

引言
随着2013年docker的发布,服务的部署方式开始逐渐向docker迁移。因为docker启动更快,资源利用率更高;并且也极其便利,业务人员只需要编写好dockerfile,就可以任意支持docker的环境中运行相应的程序。
但是大家都知道,我们并不是只有一个节点,我们也不是只有一个服务。因此,在docker产生之后的一些年里,诞生了很多种容器编排工具,其中最著名的也就是本文着重要讲的kubernetes了。
kubernetes, 一般简称为k8s,用8代替8个字符“kubernete”而成的缩写, 是由google开源的用于管理云平台中多个主机上的容器化的应用。这个项目源于google内部的borg系统,从项目的架构来看,和borg的论文如出一辙,感兴趣的可以去看一看。这篇文章会讲k8s的设计理念,k8s的主要组件,希望大家看了这篇文章,能对k8s有一个比较清晰的认识和了解。
k8s能做什么呢?
- autoscale 可以根据我们制定的规则,实现自动扩缩容,以满足业务的需要.
- 蓝绿部署 启动运行着新版应用的副本集的同时,旧版应用依旧提供服务,直到新的应用ready
- 管理有状态/无状态应用,管理cronjob等
- 自带服务发现
- 负载均衡
- 支持第三方插件
- ......
对,你所需要的,k8s基本都能做。那么,k8s有那些关键的东西呢?
k8s关键词
- master
- node
- pod
- Deployment
- Service
- label
- namespace
- ingress
- ......
如果我们使用k8s的话,应该会经常接触到这些概念,那么他们是什么呢?
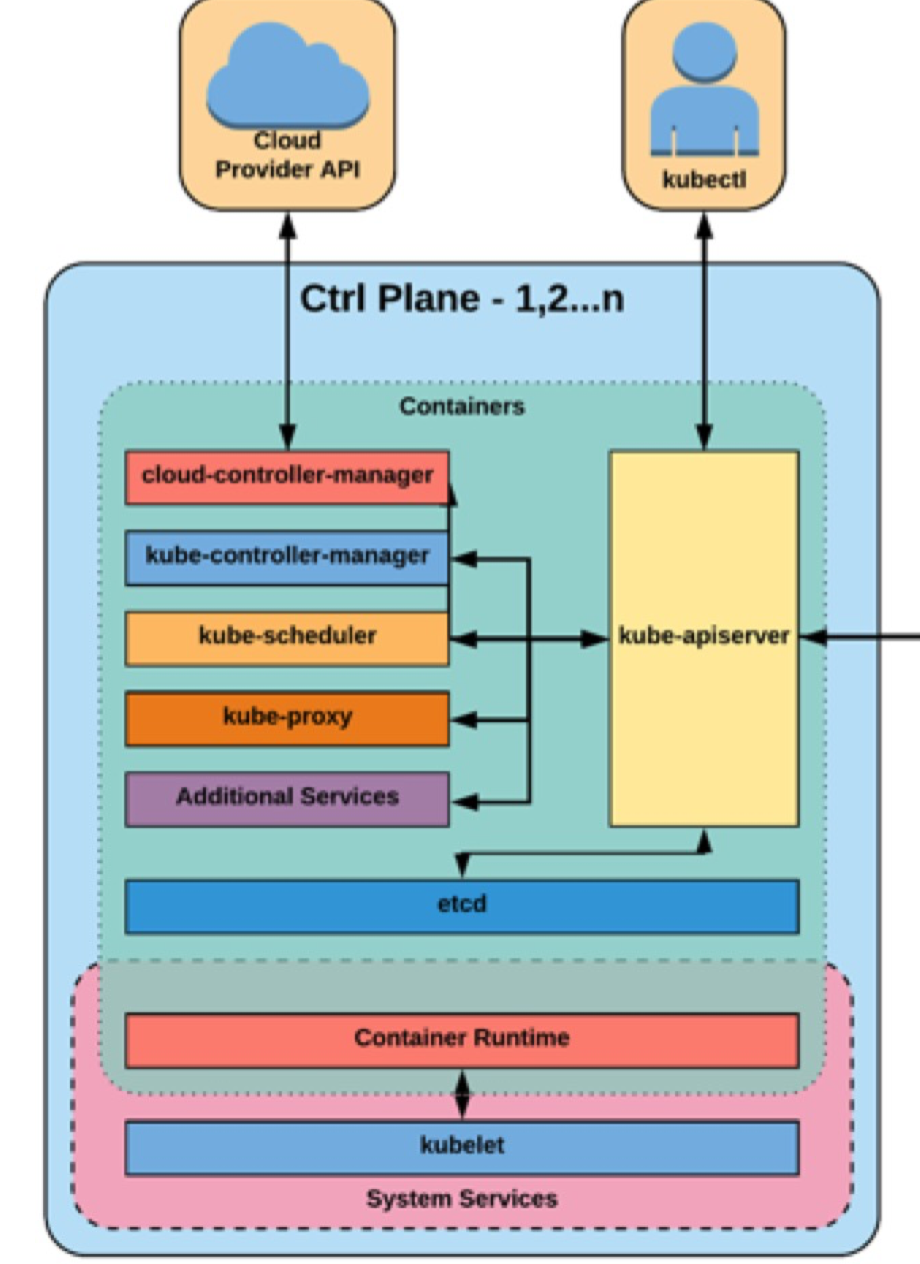
master
k8s也是master-agent架构,master可以认为是k8s的运行中心。
node
node是k8s中运行我们应用程序的节点,
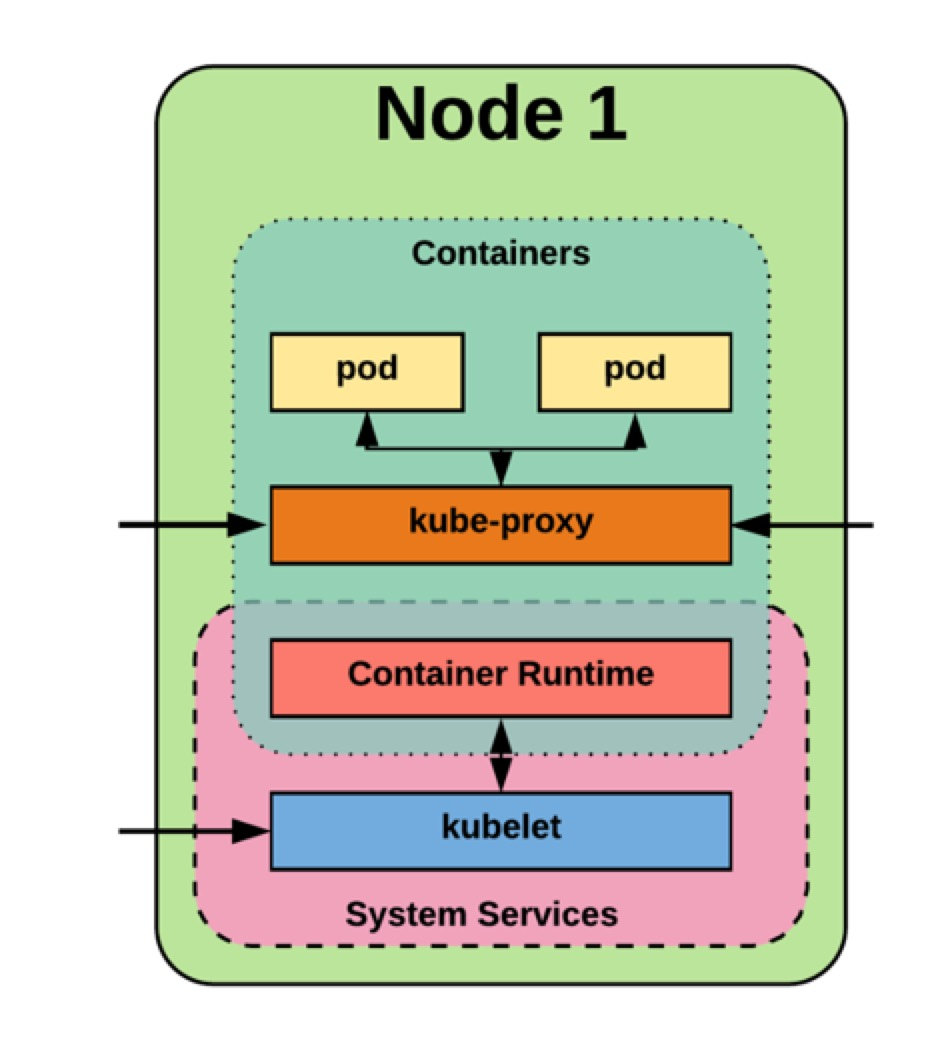
pod
pod是k8s可以创建和管理的最小单元。一个pod可以有多个容器。不具有持久化的特性。pod内的容器共享网络空间和存储,可以认为是一个逻辑主机。
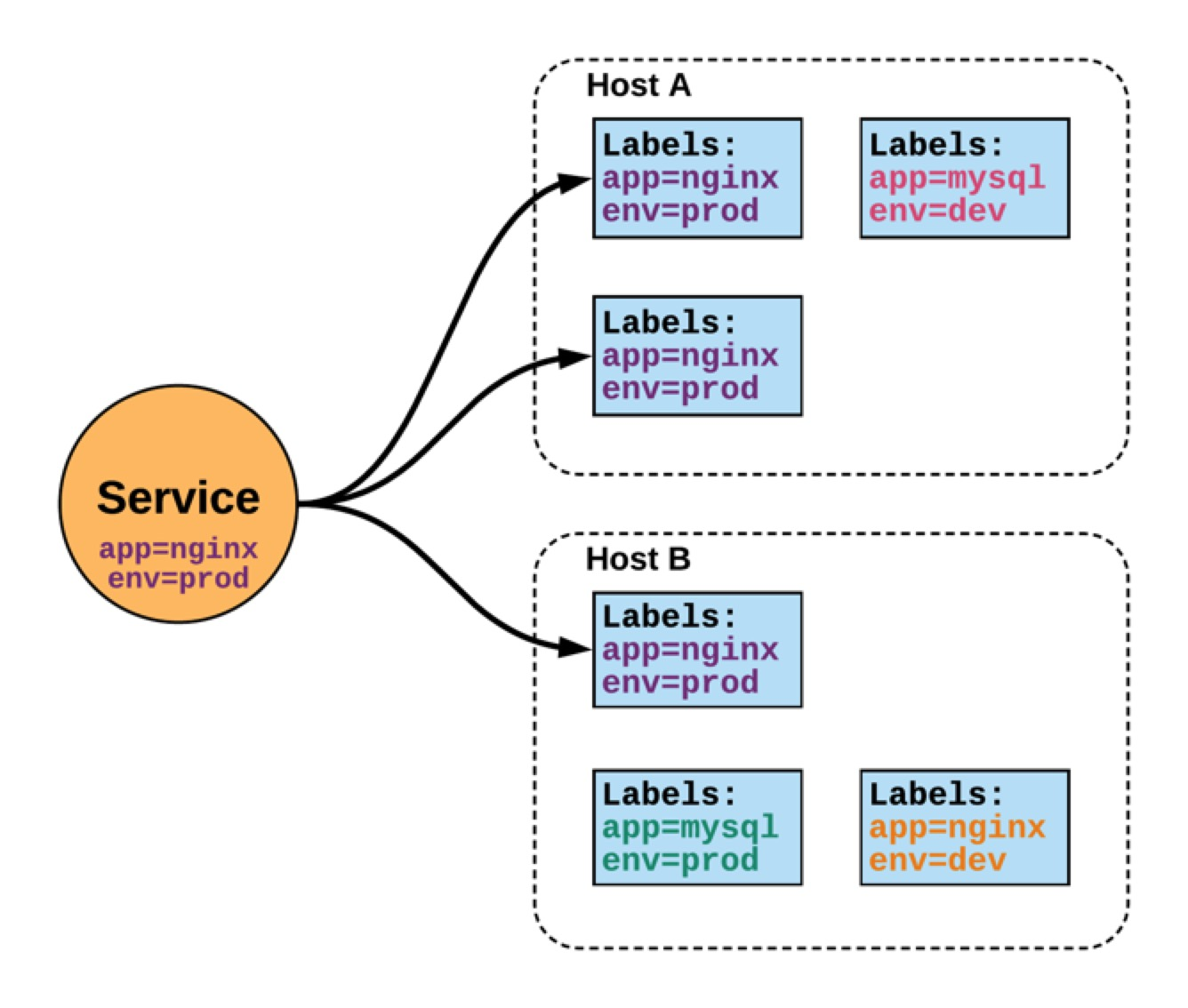
service
service是一个抽象概念,定义了服务访问pod的策略。是持久化的资源。有ClusterIP、NodePort、NodePort、ExternalName等类型。
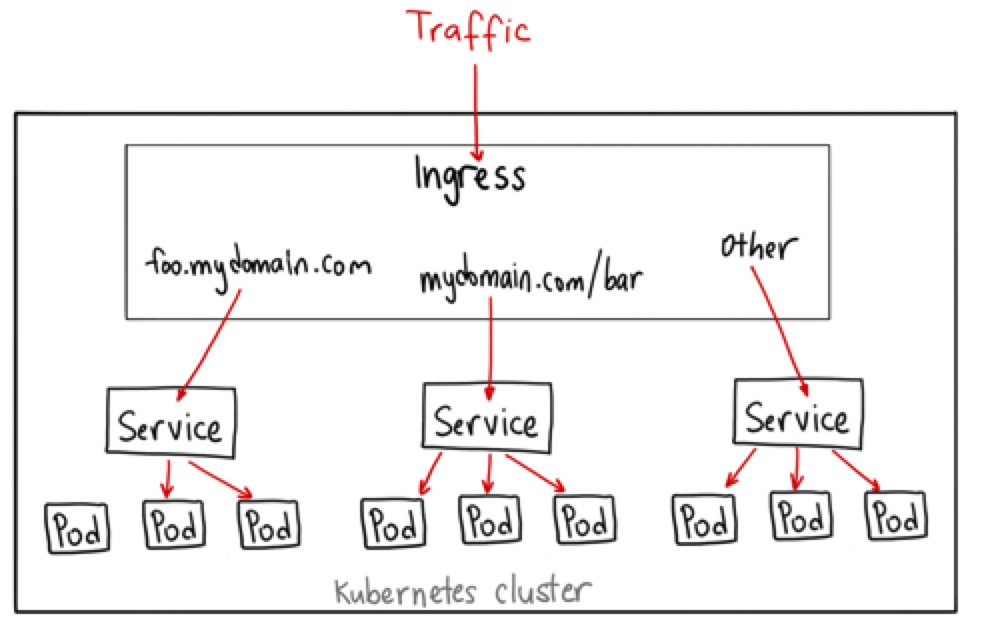
ingress
k8s对外暴露服务主要有两种方式:NotePort和LoadBalance。ingress只需要一个NodePort或者一个LB就可以满足所有service对外服务的需求。运行机制如图
Architecture
那么,现在来看看k8s的整体架构吧
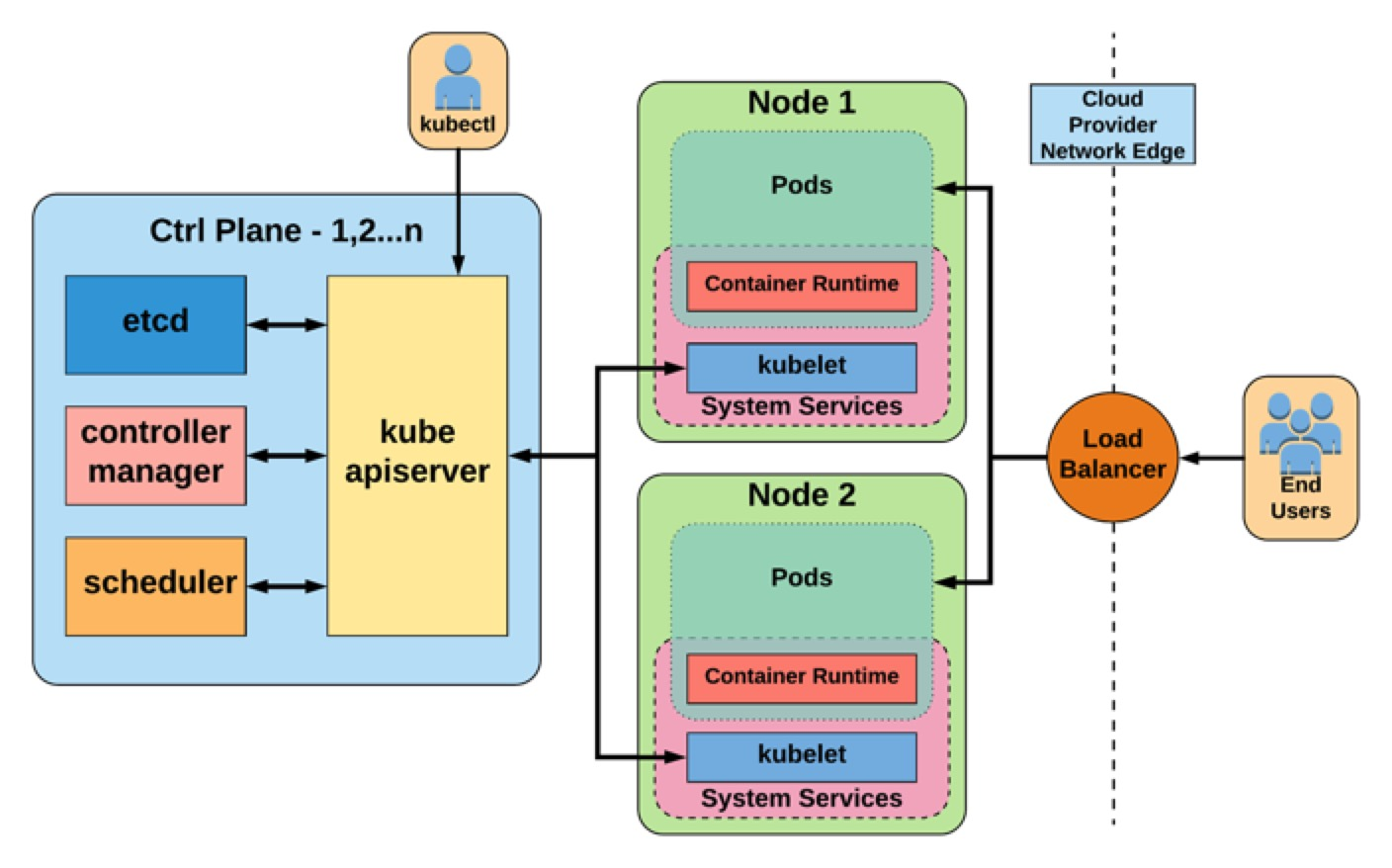
当我们创建deployment的时候发生了什么?
- api-server存储deployment到etcd中
- deployment controller监听到新的deployment,创建replicaset
- replicaset controller监听到新的replicaset,创建对应的pod
- scheduler监听到新的pod,选择适合的node
- kubelet运行pod, pod初始化
这个过程比较复杂。k8s通过api去解耦各个组件和etcd的交互,是通过 list-watch实现的此功能。后面会根据对应的代码进行一一分解。
参考:
