

前言
提醒一下,这里面需要有RPC的基础,如果对RPC没有了解的朋友,可以先跳转到以往写的两篇RPC文章中。
理论方面:从零开始的高并发(七)--- RPC的介绍,协议及框架
(可略过)代码方面:从零开始的高并发(八)--- RPC框架的简单实现
当然也不需要太过深入,知道点皮毛即可。因为Hadoop中有一个Hadoop RPC需要有点基础知识。
暂时先记得下面的满足RPC的条件(非完整):
1.不同进程间的方法调用
2.RPC分为服务端和客户端,客户端调用服务端的方法,方法的执行是在服务端
3.协议说得直白点就是一个接口,但是这个接口必须存在versionID
4.协议里面会存在抽象方法,这些抽象方法交由服务端实现
好的那我们开始
一、NameNode的启动流程解析
我们的第一个任务,就是来验证NameNode是不是一个RPC的服务端
1.1 第一步:找到NameNode的main方法
现在我们来到Hadoop2.7.0的源码,先打开NameNode.java的代码,找到它的main方法
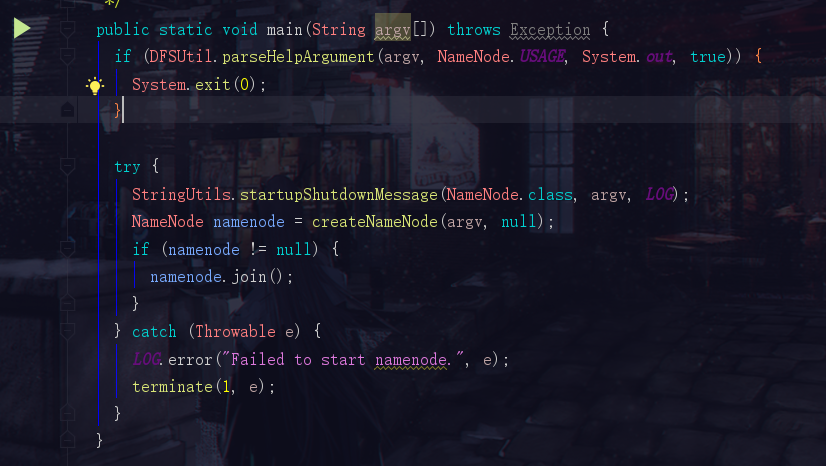
为了方便大家观看,我再标好一些注释
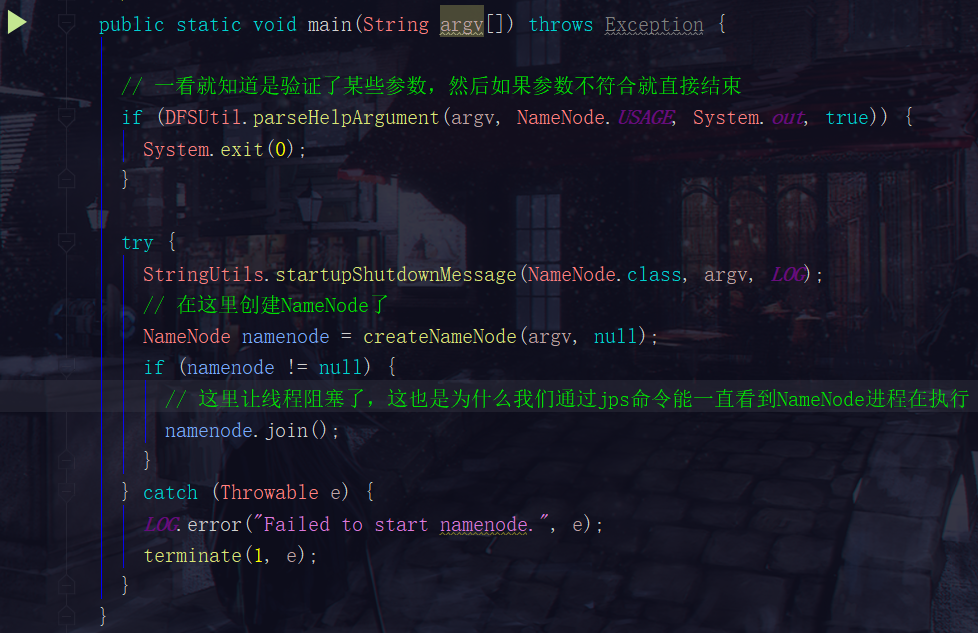
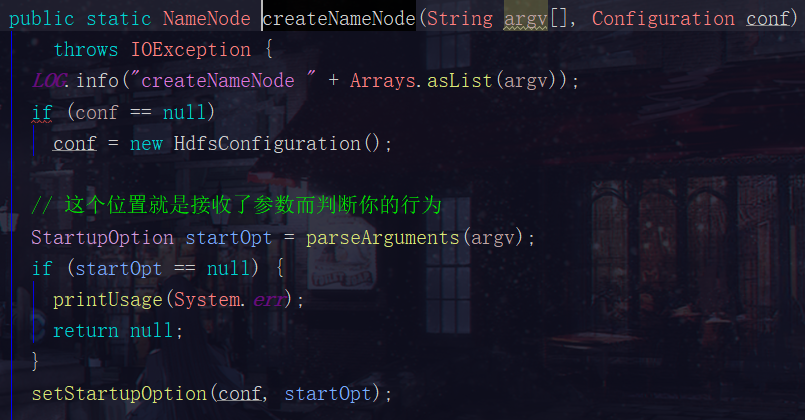
1.2 第二步:点开创建NameNode的createNameNode方法
这个createNameNode方法我们分成两部分看
第一部分:传参的部分
我们操作HDFS集群时,会通过如下一些命令
hdfs namenode -format
hadoop=daemon.sh start namanode
第二部分:switch部分
代码过长没法截图,直接复制下来
switch (startOpt) {
case FORMAT: {
boolean aborted = format(conf, startOpt.getForceFormat(),
startOpt.getInteractiveFormat());
terminate(aborted ? 1 : 0);
return null; // avoid javac warning
}
case GENCLUSTERID: {
System.err.println("Generating new cluster id:");
System.out.println(NNStorage.newClusterID());
terminate(0);
return null;
}
case FINALIZE: {
System.err.println("Use of the argument '" + StartupOption.FINALIZE +
"' is no longer supported. To finalize an upgrade, start the NN " +
" and then run `hdfs dfsadmin -finalizeUpgrade'");
terminate(1);
return null; // avoid javac warning
}
case ROLLBACK: {
boolean aborted = doRollback(conf, true);
terminate(aborted ? 1 : 0);
return null; // avoid warning
}
case BOOTSTRAPSTANDBY: {
String toolArgs[] = Arrays.copyOfRange(argv, 1, argv.length);
int rc = BootstrapStandby.run(toolArgs, conf);
terminate(rc);
return null; // avoid warning
}
case INITIALIZESHAREDEDITS: {
boolean aborted = initializeSharedEdits(conf,
startOpt.getForceFormat(),
startOpt.getInteractiveFormat());
terminate(aborted ? 1 : 0);
return null; // avoid warning
}
case BACKUP:
case CHECKPOINT: {
NamenodeRole role = startOpt.toNodeRole();
DefaultMetricsSystem.initialize(role.toString().replace(" ", ""));
return new BackupNode(conf, role);
}
case RECOVER: {
NameNode.doRecovery(startOpt, conf);
return null;
}
case METADATAVERSION: {
printMetadataVersion(conf);
terminate(0);
return null; // avoid javac warning
}
case UPGRADEONLY: {
DefaultMetricsSystem.initialize("NameNode");
new NameNode(conf);
terminate(0);
return null;
}
default: {
DefaultMetricsSystem.initialize("NameNode");
return new NameNode(conf);
}
比如第一小段是hdfs namenode -format,它是一个format
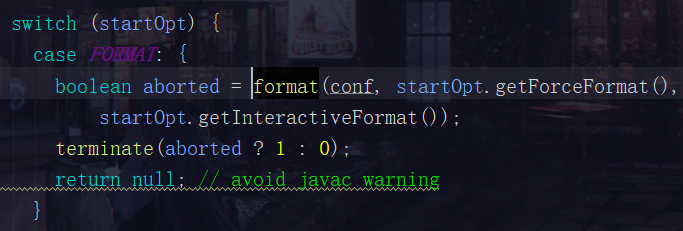
自然走的就是这个分支啦。
但是现在我比如输入的是start 也就是第二小段hadoop=daemon.sh start namanode,因为其他的都不满足,所以走的就是最后一个分支
再点进去这个new NameNode(conf)
1.3 NameNode的初始化

点进去this方法,其实就是下面的那个
前面的一大截也不需要看,无非就是一些参数的传递问题,看这个try里面的,有一个initialize,这个单词的中文是初始化,那我们就再继续点进去
1.4 初始化的具体步骤
1.4.1 HttpServer
前面的是判断了一些奇奇怪怪的条件的暂时先不管,直接看到我们比较敏感的位置
此时我们看见创建HttpServer的代码了,我们如果是初次搭建我们的大数据集群时,是不是会访问一个50070的web页面,比如
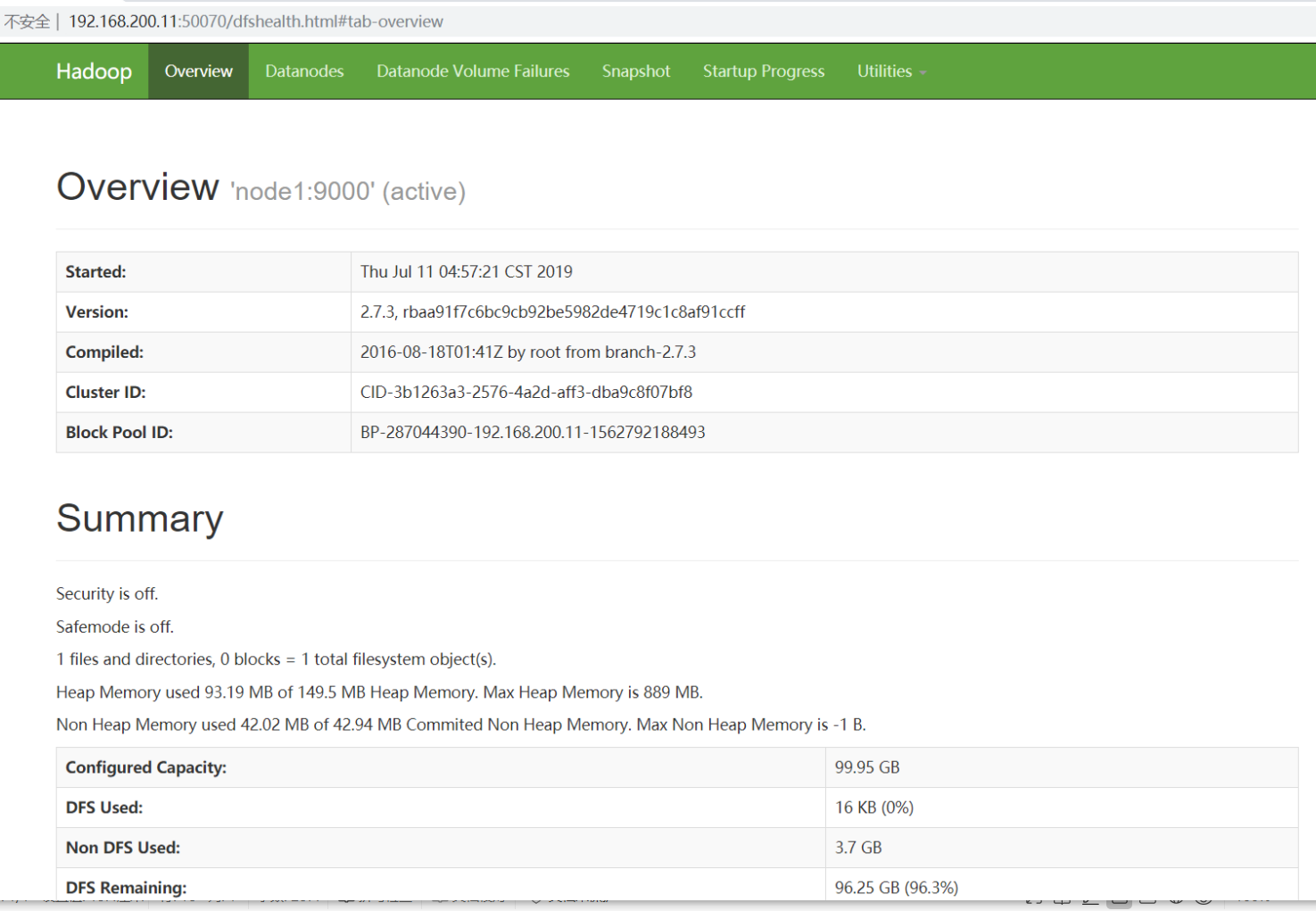
这里虽然不是啥重要的流程,不过顺便解释一下50070怎么来的
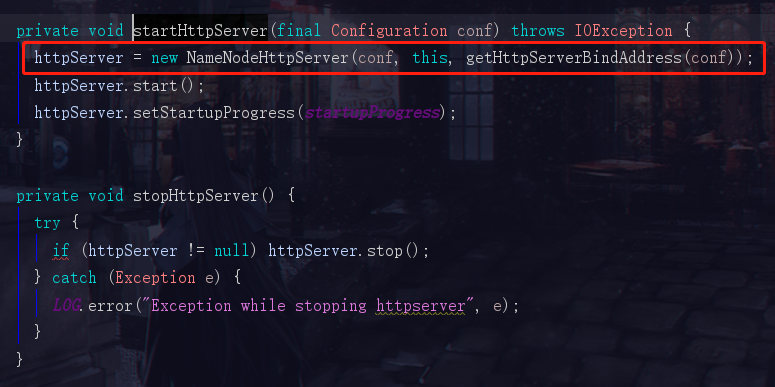
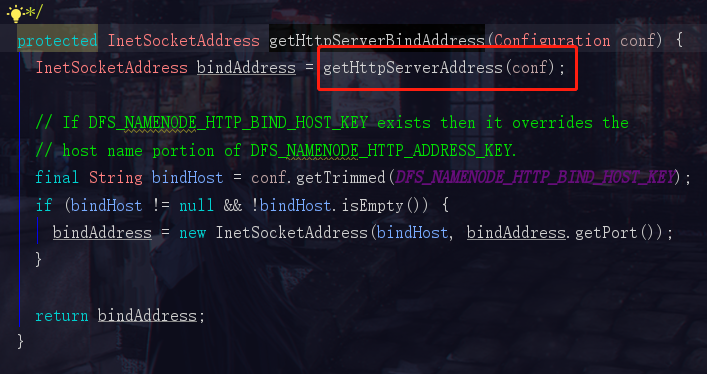
然后我们看到了这两个参数,DFS_NAMENODE_HTTP_ADDRESS_KEY 和 DFS_NAMENODE_HTTP_ADDRESS_DEFAULT
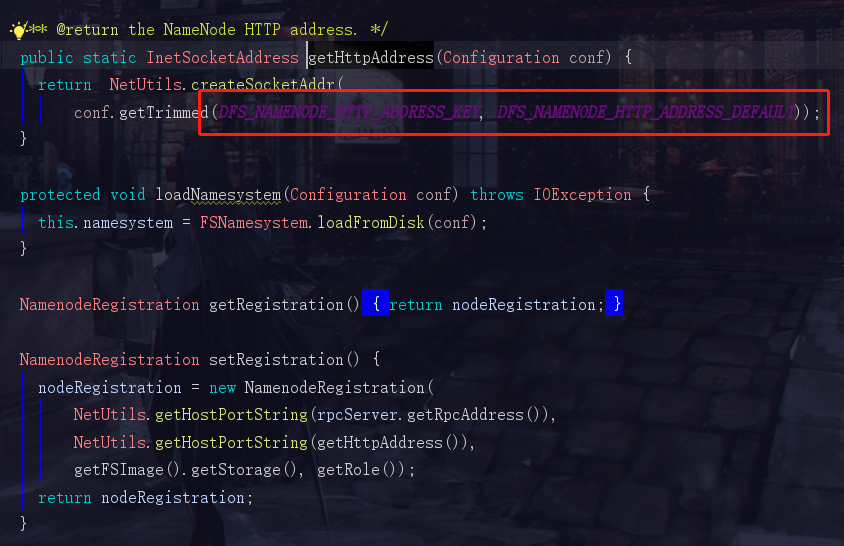
DFS_NAMENODE_HTTP_ADDRESS_KEY是自己手动配置的地址,但是一般我们都没有去手动配置,所以hadoop会使用一个默认的地址 DFS_NAMENODE_HTTP_ADDRESS_DEFAULT

看到这里,就知道我们当时访问那个网站为啥是本机ip加一个50070了吧。
1.4.2 对HttpServer2进行增强的servlet
此时我们回到第一张图,也就是第二句就是start的那张startHttpServer方法,点进去start方法看看
我们往下看,作为一名Java Developer,我们的关注点自然就是我们熟悉的servlet了
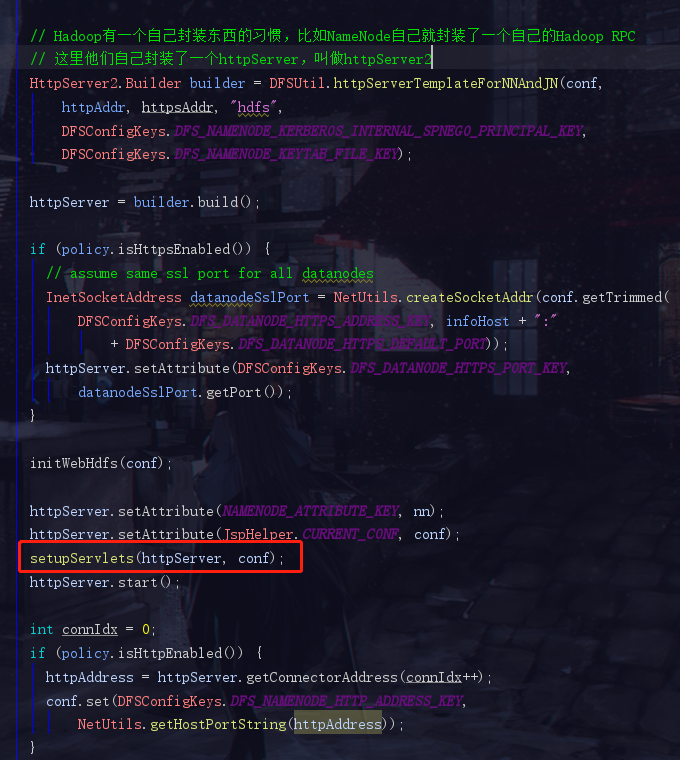
setupServlets(httpServer, conf);
这里绑定了一堆的servlet,绑的越多功能越强,我们再点进去
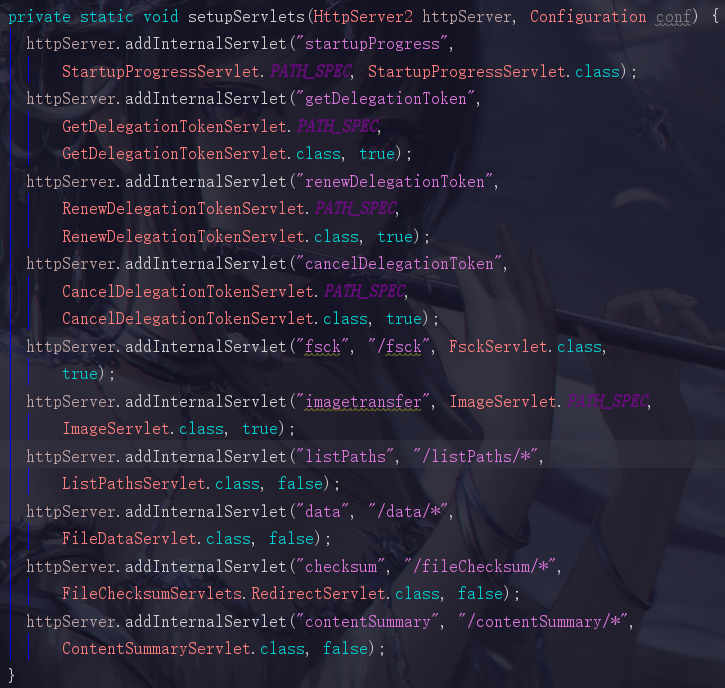
可以看到就是疯狂地add一些各式各样的servlet,我们姑且先不看,其实servlet大家应该非常熟悉,点进去先啥都别想直接跳doGet()方法就能看到它们都分别做了什么了
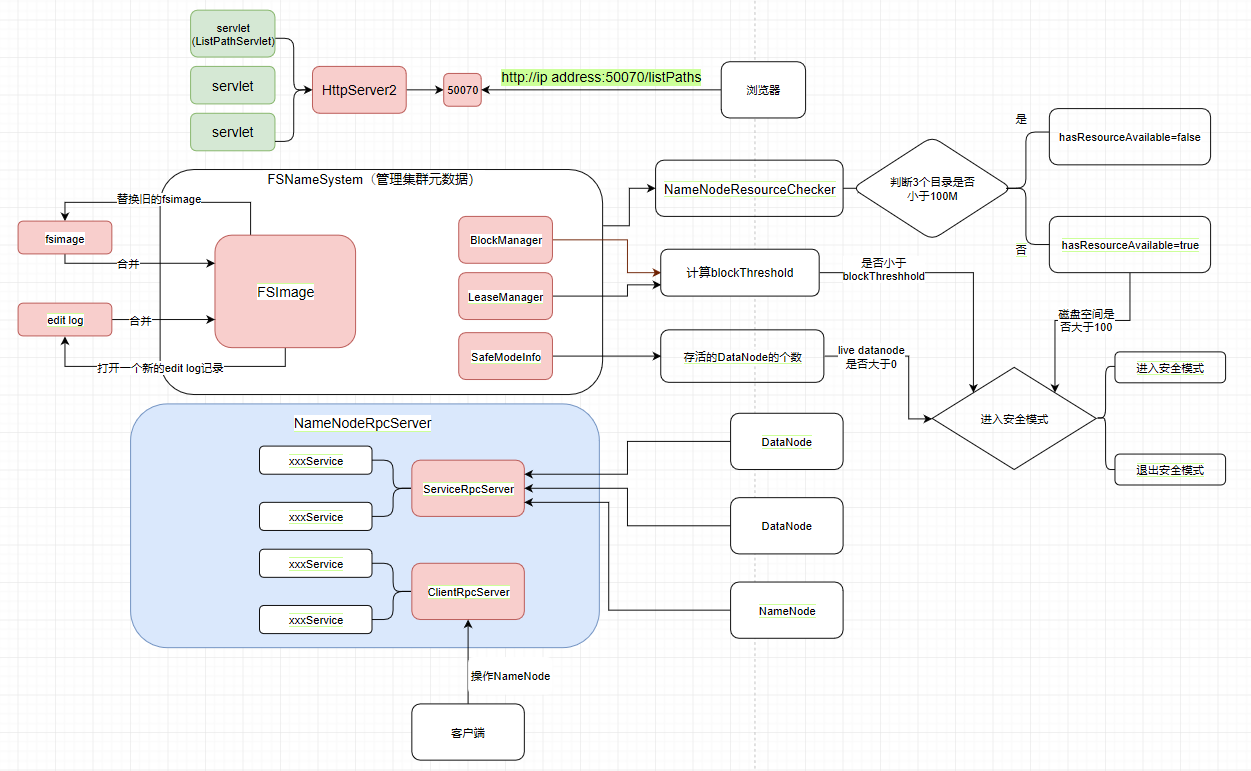
我们看到目前为止可以先画一下我们的流程图了
1.5 流程图的第一步
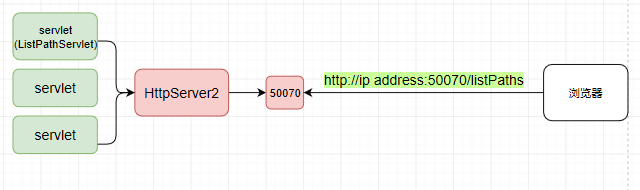
首先我们现在是有一个HttpServer2(Hadoop自己封装的HttpServer),它上面绑定了很多提供各种各样功能的servlet
它对外提供一个50070的端口,浏览器发送一个http://ip address:50070/listPaths的请求去请求servlet后,就会返回那个web页面了
1.6 Hadoop RPC
回到1.4.1中的那张HttpServer的那个位置。在启动HttpServer后,会加载元数据,但是我们现在模拟的场景是集群第一次启动,第一次启动的时候是不存在元数据的,所以我们先直接跳过这个步骤,去到Hadoop RPC的位置
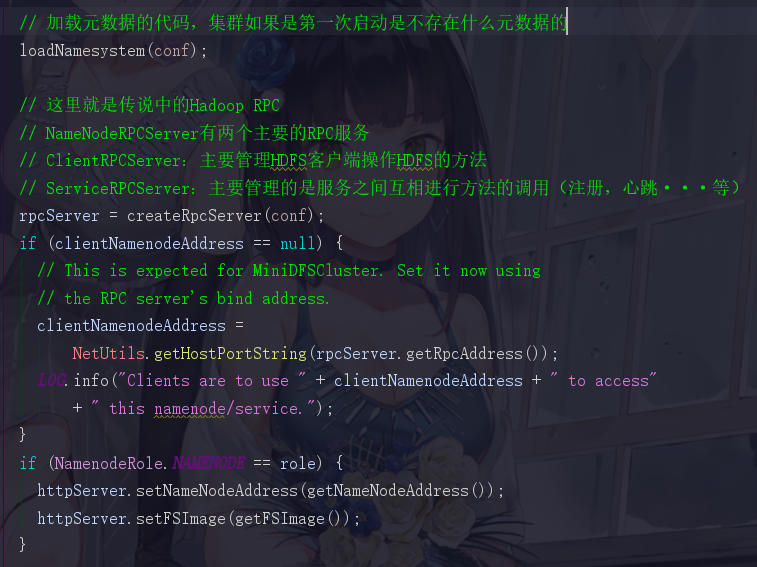
为什么我会知道这个Hadoop RPC会有两个这样的服务,这个当然不是我猜的,也并不是我找过什么资料或者点进去看过,而是在NameNode源码中告诉我们的
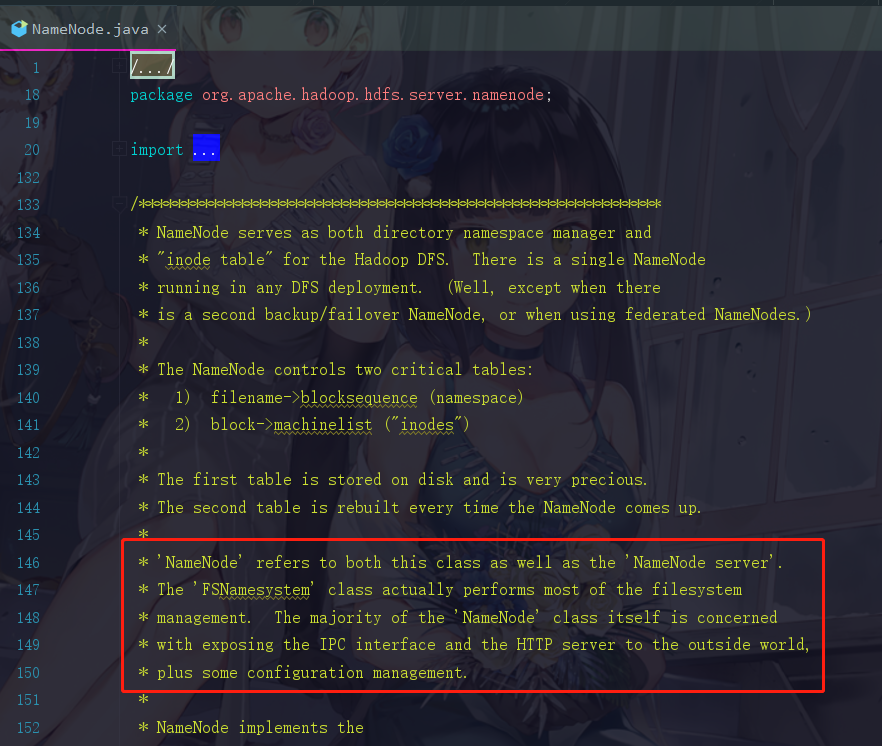
我们直接把这一段英文放到百度翻译上看看

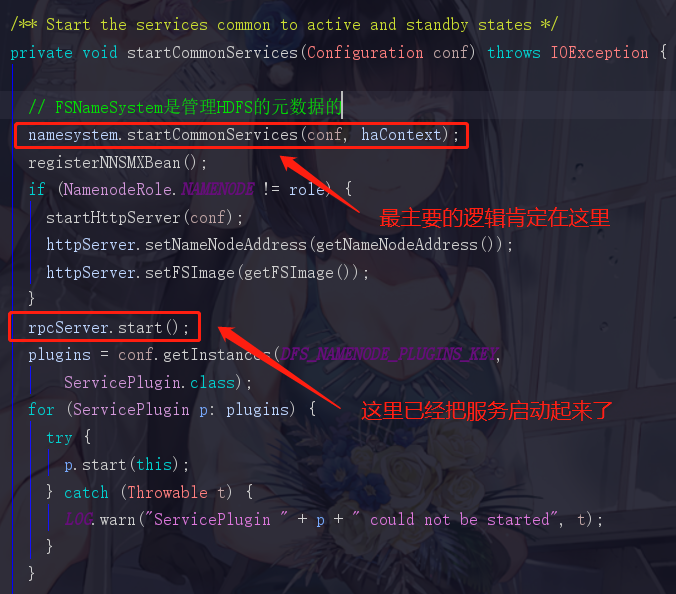
这里它就说明了,NameNode不仅仅是个类,还是个服务器,向外界公开一个IPC Server和一个Http server,补充说明一下,这个IPC Server就是让开发者去进行命令操作的。这个Http Server就是那个开放了50070界面让开发者了解HDFS的情况的。而FSNamessystem这个类是管理了HDFS的元数据的
现在我们知道了,这两个服务一个是提供给内部的DataNode去调用,而另外一个是提供给服务端去调用的
1.6.1 验证实现协议且协议中存在versionID
这里的方法起名已经非常直接了,createRpcServer()哈哈哈,我们点击进去
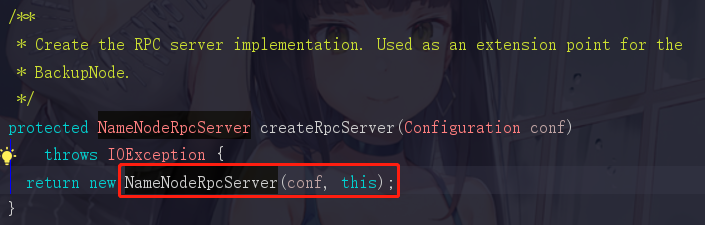
这里的注释为写了创建RPC服务端实现,它return了一个NameNodeRpcServer,那是不是它才是我们要找的NameNode服务端呢?
还记得我们开头说判断RPC的依据吗,3.协议说得直白点就是一个接口,但是这个接口必须存在versionID,好的我们记住这句话,再点进NameNodeRpcServer
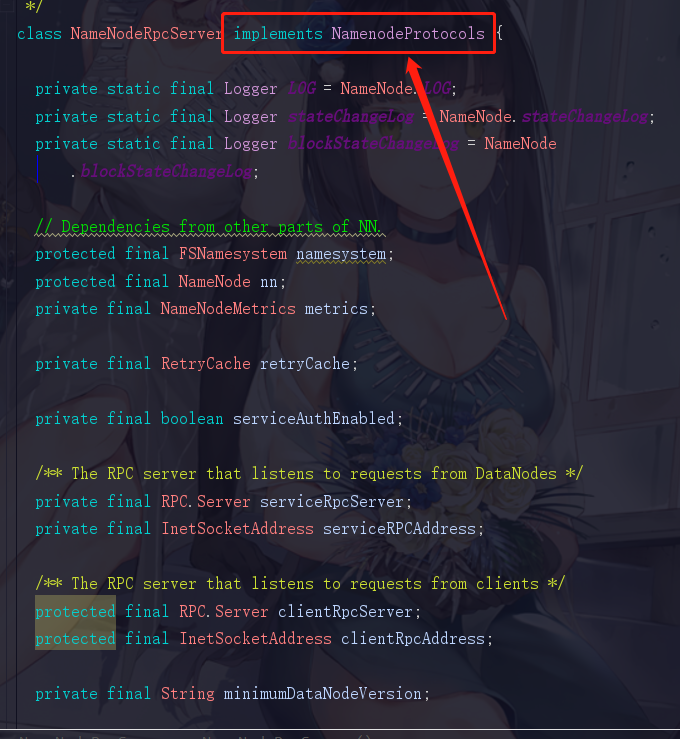
相信这就是我们想要看到的,它确实实现了一个NamenodeProtocols,感觉快要看到真相了是吧,再点进去
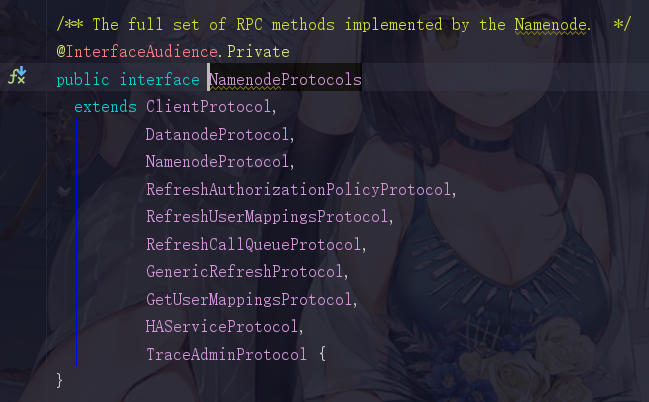
我去,继承了这么多个协议,怪不得我们的NameNode的功能如此强大,这里面得有多少个方法啊,这时候我们随便点进去一个接口去看
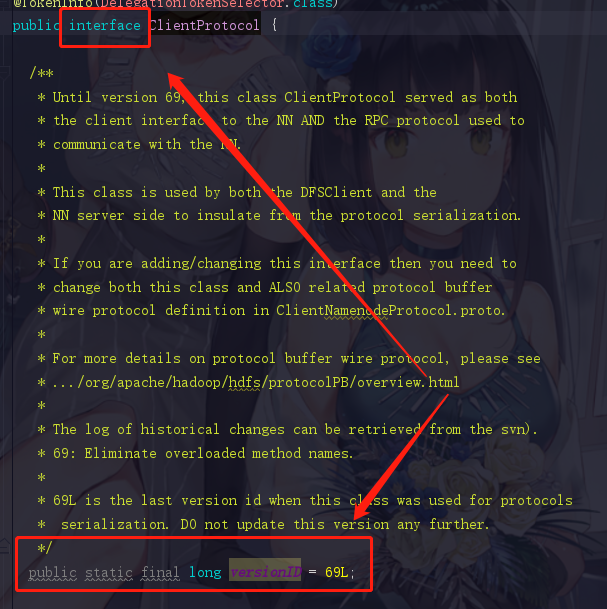
1.6.2 验证存在设置参数的过程
满足是一个接口,也有一个versionID了吧,我们现在觉得它就是服务端了,可是我们还没有看见那些set服务器地址啊,端口啊···等等这些参数的代码,所以还是不能一口咬定,所以我们现在再退回去到class NameNodeRpcServer里面,拉到296行
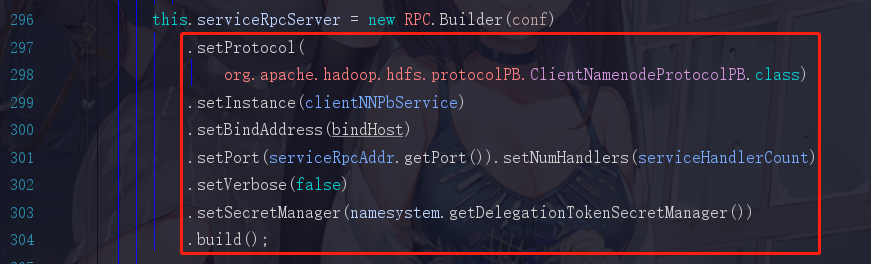
再拉取到343行,发现又有一段类似的

还记得我们刚才说过,两个服务一个是提供给内部的DataNode去调用,而另外一个是提供给服务端去调用的,所以这里这俩,第一个serviceRpcServer是服务于NameNode和DataNode之间调用的,而第二个clientRpcServer是服务于客户端与NameNode,DataNode进行交互调用的
而且在创建它们之后,会有很多的协议被添加进来,这些协议也是带有许许多多的方法的,添加的协议越多,这两个服务的功能也就越强大
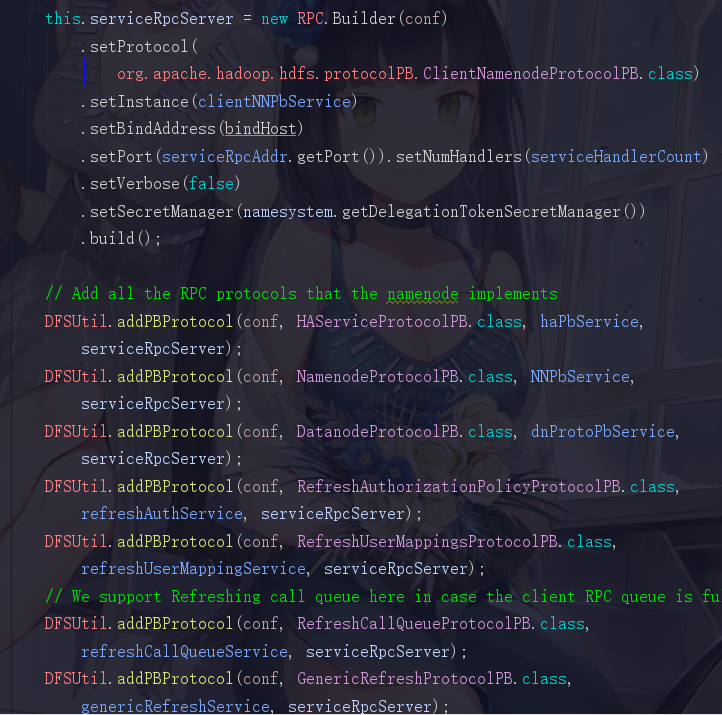
所以它们和HttpServer的套路是一样的,它们是通过添加协议来增强自己,而HttpServer是通过添加servlet而已。
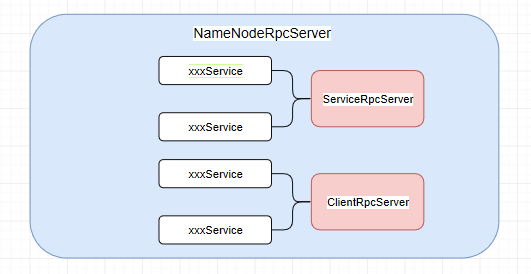
1.7 流程图的第二步
把NameNodeRpcServer的结构图画出,也就是主体为 serviceRpcServer 和 clientRpcServer ,然后它们俩提供了各种各样的服务方法
客户端操作NameNode(比如创建目录mkdirs)就要使用 clientRpcServer 提供的服务,而各个DataNode和NameNode的互相调用则通过 serviceRpcServer 实现
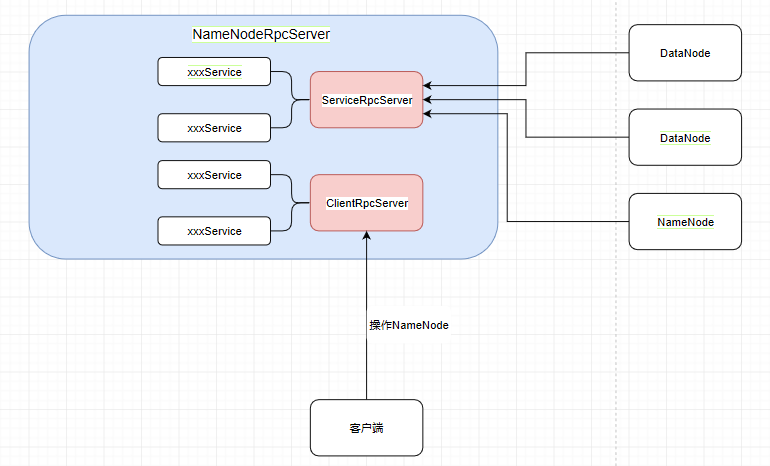
图中的namenode可以视为standBy NameNode,在HA高可用中提到过的active和standby忘记的可以去复习一下
1.8 正式启动前的检查
安全模式我们在HDFS的第一篇中的心跳机制中已经提过了,这里直接复制过来
hadoop集群刚开始启动时会进入安全模式(99.99%),就用到了心跳机制,其实就是在集群刚启动的时候,每一个DataNode都会向NameNode发送blockReport,NameNode会统计它们上报的总block数,除以一开始知道的总个数total,当 block/total < 99.99% 时,会触发安全模式,安全模式下客户端就没法向HDFS写数据,只能进行读数据。
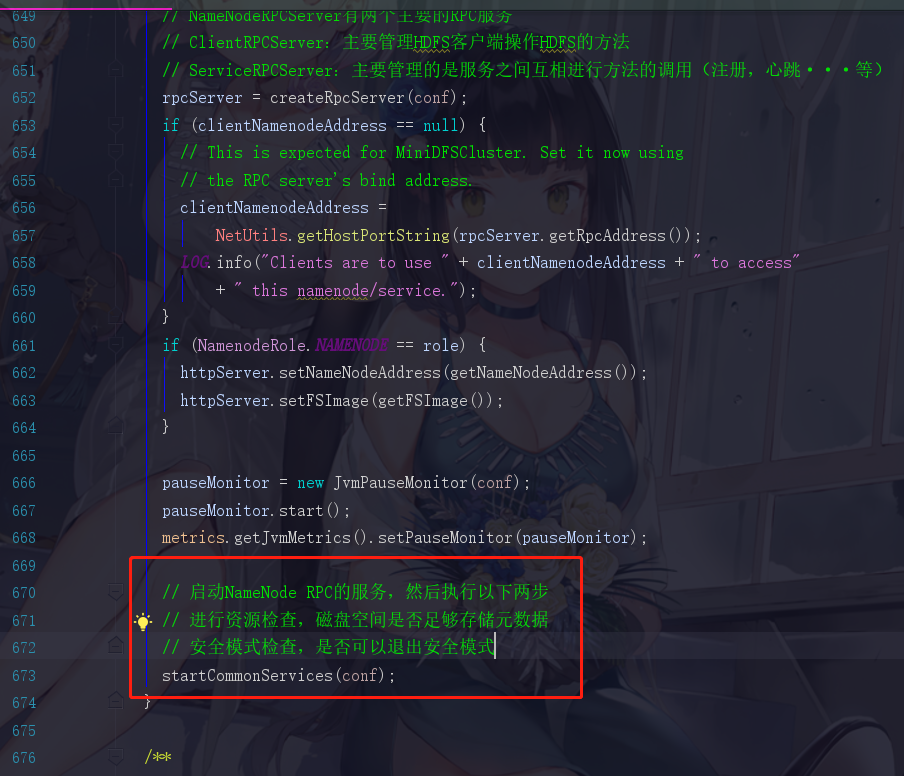
点进startCommonServices
1.8.1 NameNode资源检查1 --- 获取需要检查的目录
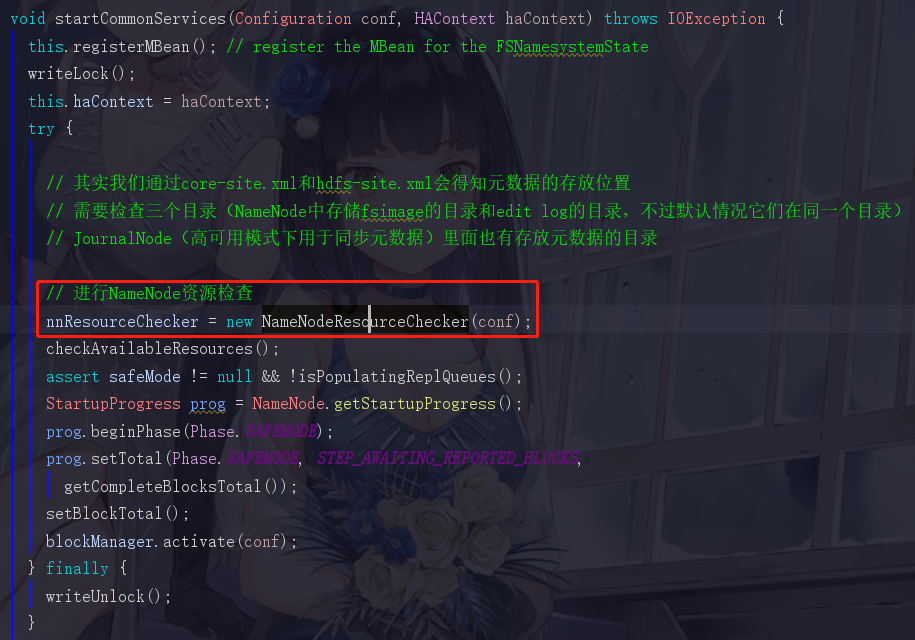
NameNodeResourceChecker直译过来就是NameNode的资源检查器,我们点进去看到
duReserved
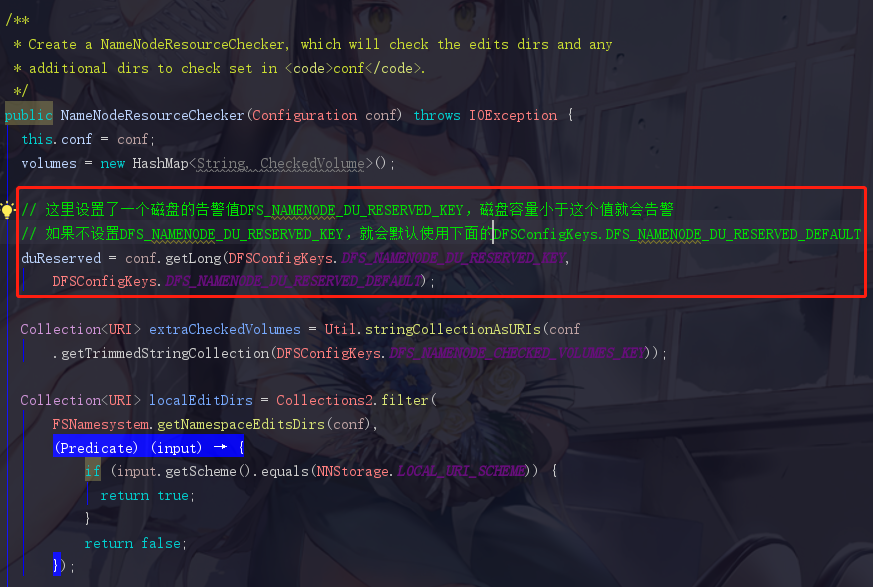
这里是一个duReserved的值,它可以让我们自行设置,如果不设置,就使用它给我们的默认值。我们也可以查看一下这个DFS_NAMENODE_DU_RESERVED_DEFAULT的默认值,它为100M,定义在DFSConfigKeys.java中
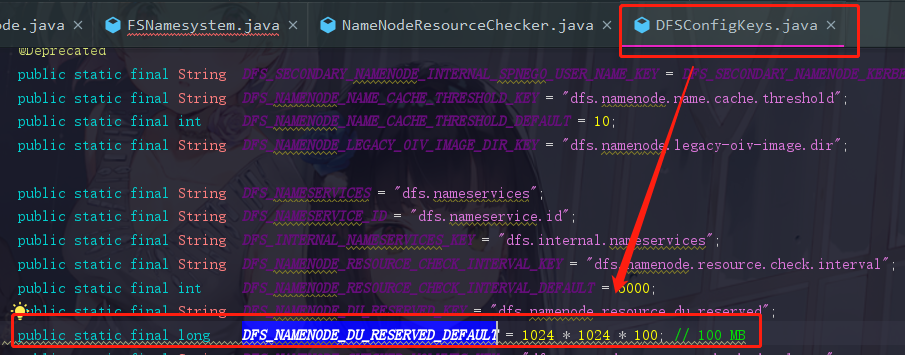
这里我也可以补充一下,我们需要判断告警的目录就在下面的getNamespaceEditsDirs(conf)中,一直点进去就可以看见我们刚刚提到的,需要检查的三个目录(NameNode中存储fsimage的目录和edit log的目录和JournalNode的目录,这些参数全部都是定义在DFSConfigKeys.java中)
localEditDirs并不是HDFS上的目录,而是linux磁盘上的目录,之后遍历这个 localEditDirs 加入到一个volume中
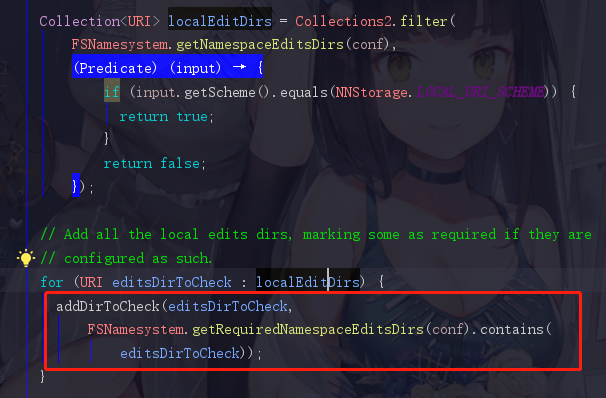
在HDFS上很多位置都可以看到volumes这个单词,volumes其实就是一个存放需要检查的目录的目录集,注释上的第一句话“Add the volume of the passed-in directory to the list of volumes to check.”意思就是将传入目录的卷添加到要检查的卷列表中,这里的卷就是volumes。
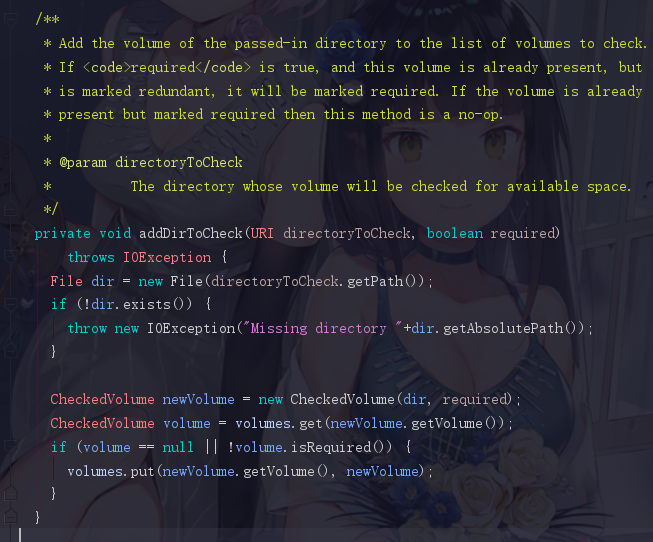
所以我们现在回到startCommonServices,现在已经得知
// 作用就是获取到所有需要检查的目录
nnResourceChecker = new NameNodeResourceChecker(conf);
1.8.2 NameNode资源检查2 --- 检查是否有足够磁盘空间存储元数据
checkAvailableResources() 点进去看一下
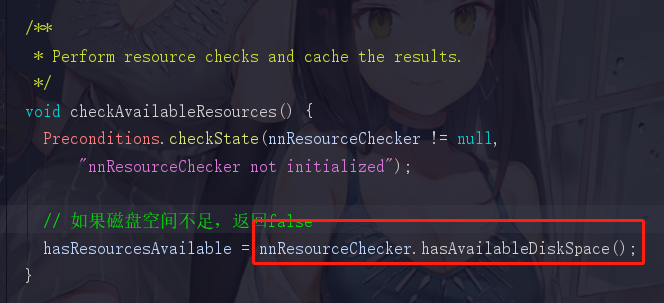
hadoop的方法命名总是如此地直白,hasAvailableDiskSpace直译过来就是有没有可用空间,再点击进去
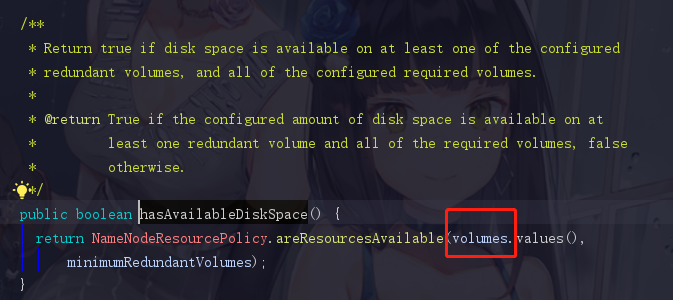
这里看到 volumes 了,因为刚刚也解释过了,volumes 就是存放需要进行检查的目录(也就是那3个目录)的,那自然把 volumes 作为参数传进来,就把那三兄弟一锅端了。再点进进去areResourcesAvailable方法,既然这个 volumes 是一个集合,那我们打赌它里面的逻辑肯定有一个for循环来遍历 volumes 里面的那些值进行检查
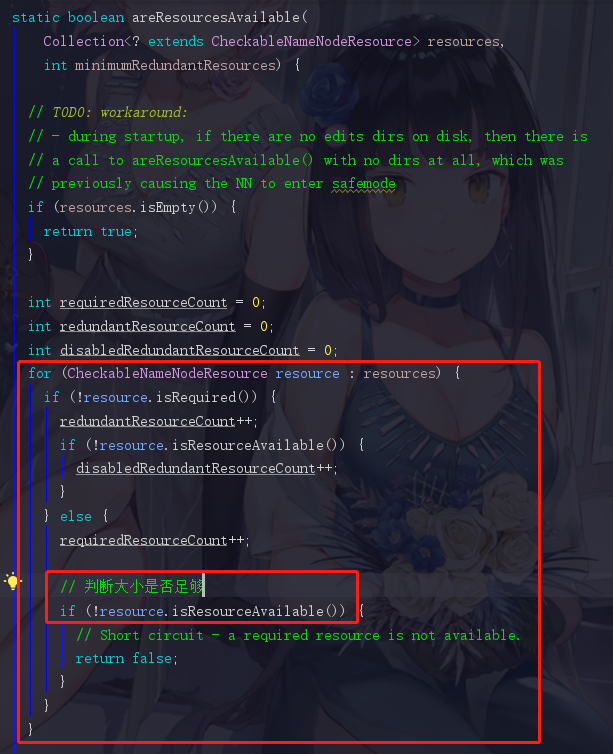
果不其然,for循环出现了。此时isResourceAvailable就是判断依据了
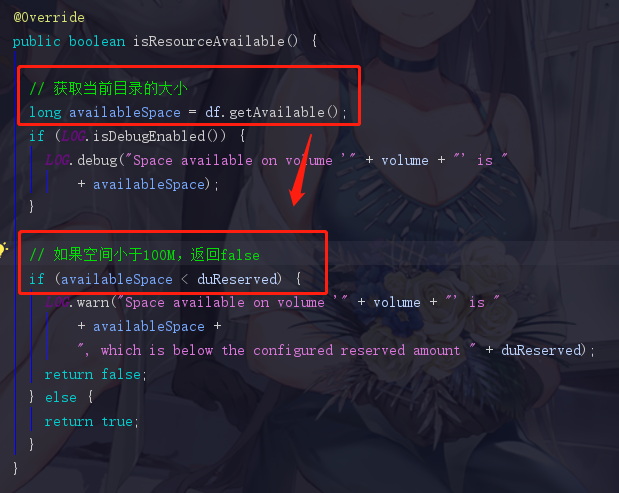
这里我们看到,它先获取到了当前目录的大小(jdk),然后和我们之前讲到的 duReserved (默认100M)做比较。这时候我们就把前面的知识点串起来了。
如果空间不足,它就会打印一段话,这段话在我们日常的公司集群环境中不太可能看到,但是如果我们是自己搭建的集群进行学习时就会看到,这个时候就是我们的虚拟机的空间不足,虽然集群服务正常启动,可是集群无法正常工作。
1.8.3 NameNode资源检查3 --- 安全模式的检查
面试题:我们是否真的清楚为什么hadoop集群会进入安全模式呢?
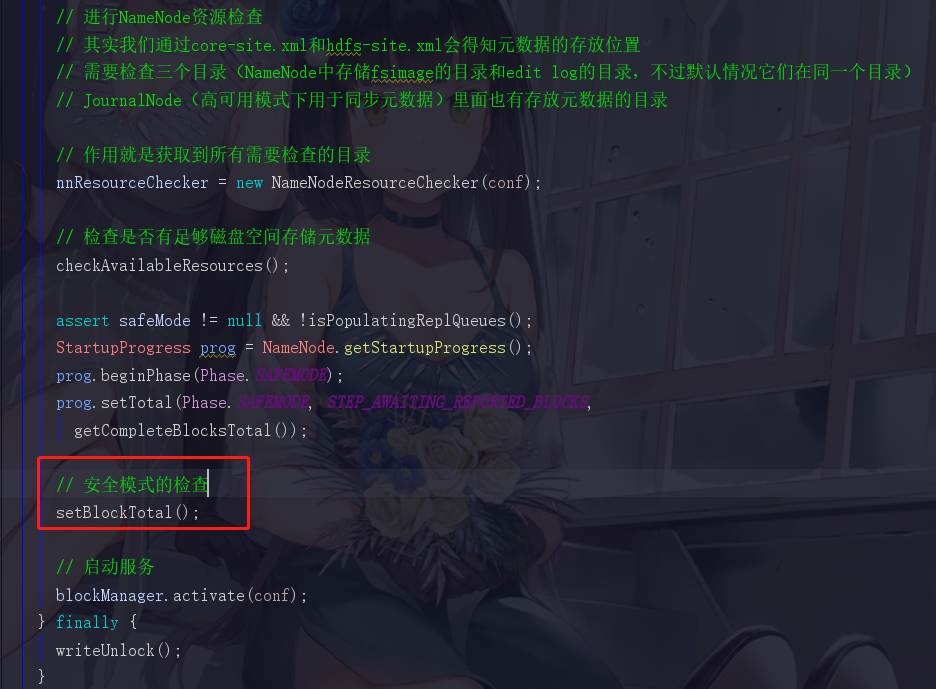
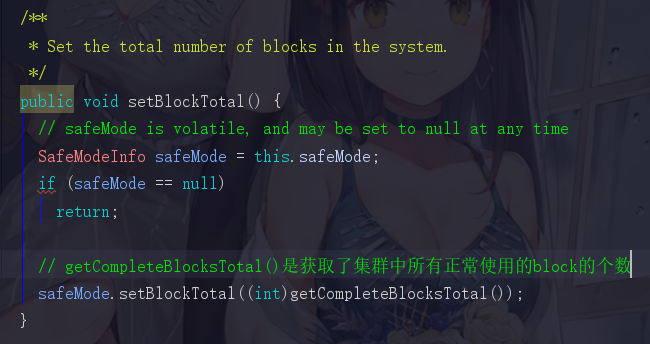
回到FSNameSystem,点进去 setBlockTotal() 方法
点进去看看它是如何获取正常block个数的
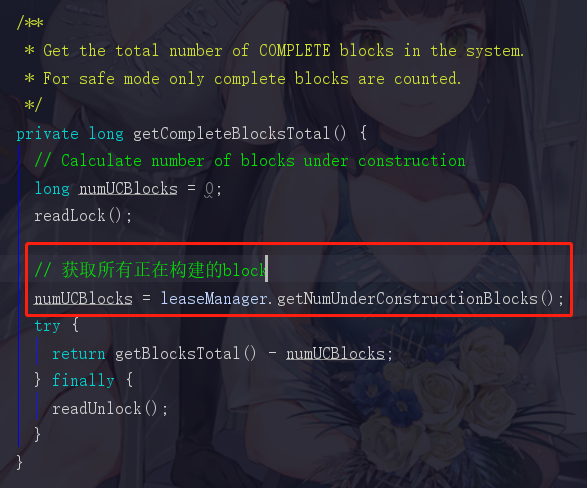
获取正在构建的block是个啥意思呢,再继续点进去
在HDFS里面block有两种状态,一种是complete,已经是可以使用的一个完整block,还有一种是UnderConstruct,这个属于正在构建,还不能正常使用,对应下文中的这个代码
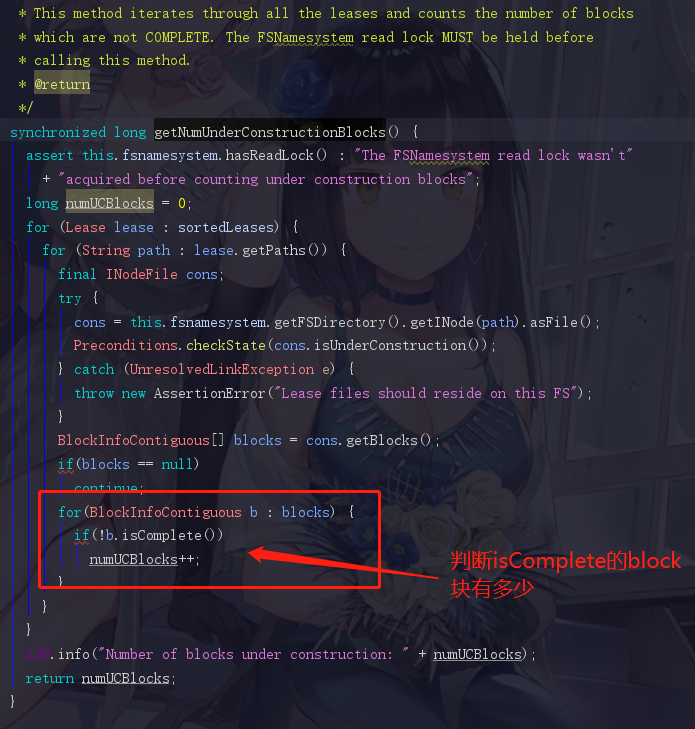
所以我们退回来,getCompleteBlocksTotal中,使用blockTotal总block数-numUCBlocks得出来的就是准备complete的block个数
退回到setBlockTotal中的safeMode.setBlockTotal((int)getCompleteBlocksTotal()),点进去setBlockTotal
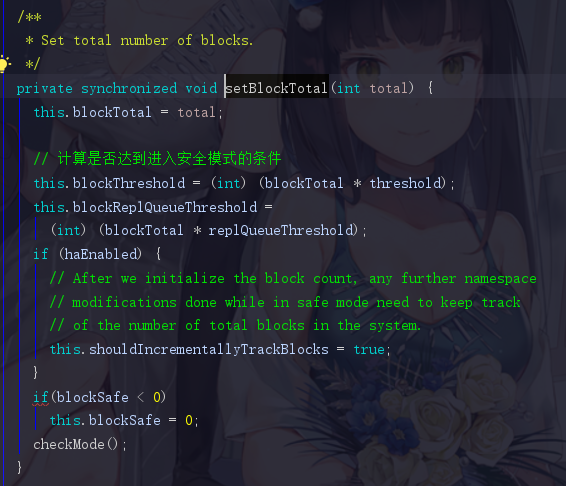
这里就是设置何时可以退出安全模式的代码,threshold默认值为0.999,比如我们总block数为1000,那如果存在999个isComplete的block,也就认为集群是健康状态,而可以退出安全模式。
点进去checkMode(),我们可以发现needEnter()即是判断进入安全模式的条件(刚刚说明的是退出的)。
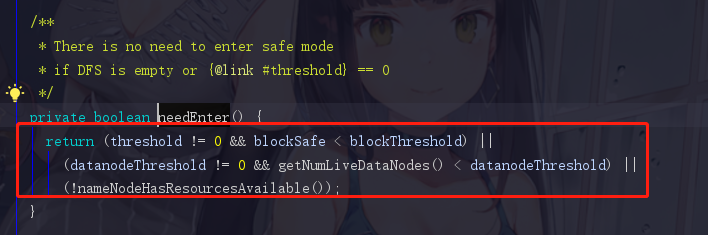
任意满足以下3个条件的任意一个,都会进去安全模式
第一个条件
threshold != 0没啥好说的,这个东西本身就不可能设置0,blockSafe < blockThreshold 这里的blockSafe是指什么呢?
我们的集群启动时,NameNode启动后DataNode也会启动,在DataNode启动时会向NameNode上报自己的block状态信息,每上报一个,blockSafe就会加一。blockThreshold满足安全模式阈值条件所需的块数,当上报的量比安全模式要求的量少时,安全模式启动。
第二个条件
datanodeThreshold != 0 && getNumLiveDataNodes() < datanodeThreshold
DataNode和NameNode会有心跳机制,这个条件大概就是,集群中存活的DataNode个数少于datanodeThreshold个就让集群处于安全模式
非常搞笑的是,这个datanodeThreshold的默认值是0,还需要自己配置,所以这个条件基本自己不配置是不生效的。hhh
第三个
!nameNodeHasResourcesAvailable()直接翻译过来,磁盘空间是否充足,对,引用的就是上面提过的hasAvailableDiskSpace,直译过来就是有没有可用空间.
1.9 服务启动
感动,整了这么久终于可以正常启动了
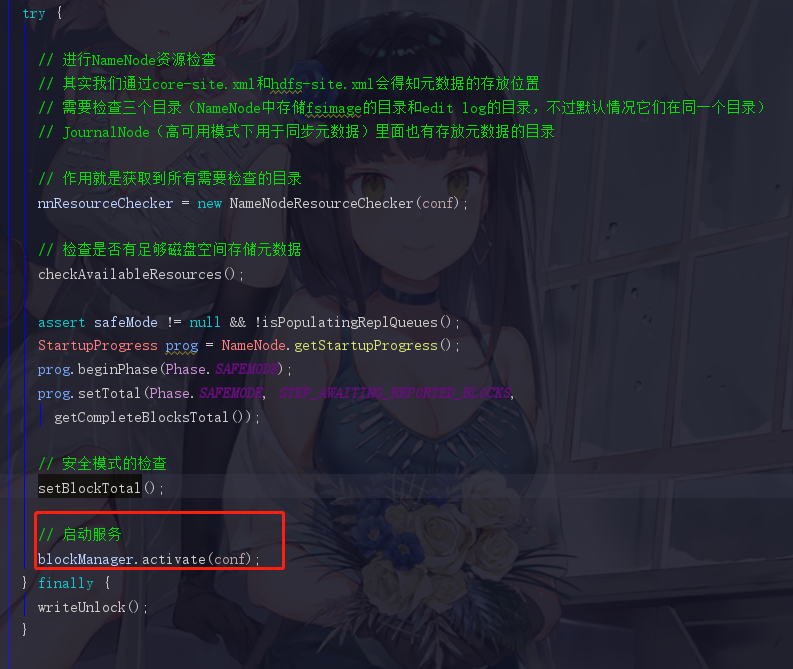
当然这里会连带启动一些服务,后面再展开了
1.10 流程图的第三步
其实就是补充了FSNameNode,然后把前几次画的都放在一起而已
finally
这一篇就是NameNode的启动的大致流程了,当然有很多细节的部分我们仍未深究或者是一笔带过,这些细节有些不重要有些是之后再进行补充的,截图真的是非常麻烦,希望这些无论是对你,对我都会有所收获。
