这一系列主要是美团18年一年的大数据相关的文章分享,倒序。 从中可以看到美团的实时数据系统架构从Storm到Flink的转变和选择。
美团点评基于 Flink 的实时数仓建设实践
source: tech.meituan.com/2018/10/18/…
关键词
实时数仓,Flink, Spark-Streaming, Storm
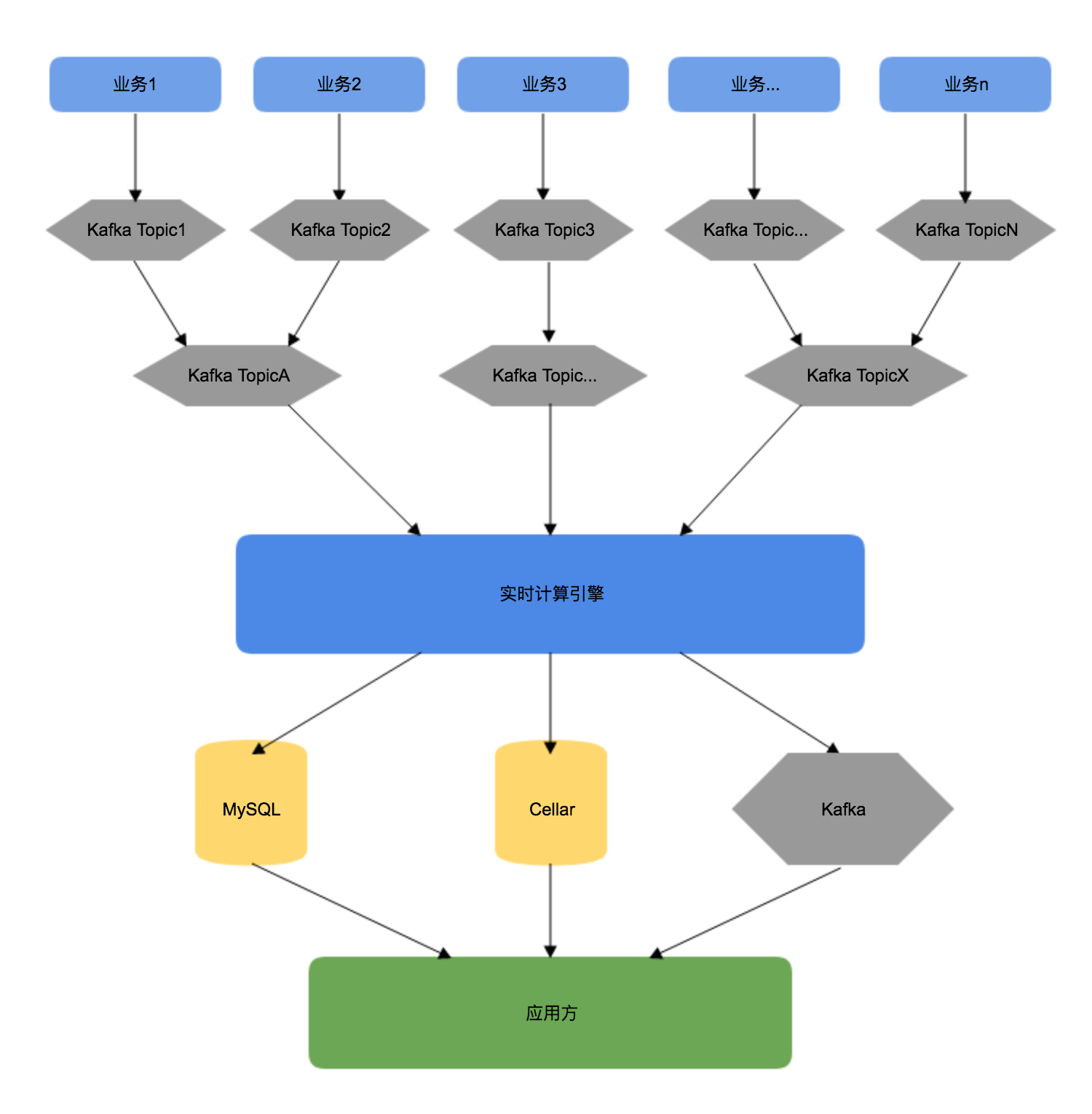
初期架构
问题
- 数据指标越来越多,“烟囱式”的开发导致代码耦合问题严重。
- 需求越来越多,有的需要明细数据,有的需要 OLAP 分析。单一的开发模式难以应付多种需求。
- 缺少完善的监控系统,无法在对业务产生影响之前发现并修复问题。
新架构
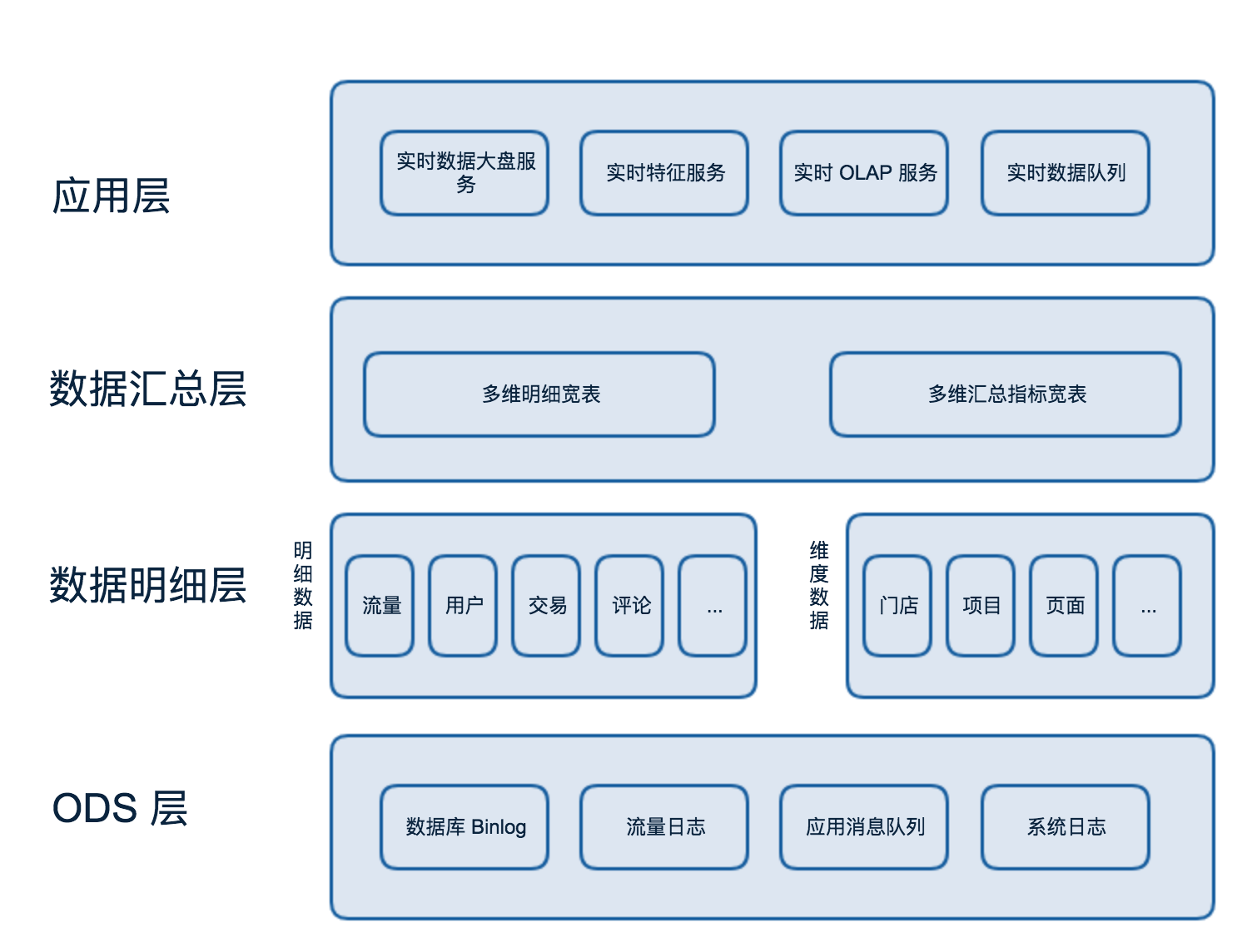
技术选型
存储引擎
| 方案 | 优势 | 劣势 |
|---|---|---|
| MySQL | 1. 具有完备的事务功能,可以对数据进行更新。2. 支持 SQL,开发成本低。 | 1. 横向扩展成本大,存储容易成为瓶颈; 2. 实时数据的更新和查询频率都很高,线上单个实时应用请求就有 1000+ QPS;使用 MySQL 成本太高。 |
| Elasticsearch | 1. 吞吐量大,单个机器可以支持 2500+ QPS,并且集群可以快速横向扩展。2. Term 查询时响应速度很快,单个机器在 2000+ QPS时,查询延迟在 20 ms以内。 | 1. 没有原生的 SQL 支持,查询 DSL 有一定的学习门槛;2. 进行聚合运算时性能下降明显。 |
| Druid | 1. 支持超大数据量,通过 Kafka 获取实时数据时,单个作业可支持 6W+ QPS;2. 可以在数据导入时通过预计算对数据进行汇总,减少的数据存储。提高了实际处理数据的效率;3. 有很多开源 OLAP 分析框架。实现如 Superset。 | 1. 预聚合导致无法支持明细的查询;2. 无法支持 Join 操作;3. Append-only 不支持数据的修改。只能以 Segment 为单位进行替换。 |
| Cellar | 1. 支持超大数据量,采用内存加分布式存储的架构,存储性价比很高;2. 吞吐性能好,经测试处理 3W+ QPS 读写请求时,平均延迟在 1ms左右;通过异步读写线上最高支持 10W+ QPS。 | 1. 接口仅支持 KV,Map,List 以及原子加减等;2. 单个 Key 值不得超过 1KB ,而 Value 的值超过 100KB 时则性能下降明显。 |
实时计算引擎
| 项目/引擎 | Storm | Flink | spark-streaming |
|---|---|---|---|
| API | 灵活的底层 API 和具有事务保证的 Trident API | 流 API 和更加适合数据开发的 Table API 和 Flink SQL 支持 | 流 API 和 Structured-Streaming API 同时也可以使用更适合数据开发的 Spark SQL |
| 容错机制 | ACK 机制 | State 分布式快照保存点 | RDD 保存点 |
| 状态管理 | Trident State状态管理 | Key State 和 Operator State两种 State 可以使用,支持多种持久化方案 | 有 UpdateStateByKey 等 API 进行带状态的变更,支持多种持久化方案 |
| 处理模式 | 单条流式处理 | 单条流式处理 | Mic batch处理 |
| 延迟 | 毫秒级 | 毫秒级 | 秒级 |
| 语义保障 | At Least Once,Exactly Once | Exactly Once,At Least Once | At Least Once |
实时数据产品实践——美团大交通战场沙盘
source: tech.meituan.com/2018/05/24/…
关键词
Storm,实时数据
问题
- 实时仓库建设不足,维度及指标不够丰富,无法快速满足不同业务需求。
- 实时数据和离线数据对比不灵活,无法自动化新增对比基期数据,且对比数据无法预先生产。
- 数据监控不及时,一旦数据出现问题而无法及时监控到,就会影响业务分析决策。
建设中的挑战
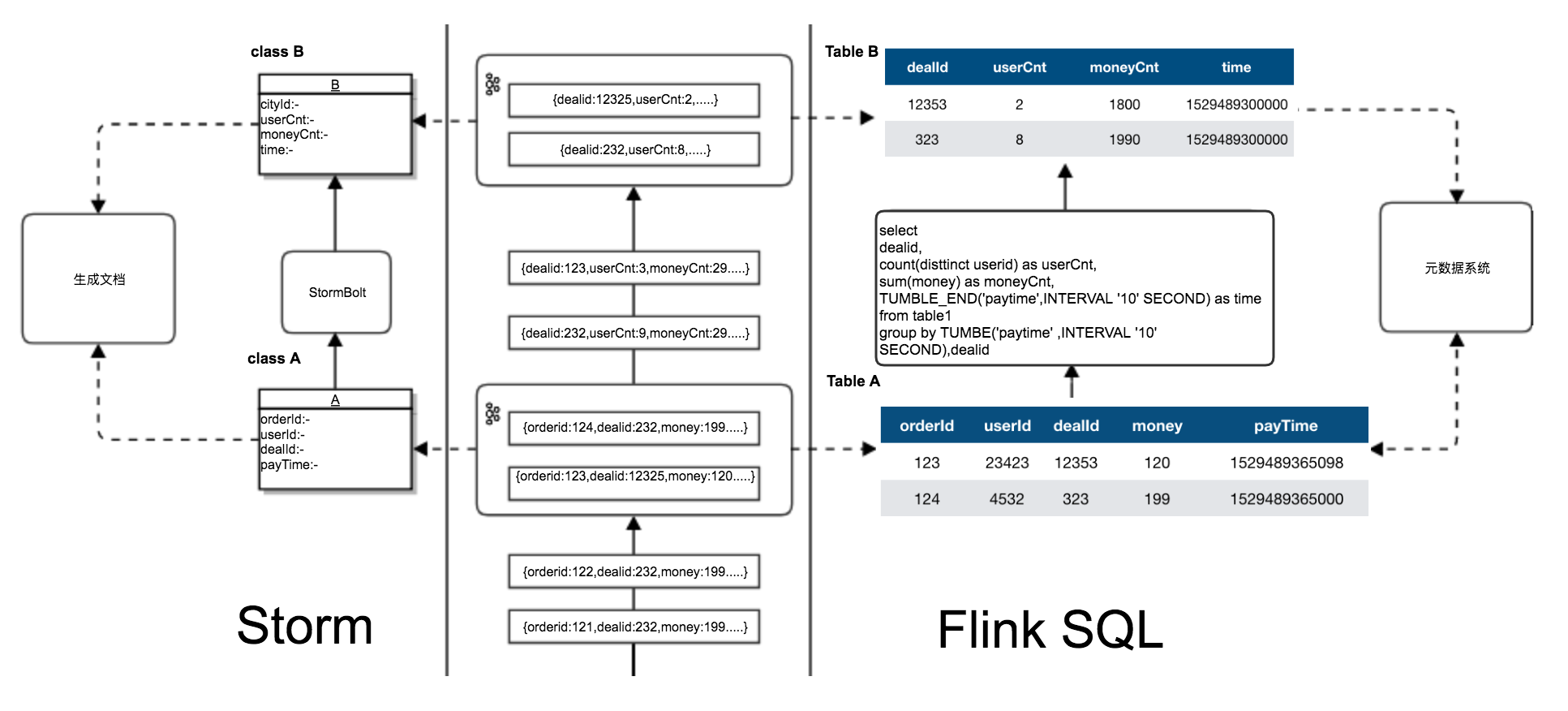
- 如何在保证数据准确性的前提下实现多实时流关联;实时流出现延迟、乱序、重复时如何解决。
- 流式计算中通常需要将多个实时流按某些主键进行关联得到特定的实时数据,但不同于离线数据表关联,实时流的到达是一个增量的过程,无法获取实时流的全量数据,并且实时流的达到次序无法确定,因此在进行关联时需要考虑存储一些中间状态及下发策略问题。
- 实时流可复用性,实时流的处理不能只为解决一个问题,而是一类甚至几类问题,需要从业务角度对数据进行抽象,分层建设,以快速满足不同场景下对数据的要求。
- 中台服务如何保证查询性能、数据预警及数据安全。
- 实时数据指标维度较为丰富,多维度聚合查询场景对服务层的性能要求较高,需要服务层能够支持较快的计算能力和响应能力;同时数据出现问题后,需要做好及时监控并快速修复。
- 如何保证产品应用需求个性化。
- 实时数据与离线数据对比不灵活,需要提供可配置方案,并能够及时生产离线数据。
总体解决方案

数据架构

实时处理流程

中台服务-性能相应优化
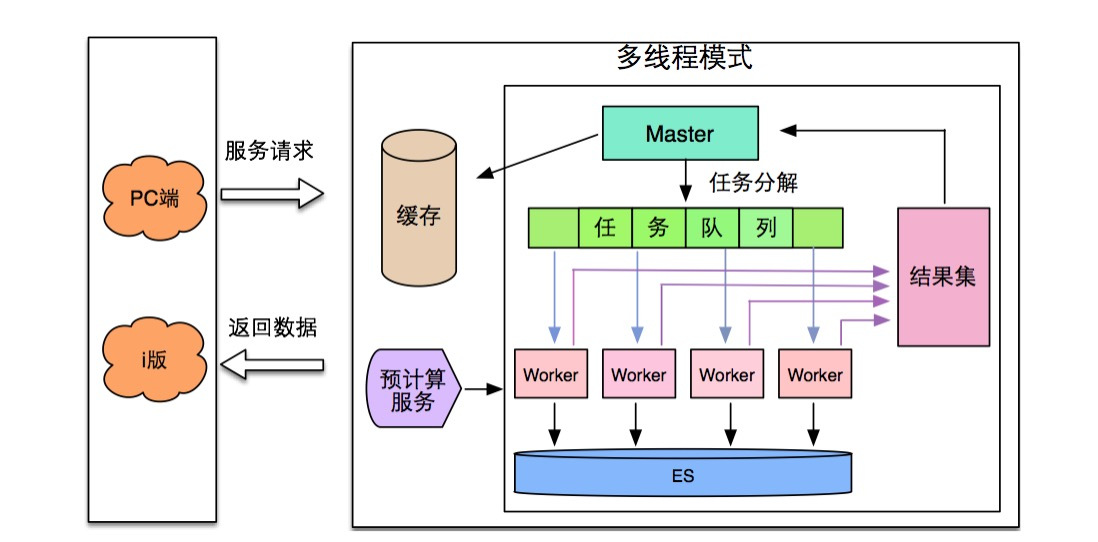
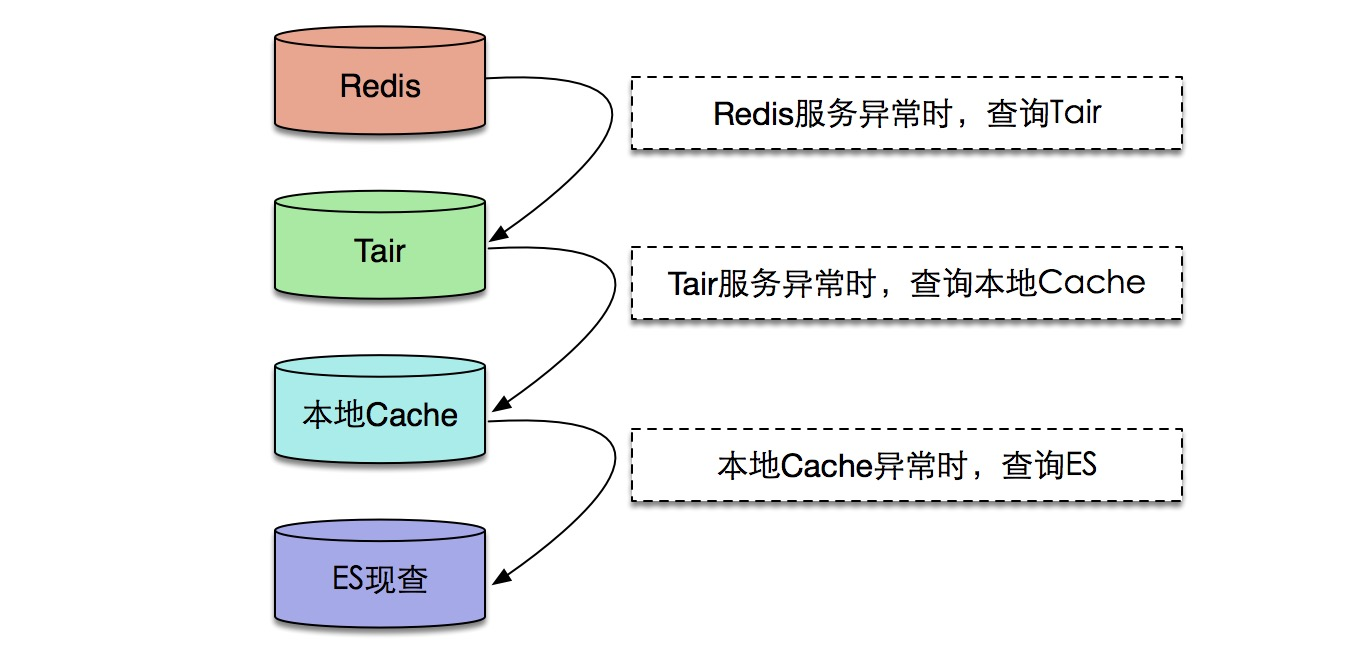
中台服务-数据降级方案
美团点评运营数据产品化应用与实践
source: tech.meituan.com/2018/02/11/…
问题
- 取数门槛高,找不到切合的数据,口径复杂不易计算,对运营人员有一定的技能要求,人力成本增大;
- 数据处理非常耗时,缺少底层离线数仓模型建设和预计算*支撑,Ad-hoc平台查询缓慢;
- 数据不一致,不同渠道口径不一致,缺少对杂乱指标的统一管理;
- 数据反馈形式不友好,缺少数据可视化的形式,无法呈现趋势,继而影响业务人员对多维、降维、对比等情况的进一步分析操作。
方案及整体架构
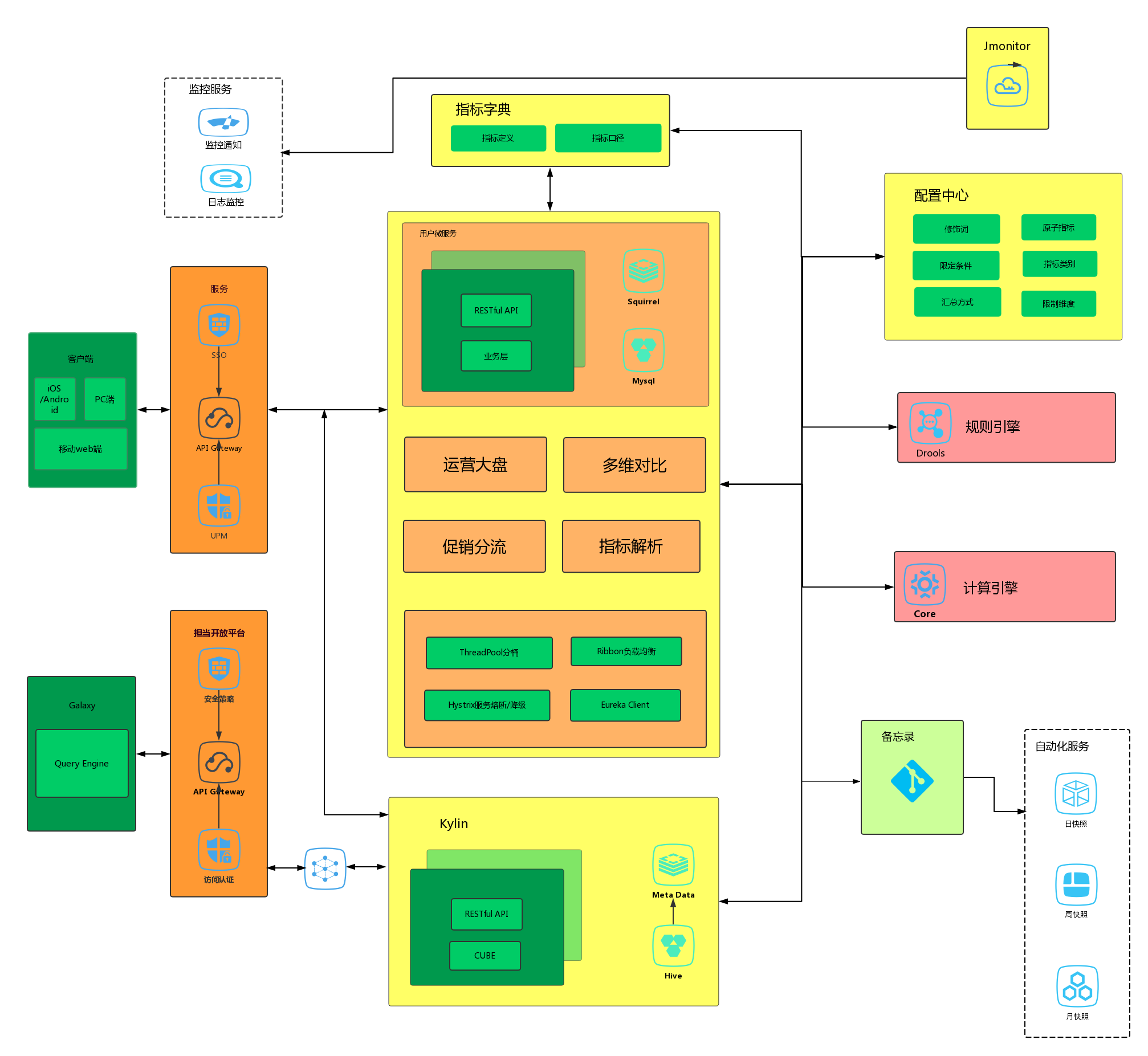
首先,构建了一个针对境内旅游运营侧全域的公共底层数据,将不同平台促销系统的数据按业务整合到一起,同时划分不同活动主题,按事件再向上聚合,做专题的数据支撑,统一数据出口。然后通过多维预计算引擎对事实数据进行预计算,构建数仓与应用的管道,从而节省计算成本,并且提升了数据互通和消费的效率,最后建设统一的数据服务中台,搭配不同端的Web应用。通过丰富的可视化效果,及多样的分析对比操作,快速、全面地支撑运营业务。
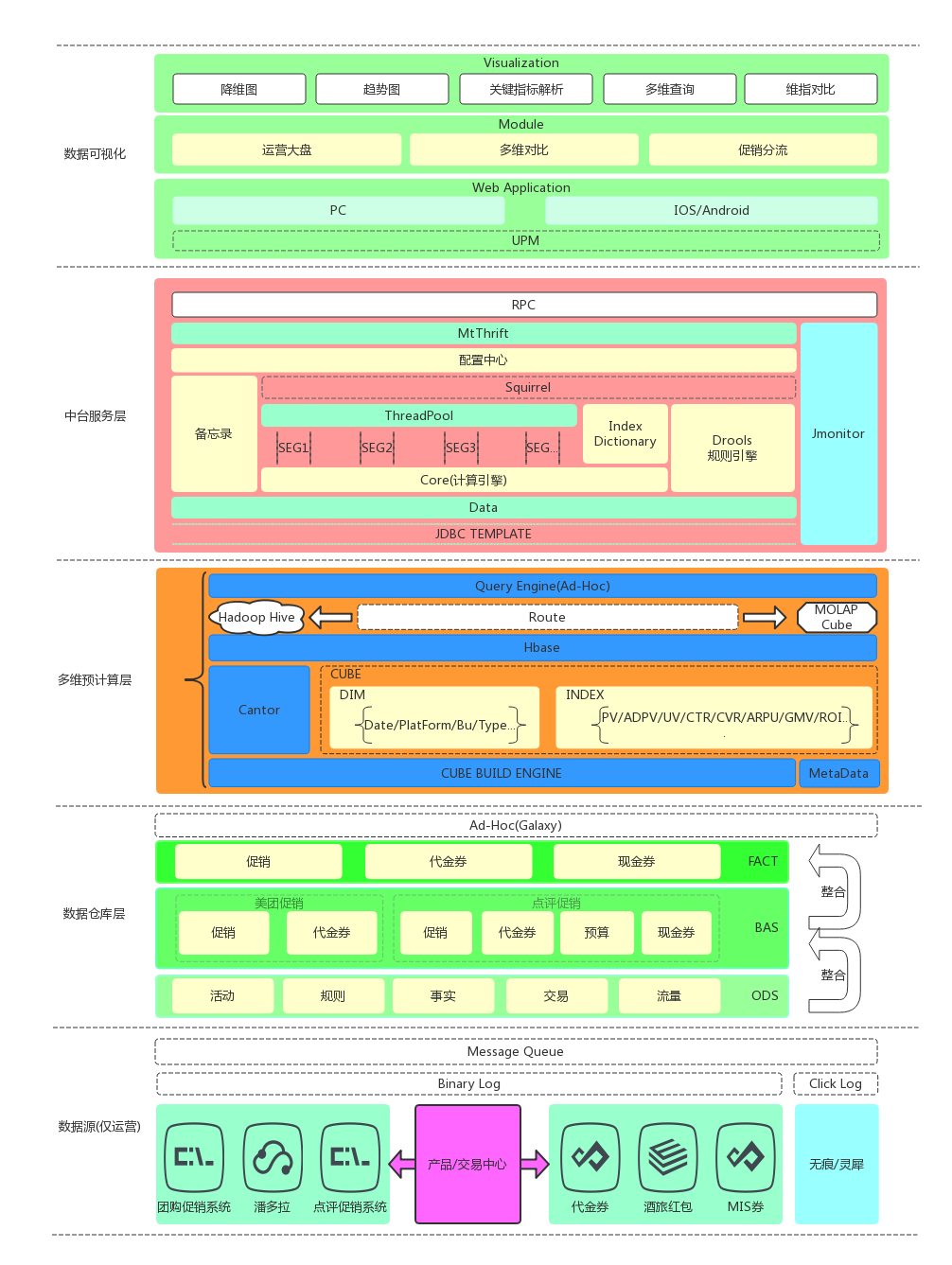
数仓架构

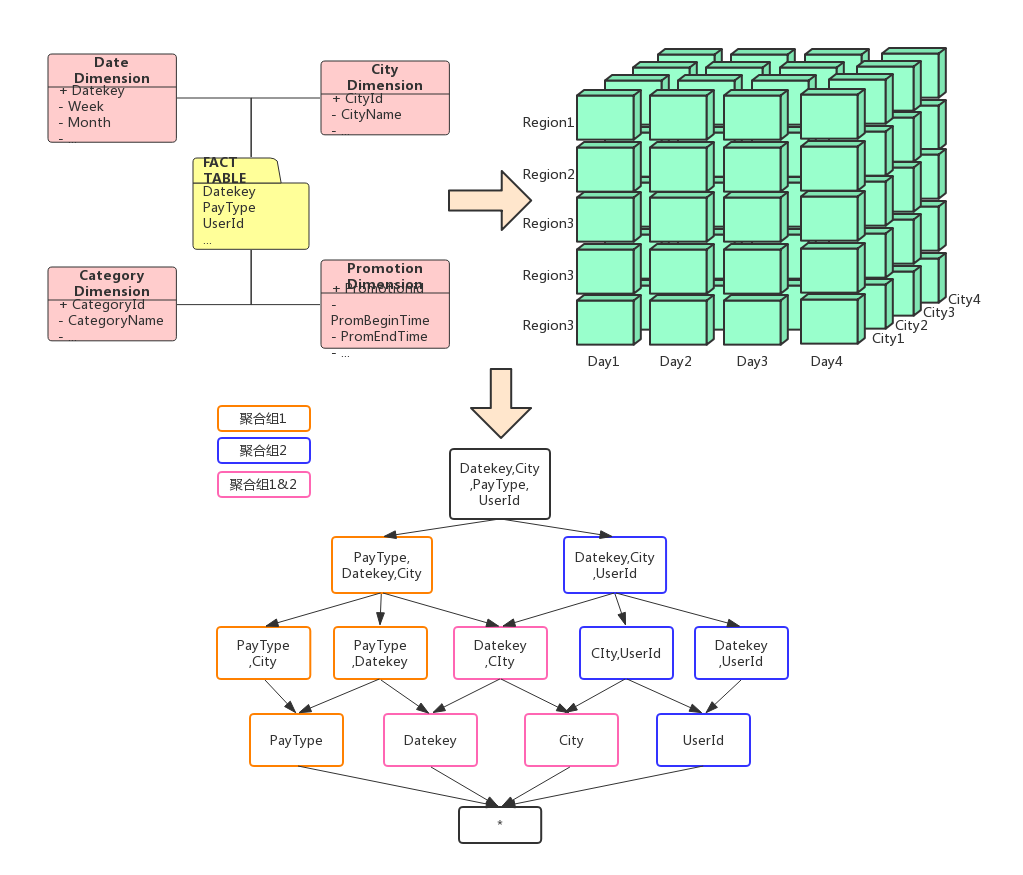
多维预计算层
预计算层是连接数据和应用之间的管道,是应用层垂直模块的专项支持。它是在Fact层数据之上的预聚合,强依赖于数仓模型中事实和维度的构建以及预关联。预计算采用Kylin引擎构建Cube聚合组,来解决取数门槛和数据处理耗时等问题,同是提供多维分析的能力,不但提供了新的Ad-Hoc(Query Engine)平台,在提高查询响应的同时,又能为产品带来更流畅的交互,增强用户体验。例如:创建一个交易数据cube,它包含日期(datakey)、用户(userid)、付款方式(paytype)、购买城市(city)。为满足不同消费方式在不同城市的应用情况和查看用户在不同城市的消费行为,建立以下两个聚合组,包含的维度和方式如图所示:
中台服务层
数据可视化
基于echarts做开发,完成趋势对比,降维操作,指标对比,多维查询等。
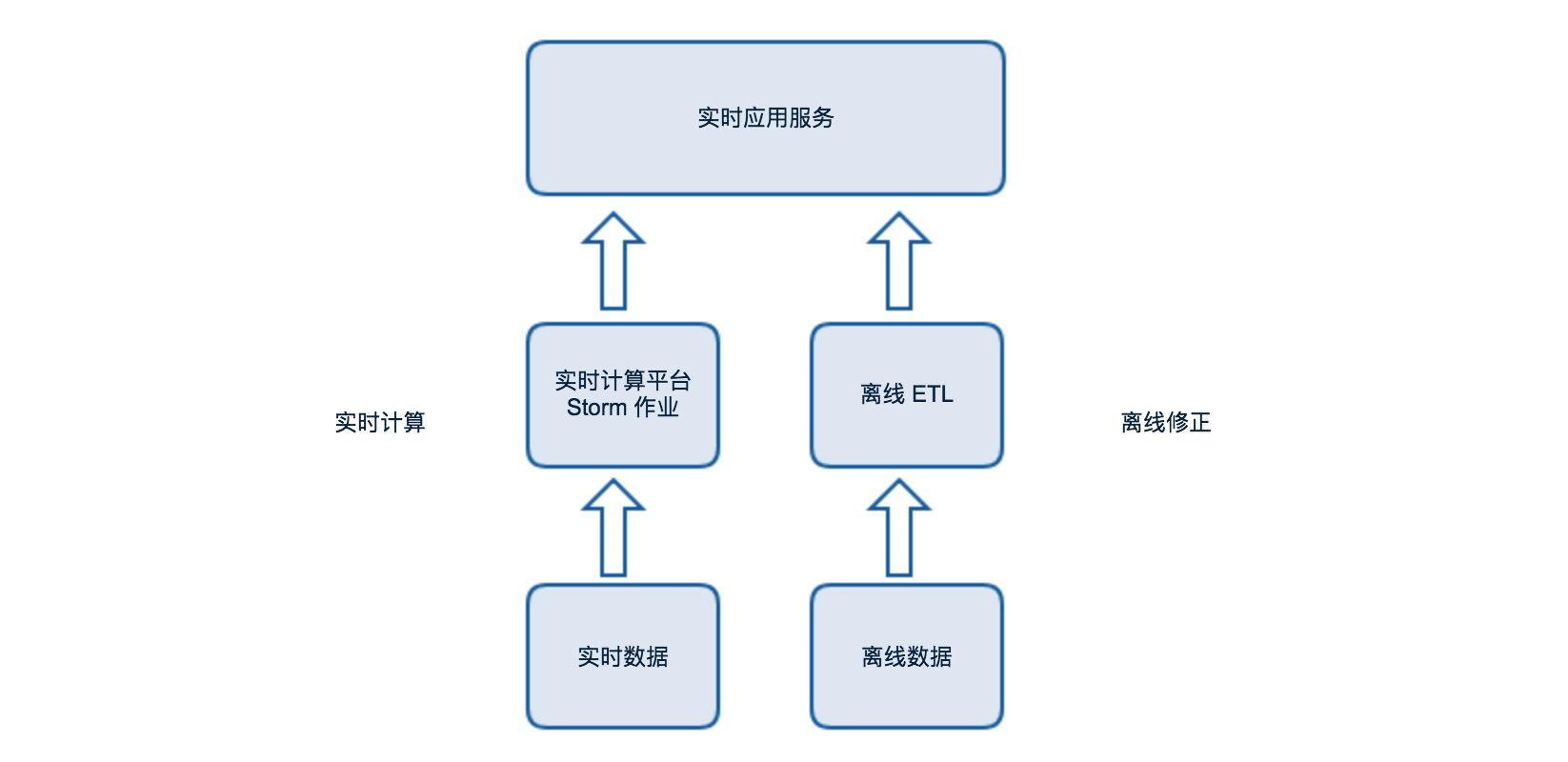
美团点评基于Storm的实时数据处理实践
source: tech.meituan.com/2018/01/26/…
问题
- 数据量的不稳定性,导致对机器需求的不确定性。用户的行为数据会受到时间的影响,比如半夜时刻和用餐高峰时段每分钟产生的数据量有两个数量级的差异。
- 上游数据质量的不确定性。
- 数据计算时,数据的落地点应该放到哪里来保证计算的高效性。
- 如何保证数据在多线程处理时数据计算的正确性。
- 计算好的数据以什么样的方式提供给应用方。
设计框架
还是比较了Storm, Flink和Spark Streaming,最终选择了Storm