

序
接着上篇 从 简单汇编基础 到 Swift 的牛刀小试
本文来轻探一下Swift 枚举
虽不高级
但也称得上积极
待到枚举汇编后 ,犹是惊鸿初见时
MemoryLayout
既然决定了偷窥,自然要带好头盔
在 Swift3 中 MemoryLayout 就取代了 sizeof ,用来查看数据占用的内存大小
有意思的是
MemoryLayout 也是一个枚举,其中包含的 有3个类型
size、stride、alignment,返回值 都是 Int,代表 字节个数
简单使用:
let a = "string"
MemoryLayout.size(ofValue: a)
// a 的字节大小
MemoryLayout<Int>.size
// 查看某个类型的字节占用,这里Int 8个字节
-
size
- 实际需要占用字节数
-
stride
- 实际分配的字节数
- 实际分配数 stride 是 alignment 的整数倍
- 使用同上
-
alignment
- 内存对齐的字节数
- 使用同上
以 买肥宅水 为例
你只能喝半瓶,半瓶就是size,取决你胃的实际大小
老板给你拿了一瓶,这里的一瓶 就是 stride,实际出售于你
瓶是一个对齐单位,因为没法 半瓶出售,alignment 就是 一瓶
内存对齐
计算机的内存以 字节 为单位,但是读取的时候 并不以字节为 单位进行读取,就像你吃饭 不以米粒为单位
何为 内存对齐?
将内存数组单元 放在合适的位置,以计算机定义的
对齐单位为准,一般以2、4、8 的倍数 为单位
何为合适?
数据分配字节,同一个数据 分配在一个 对齐单位内,视为合适
好友 4 人出去玩,安排在同一辆车上 ,视为合适
如果 是一辆摩托车呢?
每辆能坐 2 个人,对齐单位视为 2人
如果 不坐车呢 ?
您是说步行吗 ?
:行啊,我没说不行啊,我行的很
……
为何 内存对齐?
提高系统内存的性能,如果内存读取以4个字节为读取粒度进行读取
倘若没有内存对齐,数据便可 自由分配 起始位置等
某数据占用4个字节,偏移量从1开始,则内存就要读取2次
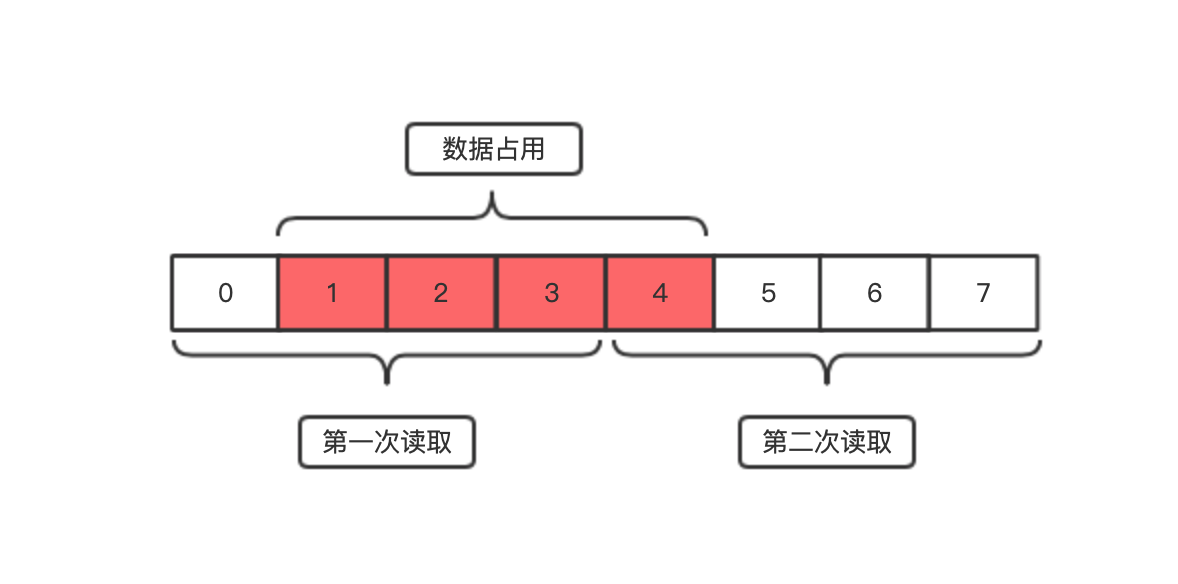
倘若数据 从 偏移量 0开始对齐,那么内存只需读取一次
作为一个 食物人
不是植物人
能一口吃完的饭,绝不分作两口
简而言之:内存对齐是一种更好的存取方式
内存虽充够,严谨点总该是好的
无类型枚举
瞥了半天,可算到了枚举
首先定义一个 没有原始值,没有关联值的枚举
enum Apple {
case mac
case pad
case phone
}
func test() {
var a = Apple.mac // 赋值 第1次
a = .pad // 赋值 第2次
a = .phone // 赋值 第3次
<!--print("需要占用: \(MemoryLayout.size(ofValue: a)) 字节")-->
<!--print("实际分配: \(MemoryLayout.stride(ofValue: a)) 字节")-->
<!--print("内存对齐: \(MemoryLayout.alignment(ofValue: a)) 字节")-->
}
-> test()
// output : 都是1个字节
实际汇编中,刚开始我建议还是把代码写在函数中,以及不要 print,可以省去很多 乱七八糟(我太菜看不懂) 的汇编代码
run, 断点打在test, 可以看到main 函数 的汇编代码
zzz`main:
0x100001420 <+0>: pushq %rbp // 压栈
0x100001421 <+1>: movq %rsp, %rbp // 栈顶rsp设置初始值,指向rbp
0x100001424 <+4>: subq $0x10, %rsp // 分配栈空间0x10 ,16个字节,栈地址向下生长,rsp向下移动
0x100001428 <+8>: movl %edi, -0x4(%rbp) // 参数,打印值edi 值为1,猜测和 分配字节数有关,望指点
0x10000142b <+11>: movq %rsi, -0x10(%rbp) // 参数,不知何义 望指点
-> 0x10000142f <+15>: callq 0x100001640 ; zzz.test() -> () at main.swift:210
0x100001434 <+20>: xorl %eax, %eax // eax 重置
0x100001436 <+22>: addq $0x10, %rsp // 回收栈空间
0x10000143a <+26>: popq %rbp // 指回上一层 rbp
0x10000143b <+27>: retq // 指向下一条命令
敲下 si 进入 test内部
zzz`test():
-> 0x100001640 <+0>: pushq %rbp
0x100001641 <+1>: movq %rsp, %rbp
0x100001644 <+4>: movb $0x0, -0x8(%rbp)
0x100001648 <+8>: movb $0x1, -0x8(%rbp)
0x10000164c <+12>: movb $0x2, -0x8(%rbp)
0x100001650 <+16>: popq %rbp
0x100001651 <+17>: retq
大概可以看到 比较重要2个信息
一. movb, b 代表一个字节,枚举值占用一个字节
二. 0 、1、2 三个数 分别赋值给同一内存空间,也就是说 mac,pad,phone 分别对应3个 数值
那我们来打印一下 a 的内存地址,查看里面装了些什么
print(UnsafeRawPointer(&a))
打印a 的内存地址 0x00007ffeefbff4d8
// 分别3次 赋值的断点记录
(lldb) x/g 0x00007ffeefbff4d8
0x7ffeefbff4d8: 0x0000000000000000
(lldb) x/g 0x00007ffeefbff4d8
0x7ffeefbff4d8: 0x0000000000000001
(lldb) x/g 0x00007ffeefbff4d8
0x7ffeefbff4d8: 0x0000000000000002
确实如我们所想
a 占用一个字节,里面装的是 0 ,1 ,2 分别代表 mac,pad,phone
总结
-
字节数
- 16进制:0x00 ~ 0xff ,表一个字节的范围也就是 0 ~ 256
-
枚举类型
无原始值、无关联值的 枚举的 占用字节 为 1
-
case 的值
- 每个 case 存储的可以 理解为它对应的
下标值,从 0 开始
- 每个 case 存储的可以 理解为它对应的
初始值枚举
写下如此,给定初始值 100
enum Apple: Int {
case mac = 100
case pad
case phone
}
同样进入 test 内部
zzz`test():
0x1000015b0 <+0>: pushq %rbp
0x1000015b1 <+1>: movq %rsp, %rbp
0x1000015b4 <+4>: movb $0x0, -0x8(%rbp)
0x1000015b8 <+8>: movb $0x1, -0x8(%rbp)
-> 0x1000015bc <+12>: movb $0x2, -0x8(%rbp)
0x1000015c4 <+20>: popq %rbp
0x1000015c5 <+21>: retq
如何 ,看着是否眼熟 ?
未曾见到 原始值 100,此汇编代码和 第一探 一模一样
由此,我们也可以暂下 结论
原始值的枚举 并未将原始值 写入内存
存入的依旧是 可以理解为下标的数值,从 0 开始
不论初始值为多少,都是从0 开始,依次累加
问题
原始值
rawValue去哪了 ?
那我们试着调用一下 rawValue 看看 它的汇编代码
var a = Apple.mac
a.rawValue
再次观察汇编
zzz`test():
0x100001540 <+0>: pushq %rbp
0x100001541 <+1>: movq %rsp, %rbp
0x100001544 <+4>: subq $0x10, %rsp
0x100001548 <+8>: movb $0x0, -0x8(%rbp)
0x10000154c <+12>: xorl %edi, %edi
0x10000154e <+14>: callq 0x100001310 ; zzz.Apple.rawValue.getter : Swift.String at <compiler-generated>
0x100001553 <+19>: movq %rdx, %rdi
我扶了扶 600° 的眼镜
默念脍炙人口的法决
三长一短选最短
三短一长选最长
下面这句 可尤其的长啊
callq0x100001310 ; zzz.Apple.rawValue.getter
这似乎是一个 方法调用
callq & getter:rawValue 的getter 方法 调用,取rawValue 的值
那么,由此可见
总结
有原始值的枚举,也是以 类似下标值的东西 存储,从 0 开始,与原始值 无关有原始值的枚举也是占用1个字节有原始值的枚举rawValue 是 以调用 getter方法取值
关联值枚举
看完前两种,接下来与 关联值枚举 会上一会
如下
enum Article {
case like(Int)
case collection(Bool)
case other
case sad
}
func test() {
var a = Article.like(20) // 步骤1
a = .collection(true) // 步骤2
a = .other // 步骤3
a = .sad // 步骤4
}
test()
/* output:
size 需要占用: 9 字节
stride 实际分配: 16 字节
alignment 内存对齐: 8 字节
/
看了以上结果
Int 占用 8 个字节, Bool 占用 1个字节,other 占用一个字节
考虑到内存空间,可以复用
如果我猜的没错
8 + 1 + 1 - 2 = 8 个字节
这点算术还要猜 ?

拿计算机算啊
结论为 9个字节
结果和我所想并不一致,考虑到自身知识浅薄,难不成
是程序 出了问题 ?
上码
打印出a 的内存地址,查看 步骤1、2、3、4 处 内存的值
因为 实际分配了 16个字节
所以就 x/2g 了,分成2份,1份 8个字节 ,足以展示全部
// 步骤1的值
(lldb) x/2g 0x00007ffeefbff4d0
0x7ffeefbff4d0: 0x0000000000000014 0x0000000000000000
// 步骤2的值
(lldb) x/2g 0x00007ffeefbff4d0
0x7ffeefbff4d0: 0x0000000000000001 0x0000000000000001
// 步骤3的值
(lldb) x/2g 0x00007ffeefbff4d0
0x7ffeefbff4d0: 0x0000000000000000 0x0000000000000002
// 步骤4的值
(lldb) x/2g 0x00007ffeefbff4d0
0x7ffeefbff4d0: 0x0000000000000001 0x0000000000000002
根据打印,做一下归纳
| 位置 | 前 8个 字节 | 后 8个 字节 |
|---|---|---|
| .like(20) | 关联值 20 | 0 |
| .collection(true) | 1 | 1 |
| .other | 0 | 2 |
| .sad | 1 | 2 |
分析
后 8 个字节
单看 .other 和 .sad , 前 8个字节依次为 0 和 1,后 8个字节都是 2
这个 2 是共同之处
再 回头看 这 2个 case,是否类型一致 ?
我们可以把
2定为 它们的 共有 类型吗 ?
结合 .like 的 0 和 .collection 的 1,好像确是如此
遂:
后8个字节 表 类型,区分 Bool,Int,以及无类型
前 8个字节
| 类型 | 前 8个字节 |
|---|---|
| Int | Int 值 |
| Bool | 1表 true;0表 false |
| 无类型 | 依次累加,与 一探 相符 |
若此时再 结合汇编代码
0x100001794 <+4>: movq $0x14, -0x10(%rbp)
0x10000179c <+12>: movb $0x0, -0x8(%rbp)
-> 0x1000017a0 <+16>: movq $0x1, -0x10(%rbp)
0x1000017a8 <+24>: movb $0x1, -0x8(%rbp)
0x1000017ac <+28>: movq $0x0, -0x10(%rbp)
0x1000017b4 <+36>: movb $0x2, -0x8(%rbp)
0x1000017b8 <+40>: movq $0x1, -0x10(%rbp)
0x1000017c0 <+48>: movb $0x2, -0x8(%rbp)
-0x10(%rbp) 这8个字节 分别 赋值 : 20、1、0、1 ,表示 值
与前面分析一致
-0x8(%rbp) 这8个字节 分别赋值 :0、1、2、2 ,表示 类型
同一致
这个结果
阁下是否豁然开朗 ?
说不完枚举
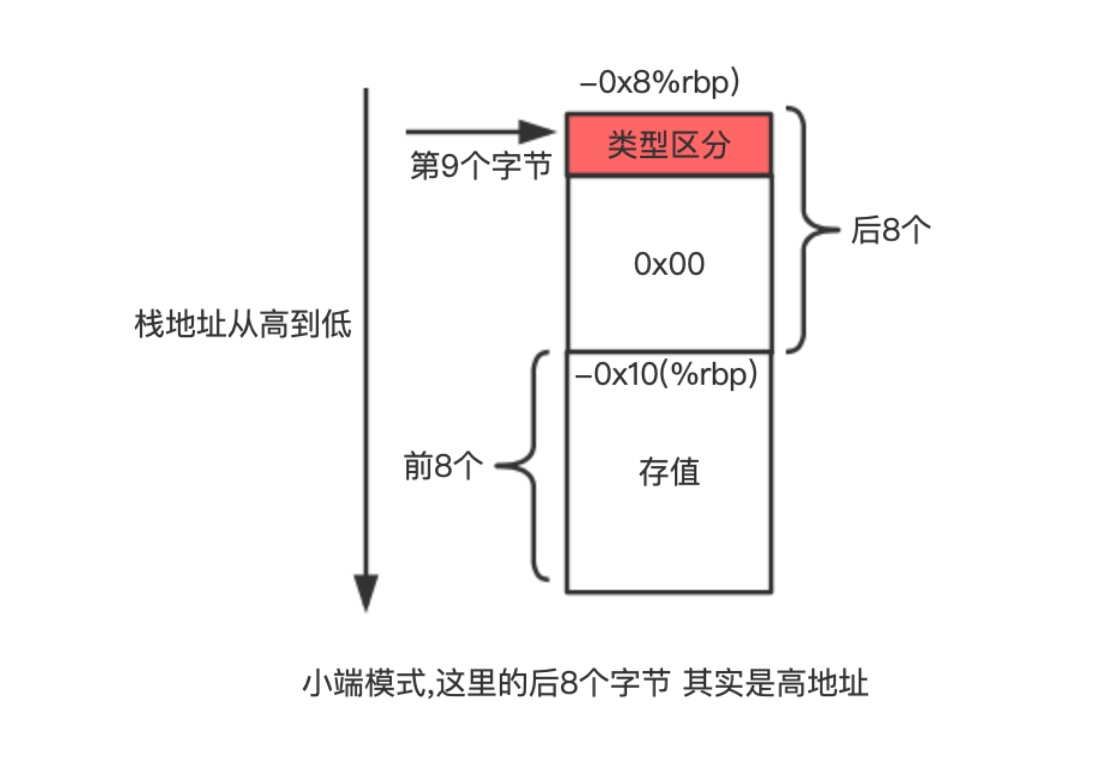
第 9 个字节
一直在说 后8个字节,其实我们只需要看第9个字节
如下第9个字节为 0x01
(lldb) x/16b 0x00007ffeefbff4d0
0x7ffeefbff4d0: 0x01 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x7ffeefbff4d8: 0x01 0x00 0x00 0x00 0x00 0x00 0x00 0x00
第 9 个字节 便为 类型区分字节
针对关联值 本例:
总结
-
关联值 枚举 (仅限本文类型 ,不包含 关联类型 是
类 和 结构体 及其它)最大类型 字节数之和 额外 + 1- 如Int 型
- case like(Int, Int) ,如果有2个 Int 就是 16 + 1
- 最后一个字节 存放
case 类型
-
非关联值
- 内存 占用 1个字节
- 内存中 以下标数 为值,依次累加
粗鄙之言 ,还望体谅
如若有误 ,还请指出
~
补充 (12.16)
至于 @李坤 在评论区 提出的问题,他也有所解答,在此表示感谢
想深入了解的同学 可以先看看 李同学的文章
至于枚举类型是 结构体 或者 类 等,笔者尚未接触到
关联值的类型有很多,这次我没有说完,等笔者接触到,就回来再一一枚举出来
补充,修正
感谢~
