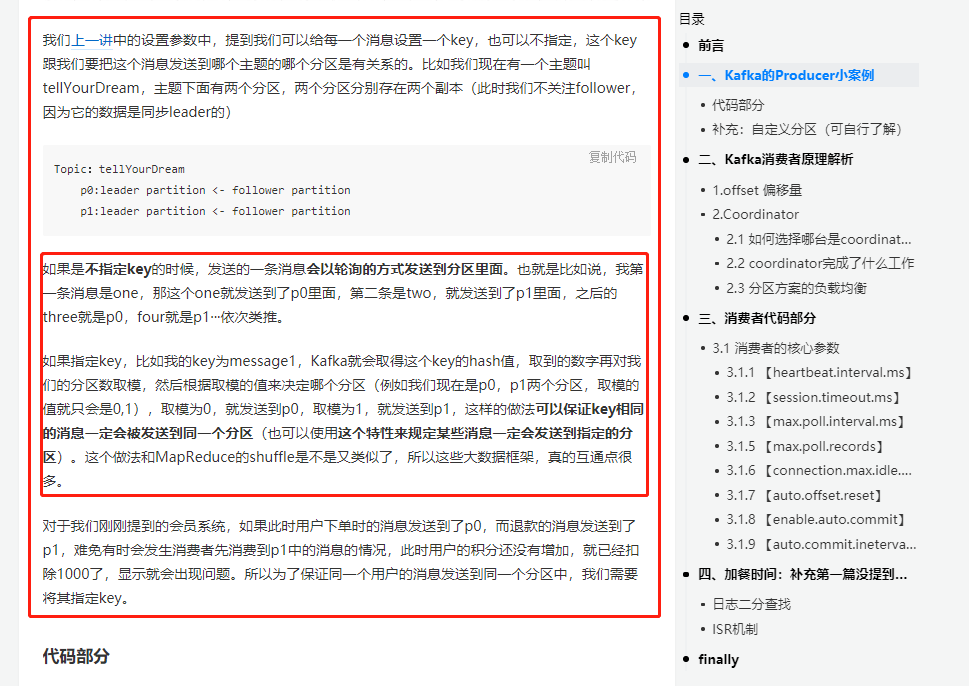
所以非常推荐大家能把以前的几篇基础读一下,相信会对你理解这些操作帮助很大。
2.4.5 重试时间(非重点)

这里大家知道这个参数就好了,也可以自行点进去看一下默认值,这里直接告诉大家默认是100毫秒得了
2.4.6 序列化器(非重点)

其实就是我们文章开篇的那两个

2.4.7 拦截器 (非重点)

2.4.8 元数据单元 Metadata
下方4个参数会分别提及一下

第一个参数
this.metadata = new Metadata(retryBackoffMs, config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG), true, clusterResourceListeners);
参数 METADATA_MAX_AGE_CONFIG ,默认值是5分钟,作用是默认每隔5分钟,生产者会从集群中去获取一次元数据信息。因为要发送消息的话我们必须保证元数据信息是准确的。
第二个参数
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
参数 MAX_REQUEST_SIZE_CONFIG 这里代表的是生产者往服务端发送消息时规定一条消息最大为多少。而如果你超过了这个规定的大小,你的消息就无法发送出去。默认是1M,这个值有点偏小了,生产环境中需要去修改这个值。比如10M,当然这个因地制宜,大家需要结合公司的实际情况决定。
第三个参数
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
参数 BUFFER_MEMORY_CONFIG 指的是缓冲区,也就是 RecordAccumulator 大小。这个值一般是够用的,默认是32M
第四个参数
this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));
参数 COMPRESSION_TYPE_CONFIG 默认情况下是不支持压缩,不过也可以设置,可供选择的除了none,还有gzip,snappy,lz4,我们一般会使用lz4,这些都是可以点进去源码里面查看的。这里我就不点进去了。
进行了压缩后,一次发送出去的消息就变多,自然吞吐量是上来了,不过会对cpu造成一定的负担,请思考清楚后使用。
2.4.9 根据先前提供的参数初始化缓冲区
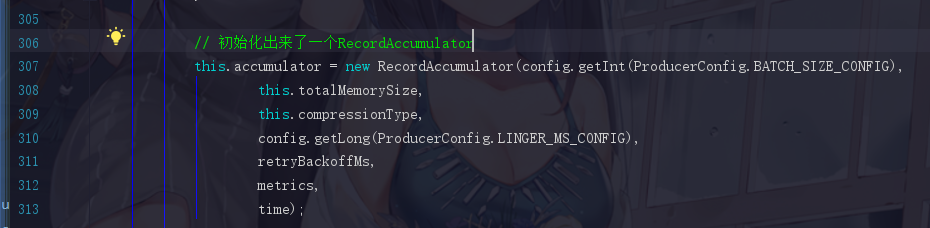
2.4.10 获取集群中的元数据信息的地址

参数 BOOTSTRAP_SERVERS_CONFIG 和我们之前写过的demo代码是一样的
props.put("bootstrap.servers", "hadoop1:9092,hadoop2:9092,hadoop3:9092");
BOOTSTRAP_SERVERS_CONFIG 就是这个"hadoop1:9092,hadoop2:9092,hadoop3:9092",它的作用就是给生产者指明方向去获取集群中的元数据而已。
2.4.11 update
这个看起来把地址作为参数传进去了,像是获取或更新元数据信息的方法,后面我们来验证一下我们的猜测是否正确

2.4.12 初始化组件 NetworkClient
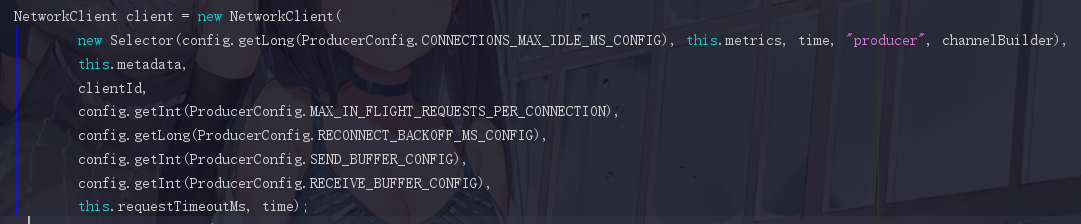
这里面也有好几个参数需要去注意
--- ① CONNECTIONS_MAX_IDLE_MS_CONFIG
一个网络连接最大空闲时间,超过之后会自动关闭此连接,默认值为9min
一般情况下我们会设置成-1,-1时是什么情况下都不回收
--- ② (重要)MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION
每个发送数据的网络连接对并未接收到响应的消息的最大数。默认值是5
是不是感觉非常地拗口,那我们换个说法,producer向各个服务器发送数据都会建立不同的网络连接,然后开始发送数据,假如现在我们的MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION设置成默认值5,发送了1,2,3,4,5···,这服务器都没给我们返回响应,那消息6我们就不能继续再发了。
注意:因为Kafka的重试机制有可能会导致消息乱序,所以我们一般为了保证消息有序会把 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 设置为1.
比如我们常见的订单系统和会员积分系统就是非常鲜明的场景,订单是要创建过后才能取消的,而对应的会员积分是要先增后减的,如果这个顺序不能保证,系统就会出现问题。
所以千万不要以为,给我们的message设置了key,保证了同一个场景的消息放到了同一个分区,就可以保证消息的顺序,在Kafka中要保证真正的有序,是需要设置这个 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 参数为 1 的
--- ③ SEND_BUFFER_CONFIG 和 RECEIVE_BUFFER_CONFIG
因为这不是很重要的东西所以就丢一起了,就是NIO的一些东西
SEND_BUFFER_CONFIG 指socket发送数据时缓冲区的大小,默认128K(如果忘记了请回顾NIO篇)
RECEIVE_BUFFER_CONFIG 指socket接受数据的缓冲区的大小,默认是32K
2.4.13 Sender线程的初始化流程
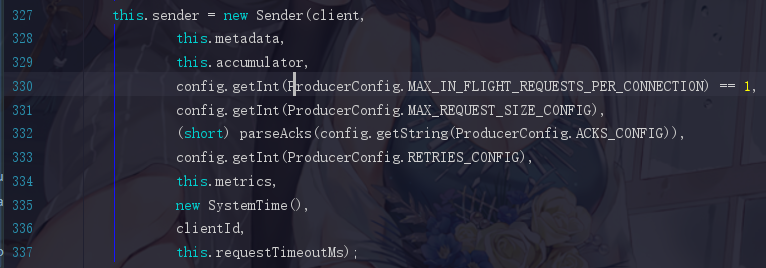
重要的参数就一个,RETRIES_CONFIG 是重试次数,默认是不重试,这样就十分坑爹了,这个情况下程序很脆弱,只要稍微出现了一些小毛病就挂掉了。大数据都是分布式的系统,因为网络的一些不稳定,导致整个系统挂掉,那就得不偿失了。之前也告诉过大家了,程序中 95% 的问题,都是可以通过重试解决的
当然 ACKS_CONFIG 这个参数也十分重要,不过我们在之前讲生产者的时候已经讲过了,不信我给你截图
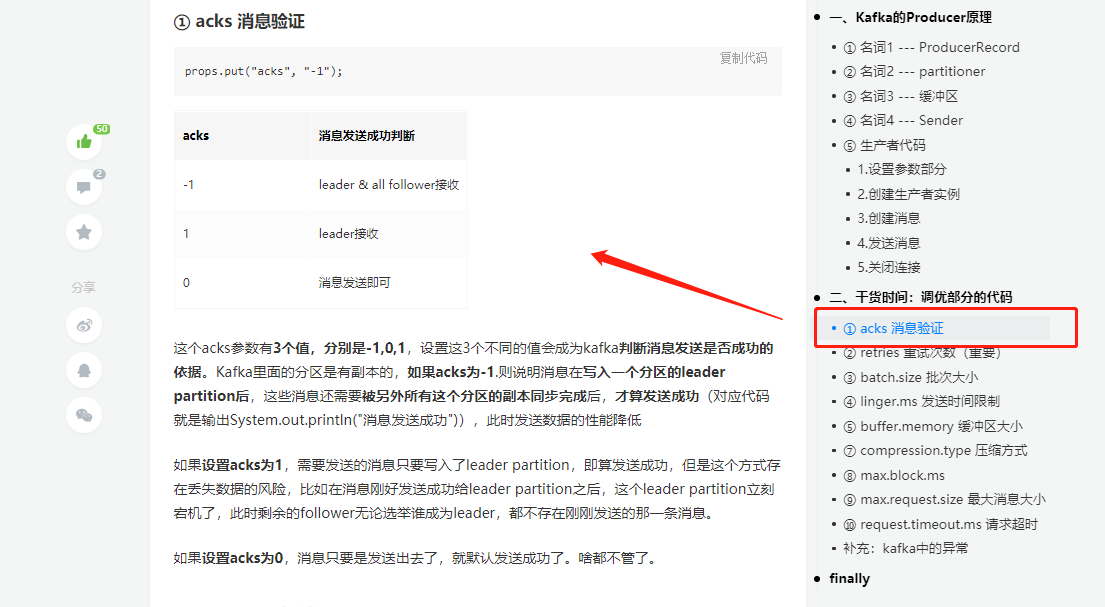
你看,我不会骗你的。在此也是再强调一次,前面几篇的基础都是有用的,最好还是可以去补补哦!
所以如果面试时候问如何保证数据不丢失,ACKS_CONFIG是一个很重要的参数。要设置为 -1,还有另外一个参数后面再提。
2.4.14 启动Sender线程

在这里你会发现,Kafka的源码在一些细节方面做的相当的出色,它这个new KafkaThread可以点进去看一下
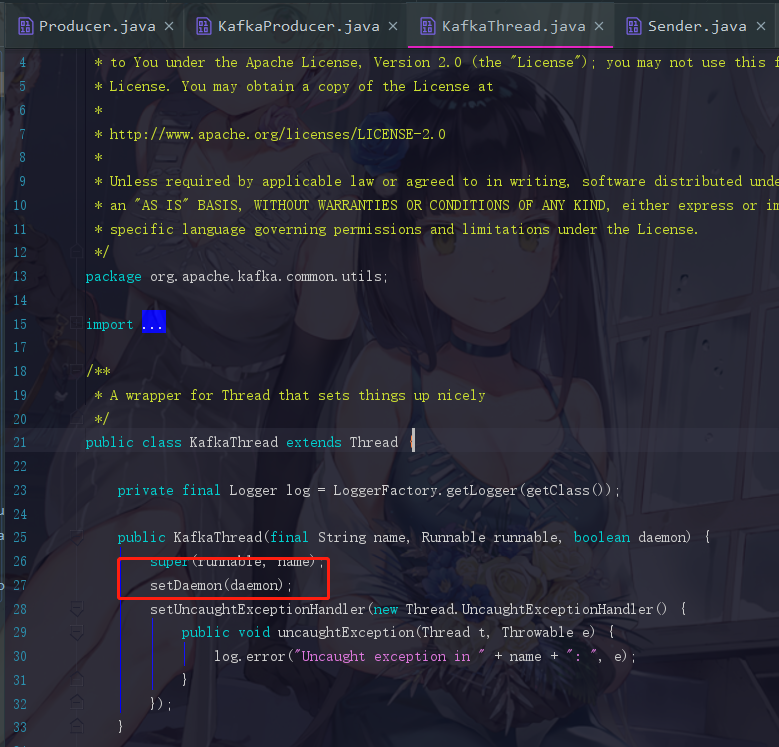
它就是把这个线程设置成后台线程,它不直接启动而是创建线程把Sender传进去的原因就是因为它要把业务代码和线程相关的代码隔离开来,就算之后你还要增加一些参数给这个线程,你也直接在 KafkaThread.java 中补充即可。通过这些小细节,是可见这个代码的编写是十分优秀的。
到这里这个生产者的构造函数就差不多了,不过我们还有metadata这个关键的东西没有展开
2.5 Metadata是如何管理元数据的
我们点进去Metadata.java来看看
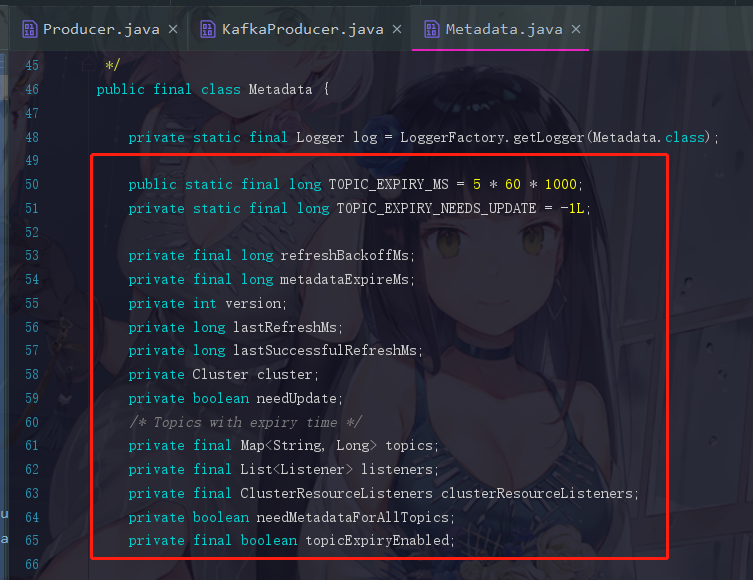
这里面的参数简单过一下
2.5.1 refreshBackoffMs
两次更新元数据的请求的最小时间间隔,默认100ms。因为我们请求元数据的过程其实不是一定成功的,而请求不到元数据信息的话,那我们就找不到leader partition了。
2.5.2 metadataExpireMs
这个是多久时间自动更新一次元数据,默认5min一次
2.5.3 version
对于producer端来说,元数据是有版本号的,每次更新元数据后都会更新这个版本号。
2.5.4 lastRefreshMs
最后一次更新元数据的时间
2.5.5 lastSuccessfulRefreshMs
最后一次 成功 更新元数据的时间
2.5.6 cluster(最重要)
Kafka集群的元数据
2.5.7 needUpdate
是否需要更新元数据的标识
2.5.8 topics
表示现在已有的topic
2.6 Cluster --- Kafka集群中的元数据
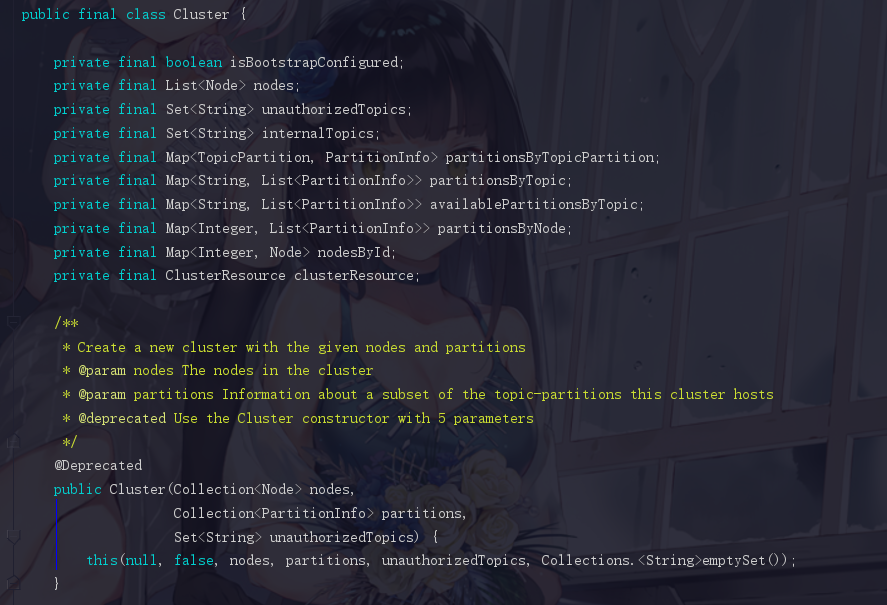
2.6.1 nodes
我们知道Kafka集群是多个节点的,这个参数代表的就是Kafka的节点,我们也可以点进去node看看,其实无非就是一些主机名,端口号等字段
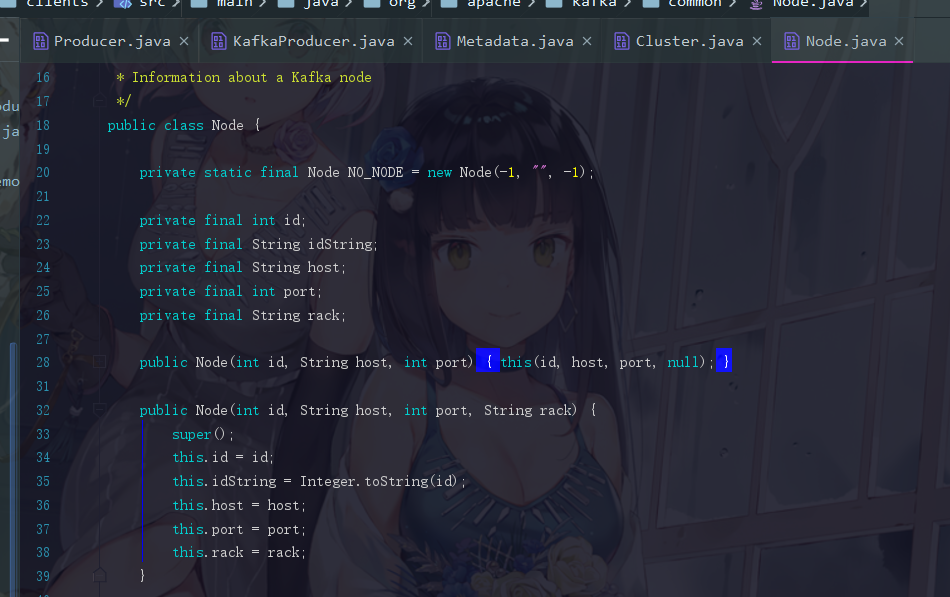
2.6.2 unauthorizedTopics 和 internalTopics
关于Kafka的权限方面的topic,知道有这么回事就可以了
2.6.3 一些封装好的数据结构
这些数据结构不一定是全部用的上的
private final Map<TopicPartition, PartitionInfo> partitionsByTopicPartition;
private final Map<String, List<PartitionInfo>> partitionsByTopic;
private final Map<String, List<PartitionInfo>> availablePartitionsByTopic;
private final Map<Integer, List<PartitionInfo>> partitionsByNode;
private final Map<Integer, Node> nodesById;
private final ClusterResource clusterResource;
Map partitionsByTopicPartition ,代表了partition和它的关联信息,我们可以点进去 PartitionInfo 看看,为了方便观看,我就直接写好注释了
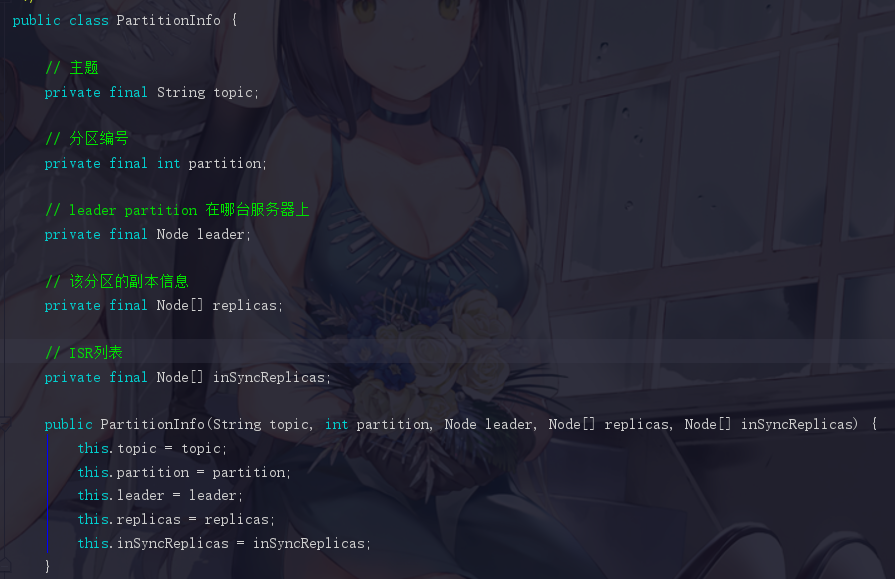
所以 PartitionInfo 其实就是这个 partition 所对应的信息
Map> partitionsByTopic 代表这个topic有哪些分区
Map> availablePartitionsByTopic 代表这个topic有哪些可用的partition
Map> partitionsByNode 这台服务器上面有哪些partition(服务器用的是服务器的编号标识)
private final Map nodesById 记录服务器和服务器编号(编号从0开始)的Map
private final ClusterResource clusterResource Kafka集群的id信息(这个参数不怎么重要)
那到这里,Metadata的结构我们大体上就了解了,回到一开始的 KafkaProducer.java
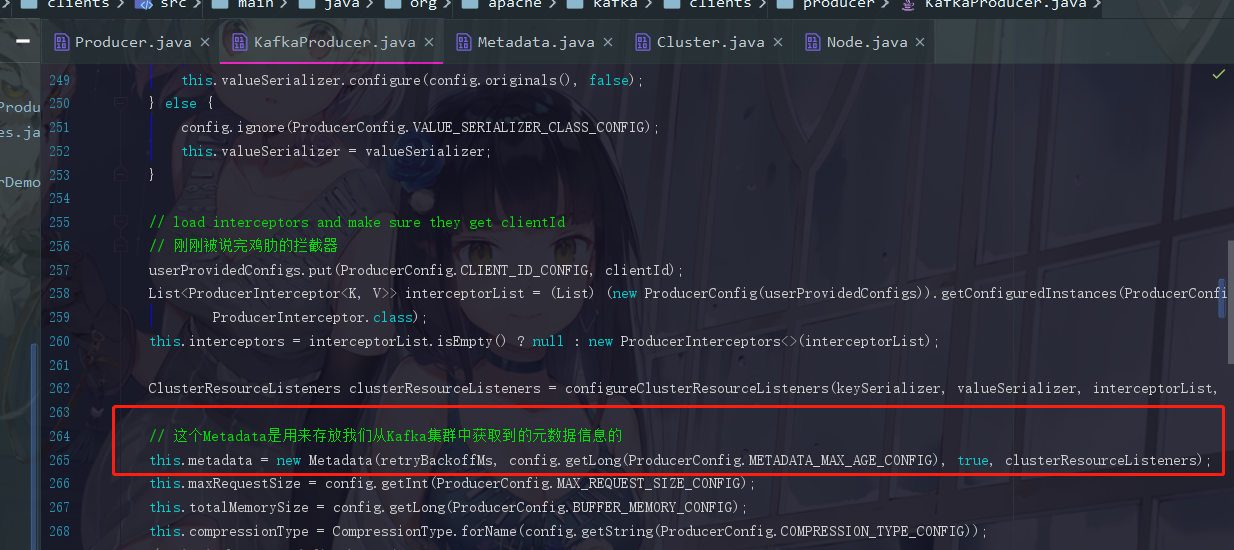
现在我们就知道了,它是靠上面我们所说的这些数据结构去维护元数据信息的
2.6 刚刚我们猜想是获取更新元数据的update
对2.4.11 的展开说明

点进去update,拉到大概204行看看
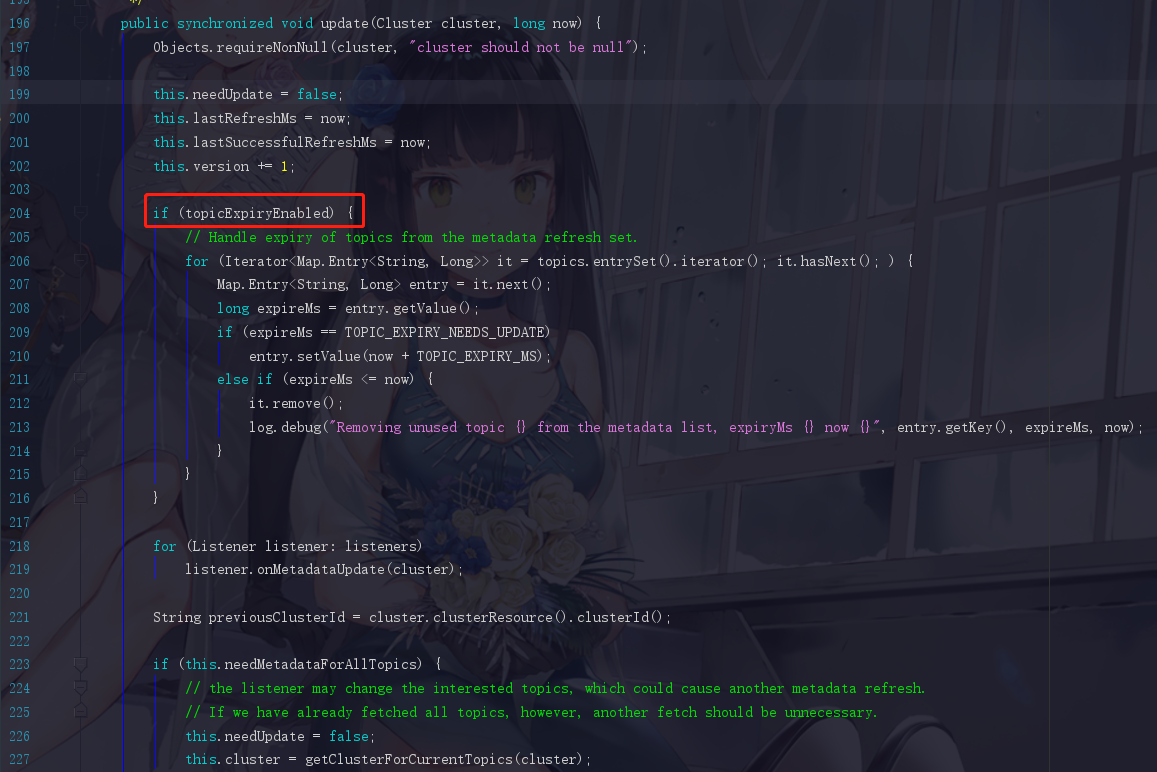
我们都可以逐一地把这些条件的默认值看一下
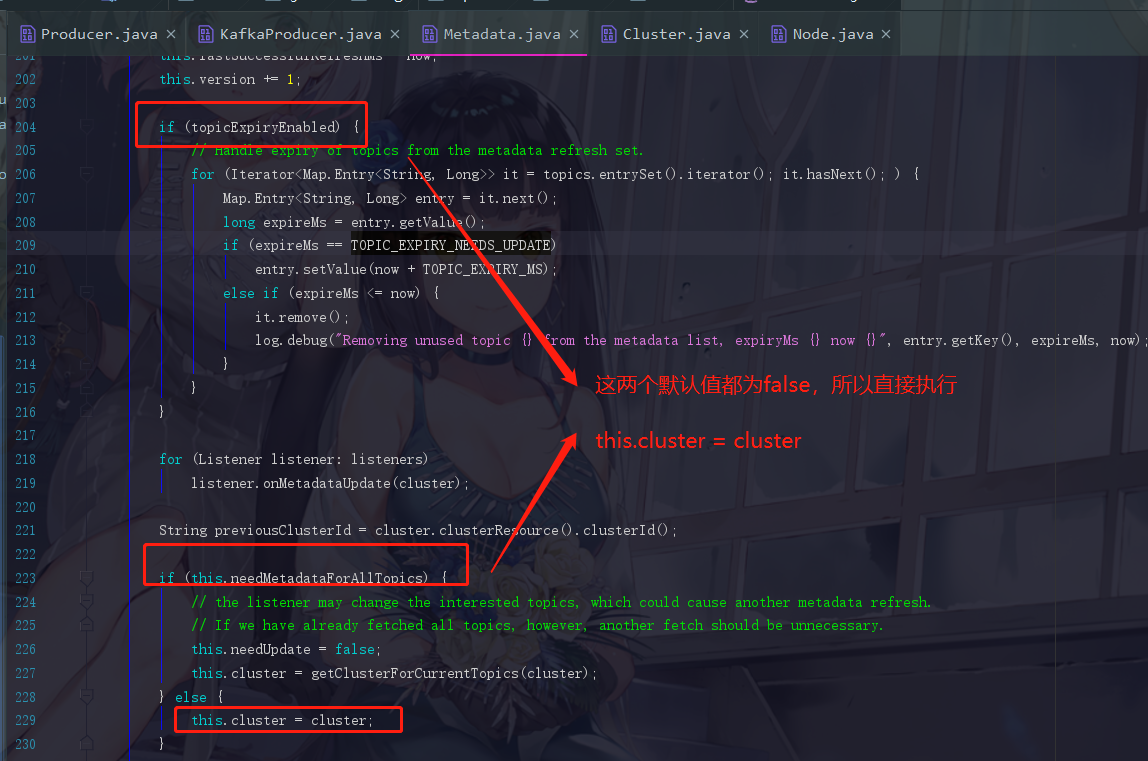
可是我们现在就懵了,这个cluster不就是刚刚我们传进来的参数 Cluster.bootstrap(addresses) 吗?这明显啥都没干啊,所以我们一开始的猜想就错了,所以结论就是:
生产者在初始化的过程中,是并没有去获取元数据信息的
但是转念一想,反正我们发送消息的时候,是一定要获取到集群元数据才可以得知集群中leader的存在的,所以我们之后只要到发送的逻辑前后去找就好了。
到这些,生产者的初始化就结束了。
2.7 获取到的信息
在KafkaProducer的初始化过程里面,初始化了很多重要的参数和几个核心的组件,也带领大家把图大致地画了出来,例如 RecordAccumulator ,Sender,NetworkClient,而且Sender线程其实是初始化好的时候就已经启动了。还有初始化的过程中并没有拉取元数据的行为。
三、producer发送消息的核心流程
回到梦开始的地方,那个源码中自带的例子
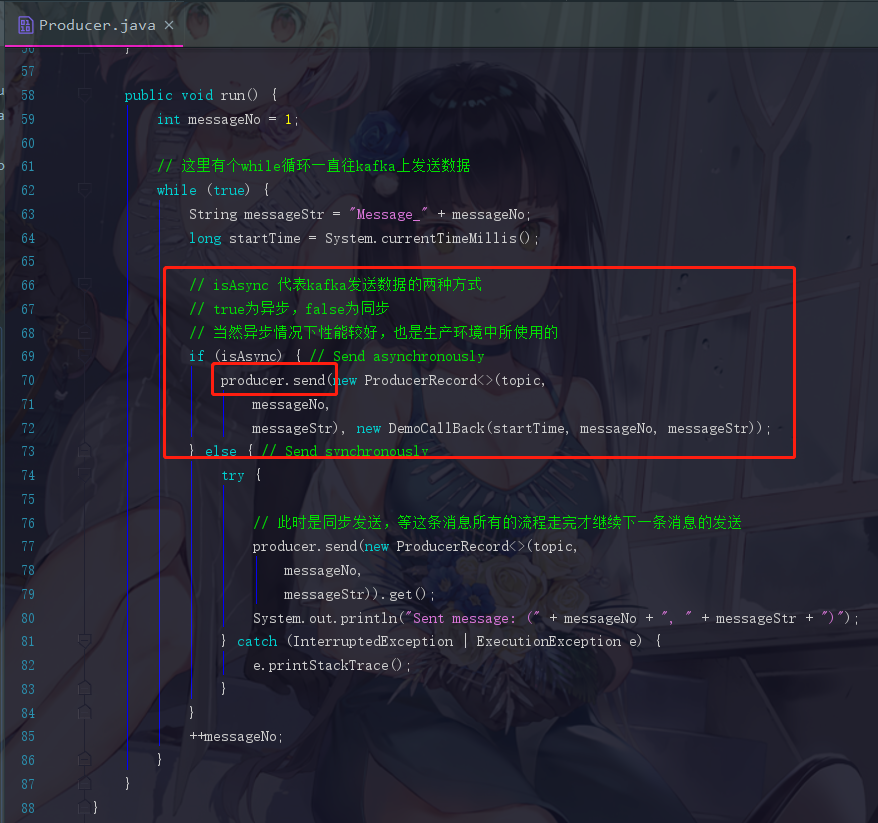
我们知道就是这个send来发送消息的,那我们就点进去看看吧
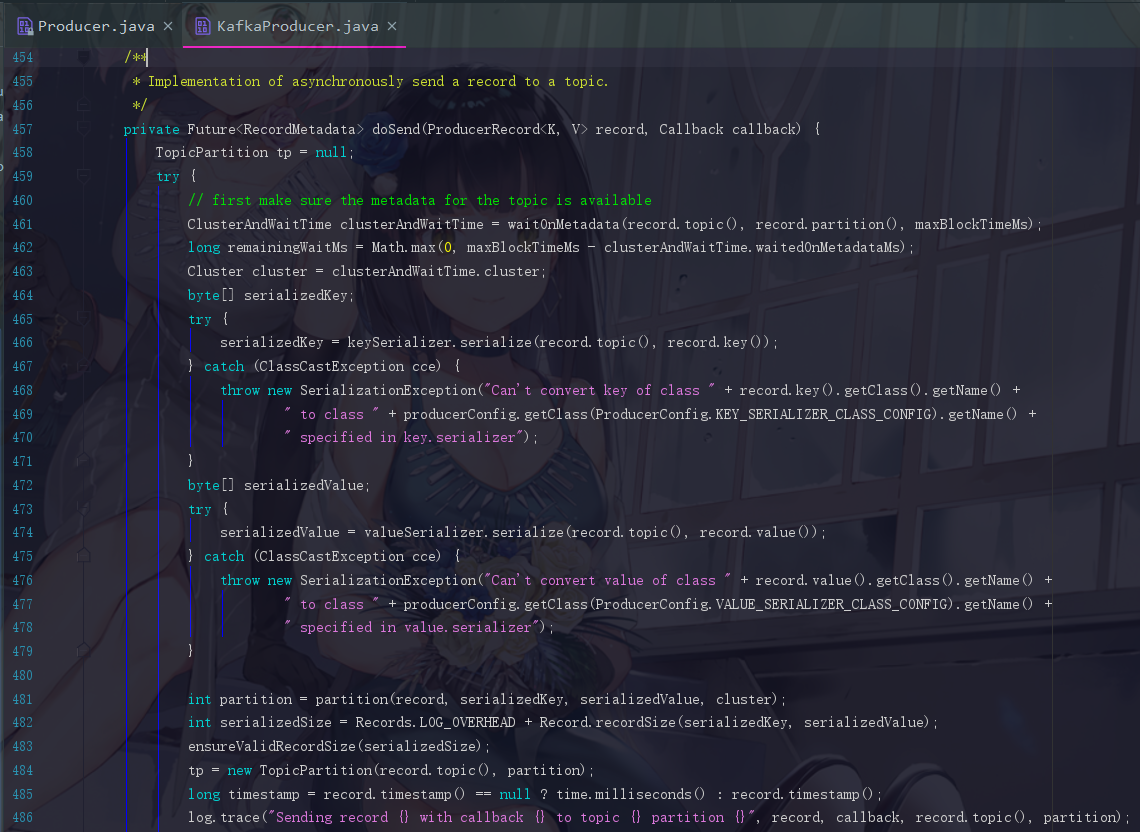
我们可以看到,代码非常长,大致跳转到了KafkaProducer的454行,直接从try开始整理步骤,其实这个步骤,我们也是大致清楚的

暂时走这前5步
3.1 拉取元数据

把注释放到百度翻译,这东西就完美地理解了,我们在发送消息前就是通过这个waitOnMetadata来同步等待元数据的拉取的。maxBlockTimeMs是指最多等待这个拉取过程多久,因为这个拉取过程进行时代码是阻塞在这里的,所以我们必须设置一个时间限制来放行。

这个计算了一个剩余时间,然后把集群中的元数据更新。

3.2 对消息的key,value进行序列化
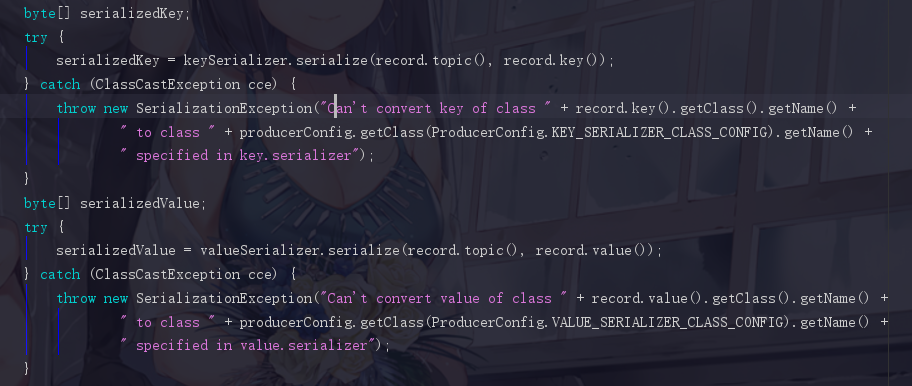
3.3 根据分区器选择消息应该发往的分区
int partition = partition(record, serializedKey, serializedValue, cluster);
int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);
因为现在我们已经获取到了元数据了,这儿就可以开始根据元数据信息进行计算得出发送结果。
3.4 确认一下消息的大小是否超过了最大值
ensureValidRecordSize(serializedSize);
KafkaProducer初始化的时候,指定了一个参数,代表了producer这里最大能发送的一条消息能有多大,默认1M,一般都会修改
3.5 根据元数据信息封装分区对象
tp = new TopicPartition(record.topic(), partition);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
3.6 给消息绑定回调函数
Callback interceptCallback = this.interceptors == null ? callback : new InterceptorCallback<>(callback, this.interceptors, tp);
因为我们是异步发送的方式,所以需要回调函数来确认
3.7 消息存入 RecordAccumulator
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
RecordAccumulator是默认32M的一块缓冲区,之后在这里我们需要把消息封装成一个个的batch来发送,如果批次满了,就会新创建出一个新的批次。启动Sender线程去发送数据。
四、waitOnMetadata是如何工作的
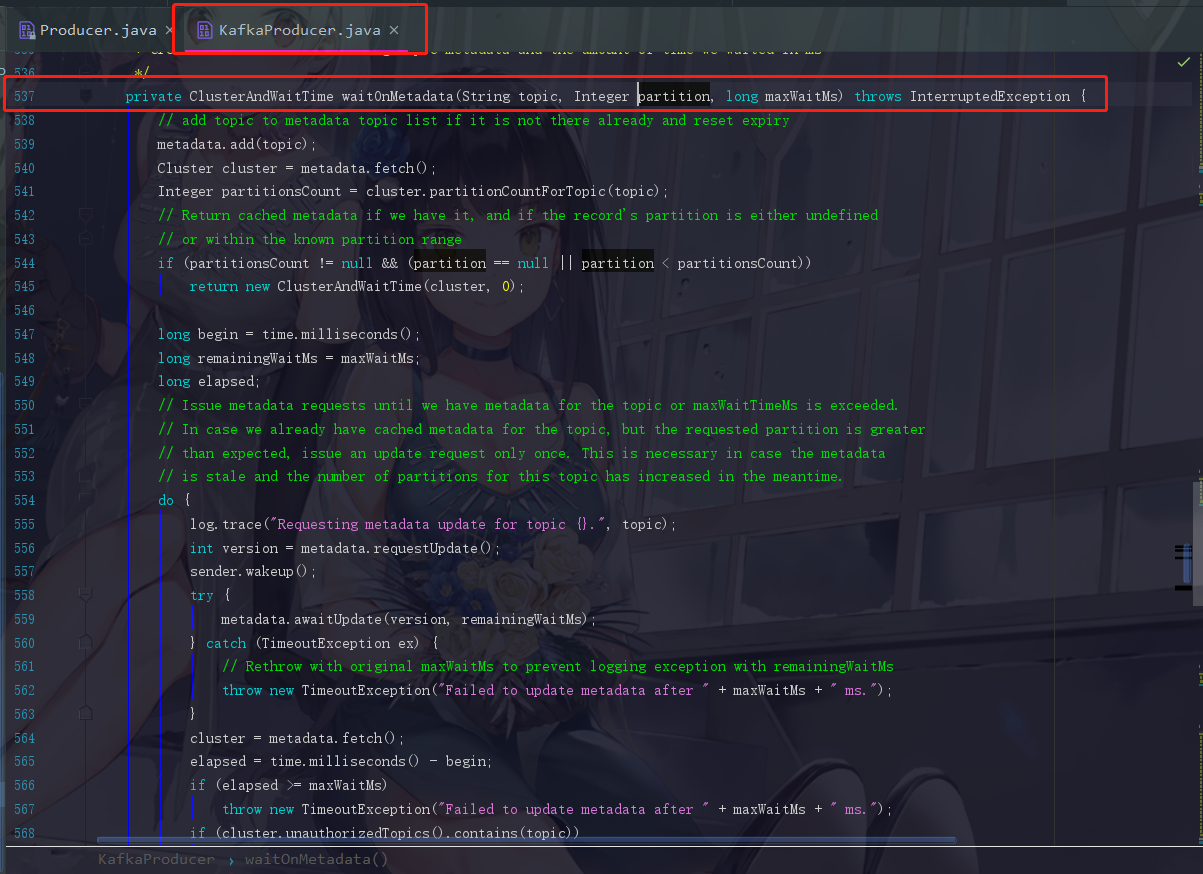
4.1 把当前的topic存入到元数据里面
// add topic to metadata topic list if it is not there already and reset expiry
metadata.add(topic);
注释翻译:将主题添加到元数据主题列表(如果尚未存在),并重置过期时间
4.2 fetch操作
Cluster cluster = metadata.fetch();
这里fetch是直接从缓存中获取到已存在的元数据。但是经过我们刚刚的分析,我们知道此时这个cluster是没有数据的,这里面只有我们作为参数的addresses而已。根据我们的场景驱动,在第一次执行到这里时也是刚好KafkaProducer初始化完成的时候。此时cluster并没有获取到元数据
4.3 查看分区信息
Integer partitionsCount = cluster.partitionCountForTopic(topic);
这里是根据当前的topic从集群中的cluster查看分区信息,但是同理,第一次执行时也是没有数据的,cluster啥都没有
4.4 返回元数据信息和时间
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
同理,我们根本不会执行到这一步,因为我们第一次执行时根本没有获取过元数据
4.5 从服务端拉取元数据
刚刚的4.2~4.4第一次执行都是无用功,拉取元数据还得从这里开始。先是定义了3个关于时间的参数
// 记录当前时间
long begin = time.milliseconds();
// 剩余多长时间,默认值为刚刚提到的最大等待时间
long remainingWaitMs = maxWaitMs;
// 已花时间
long elapsed;
然后是一个do···while循环来获取元数据
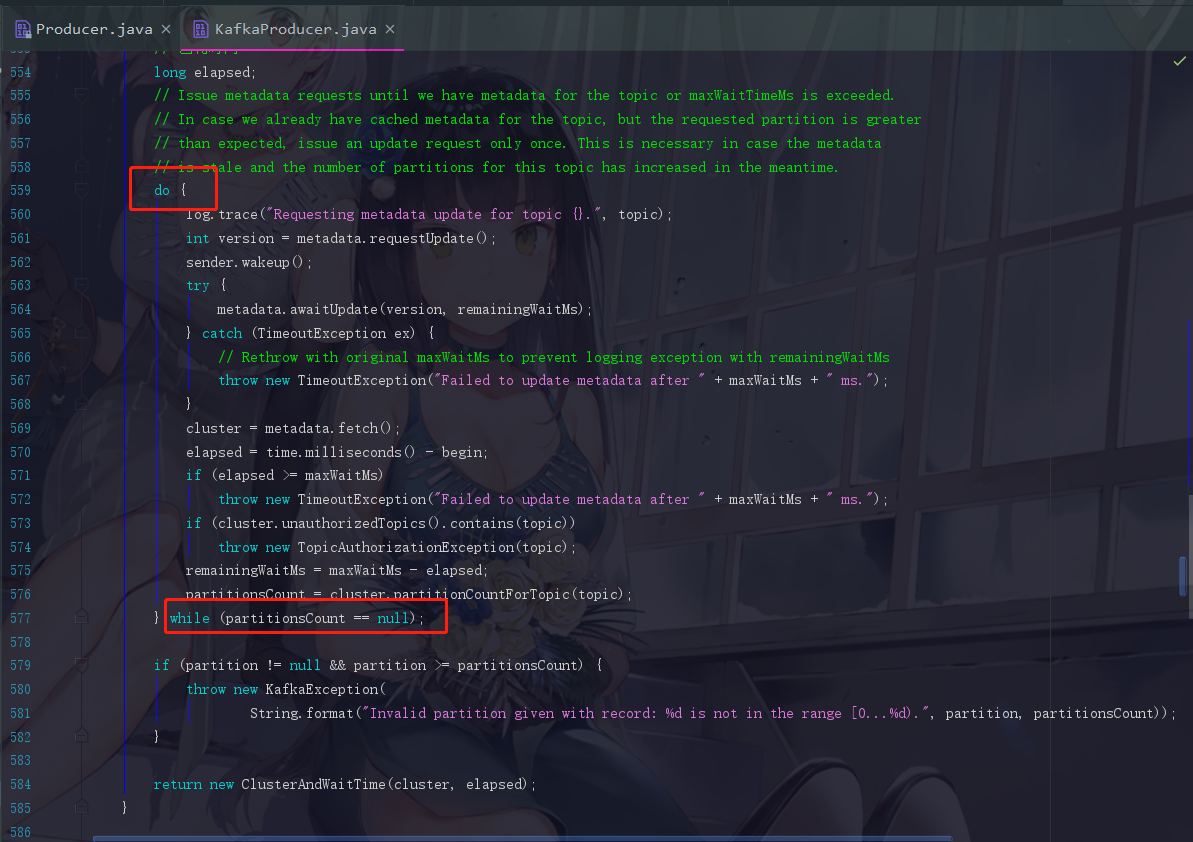
4.5.1 版本号的问题
int version = metadata.requestUpdate();
此时我们的第一个操作就是获取到元数据的版本,对于producer来说,元数据是有版本号的,每次成功更新元数据都得要更新一次版本号。requestUpdate方法主要是把 2.6.7中的 needUpdate 的值改为true,然后获取到当前元数据的版本号。
4.5.2 sender.wakeup()
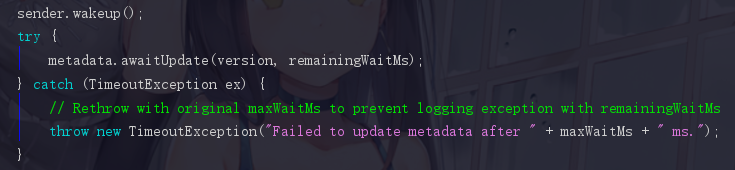
这里我们发现Sender线程也开始干活了,其实是因为拉取元数据的过程是由Sender线程来完成的,这个地方把Sender唤醒之后,就开始 同步 等待元数据的到来,这一点可以从while (partitionsCount == null)可知
4.5.3 尝试获取一些参数
如果成功执行,应该就已经获取到元数据了,所以我们可以尝试获取一些参数信息
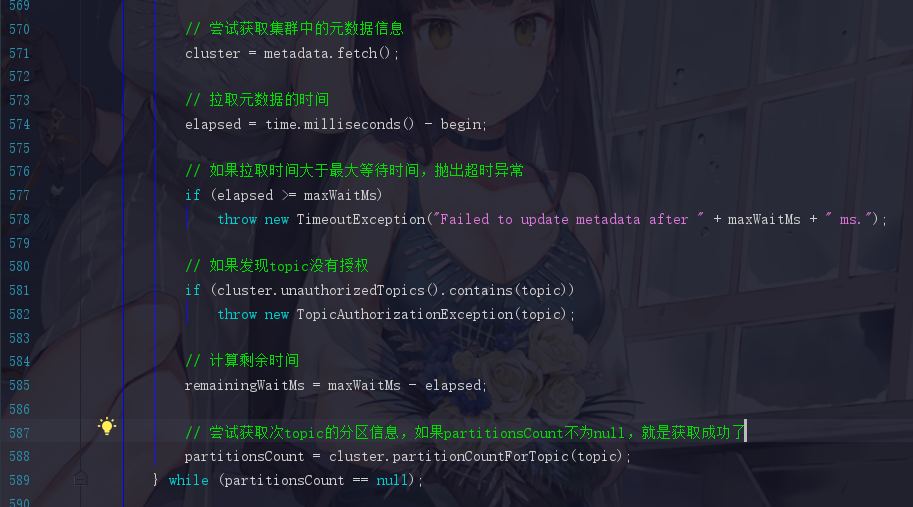
4.5.4 同步等待元数据的awaitUpdate
在4.5.2我们提到了通过这个方法同步等待元数据的到来
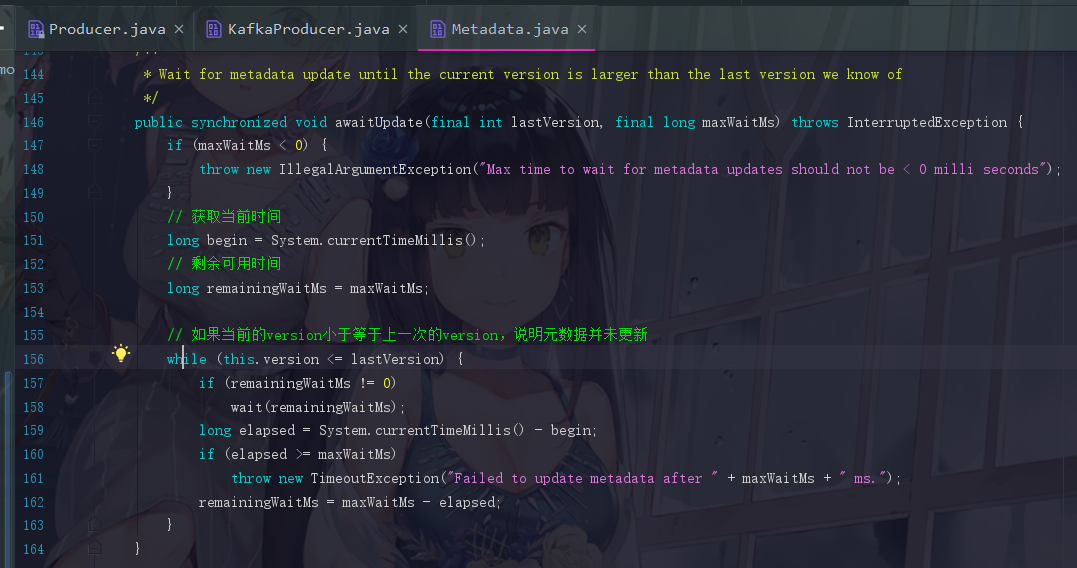
虽然我们还没去看Sender线程的源码,可是我们猜也能猜到,更新元数据成功之后一定会把这个 wait(remainingWiaitMs) 给唤醒。其他大部分的代码都是大家已经可以看懂的代码了。
4.6 Sender是如何拉取元数据的
去到Sender.java,然后找到run方法
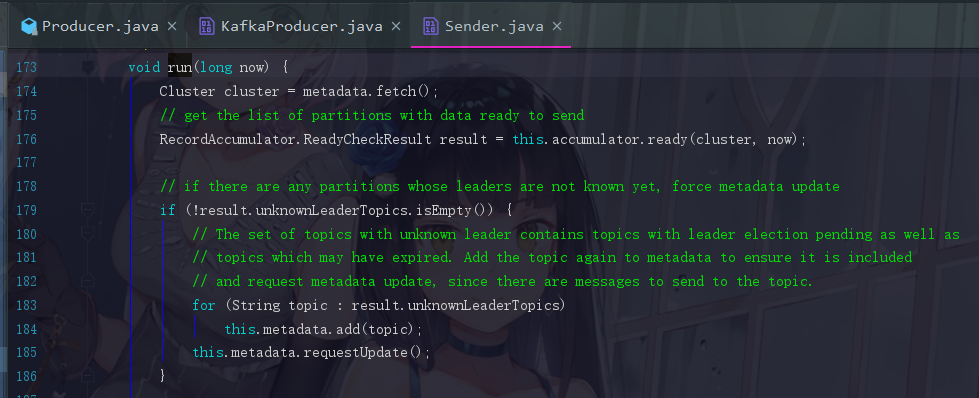
第一句Cluster cluster = metadata.fetch();我们已经看了好多好多次了,是没有元数据的大家应该都知道了。是的,这个run方法虽然很长,可是,一直到236行,在第一次执行,没有元数据的情况下,都是不执行的,执行的只有下面这一句
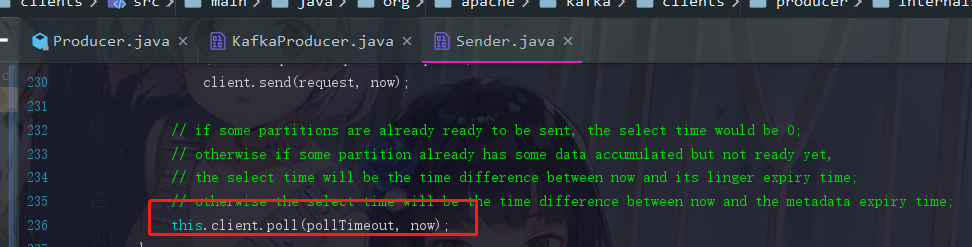
这里面的client,我们点一下,会发现是一个 KafkaClient,而这 KafkaClient,它的实现类是 NetworkClient

而我们如果要看poll方法的逻辑,就直接点开 NetworkClient 的poll即可
4.6.1 NetworkClient 的poll方法
Kafka的网络设计之后我们再提及,如果阅读这里有压力的话,之后再回头看这里就很好懂了。
--- 步骤1:封装了一个拉取元数据请求
long metadataTimeout = metadataUpdater.maybeUpdate(now);
点进去 maybeUpdate 瞧瞧
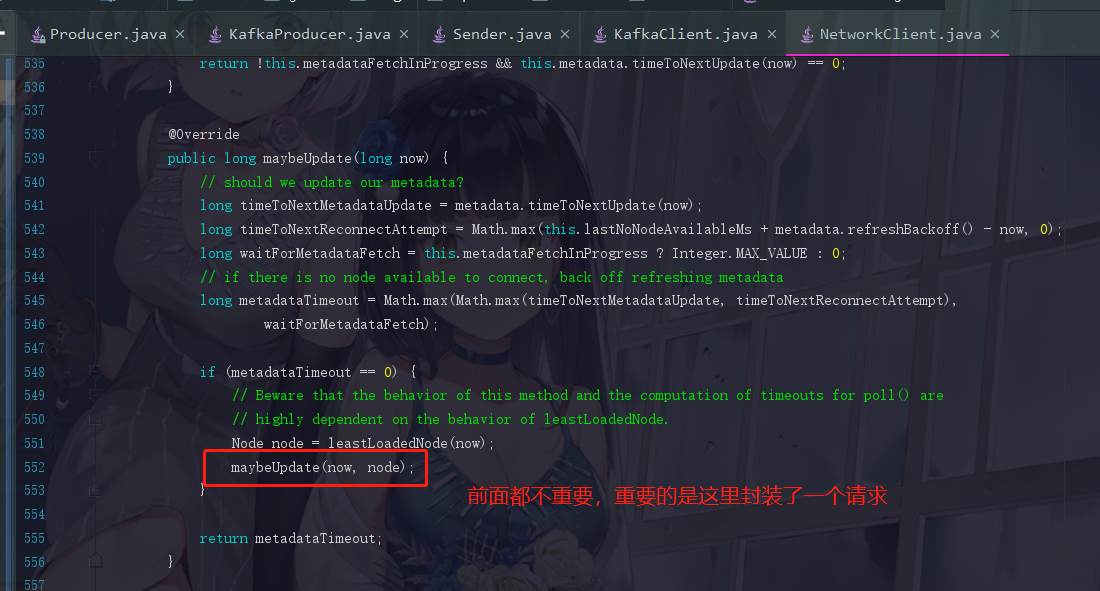
继续点击,能看到一个封装好的request,这个请求完成之后下一句代码就是doSend
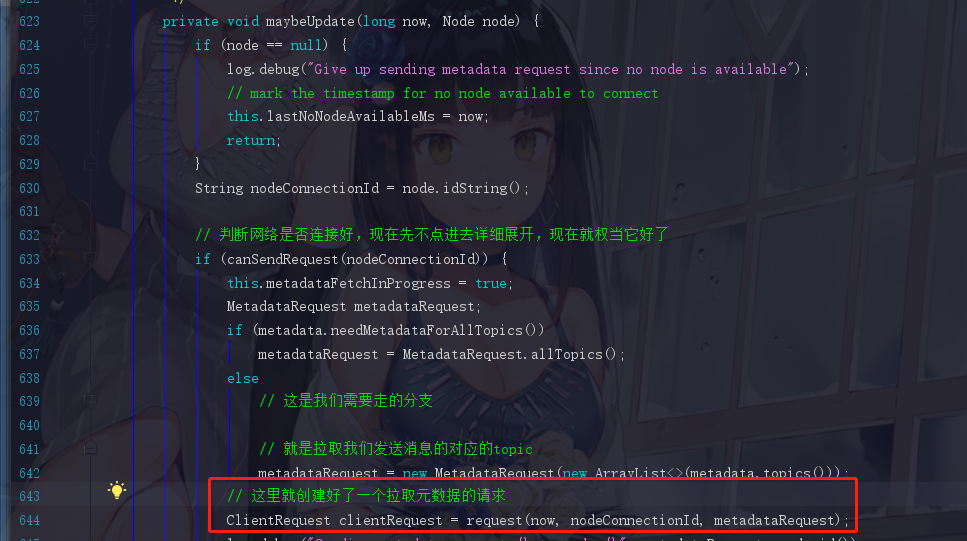
点进去,是一个ClientRequest

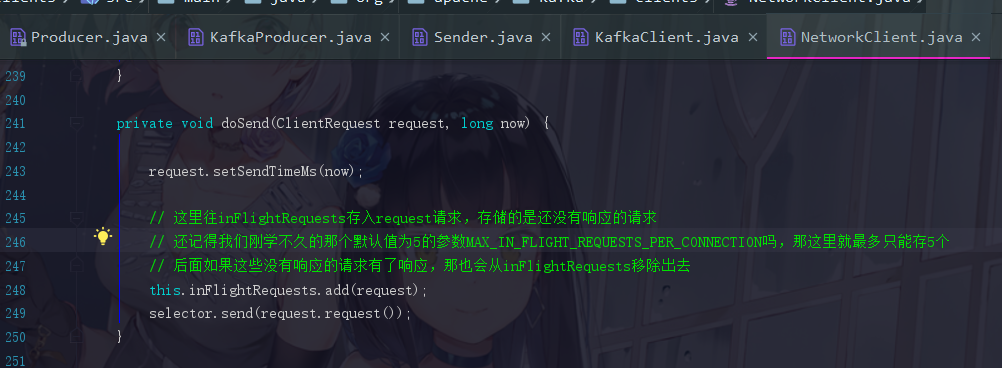
之后我们点send方法,说真的我都有点头晕了,此时会跳到Selectable.java里面,发现send是个抽象方法,实现是Selector.java

这里所有的参数我们都先不看,下篇我会展开,我们现在只想找到获取元数据的那个东西,差不多240行会看到它的send方法
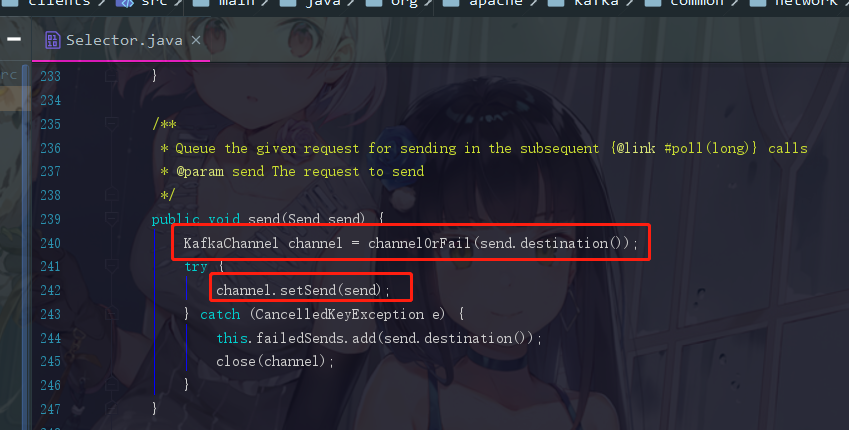
点进去setSend,会跳转到KafkaChannel的setSend方法
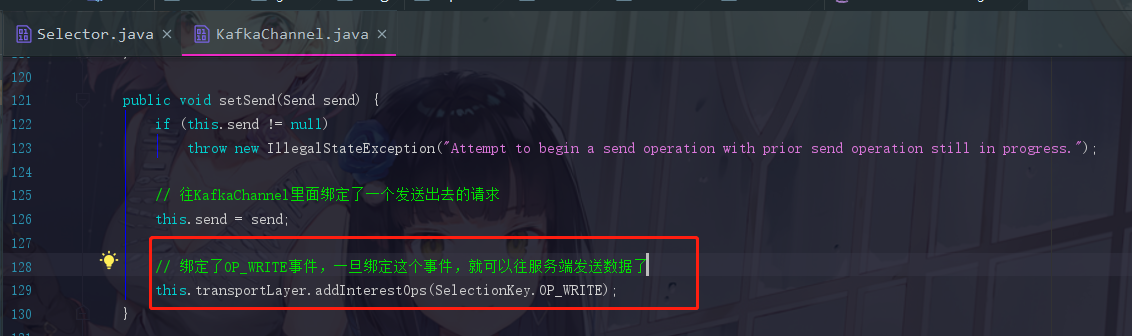
看到没有,连selectionKey都是一模一样的,如果在这里不能理解的话,请跳转NIO篇的NIO非阻塞式网络通信那里去复习一下哦
退回到networkClient的poll方法
--- 步骤2:执行网络IO的操作
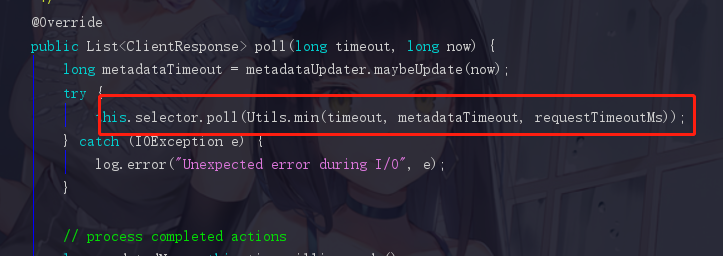
这个部分全部都是NIO的知识,在这里我就不展开了。因为是那种不难但是跳来跳去的问题,截起图来稍嫌麻烦。如果有存在疑问的话,欢迎交流,这里我就跳过这些NIO的步骤了。我们之后会看到一个writeTo方法把请求发送出去给服务端。知道这么回事就差不多了
---步骤3:接收响应并处理
上面请求发出去了我们自然是要接收服务端返回的响应的
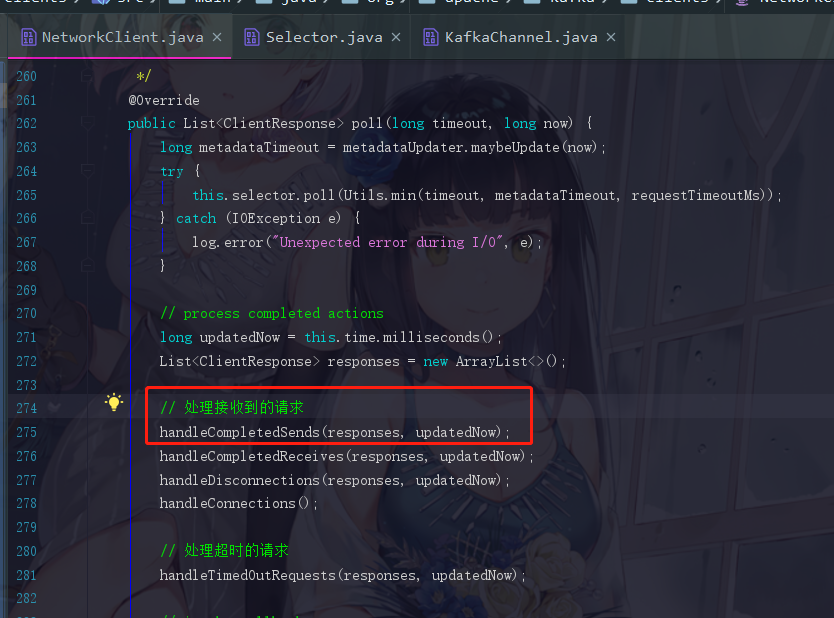
点进去handleCompletedSends
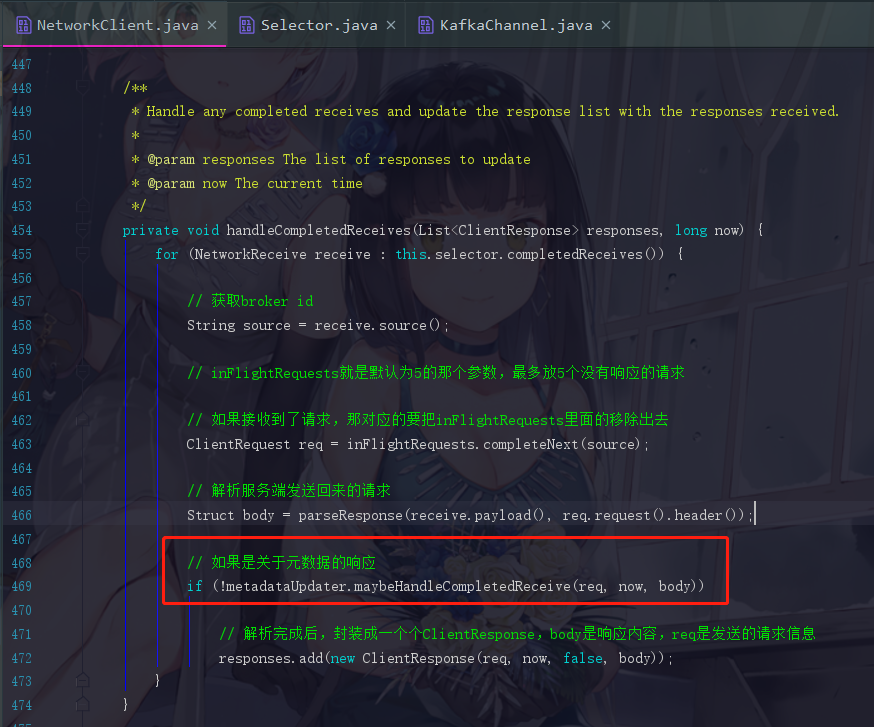
maybeHandleCompletedReceive就是处理响应的方法
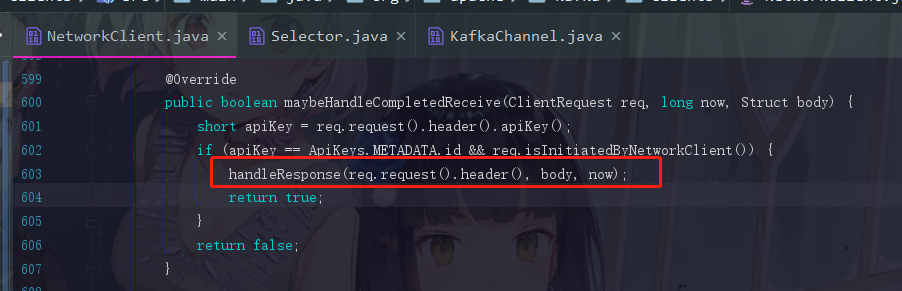
4.6.2 处理响应的逻辑及元数据获取
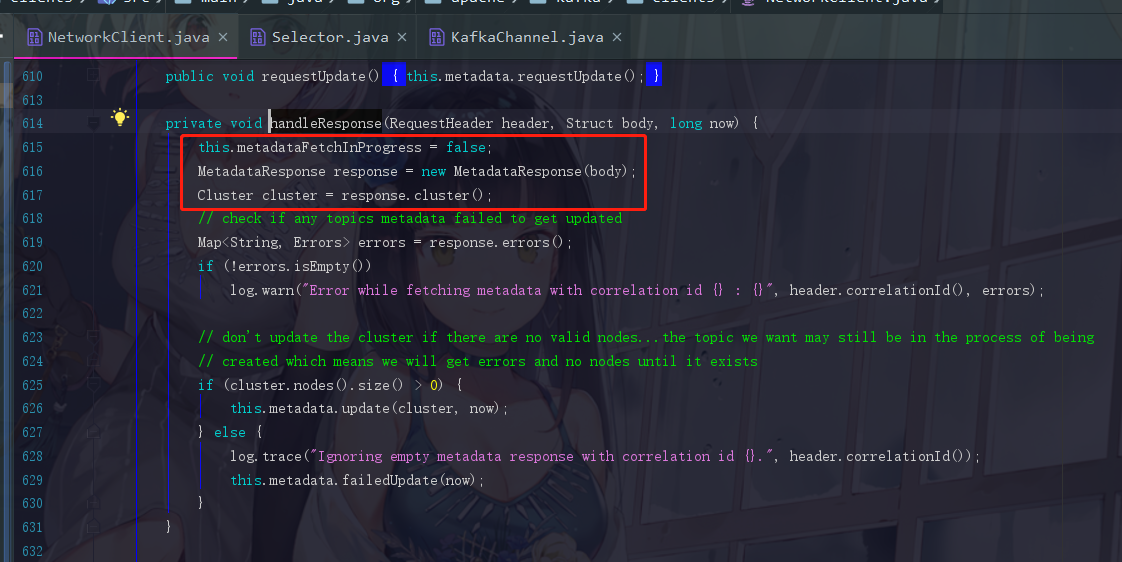
MetadataResponse response = new MetadataResponse(body);
因为服务端发送回来的也是一个二进制的数据结构,所以生产者在这里要对它进行解析,并封装成一个MetadataResponse对象
Cluster cluster = response.cluster();
响应里面会带有元数据的信息,现在进行获取cluster对象了
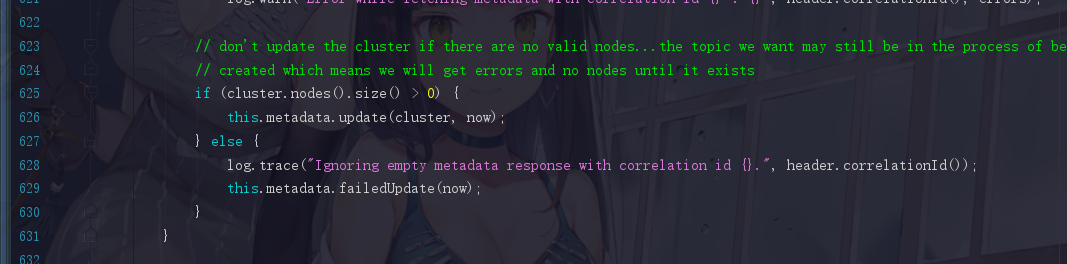
后面开始进行判断,如果cluster.nodes().size() > 0,那就已经成功获取到元数据对象了,此时update,这个方法点进去你也会看到,version=version+=1,版本号加一了。关键点是后面还会有一句notifyAll()方法,把刚刚同步等待元数据信息的线程唤醒,让代码退出while循环。
所以到此,就是一个完整的获取到元数据的过程了。
finally
真的是写到后面自己都头晕脑胀了,这种源码类型的说明起来非常吃力,跳来跳去,也是希望大家能够有所收获吧,一直到现在,我们再看看这个图
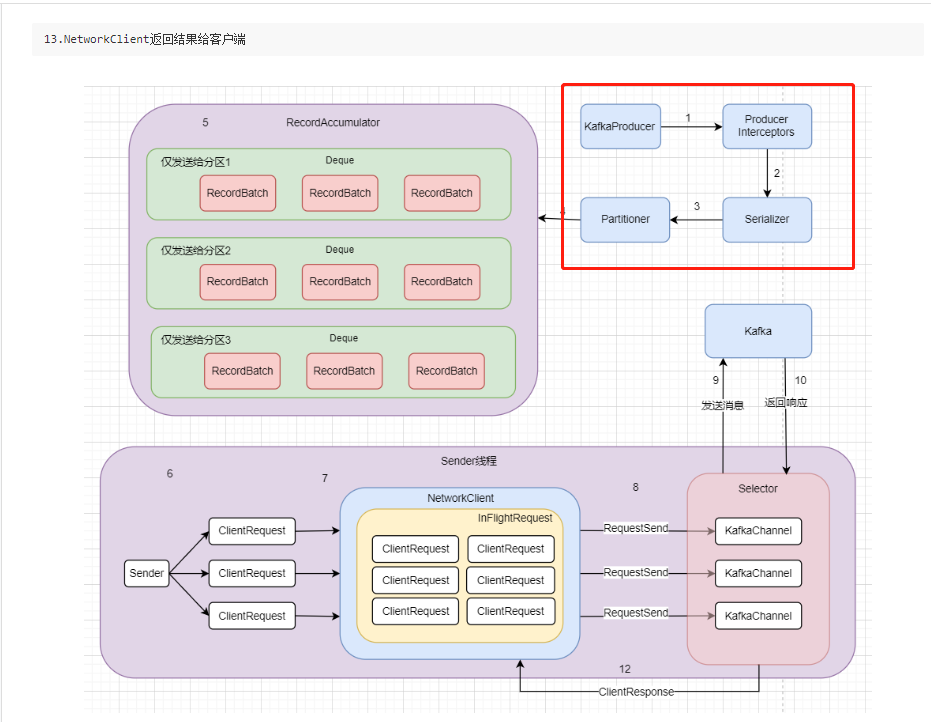
连序列化都还没展开,任重而道远啊···🤣🤣🤣
下一篇会把Kafka的网络设计给展开,感兴趣的朋友可以关注(公众号:说出你的愿望吧)一下哦,觉得文章还可以的可以点个小赞,谢谢。

