

这周面试的时候被面试官问到AQS,回答得比较尴尬,所以提前把AQS相关的内容整理出来了。本来第四篇准备写一下栈或者哈希的并发数据结构……
互斥锁
在介绍互斥锁的实现之前,我们需要了解一堆多线程模型的基本概念:竞态条件、临界区、忙等待、死锁、饥饿等。
竞态条件
在多线程模型中,由于线程之间的执行顺序无法确定,我们无法得到一个唯一确定的执行结果。而如果在某些地方我们假定了这个执行结果,就会造成竞态条件——最典型的例子是先检查后执行(Check and act)。在Java并发实战一书中,就举了一个和朋友约定见面地点的例子:假设现在有两家星巴克,而你并不知道朋友去了哪一家,所以很可能你前脚出了门,朋友后脚就进来了。这里你查看星巴克里朋友在不在就是检查,是否见面依赖于检查的结果。朋友可能在检查后又回来了,这就是在检查后改变了状态。
在数据库中,存在大量的并发事务,但我们并不会考虑其中的竞态条件,就是因为数据库存在互斥锁。
临界区
临界区就是一段只能被单个线程访问的代码。TAOMP 一书中定义了互斥:不同线程之间的临界区没有重叠。设是A第k次执行临界区的时间段,那么A和B互斥可以表示为二者时间段的全序关系(也可以是反过来的):
两线程锁
这里介绍的锁算法只适用于两个线程,它们分别叫做 LockOne 和 LockTwo 算法。LockOne 为两个线程分别设置了两个标志位,然后相互读取对方的标志来判断是否可以进入临界区:
class LockOne implements Lock {
private volatile boolean[] flag = new boolean[2];
public void lock() {
int i = ThreadID.get();
int j = 1 - i;
flag[i] = true;
while (flag[j]) {}
}
public void unlock() {
int i = ThreadID.get();
flag[i] = false;
}
}
注意到这里设置标志在判断标志之前,否则就会陷入到之前先检查后执行的错误中。这里设置标志实际上是一种声明:我即将进入临界区,而其他线程不能进入。因此,这个算法不具有无死锁的特性,因为可能两个线程都声明了,所以都无法进入临界区。
LockTwo 算法只有一个volatile的标志位。它不是判断标记是否由自己设置,而是另一个线程设置(因为自己设置的话,不论何时都可以进入临界区)。换而言之,这里声明的其实是:我不会进入临界区,你先进去。
public class LockTwo implements Lock {
private volatile int victim;
public void lock() {
int i = ThreadID.get();
victim = i;
while (victim == i) {};
}
public void unlock() { ... }
}
但是,LockTwo 依然不是无死锁的,它会在线程线性执行的时候死锁。其实我们能从这两个算法身上看到FLP不可能定理的影子,也就是所谓的共识问题。
Peterson锁
Peterson Lock 结合了 LockOne 和 LockTwo,是一种最为简洁的无饥饿锁算法。为什么 LockOne 和 LockTwo 这两个算法恰好是互补的呢?LockOne 声明的是我要进入,其本质是一种权力,是不可篡改的(因此,它对应私有内存);LockTwo 声明的是我不进入,只是一种声明,是可以被篡改的(因此对应共享的内存)。
它们叠加的声明是:我打算进入临界区,但是你可以先进。关键在于循环条件的判断——Peterson锁是二者的与(AND)关系。因此,这个算法是完备的,因为既保证了交叉覆盖的唯一性,又保证了任何一方缺席的可靠性。
多线程锁
过滤锁
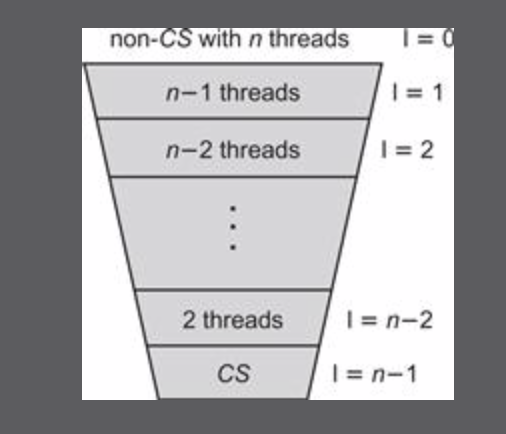
在Peterson锁中,使用2个标志位来表示线程是否正尝试进入临界区。过滤锁将这个概念一般化了,用一个整数表示线程进入的层数。过滤锁将和其他线程的竞争抽象化为n-1个层,每一层都相当于一个临界区。这也是这个算法名称的由来:每次将一个线程筛出临界区。
以下是伪代码(没有施加可见性):
class Filter implements Lock {
int[] level; // level[i] for thread i
int[] victim; // victim[L] for level L
public Filter(int n) {
level = new int[n];
victim = new int[n];
for (int i = 1; i < n; i++) {
level[i] = 0;
}
}
public void lock() {
for (int L = 1; L < n; L++) {
level[i] = L;
victim[L] = i;
while ((∃ k != i level[k] >= L) &&
victim[L] == i ) {};
}
}
public void unlock() {
level[i] = 0;
}
}
实际上,过滤锁可以看做是N把锁的顺次上锁。这种按照同样的顺序上多把锁的方式在许多并发数据结构中都可以看到。过滤锁并不能在每层都停留一个线程,从而形成排队,因而无法保证公平性。当一个线程获得锁时,其他n-1个线程可能都在最底层,也可能分散在各层。
公平性
一般来说,锁需要保证无饥饿演进。但是,无饥饿不能保证公平,因为不知道进入临界区的时间。但是,可以保证一种先来先服务的公平。在讨论这种公平前,由于自旋加锁通常是无限的循环,因此需要刨除这部分代码。一般会把lock分为两部分:
- A doorway section, whose execution interval
consists of a bounded number of steps
- a waiting section, whose execution interval
may take an unbounded number of steps
也就是门廊区和等待区。一个门廊区在有限步骤内完成,这也被叫做有界限的无等待(bounded wait-free)。
A lock is first-come-first-served if, whenever, thread A finishes its doorway before thread B starts its doorway, then A cannot be overtaken by B:
If, then
for threads A and B and integers j and k.
按照这种定义,过滤锁不是公平的,因为当victim被修改时,通过这一层的线程究竟是否是最早到达的线程是不确定的。
Lamport面包房算法
这个算法的发明人其实就是分布式系统中大名鼎鼎的兰帕德。原本分布式系统和并发问题就有很强的关联性——但并发问题要更简单,因为它有一个共享内存的条件(其实还有别的,比如不会考虑CPU的部分故障)。
面包房算法和过滤锁很相似,除了把victim替换成了一个递增的编号。这个编号每次从已有的所有编号中取最大值加1。然后,线程等待所有在这个编号之前的线程执行完毕。不过,有可能两个线程的编号一致——它通过比较线程的编号来保证唯一的序关系。
这个算法和Lamport时间戳有很强的相似性。比如,Lamport时间戳通过附加机器的编号,而这里是线程。但它们也有区别:在多线程模型中,门廊区(doorways)获取的编号虽然有可能是重复的,但是绝不可能出现一个线程获取到了更小的编号——这里隐含的假定是,线程的状态一经广播就具有了一致性,状态的变化是瞬时的——如果线程B获取到线程A的编号是1,那么线程C不可能获取到0。这一点在分布式系统中就不是一个可靠的保证了,因为机器A从0到1这一状态变化的广播不是瞬时的——实际上Lamport时间戳没有广播,因为它是通过客户端实现因果顺序上的序关系。这也是为什么,Lamport时间戳不能实现类似这里的临界区判断。它必须在事后才能知道全局的顺序,因此在某个时刻,它不能判断两个操作的顺序(这可以通过全序广播来解决)。
可以证明,面包房算法是无死锁的,也是FIFO的。而同时满足这两点的算法必然是无饥饿的。
有界时间戳
面包房算法有一个明显的问题,就是编号是永远递增的。为了解决这个问题,需要使用环形的时间戳。环形结构常常用于解决有界问题,比如一致性哈希。
这里书中用一个更加泛化的图论知识来解释有界时间戳。所有的序关系都可以看作是一个有向图中的边。这个序关系具有反对称和反自反性。在这里书中提到了前趋图的概念。我查了一下,关于这个定义不管是维基百科还是网上很多文章都没有很好的定义,比如前趋图其实是DAG的超集。所以,姑且可以认为它是满足这两个性质的有向图。
考虑一个前趋图G。图的支配指的是G的子图A的全部节点都有指向子图B的边。之前在看算法的时候,似乎有最小支配集的概念,不过这似乎不是一个非常大众的问题。如果A支配图G,那么相当于A拥有最大的时间戳。支配定义了图的乘法。
Replace every node v of G by a copy of H (denoted
), and let
in
if v dominates u in G.
数学归纳法定义有界时间戳的前趋图:
is a single node.
is the three-node graph defined earlier.
- For k > 2,
=
.
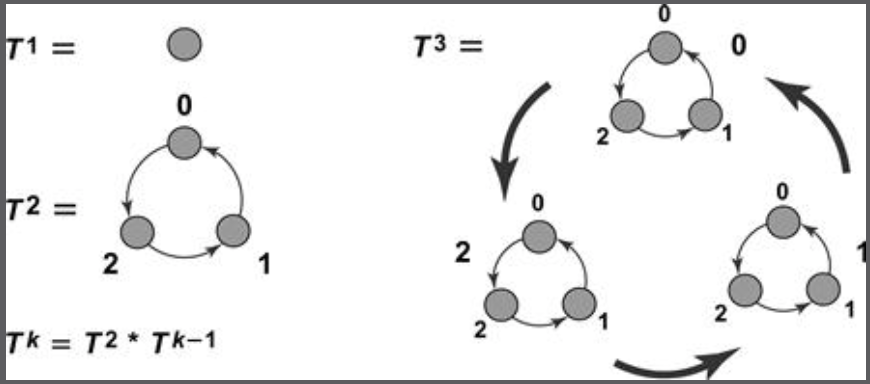
表示n个线程的有界时间戳。注意到它和一致性哈希的区别——它是一个递归的环形结构,所以这样每次只需要移动1个数字。也可以把有界时间戳看作是一个三进制系统。
比如3个线程中,如果线程1和2都在环1上,那么线程3如果想要分配一个新的时间戳就需要转移到环0上。如果线程1和线程2想要分配,它们只需要在这个环内循环。假设线程3一直得到分配,那么它的时间戳不会变化,因为没有更大的时间戳了。
用形式化的说法是,如果线程1和2的时间戳(也可以说是令牌)在同一个子图里,那么线程3的时间戳应该移动到一个支配
的子图里。
自旋锁和争用
前面介绍的过滤锁和面包房算法都是自旋锁,也就是说存在线程的自旋(忙等待)。如果获取锁的延迟较低,可以这样做——反之,应该采用阻塞的方式,也就是把线程挂起来让出CPU,这其实是一种tradeoff(线程的切换也有开销)。在OS中,也可以综合起来,先自旋再阻塞。
在实际中,我们可能不会使用过滤锁,面包房算法这样基于内存的设计。其原因之一是它的空间开销是和线程数相关的。不过,如果一个互斥锁想要实现无饥饿,它的空间下界必须是这么多,即使是使用CAS(比如后面的CLH锁):
Danny Hendler, Faith Fich, and Nir Shavit have extended the work of Jim Burns and Nancy Lynch to show that any starvation-free mutual exclusion algorithm requires
space, even if strong operations such as
getAndSet()orcompareAndSet()are used, implying that all the queue-lock algorithms considered here are space-optimal.
基于内存的算法基本上依赖于程序执行的顺序,也就是说必须施加volatile这样的可见性。这个开销和CAS比较接近,因此直接使用CAS更好。
Test-And-Set Locks
一般也叫做TAS锁,在Java的原子类中对应getAndSet方法。如果仔细看一下Java内部原子类的实现,可以发现它是基于CAS实现的。
TAS锁非常简单,就是直接判断一个原子的布尔类即可。因为这个操作具有原子性,所以一切都可以work。但是,这里我们需要在循环体里写CAS操作,这显然是非常大的开销。理所应当的,我们会想到一个变种,即TTAS锁(测试-测试-设置),它避免了直接使用TAS做判断的开销,在外层加上了一个单纯判断锁状态的循环。
class TTASlock {
AtomicBoolean state = new AtomicBoolean(false);
void lock() {
while (true) {
while (state.get()) {}
if (!state.getAndSet(true))
return;
}
}
一般来说,程序员可能都能想到TTAS这一层,但是它依然不是性能最佳的。原因可以这样说明:
我们可以把CPU的总线结构看做是一种微型以太网(这个比喻非常有趣)。每个CPU可以对总线进行广播,但总线每个时刻都是独占的(不能同时广播多个)。所有的CPU可以监听广播。如果一个CPU在Cache中找不到某个值,就会在总线上进行广播——如果别的CPU中的Cache包含这个值,会把对应的值和地址也进行广播来响应。最坏的情况是,如果所有缓存没有这个值,只能从内存中读取。getAndSet本质是一个总线上的广播:它和volatile类似,会禁用缓存来保证数据一致性。注意它禁用的是所有线程的缓存,而不只是自己的——这将导致所有的CPU都要重新从总线上读取最新的值。
在TTAS锁中,虽然可以先通过读取值来避免循环CAS,但一旦某个线程释放锁,每个自旋等待锁的线程都会开始CAS。前面已经提到,广播是独占的,具有delay特性,所以TTAS的锁释放会导致所有线程在总线上排队。这被称为总线风暴。解决上述问题的策略叫做本地自旋(local spinning)。TTAS做到了在持有锁时本地自旋,但是在释放锁时依然存在问题。
这里关于现代计算机处理器架构的描述是非常简单的,没有提到一些更深入的概念,比如缓存协议。
指数后退
争用(contention)代表着多个线程同时竞争一把锁。一个重要的结论是,对于TTAS锁而言,如果其他线程在读锁和CAS之间获得了锁,那么很可能存在高争用。
对于高争用的锁,可以使用后退机制来给正在竞争的线程结束的机会。一个原则是,失败尝试的次数越多,那么发生争用的可能性越高,线程需要后退的时间越长(为了避免意外一般设置一个最大上限)。这被称为指数后退(Exponential Backoff)。
后退机制蕴含的思想是非常常见的,例如在Raft协议中,我们使用随机时间戳来避免竞选的冲突。
Backoff锁易于实现,不过最优解依赖于具体的机器配置(这意味着调优)。例如,Linux内核使用的锁算法,Ticket Lock(该算法有点像Lamport面包房算法的一个变种),就采用了指数后退:
type lock = record
next_ticket : unsigned integer := 0
now_serving : unsigned integer := 0
procedure acquire_lock (L : ^lock)
my_ticket : unsigned integer := fetch_and_increment (&L->next_ticket)
// returns old value; arithmetic overflow is harmless
loop
pause (my_ticket - L->now_serving)
// consume this many units of time
// on most machines, subtraction works correctly despite overflow
if L->now_serving = my_ticket
return
procedure release_lock (L : ^lock)
L->now_serving := L->now_serving + 1
队列锁
基于TTAS的后退锁仍然存在一定的问题:
- 缓存一致流量(Cache-coherence Traffic)。毕竟仍然是基于TTAS,无法抹去这个根本特点。
- 临界区利用率低。
而队列锁可以解决这些问题,也就是说它是一种比较完美的针对缓存一致性的解决方案。此外,队列锁还具有公平性。
原理上,队列锁就是所有线程进行排队。我们可以把这个过程抽象成一个链表(当然也可以是数组)——每个线程只需要检查其前驱是否已经完成。这样做可以有效避免了缓存一致流量,因为每个线程CAS的对象不同。
基于数组的锁
该锁实现被称为ALock——基于作者Tom Anderson的名字命名的。这是一个基于环形数组实现的队列锁。显然,数组长度应该不小于最大并发线程个数。数组的每个位置被称为一个槽位(slot)。
一开始锁会由第一个线程获得。之后每个线程在释放锁的时候,还要将锁赋予下一个线程(即设置它的槽位为true)。此外,还需要一个ThreadLocal变量存储线程的槽位。每个线程只需要在自己的槽位上自旋。书中代码如下:
public class ALock implements Lock {
// thread-local variable
ThreadLocal<Integer> mySlotIndex = new ThreadLocal<Integer> (){
protected Integer initialValue() {
return 0;
}
};
AtomicInteger tail;
volatile boolean[] flag;
int size;
/**
* Constructor
* @param capacity max number of array slots
*/
public ALock(int capacity) {
size = capacity;
tail = new AtomicInteger(0);
flag = new boolean[capacity];
flag[0] = true;
}
public void lock() {
int slot = tail.getAndIncrement() % size;
mySlotIndex.set(slot);
while (! flag[mySlotIndex.get()]) {}; // spin
}
public void unlock() {
flag[mySlotIndex.get()] = false;
flag[(mySlotIndex.get() + 1) % size] = true;
}
...
}
这里有一个细节是环形数组的volatile修饰。我们知道,数组是一个引用变量,这并不能保证数组元素的可见性。所以书中代码可能存在一点问题。不过,这里是否需要数组元素具有可见性呢?
我个人觉得是不需要的(当然也经过了测试)。因为这里和过滤锁不同,每次只有一个线程的flag可以设置为true。此时并不存在竞态条件,只需要等待这个值在两个线程的CPU缓存上同步即可。
看起来ALock算法已经比较完美了,但其实还有许多缺点。其中之一是假共享(false share)问题——这个在计算机组成原理中属于缓存的重点内容之一。这主要是由于缓存行通常设置得比较大,因而会导致一个数据周围的数据一并被作为一个整体。当我们设置一个值的缓存无效时,会产生连锁反应。解决假共享的方法就是对齐(padding),这个了解C/C++的人都非常熟悉了。
此外,ALock还有一个缺点:需要提前确定线程的数量,并且这个数量是固定的,即使这个锁最后实际只有几个线程竞争,但是依然会采用这么多内存空间。这是由数组的特点决定的。
CLH锁
ALock的优化版本是CLH锁,这是一种真正被广泛实用的锁设计,比如 AQS 就是其变种。CLH锁是由Craig,Landin和Hagersten这三位大牛提出的。
CLH锁通过虚拟链表来避免内存开销。之所以说是虚拟的,是因为它的Node本身不需要有指针,只需要线程持有它的前驱Node即可。这一点比较微妙。
整个代码比较简单,除了解锁部分有一个设置自己线程的节点为前驱的操作:
/**
* Craig-Hagersten-Landin Lock
* @author Maurice Herlihy
*/
public class CLHLock implements Lock {
// most recent lock holder
AtomicReference<QNode> tail;
// thread-local variables
ThreadLocal<QNode> myNode, myPred;
/**
* Constructor
*/
public CLHLock() {
tail = new AtomicReference<QNode>(new QNode());
// initialize thread-local variables
myNode = new ThreadLocal<QNode>() {
protected QNode initialValue() {
return new QNode();
}
};
myPred = new ThreadLocal<QNode>() {
protected QNode initialValue() {
return null;
}
};
}
public void lock() {
QNode qnode = myNode.get(); // use my node
qnode.locked = true; // announce start
// Make me the new tail, and find my predecessor
QNode pred = tail.getAndSet(qnode);
myPred.set(pred); // remember predecessor
while (pred.locked) {} // spin
}
public void unlock() {
QNode qnode = myNode.get(); // use my node
qnode.locked = false; // announce finish
myNode.set(myPred.get()); // reuse predecessor
}
static class QNode { // Queue node inner class
public boolean locked = false;
}
}
这其实就是我们前面说的,特殊的回收协议。在当前节点释放锁时,它仍然被它的后继节点使用(轮询)而不能被回收,所以这里必须要用一个新的节点。但如果new一个Node的话,很可能就导致内存泄露了,所以重新利用前驱节点作为线程再次加锁的节点。此外,因为此时前驱依然被自己引用,所以不必担心被回收。
CLH锁可能的缺点就是对于无Cache的NUMA( Non-Uniform Memory Access)架构不友好。如果两个线程代表的节点在内存中的距离比较远,那么性能不太好。
MCS锁
MCS锁可能是CLH锁对于NUMA的优化。CLH锁唯一的非本地存储就是前驱节点的指针——因此MCS反其道而行之,在每个节点内存储它的后继结点。因为后继是在Node里,所以MCS只有一个线程本地变量。
我们可以把它和CLH锁的区别看作是一种通知和轮询的区别:CLH锁通过线程保存的前驱节点信息来不断主动的询问这个节点是否释放锁,MCS锁通过线程的本地节点信息来自旋,直到前驱节点将锁传给线程的(后继)节点,这个过程是通过共享内存实现的消息传递。
注意到,MCS锁只能用后继节点而不是前驱节点这样做,因为解锁时需要设置后继节点。不过也并非完全不可能——可以通过后继节点延迟检查的方式。这是后面TOLock的雏形。
MCS锁需要注意的是释放锁的过程,这里有额外的CAS操作。主要是判断这个节点是否为等待链唯一的节点——如果是,那么就需要移除这个节点。需要考虑到的边界情况是另一个线程刚刚插入到等待链。这里的写法很有技巧,先进行if再进行while循环(而不是直接while),可以思考一下为什么这样做。
public void unlock() {
QNode qNode = myNode.get();
if (qNode.next == null) {
if (tail.compareAndSet(qNode, null)) {
return;
}
while (qNode.next == null) {
}
}
qNode.next.locked = false;
qNode.next = null;
}
MCS锁虽然弥补了CLH锁的不足,但代价是额外的读写和CAS。
时限队列锁
Java的Lock接口有一个tryLock方法,这就是一个时限(timeout):调用者请求锁等待的最大时间。
对于队列锁而言,从队列移出一个节点比较麻烦。因此,一种较好的方法是懒惰策略:当线程超时的时候进行标记,然后由后继者根据标记来判断是否前驱节点已经放弃。然后,后继就可以重新在它的前驱的前驱上自旋。书中提到,这种方式有一个额外的好处:后继可以回收前驱节点。这为什么是一个优势呢?我仔细想了一下,应该是因为CLH锁的节点回收总是在线程重新更新前驱节点时(而且考虑到GC的安全点,回收时机可能还在自旋完成进入临界区之后),那么如果这个线程本身不重新申请锁但也不释放,则前驱节点也永远无法回收。相反,超时锁任何的后继线程都可以回收前面超时的节点。
Bill Scherer和Michael Scott提出了超时锁(TOLock)。超时锁的实现其实很有技巧。类似于MCS锁,它由节点而不是线程保存前驱节点的信息,不过这也是懒惰策略必须的。但超时锁的本质仍然是CLH锁而不是MCS,因为它实质上是把传递锁变成了传递前驱。而对于锁的自旋或者说轮询,只是前驱节点信息中的一个部分。
这么说可能有点抽象。在超时锁中,线程每次请求锁都要创建一个新的节点插入链中——但其实并没有形成节点链,因为节点的前驱字段pred依然设置null(不过全局的tail指针需要更新)。每个节点实际上都是在前驱节点的pred上自旋——直到这个字段为AVAILABLE,或者是已经超时的节点。符号AVAILABLE代表一个全局不被使用的静态节点。只要节点释放了锁,就指向这个特殊节点。
超时节点的标记其实就是pred设置为它的前驱节点。这样节省了一个标记位。节点超时以后需要检查是否为队列末尾:
if (!tail.compareAndSet(qNode, myPred)) {
qNode.pred = myPred;
}
感觉这个CAS不是必须的,不过能尽早回收总是好的。
等待链的回收时机在后继的线程跳过超时节点进入临界区。一旦设置了它的前驱指向前驱的前驱(即中间存在超时节点),那么就相当于这些节点已经不可达,会在下次GC时回收。
public class TOLock implements Lock{
static QNode AVAILABLE = new QNode();
AtomicReference<QNode> tail;
ThreadLocal<QNode> myNode;
public TOLock() {
tail = new AtomicReference<QNode>(null);
// thread-local field
myNode = new ThreadLocal<QNode>() {
protected QNode initialValue() {
return new QNode();
}
};
}
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
long startTime = System.nanoTime();
long patience = TimeUnit.NANOSECONDS.convert(time, unit);
QNode qnode = new QNode();
myNode.set(qnode); // remember for unlock
qnode.pred = null;
QNode pred = tail.getAndSet(qnode);
if (pred == null || pred.pred == AVAILABLE) {
return true; // lock was free; just return
}
while (System.nanoTime() - startTime < patience) {
QNode predPred = pred.pred;
if (predPred == AVAILABLE) {
return true;
} else if (predPred != null) { // skip predecessors
pred = predPred;
}
}
// timed out; reclaim or abandon own node
if (!tail.compareAndSet(qnode, pred))
qnode.pred = pred;
return false;
}
public void unlock() {
QNode qnode = myNode.get();
if (!tail.compareAndSet(qnode, null))
qnode.pred = AVAILABLE;
}
// any class that implements lock must provide these methods
public void lock() {
try {
tryLock(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
public Condition newCondition() {
throw new java.lang.UnsupportedOperationException();
}
public boolean tryLock() {
try {
return tryLock(0, TimeUnit.NANOSECONDS);
} catch (InterruptedException ex) {
return false;
}
}
public void lockInterruptibly() throws InterruptedException {
throw new java.lang.UnsupportedOperationException();
}
static class QNode { // Queue node inner class
public QNode pred = null;
}
}
相比CLH锁形成的等待链,超时锁有更加隐式的等待链,和显式的超时链。那些超时的线程就像是金蝉脱壳一般在原先的等待链中留下了一个待清理的超时节点。这个清理的过程其实也是一种线程协助。
TOLock具有CLHLock大多数优点:在缓存的存储单元上进行本地自旋以及对锁空闲的快速检测,也有BackoffLock的无等待超时特性。该锁的缺点在于,每次锁访问都需要分配一个新节点以及在访问临界区之前可能不得不回溯一个超时节点链。
AQS实现
AQS(AbstractQueuedSynchronizer)是JUC的核心,它是诸如ReentrantLock,Semaphore等Java重要并发结构的底层实现。AQS内部使用CLH锁的原理实现同步队列的管理。不过,CLH 锁是一个自旋队列锁,而 AQS 是一个阻塞同步器,所以 AQS 只借鉴了 CLH 锁的思想。
Doug Lea大神关于 AQS 有一篇对应的论文,可以在并发编程网看到他的翻译。
The java.util.concurrent Synchronizer Framework 中文翻译版
我觉得总体来说比直接阅读源码要简单许多。同步器核心的伪代码如下:
// acquire
while (synchronization state does not allow acquire) {
enqueue current thread if not already queued;
possibly block current thread;
}
dequeue current thread if it was queued;
//release
update synchronization state;
if (state may permit a blocked thread to acquire){
unblock one or more queued threads;
}
简单而言,AQS需要实现3个功能:
- 同步状态的原子性管理
- 线程的阻塞与解除阻塞
- 队列的管理
第一个通过volatile的state变量保证;第二个通过LockSupport(无法使用synchronized精确控制线程的唤醒和阻塞)。最后,Doug Lea大神解释了为什么使用CLH锁而不是MCS锁,因为CLH锁更容易实现取消和超时的功能。
AQS本身的字段并不多,其核心就是3个:head,tail和state。我们在 CLH 里只有tail,没有head,因为我们不需要知道当前持有锁的节点。但是 AQS 是需要查询当前持有锁的节点的,所以head必不可少。在同步器中,state可能是线程重入的次数,也可能是信号量中剩余的许可次数。
接下来,我们可以看一下 AQS 的 Node 究竟有哪些字段:
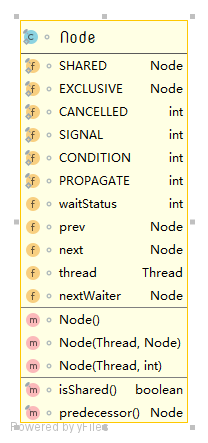
其中大写的相当于是枚举值或者常量。关于Node可能会有这样一些疑问:
- 为什么AQS是双向链表,而CLH锁是单向的(甚至是虚拟的)?
- 这4种状态的含义是什么?
- 为什么有了
next还需要nextWaiter?
第一个问题Doug Lea大神已经解释了:因为需要实现取消和超时这样的功能。此外,由于AQS是阻塞的,一个节点需要显式唤醒(unpark)其后继。
状态位的设计在前面的超时锁中我们已经看到了。这4种状态中可能让人迷惑的是SIGNAL和PROPAGATE:SIGNAL 代表线程将会唤醒它的后继。在shouldParkAfterFailedAcquire方法中,它会先判断是否已经把前驱节点设置为SIGNAL,如果设置了才允许线程阻塞。这是为了让前驱节点能够在得到资源后,保证会唤醒后继。PROPAGATE 和共享模式有关,如果你查找它的引用,你会发现它没有被用到的地方——但实际上,它被通过waitStatus<0隐式使用了。在setHeadAndPropagate中,这个方法在节点得到资源后,并且剩余资源下调用。
其实这个nextWaiter的名字略有些奇怪。nextWaiter连接的是AQS的条件队列,如果节点没有条件变量,那么代表SHARED或者EXCLUSIVE。
AQS 是一个抽象类(废话),它其中包含了几个待实现的方法:
tryAcquire(int arg)tryRelease(int arg)tryAcquireShared(int arg)tryReleaseShared(int arg)isHeldExclusively()
这几个方法不是抽象的(只是抛出未实现异常),因为共享模式不需要实现独占模式的方法,反之亦然。这些方法定义了资源访问的方法,其内容主要是实现状态state控制。以ReentrantLock为例,我们都知道它的lock就是acquire(1)(不过在ReentrantLock默认非公平模式下,允许线程先CAS抢占资源)。
可以看一下ReentrantLock公平模式下的tryAcquire:
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
hasQueuedPredecessors和公平性判断有关,其他就是判断线程是否可以抢占锁,若已经持有锁,则重入时设置计数。
AQS提供的模板方法为自己的核心流程所调用:
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
在互斥模式下,首先调用子类自定义的获取资源方法,如果不成功则调用addWaiter将当前线程作为一个节点插入等待队列。因为后续acquire会一直阻塞直到得到锁,所以这里不会多次插入。阻塞定义在acquireQueued中,这个方法值得一提:
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
首先如果节点是head的后继,此时又调用tryAcquire成功,说明资源即state的所有权拿到了,可以修改自己为head并结束自旋。否则要进行一次shouldParkAfterFailedAcquire的判断:这个方法前面已经说了,比较简单,主要是判断前驱节点是否设置了SIGNAL,如果没有就CAS设置,如果前驱超时顺便清理一下。不过这里有可能CAS前驱的状态失败,此时返回false,但无关紧要,因为在acquireQueued有一个大循环。parkAndCheckInterrupt很简单就是直接阻塞当前线程。
最后这个acquireQueued的语义需要注意。它代表的是线程是否被中断了。
release与此类似,一些小的细节比如这里的判断条件h != null是为了避免重复处理(我们前面提到过线程协助)。核心在unparkSuccessor方法:
private void unparkSuccessor(Node node) {
/*
* If status is negative (i.e., possibly needing signal) try
* to clear in anticipation of signalling. It is OK if this
* fails or if status is changed by waiting thread.
*/
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
/*
* Thread to unpark is held in successor, which is normally
* just the next node. But if cancelled or apparently null,
* traverse backwards from tail to find the actual
* non-cancelled successor.
*/
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
这里依然是循环刨除超时节点,直到找到了状态有效的,然后调用唤醒。注意这里只唤醒一次。
你可以看一下之前的伪代码,基本上是一样的。
分析完了互斥模式,接下来看一下共享模式。这个模式稍微有些不同。我们可能首先会想到,多个等待队列里的节点都可以获得资源怎么办?
共享模式下的函数返回值有特殊的语义,即表示剩余资源的数量。我们还是从核心方法开始:
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
这里改名了封装叫做doAcquireShared和doReleaseShared。其中:
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
可以看到依然是添加节点入队,检查中断,是否可以park之类。但是,这里多了一块逻辑:如果它得到了资源(剩余资源大于等于0,这里不用担心0的问题),它会调用setHeadAndPropagate。这个方法从名字我们大致可以猜出它的意图:
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);
/*
* Try to signal next queued node if:
* Propagation was indicated by caller,
* or was recorded (as h.waitStatus either before
* or after setHead) by a previous operation
* (note: this uses sign-check of waitStatus because
* PROPAGATE status may transition to SIGNAL.)
* and
* The next node is waiting in shared mode,
* or we don't know, because it appears null
*
* The conservatism in both of these checks may cause
* unnecessary wake-ups, but only when there are multiple
* racing acquires/releases, so most need signals now or soon
* anyway.
*/
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
doReleaseShared();
}
}
这里先判断之前的head状态,然后判断自己刚刚设置的head(这里为什么不用node而是head你可以思考一下,因为其他线程)状态,如果有效则判断节点的后继是否可以唤醒,也就是doReleaseShared所做的工作。所以共享模式是非常有趣的,它既获取资源,也做了释放资源时的唤醒。这就解决了我们前面说的问题,假设资源有多个,那么不论头结点是获取还是释放都会唤醒后面等待的节点(只要资源足够)。
private void doReleaseShared() {
/*
* Ensure that a release propagates, even if there are other
* in-progress acquires/releases. This proceeds in the usual
* way of trying to unparkSuccessor of head if it needs
* signal. But if it does not, status is set to PROPAGATE to
* ensure that upon release, propagation continues.
* Additionally, we must loop in case a new node is added
* while we are doing this. Also, unlike other uses of
* unparkSuccessor, we need to know if CAS to reset status
* fails, if so rechecking.
*/
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
许多博客都没有讲清楚这个PROPAGATE的用途。可以看到,它会将head的状态设置为PROPAGATE,但是似乎并没有用到?秘密是setHeadAndPropagate里,用的是waitStatus < 0。也就是说,设置为PROPAGATE代表你可以代替这个节点唤醒它的后继。这是因为在共享模式下,可能多个线程都得到了资源,然后进入了setHeadAndPropagate。但是我插队了,得保证这个唤醒机制不能乱啊,所以每个线程都会去设置head。
AQS 分为等待队列和条件队列。AQS提供了一个ConditionObject,这个对象主要是基于AQS的nextWaiter来实现Condition接口。这个就比较简单了,一般实现了newCondition方法的对象,比如ReentrantLock,就是直接new一个这个对象。所以,每个锁都可能有多个条件队列。由于条件队列只需要按照条件触发,所以整体比较简单,简单看一下如何实现的:
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
首先添加节点,之后调用fullyRelease(本质上还是release)释放节点持有的锁。然后如果节点不在等待队列(其实我的叫法有点问题,应该是同步队列)上,那么就阻塞该节点。signal会把它从条件队列移到等待队列,这样就会跳出循环重新获得锁。这里建议看一下论文原文。
到这里差不多AQS的基本原理就理清楚了,因为时间有限,一些诸如超时、线程中断的部分就暂时略过了,有时间再续上。
组合锁
Spin-lock algorithms impose trade-offs. Queue locks provide first-come-first-served fairness, fast lock release, and low contention, but require nontrivial protocols for recycling abandoned nodes. By contrast, backoff locks support trivial timeout protocols, but are inherently not scalable, and may have slow lock release if timeout parameters are not well-tuned.
一个基本的观察是,队列锁只需要在局部进行锁切换。这会自然想到一种组合的策略,那就是限制等待链的长度,其他的线程均采取指数后退。
组合锁维护一个等待链数组。每次节点请求锁都随机分配一个节点(这说明组合锁不是公平的)。节点有4种状态:空闲,等待,放弃,释放锁。类似于超时锁,组合锁对于超时节点的处理也是惰性策略,在放弃节点的时候标记。在重用该节点时,如果节点是放弃状态,除了更新前缀外还要设置节点的状态为空闲,以便于下次被重新分配。
组合锁分为获取节点,入队,等待锁3个阶段。获取节点其实是另一个争用过程。组合锁的缺点是无并发时需要额外的操作。解决的方法是提供了一个快速路径(Fast Path),这个算法是由Lamport提出来的。
