背景
- 前言
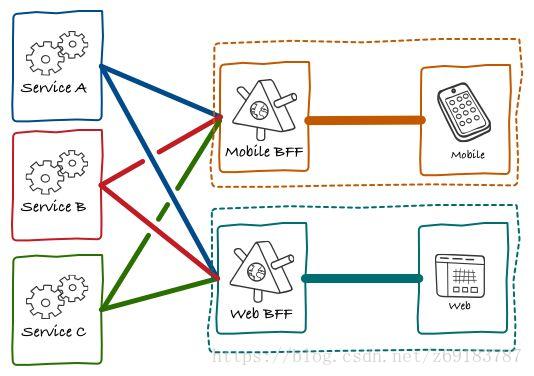
近年来,随着一波又一波技术浪潮的更迭,分工的不断细化,以及和业务越来越紧密的联系,前端早已告别了切图的时代,经历了类库补齐浏览器差异的时代;经历了各种模板引擎补齐模板渲染的时代;经历了各种mv的时代;逐步技术栈上归于react、vue全家桶;Node的普及,以及移动端设备提升、HTML5能力加强,端技术的融合已经是一种趋势;端和服务分离显得尤为重要,同样对服务层的数据适配提出了更高的要求。BFF(backend for frontend) 模式的提出让我们更加清晰认识到前后端分离,通俗来讲BFF就是前端负责业务逻辑的渲染,后端提供底层服务,如下图:
- 现状
在阿里内部更多前端团队基于BFF有过尝试,基本上都是基于begg或者midway,通过nodejs提供的能力去抽取、聚合、分发数据,服务端更加聚焦对应的业务领域。
我们跳出技术栈去看BFF,有些服务端的团队也有类似的尝试,比如淘宝的tql,graphql目前很火,tql就是基于graphql实现的,并且做了很多深入的优化,性能没得说同时支持去中心化。
- 分析(他山之石)
我们一直都在说全栈开发,其实更多是BFF范畴下,而不是把前后端的事都一个人干;其中F数据适配层,是前后端分离的关键点,也是我们可以发力的地方,那么有了tql,亦或有些个性化的需求更退一步使用node来做数据适配是不是就搞定一切了呢?当然不是,单独使用egg就不必多说,需要去维护整个应用和库表,有变更还需要走变更发布流程,主要结合我们的业务场景分析以下tql:tql 前面有介绍过优势,基于graphql,那就要求前后端都遵循graphql的协议(schema), 也就说要接入tql那就要求前后端都必须要做相应的适配,最主要的是graphql要求稳定的数据模型,假设我们的数据是动态schema产生的数据(jdata),或者一些创新的业务场景数据模型还没有被固化,这些场景都是不合适的。
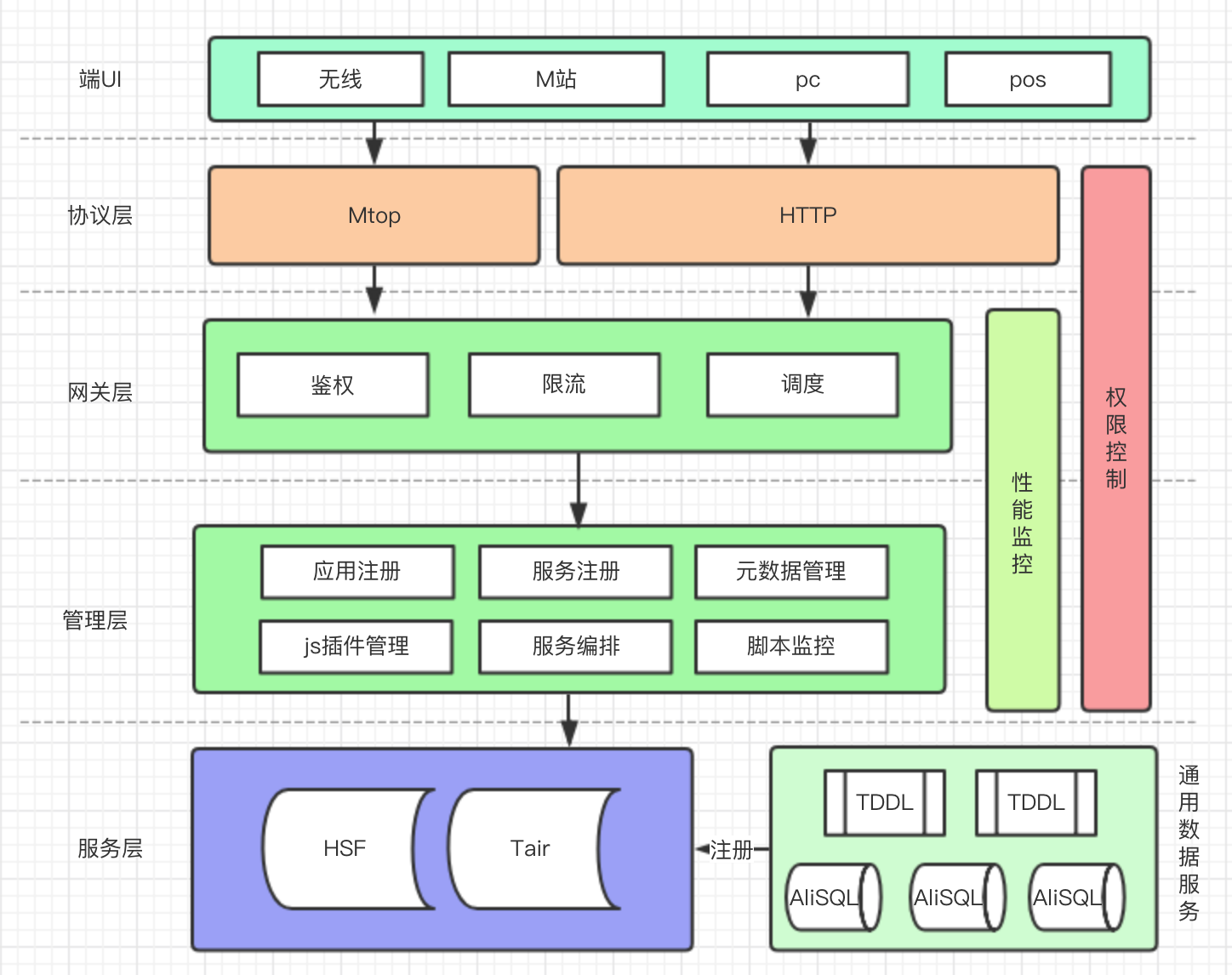
- 我们希望打造的平台&破解思路
上面讲了更多,我们对BFF以及现在的技术方案有了了解,总结起来我们发现现有的BFF的技术方案都是基于数据已经生成的前提,更多的是做数据查询的适配,如果遇到新的业务,或者需要存储一些配置信息,应该怎么办?显然我们需要后端去支持(node/java),我们要么去维护一个node应用,要么去让java端支持。既然BFF模式正确的,我们不妨把B层去拓展一下,让B层去适配所有的service(db也是一个service),如下图:
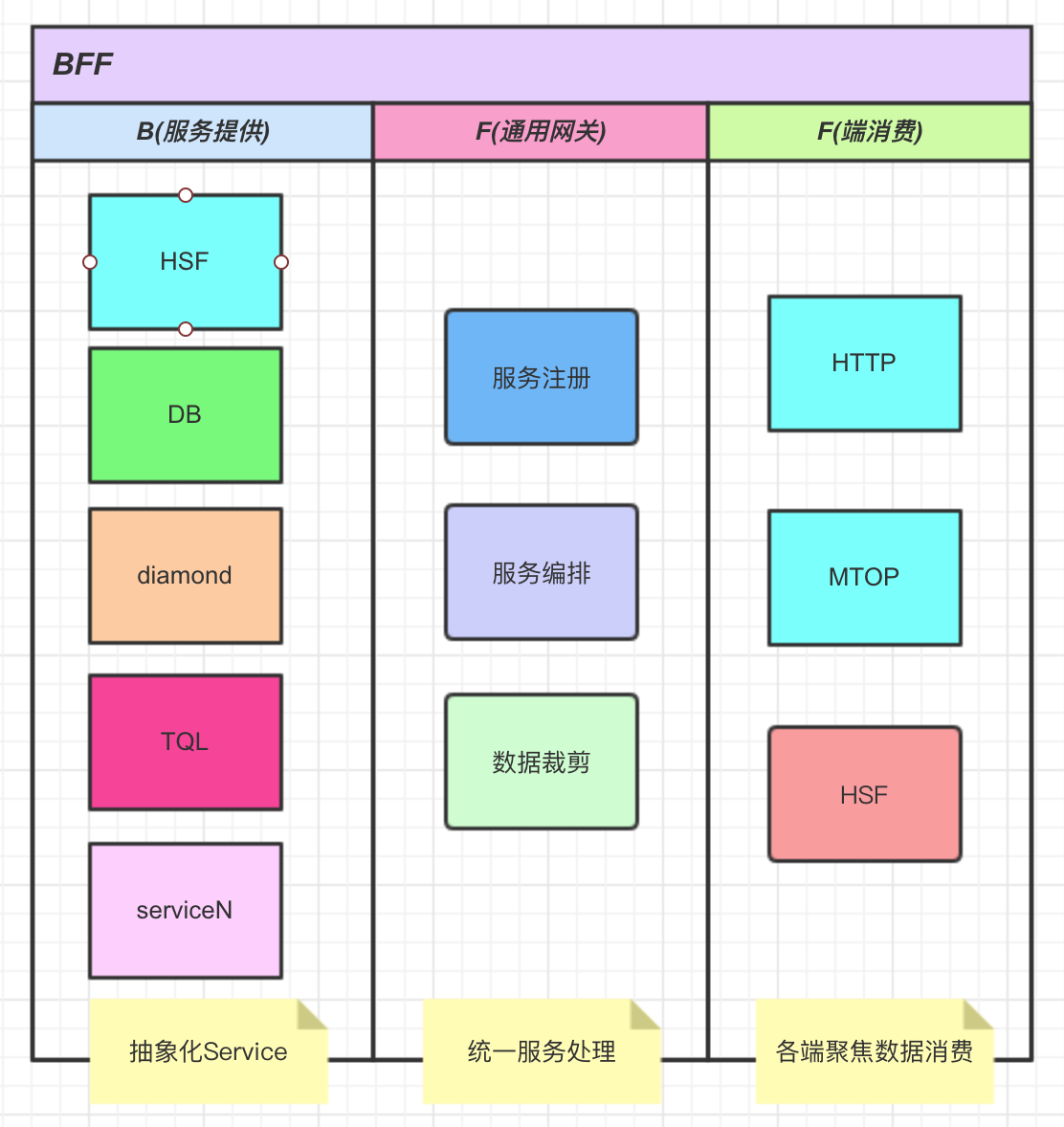
总结起来期望的平台需要具备以下特点:
- 统一的网关,前后端分离服务端只提供原子型的服务,势必需要统一的网关来链接端消费
- 服务插件化,当下端的开发不仅仅限于UI的渲染和交互,全栈以及各端融合也就是大前端让我们有更大的空间去做尝试,除了自建的技术项目以外还可以owner一些创新业务项目,这就对服务需求也是多样化
- 可视化编辑js,对于数据提裁剪各业务逻辑不尽相同,js可以更加灵活去实现业务逻辑,同时编辑、测试、发布统一线上完成
- js插件化,是为了代码共享提高开发效率
- 服务编排,通常一个请求往往不是一个服务可以满足的,我们需要编排多个服务,同时需要具备多服务并行处理能力
- 通用数据存储:数据存储是我们绕不开的话题,不需要再去维护一个后端应用来存储数据,把数据存储通用化当成一个核心服务插件
破解思路: