


分享内容及技术栈
本文将分享结合羚珑项目自身情况搭建的测试工作流的实践经验,针对于 Node.js 服务端应用的工具方法和接口的单元测试、集成测试等。实践经验能给你带来:
- 利用 Jest 搭建一套开发体验友好的测试工作流。
- 书写一个高效的单元测试用例,及集成测试用例。
- 利用封装技术实现模块间的分离,简化测试代码。
- 使用 SuperTest 完成应用进程与测试进程的合并。
- 创建高效的数据库内存服务,实现彼此隔离的测试套件运行机制。
- 了解模拟(Mock)、快照(snapshot)与测试覆盖率等功能的使用。
- 理解 TDD 与 BDD。
- ...
文中涉及的基础技术栈有(需要了解的知识):
- TypeScript: JavaScript 语言的超集,提供类型系统和新 ES 语法支持。
- SuperTest: HTTP 代理及断言工具。
- MongoDB: NoSQL 分布式文件存储数据库。
- Mongoose: MongoDB 对象关系映射操作库(ORM)。
- Koa: 基础 Web 应用程序框架。
- Jest: 功能丰富的 JavaScript 测试框架。
- lodash: JavaScript 工具函数库。
关于羚珑

羚珑是京东旗下智能设计平台,提供在线设计服务,主要包括大类如:
图片设计:快速合成广告图,主图,公众号配图,海报,传单,物流面单等线上与线下设计服务。
视频设计:快速合成主图视频,抖音短视频,自定义视频等设计服务。
页面设计:快速搭建活动页,营销页,小游戏,小程序等设计服务。
实用工具:批量抠图、改尺寸、配色、加水印等。
基于行业领先技术,为商家、用户提供丰富的设计能力,实现快速产出。
羚珑架构及测试框架选型
先介绍下羚珑项目的架构,方便后续的描述和理解。羚珑项目采用前后端分离的机制,前端采用 React Family 的基础架构,再加上 Next.js 服务端渲染以提供更好的用户体验及 SEO 排名。后端架构则如下图所示,流程大概是浏览器或第三方应用访问项目 Nginx 集群,Nginx 集群再通过负载均衡转发到羚珑应用服务器,应用服务器再通过对接外部服务或内部服务等,或读写缓存、数据库,逻辑处理后通过 HTTP 返回到前端正确的数据。
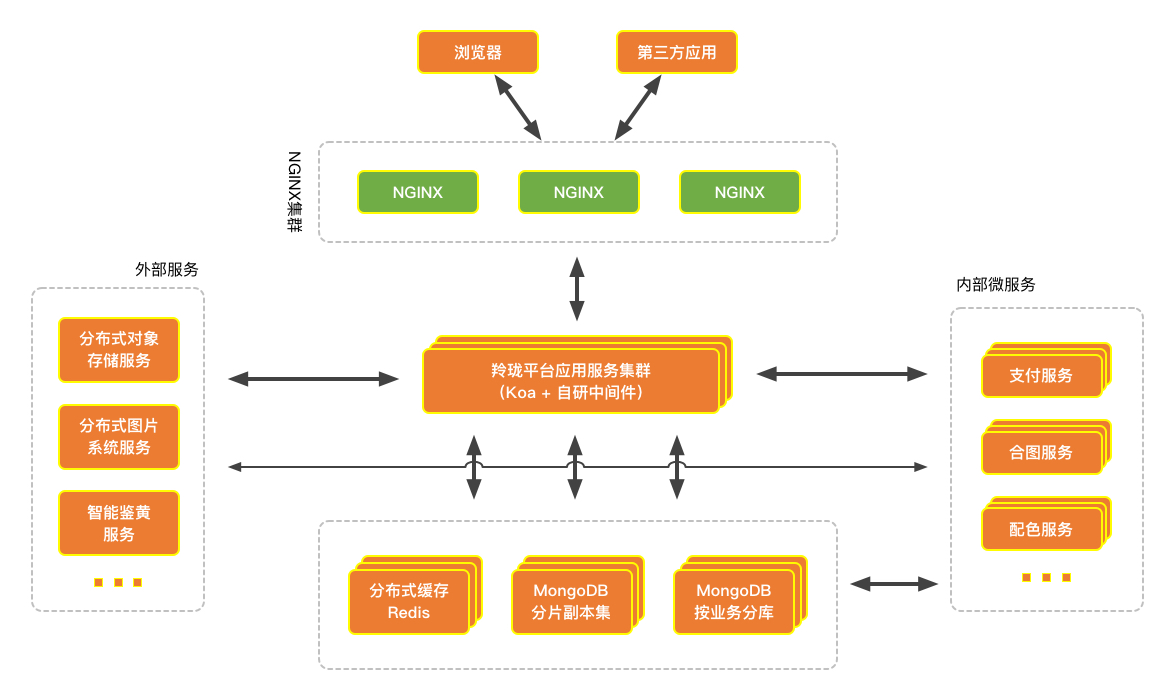
主流测试框架对比
接下来,根据项目所需我们对比下当下 Node.js 端主流的测试框架。
| Jest | Mocha | AVA | Jasmine | |
|---|---|---|---|---|
| GitHub Stars | 28.5K | 18.7K | 17.1K | 14.6K |
| GitHub Used by | 1.5M | 926K | 46.6K | 5.3K |
| 文档友好 | 优秀 | 良好 | 良好 | 良好 |
| 模拟功能(Mock) | 支持 | 外置 | 外置 | 外置 |
| 快照功能(Snapshot) | 支持 | 外置 | 支持 | 外置 |
| 支持 TypeScript | ts-jest | ts-mocha | ts-node | jasmine-ts |
| 详细的错误输出 | 支持 | 支持 | 支持 | 未知 |
| 支持并行与串行 | 支持 | 外置 | 支持 | 外置 |
| 每个测试进程隔离 | 支持 | 不支持 | 支持 | 未知 |
*文档友好:文档结构组织有序,API 阐述完整,以及示例丰富。
分析:
- 之所以 Mocha GitHub 使用率很高,很有可能是因为出现的最早(2011年),并由 Node.js 届顶级开发者 TJ 领导开发的(后转向Go语言),所以早期项目选择了 Mocha 做为测试框架,而 Jest、AVA 则是后起之秀(2014年),并且 Stars 数量都在攀升,预计新项目都会在这两个框架中挑选。
- 相比外置功能,内置支持可能会与框架融合的更好,理念更趋近,维护更频繁,使用更省心。
- Jest 模拟功能可以实现方法模拟,定时器模拟,模块/文件依赖模拟,在实际编写测试用例中,模拟模块功能(mock modules)被常常用到,它可以确保测试用例快速响应并且不会变化无常。下文也会谈到如何使用它,为什么需要使用它。
综上,我们选择了 Jest 作为基础测试框架。
从0到1落地实践
Jest 框架配置
接下来,我们从 0 到 1 开始实践,首先是搭建测试流,虽然 Jest 可以达到开箱即用,然而项目架构不尽相同,大多时候需要根据实际情况做些基础配置工作。以下是根据羚珑项目提取出来的简化版项目目录结构,如下。
├─ dist # TS 编译结果目录
├─ src # TS 源码目录
│ ├─ app.ts # 应用主文件,类似 Express 框架的 /app.js 文件
│ └─ index.ts # 应用启动文件,类似 Express 框架的 /bin/www 文件
├─ test # 测试文件目录
│ ├─ @fixtures # 测试固定数据
│ ├─ @helpers # 测试工具方法
│ ├─ module1 # 模块1的测试套件集合
│ │ └─ test-suite.ts # 测试套件,一类测试用例集合
│ └─ module2 # 模块2的测试套件集合
├─ package.json
└─ yarn.lock
这里有两个小点:
- 以
@开头的目录,我们定义为特殊文件目录,用于提供些测试辅助工具方法、配置文件等,平级的其他目录则是测试用例所在的目录,按业务模块或功能划分。以@开头可以清晰的显示在同级目录最上方,很容易开发定位,凑巧也方便了编写正则匹配。 test-suite.ts是项目内最小测试文件单元,我们称之为测试套件,表示同一类测试用例的集合,可以是某个通用函数的多个测试用例集合,也可以是一个系列的单元测试用例集合。
首先安装测试框架。
yarn add --dev jest ts-jest @types/jest
因为项目是用 TypeScript 编写,所以这里同时安装 ts-jest @types/jest。然后在根目录新建 jest.config.js 配置文件,并做如下小许配置。
module.exports = {
// preset: 'ts-jest',
globals: {
'ts-jest': {
tsConfig: 'tsconfig.test.json',
},
},
testEnvironment: 'node',
roots: ['<rootDir>/src/', '<rootDir>/test/'],
testMatch: ['<rootDir>/test/**/*.ts'],
testPathIgnorePatterns: ['<rootDir>/test/@.+/'],
moduleNameMapper: {
'^~/(.*)': '<rootDir>/src/$1',
},
}
preset: 预设测试运行环境,多数情况设置为 ts-jest 即可,如果需要为 ts-jest 指定些参数,如上面指定 TS 配置为 tsconfig.test.json,则需要像上面这样的写法,将 ts-jest 挂载到 globals 属性上,更多配置可以移步其官方文档,这里。
testEnvironment: 基于预设再设置测试环境,Node.js 需要设置为 node,因为默认值为浏览器环境 jsdom。
roots: 用于设定测试监听的目录,如果匹配到的目录的文件有所改动,就会自动运行测试用例。<rootDir> 表示项目根目录,即与 package.json 同级的目录。这里我们监听 src 和 test 两个目录。
testMatch: Glob 模式设置匹配的测试文件,当然也可以是正则模式,这里我们匹配 test 目录下的所有文件,匹配到的文件才会当做测试用例执行。
testPathIgnorePatterns: 设置已经匹配到的但需要被忽略的文件,这里我们设置以 @ 开头的目录及其所有文件都不当做测试用例。
moduleNameMapper: 这个与 TS paths 和 Webpack alias 雷同,用于设置目录别名,可以减少引用文件时的出错率并且提高开发效率。这里我们设置以 ~ 开头的模块名指向 src 目录。
第一个单元测试用例
搭建好测试运行环境,于是便可着手编写测试用例了,下面我们编写一个接口单元测试用例,比方说测试首页轮播图接口的正确性。我们将测试用例放在 test/homepage/carousel.ts 文件内,代码如下。
import { forEach, isArray } from 'lodash’
import { JFSRegex, URLRegex } from '~/utils/regex'
import request from 'request-promise'
const baseUrl = 'http://ling-dev.jd.com/server/api'
// 声明一个测试用例
test('轮播图个数应该返回 5,并且数据正确', async () => {
// 对接口发送 HTTP 请求
const res = await request.get(baseUrl + '/carousel/pictures')
// 校验返回状态码为 200
expect(res.statusCode).toBe(200)
// 校验返回数据是数组并且长度为 5
expect(isArray(res.body)).toBe(true)
expect(res.body.length).toBe(5)
// 校验数据每一项都是包含正确的 url, href 属性的对象
forEach(res.body, picture => {
expect(picture).toMatchObject({
url: expect.stringMatching(JFSRegex),
href: expect.stringMatching(URLRegex),
})
})
})
编写好测试用例后,第一步需要启动应用服务器:
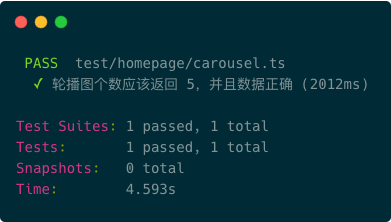
第二步运行测试,在命令行窗口输入:npx jest,如下图可以看到用例测试通过。
当然最佳实践则是把命令封装到 package.json 里,如下:
{
"scripts": {
"test": "jest",
"test:watch": "jest --watch",
}
}
之后便可使用 yarn test 来运行测试,通过 yarn test:watch 来启动监听式测试服务。
SuperTest 增强
虽然上面已经完成基本的测试流程开发,但很明显的一个问题是每次运行测试,我们需要先启动应用服务,共启动两个进程,并且需要提前配置 ling-dev.jd.com 指向 127.0.0.1:3800,这是一个繁琐的过程。所以我们引入了 SuperTest,它可以把应用服务集成到测试服务一起启动,并且不需要指定 HTTP 请求的主机地址。
我们封装一个公共的 request 方法,将它放在 @helpers/agent.ts 文件内,如下。
import http from 'http'
import supertest from 'supertest'
import app from '~/app'
export const request = supertest(http.createServer(app.callback()))
解释:
- 使用
app.callback()而不是app.listen(),是因为它可以将同一个app同时作为 HTTP 和 HTTPS 或多个地址。app.callback()返回适用于http.createServer()方法的回调函数来处理请求。 - 之后,
http.createServer()创建一个未监听的 HTTP 对象给 SuperTest,当然 SuperTest 内部也会调用listen(0)这样的特殊端口,让操作系统提供可用的随机端口来启动应用服务器。
所以上面的测试用例我们可以改写成这样:
import { forEach, isArray } from 'lodash’
import { JFSRegex, URLRegex } from '~/utils/regex'
// 引入公共的 request 方法
import { request } from '../@helpers/agent'
test('轮播图个数应该返回 5,并且数据正确', async () => {
const res = await request.get('/api/carousel/pictures')
expect(res.status).toBe(200)
// 同样的校验...
})
因为 SuperTest 内部已经帮我们包装好了主机地址并自动启动应用服务,所以请求接口时只需书写具体的接口,如 /api/carousel/pictures,也只需运行一条命令 yarn test,就可以完成整个测试工作。
数据库内存服务
项目架构中可以看到数据库使用的是 MongoDB,在测试时,几乎所有的接口都需要与数据库连接。此时可通过环境变量区分并新建 test 数据库,用于运行测试用例。有点不好的是测试套件执行完成后需要对 test 数据库进行清空,以避免脏数据影响下个测试套件,尤其是在并发运行时,需要保持数据隔离。
使用 MongoDB Memory Server 是更好的选择,它会启动独立的 MongoDB 实例(每个实例大约占用非常低的 7MB 内存),而测试套件将运行在这个独立的实例里。假如并发为 3,那就创建 3 个实例分别运行 3 个测试套件,这样可以很好的保持数据隔离,并且数据都保存在内存中,这使得运行速度会非常快,当测试套件完成后则自动销毁实例。
接下来我们把 MongoDB Memory Server 引入实际测试中,最佳方式是把它写进 Jest 环境配置里,这样只需要一次书写,自动运行在每个测试套件中。所以替换 jest.config.js 配置文件的 testEnvironment 为自定义环境 <rootDir>/test/@helpers/jest-env.js。
编写自定义环境 @helpers/jest-env.js:
const NodeEnvironment = require('jest-environment-node')
const { MongoMemoryServer } = require('mongodb-memory-server')
const child_process = require('child_process')
// 继承 Node 环境
class CustomEnvironment extends NodeEnvironment {
// 在测试套件启动前,获取本地开发 MongoDB Uri 并注入 global 对象
async setup() {
const uri = await getMongoUri()
this.global.testConfig = {
mongo: { uri },
}
await super.setup()
}
}
async function getMongoUri() {
// 通过 which mongod 命令拿到本地 MongoDB 二进制文件路径
const mongodPath = await new Promise((resolve, reject) => {
child_process.exec(
'which mongod',
{ encoding: 'utf8' },
(err, stdout, stderr) => {
if (err || stderr) {
return reject(
new Error('找不到系统的 mongod,请确保 `which mongod` 可以指向 mongod')
)
}
resolve(stdout.trim())
}
)
})
// 使用本地 MongoDB 二进制文件创建内存服务实例
const mongod = new MongoMemoryServer({
binary: { systemBinary: mongodPath },
})
// 得到创建成功的实例 Uri 地址
const uri = await mongod.getConnectionString()
return uri
}
// 导出自定义环境类
module.exports = CustomEnvironment
Mongoose 中便可以这样连接:
await mongoose.connect((global as any).testConfig.mongo.uri, {
useNewUrlParser: true,
useUnifiedTopology: true,
})
当然在 package.json 里需要禁用 MongoDB Memory Server 去下载二进制包,因为上面已经使用了本地二进制包。
"config": {
"mongodbMemoryServer": {
"version": "4.0",
// 禁止在 yarn install 时下载二进制包
"disablePostinstall": "1",
"md5Check": "1"
}
}
登录功能封装与使用
大多时候接口是需要登录后才能访问的,所以我们需要把整块登录功能抽离出来,封装成通用方法,同时借此初始化一些测试专用数据。
为了使 API 易用,我希望登录 API 长这样:
import { login } from '../@helpers/login'
// 调用登录方法,根据传递的角色创建用户,并返回该用户登录的 request 对象。
// 支持多参数,根据参数不同自动初始化测试数据。
const request = await login({
role: 'user',
})
// 使用已登录的 request 对象访问需要登录的用户接口,
// 应当是登录态,并正确返回当前登录的用户信息。
const res = await request.get('/api/user/info')
开发登录方法:
// @helpers/agent.ts
// 新添加 makeAgent 方法
export function makeAgent() {
// 使用 supertest.agent 支持 cookie 持久化
return supertest.agent(http.createServer(app.callback()))
}
// @helpers/login.ts
import { assign, cloneDeep, pick } from 'lodash'
import { makeAgent } from './agent'
export async function login(userData: UserDataType): Promise<RequestAgent> {
userData = cloneDeep(userData)
// 如果没有用户名,自动创建用户名
if (!userData.username) {
userData.username = chance.word({ length: 8 })
}
// 如果没有昵称,自动创建昵称
if (!userData.nickname) {
userData.nickname = chance.word({ length: 8 })
}
// 得到支持 cookie 持久化的 request 对象
const request: any = makeAgent()
// 发送登录请求,这里为测试专门设计一个登录接口
// 包含正常登录功能,但还会根据传参不同初始化测试专用数据
const res = await request.post('/api/login-test').send(userData)
// 将登录返回的数据赋值到 request 对象上
assign(request, pick(res.body, ['user', 'otherValidKey...']))
// 返回 request 对象
return request as RequestAgent
}
实际用例中就像上面示例方式使用。
模拟功能使用
从项目架构中可以看到项目也会调用较多外部服务。比方说创建文件夹的接口,内部代码需要调用外部服务去鉴定文件夹名称是否包含敏感词,就像这样:
import { detectText } from '~/utils/detect'
// 调用外部服务检测文件夹名称是否包含敏感词
const { ok, sensitiveWords } = await detectText(folderName)
if (!ok) {
throw new Error(`检测到敏感词: ${sensitiveWords}`)
}
实际测试的时候并不需要所有测试用例运行时都调用外部服务,这样会拖慢测试用例的响应时间以及不稳定性。我们可以建立个更好的机制,新建一个测试套件专门用于验证 detectText 工具方法的正确性,而其他测试套件运行时 detectText 方法直接返回 OK 即可,这样既保证了 detectText 方法被验证到,也保证了其他测试套件得到快速响应。
模拟功能(Mock)就是为这样的情景而诞生的。我们只需要在 detectText 方法的路径 utils/detect.ts 同级新建__mocks__/detect.ts 模拟文件即可,内容如下,直接返回结果:
export async function detectText(
text: string
): Promise<{ ok: boolean; sensitive: boolean; sensitiveWords?: string }> {
// 删除所有代码,直接返回 OK
return { ok: true, sensitive: false }
}
之后每个需要模拟的测试套件顶部加上下面一句代码即可。
jest.mock('~/utils/detect.ts')
在验证 detectText 工具方法的测试套件里,则只需 jest.unmock 即可恢复真实的方法。
jest.unmock('~/utils/detect.ts')
当然应该把 jest.mock 写在 setupFiles 配置里,因为需要模拟的测试套件占绝大多数,写在配置里会让它们在运行前自动加载该文件,这样开发就不必每处测试套件都加上一段同样的代码,可以有效提高开发效率。
// jest.config.js
setupFiles: ['<rootDir>/test/@helpers/jest-setup.ts']
// @helpers/jest-setup.ts
jest.mock('~/utils/detect.ts')
模拟功能还有方法模拟,定时器模拟等,可以查阅其文档了解更多示例。
快照功能使用
快照功能(Snapshot)可以帮我们测试大型对象,从而简化测试用例。
举个例子,项目的模板解析接口,该接口会将 PSD 模板文件进行解析,然后吐出一个较大的 JSON 数据,如果挨个校验对象的属性是否正确可能很不理想,所以可以使用快照功能,就是第一次运行测试用例时,会把 JSON 数据存储到本地文件,称之为快照文件,第二次运行时,就会将第二次返回的数据与快照文件进行比较,如果两个快照匹配,则表示测试成功,反之测试失败。
而使用方式很简单:
// 请求模板解析接口
const res = await request.post('/api/secret/parser')
// 断言快照是否匹配
expect(res.body).toMatchSnapshot()
更新快照也是敏捷的,运行命令 jest --updateSnapshot 或在监听模式输入 u 来更新。
集成测试
集成测试的概念是在单元测试的基础上,将所有模块按照一定要求或流程关系进行串联测试。比方说,一些模块虽然能够单独工作,但并不能保证连接起来也能正常工作,一些局部反映不出来的问题,在全局上很可能暴露出来。
因为测试框架 Jest 对于每个测试套件是并行运行的,而套件内的用例则是串行运行的,所以编写集成测试很方便,下面我们用文件夹的使用流程示例如何完成集成测试的编写。
import { request } from '../@helpers/agent'
import { login } from '../@helpers/login'
const urlCreateFolder = '/api/secret/folder' // POST
const urlFolderDetails = '/api/secret/folder' // GET
const urlFetchFolders = '/api/secret/folders' // GET
const urlDeleteFolder = '/api/secret/folder' // DELETE
const urlRenameFolder = '/api/secret/folder/rename' // PUT
const folders: ObjectAny[] = []
let globalReq: ObjectAny
test('没有权限创建文件夹应该返回 403 错误', async () => {
const res = await request.post(urlCreateFolder).send({
name: '我的文件夹',
})
expect(res.status).toBe(403)
})
test('确保创建 3 个文件夹', async () => {
// 登录有权限创建文件夹的用户,比如设计师
globalReq = await login({ role: 'designer' })
for (let i = 0; i < 3; i++) {
const res = await globalReq.post(urlCreateFolder).send({
name: '我的文件夹' + i,
})
// 将创建成功的文件夹置入 folders 常量里
folders.push(res.body)
expect(res.status).toBe(200)
// 更多验证规则...
}
})
test('重命名第 2 个文件夹', async () => {
const res = await globalReq.put(urlRenameFolder).send({
id: folders[1].id,
name: '新文件夹名称',
})
expect(res.status).toBe(200)
})
test('第 2 个文件夹的名称应该是【新文件夹名称】', async () => {
const res = await globalReq.get(urlFolderDetails).query({
id: folders[1].id,
})
expect(res.status).toBe(200)
expect(res.body.name).toBe('新文件夹名称')
// 更多验证规则...
})
test('获取文件夹列表应该返回 3 条数据', async () => {
// 与上雷同,鉴于代码过多,先行省略...
})
test('删除最后一个文件夹', async () => {
// 与上雷同,鉴于代码过多,先行省略...
})
test('再次获取文件夹列表应该返回 2 条数据', async () => {
// 与上雷同,鉴于代码过多,先行省略...
})
测试覆盖率
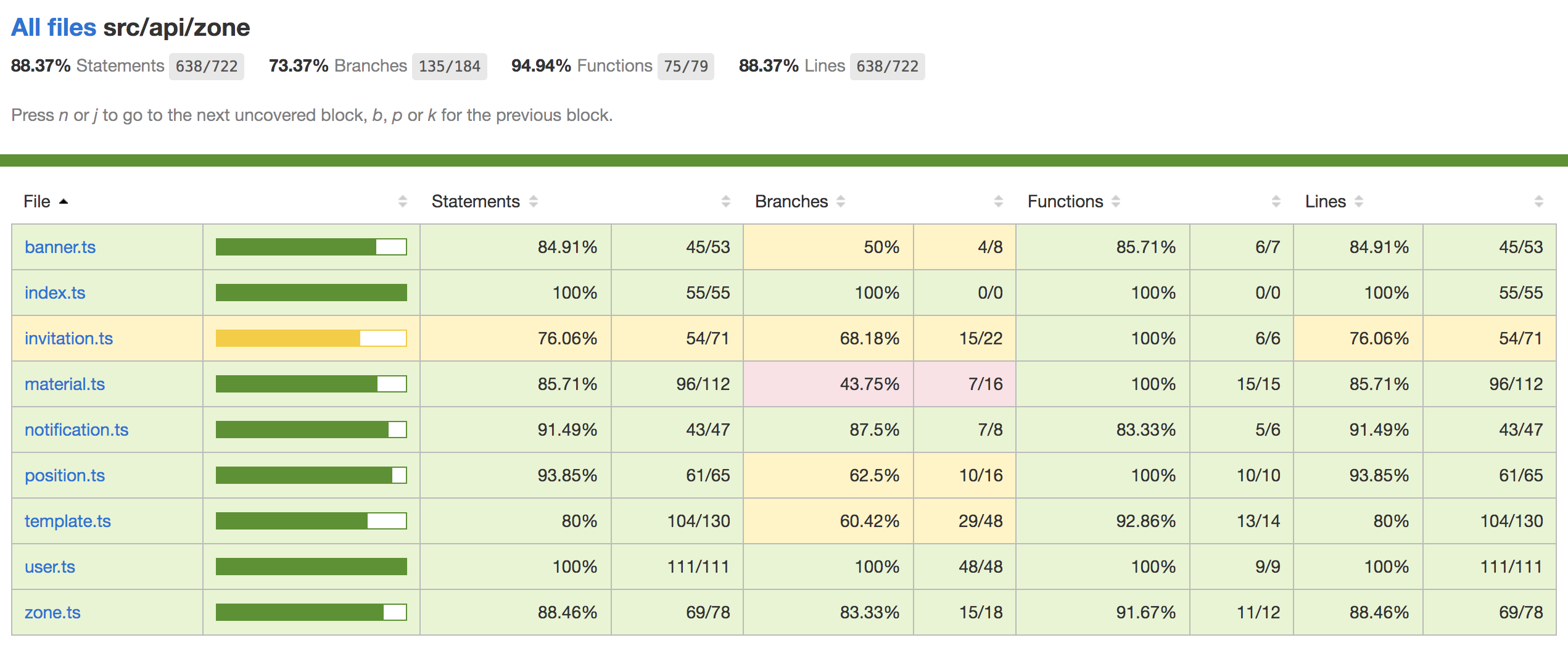
测试覆盖率是对测试完成程度的评测,基于文件被测试的情况来反馈测试的质量。
运行命令 jest --coverage 即可生成测试覆盖率报告,打开生成的 coverage/lcov-report/index.html 文件,各项指标一览无余。因为 Jest 内部使用 Istanbul 生成覆盖率报告,所以各项指标依然参考 Istanbul。
持续集成
写完这么多测试用例之后,或者是开发完功能代码后,我们是不是希望每次将代码推送到托管平台,如 GitLab,托管平台能自动帮我们运行所有测试用例,如果测试失败就邮件通知我们修复,如果测试通过则把开发分支合并到主分支?
答案是必须的。这就与持续集成(Continuous Integration)不谋而合,通俗的讲就是经常性地将代码合并到主干分支,每次合并前都需要运行自动化测试以验证代码的正确性。
所以我们配置一些自动化测试任务,按顺序执行安装、编译、测试等命令,测试命令则是运行编写好的测试用例。一个 GitLab 的配置任务(.gitlab-ci.yml)可能像下面这样,仅作参考。
# 每个 job 之前执行的命令
before_script:
- echo "`whoami` ($0 $SHELL)"
- echo "`which node` (`node -v`)"
- echo $CI_PROJECT_DIR
# 定义 job 所属 test 阶段及执行的命令等
test:
stage: test
except:
- test
cache:
paths:
- node_modules/
script:
- yarn
- yarn lint
- yarn test
# 定义 job 所属 deploy 阶段及执行的命令等
deploy-stage:
stage: deploy
only:
- test
script:
- cd /app
- make BRANCH=origin/${CI_COMMIT_REF_NAME} deploy-stage
持续集成的好处:
- 快速发现错误。
- 防止分支大幅偏离主干分支。
- 让产品可以快速迭代,同时还能保持高质量。
TDD与BDD引入
TDD 全称测试驱动开发(Test-driven development),是敏捷开发中的一种设计方法论,强调先将需求转换为具体的测试用例,然后再开发代码以使测试通过。
BDD 全称行为驱动开发(Behavior-driven development),也是一种敏捷开发设计方法论,它没有强调具体的形式如何,而是强调【作为什么角色,想要什么功能,以便收益什么】这样的用户故事指定行为的论点。
两者都是很好的开发模式,结合实际情况,我们的测试更像是 BDD,不过并没有完全摒弃 TDD,我们的建议是如果觉得先写测试可以帮助更快的写好代码,那就先写测试,如果觉得先写代码再写测试,或一边开发一边测试更好,则采用自己的方式,而结果是编码功能和测试用例都需要完成,并且运行通过,最后通过 Code Review 对代码质量做进一步审查与把控。
笔者称之为【师夷长技,聚于自身】:结合项目自身的实际情况,灵活变通,形成一套适合自身项目发展的模式驱动开发。
结论
自动化测试提供了一种有保障的机制检测整个系统,可以频繁地进行回归测试,有效提高系统稳定性。当然编写与维护测试用例需要耗费一定的成本,需要考虑投入与产出效益之间的平衡。
欢迎关注凹凸实验室博客:aotu.io
或者关注凹凸实验室公众号(AOTULabs),不定时推送文章:

