

文章首发自个人博客
最近我发现很多面试题里面都有「如何理解虚拟 DOM」这个题,我觉得这个题应该没有想象中那么好答,因为很多人没有真正理解虚拟 DOM 它的价值所在,我这篇从虚拟 DOM 的诞生过程来引出它的价值以及历史地位,帮助你深入的理解它。
什么是虚拟DOM
本质上是 JavaScript 对象,这个对象就是更加轻量级的对 DOM 的描述。
对,就是这么简单!
就是一个复杂一点的对象而已,没什么好说的,重点是为什么要有这个东西,以及有了这个描述有什么好处才是我们今天要介绍的内容。
为什么要有虚拟DOM
再谈为什么要用虚拟 DOM 之前,先来聊一聊 React 是怎么诞生的,毕竟在了解历史背景,再去思考他的诞生,就知道是必然会出现的。
再查了很多关于 React 的历史相关的文章,这篇文章我感觉比较值得令我信服:React 是怎样炼成的。
众所周知,Facebook 是 PHP 大户,所以 React 最开始的灵感就来至于 PHP。
字符串拼接时代 - 2004
在 2004 年这个时候,大家都还在用 PHP 的字符串拼接来开发网站:
$str = '<ul>';
foreach ($talks as $talk) {
$str += '<li>' . $talk->name . '</li>';
}
$str += '</ul>';
这种方式代码写出来不好看不说,还容易造成 XSS 等安全问题。
应对方法是对用户的任何输入都进行转义(Escape)。但是如果对字符串进行多次转义,那么反转义的次数也必须是相同的,否则会无法得到原内容。如果又不小心把 HTML 标签(Markup)给转义了,那么 HTML 标签会直接显示给用户,从而导致很差的用户体验。
XHP 时代 - 2010
到了 2010 年,为了更加高效的编码,同时也避免转义 HTML 标签的错误,Facebook 开发了 XHP 。XHP 是对 PHP 的语法拓展,它允许开发者直接在 PHP 中使用 HTML 标签,而不再使用字符串。
$content = <ul />;
foreach ($talks as $talk) {
$content->appendChild(<li>{$talk->name}</li>);
}
这样的话,所有的 HTML 标签都使用不同于 PHP 的语法,我们可以轻易的分辨哪些需要转义哪些不需要转义。
不久的后来,Facebook 的工程师又发现他们还可以创建自定义标签,而且通过组合自定义标签有助于构建大型应用。
JSX - 2013
到了 2013 年,前端工程师 Jordan Walke 向他的经理提出了一个大胆的想法:把 XHP 的拓展功能迁移到 JS 中。首要任务是需要一个拓展来让 JS 支持 XML 语法,该拓展称为 JSX。因为当时由于 Node.js 在 Facebook 已经有很多实践,所以很快就实现了 JSX。
可以猜想一下为什么要迁移到 js 中,我猜想应该是前后端分离导致的。
const content = (
<TalkList>
{ talks.map(talk => <Talk talk={talk} />)}
</TalkList>
);
React
在这个时候,就有另外一个很棘手的问题,那就是在进行更新的时候,需要去操作 DOM,传统 DOM API 细节太多,操作复杂,所以就很容易出现 Bug,而且代码难以维护。
然后就想到了 PHP 时代的更新机制,每当有数据改变时,只需要跳到一个由 PHP 全新渲染的新页面即可。
从开发者的角度来看的话,这种方式开发应用是非常简单的,因为它不需要担心变更,且界面上用户数据改变时所有内容都是同步的。
为此 React 提出了一个新的思想,即始终整体“刷新”页面
当发生前后状态变化时,React 会自动更新 UI,让我们从复杂的 UI 操作中解放出来,使我们只需关于状态以及最终 UI 长什么样。
下面看看局部刷新和整体刷新的区别。
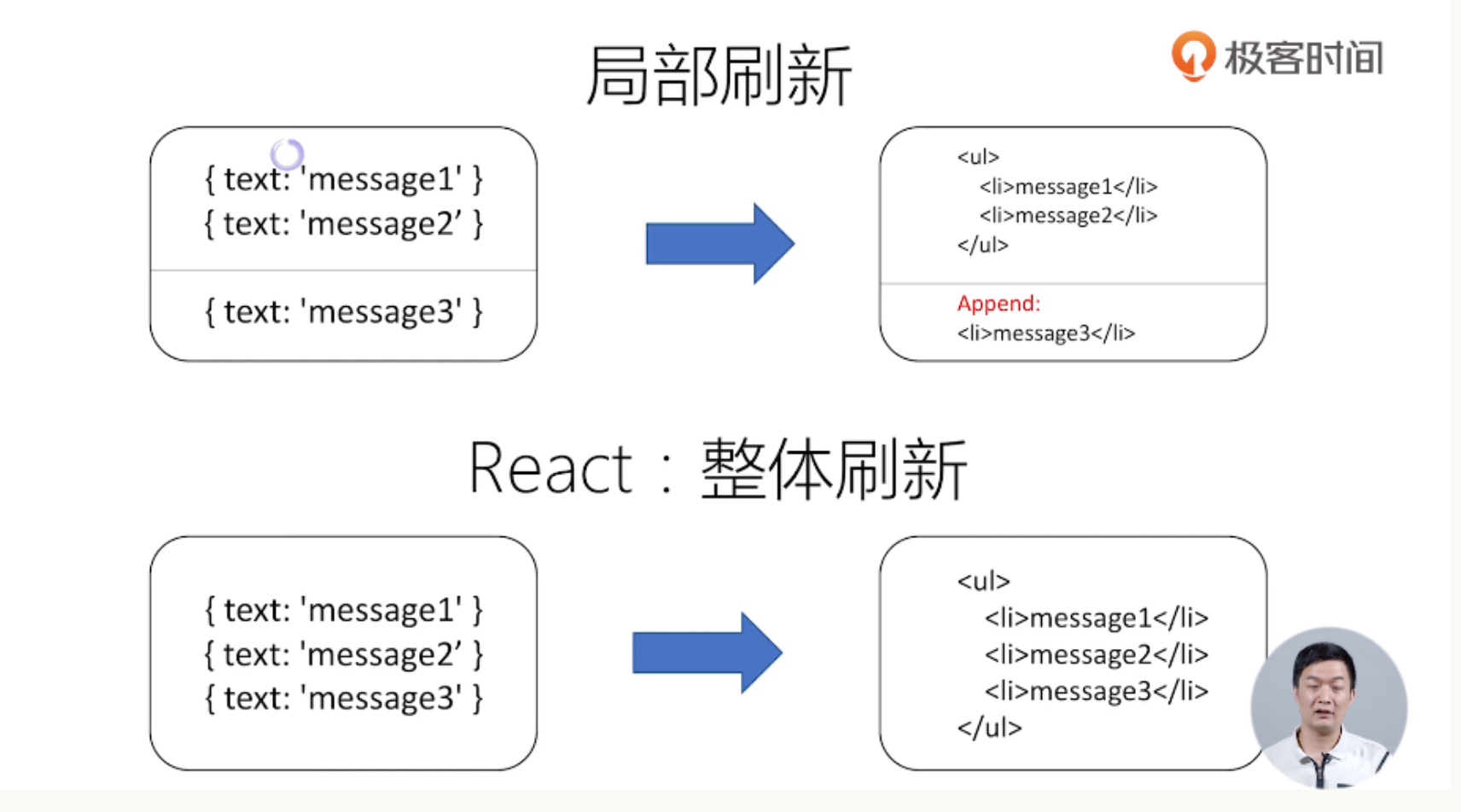
图片来自于极客时间王沛老师的《React进阶与实战》
局部刷新:
// 下面是伪代码
var ul = find(ul) // 先找到 ul
ul.append(`<li>${message3}</li>`) //然后再将message3插到最后
// 想想如果是不插到最后一个,而是插到中间的第n个
var ul = find(ul) // 先找到 ul
var preli = find(li(n-1)) // 再找到 n-1 的一个 li
preli.next(`<li>${message3}</li>`) // 再插入到 n-1 个的后面
整体刷新:
UI = f(messages) // 整体刷新 3 条消息,只需要调用 f 函数
// 这个是在初始渲染的时候就定义好的,更新的时候不用去管
function f(messages) {
return <ul>
{messages.map(message => <li>{ message }</li>)}
</ul>
}
这个时候,我只需要关系我的状态(数据是什么),以及 UI 长什么样(布局),不再需要关系操作细节。
这种方式虽然简单粗暴,但是很明显的缺点,就是很慢。
另外还有一个问题就是这样无法包含节点的状态。比如它会失去当前聚焦的元素和光标,以及文本选择和页面滚动位置,这些都是页面的当前状态。
Diff
为了解决上面说的问题,对于没有改变的 DOM 节点,让它保持原样不动,仅仅创建并替换变更过的 DOM 节点。这种方式实现了 DOM 节点复用(Reuse)。
至此,只要能够识别出哪些节点改变了,那么就可以实现对 DOM 的更新。于是问题就转化为如何比对两个 DOM 的差异。
说道对比差异,可能很容易想到版本控制(git)。
DOM 是树形结构,所以 diff 算法必须是针对树形结构的。目前已知的完整树形结构 diff 算法复杂度为 O(n^3) 。
但是时间复杂度 O(n^3) 太高了,所以Facebook工程师考虑到组件的特殊情况,然后将复杂度降低到了 O(n)。
附:详细的 diff 理解:不可思议的 react diff 。
Virtual DOM
前面说到,React 其实实现了对 DOM 节点的版本控制。
做过 JS 应用优化的人可能都知道,DOM 是复杂的,对它的操作(尤其是查询和创建)是非常慢非常耗费资源的。看下面的例子,仅创建一个空白的 div,其实例属性就达到 231 个。
// Chrome v63
const div = document.createElement('div');
let m = 0;
for (let k in div) {
m++;
}
console.log(m); // 231
对于 DOM 这么多属性,其实大部分属性对于做 Diff 是没有任何用处的,所以如果用更轻量级的 JS 对象来代替复杂的 DOM 节点,然后把对 DOM 的 diff 操作转移到 JS 对象,就可以避免大量对 DOM 的查询操作。这个更轻量级的 JS 对象就称为 Virtual DOM 。
那么现在的过程就是这样:
- 维护一个使用 JS 对象表示的 Virtual DOM,与真实 DOM 一一对应
- 对前后两个 Virtual DOM 做 diff ,生成变更(Mutation)
- 把变更应用于真实 DOM,生成最新的真实 DOM
可以看出,因为要把变更应用到真实 DOM 上,所以还是避免不了要直接操作 DOM ,但是 React 的 diff 算法会把 DOM 改动次数降到最低。
剩下的历史就不谈了,已经引出这篇文章的重点:虚拟 DOM。详细的历史可见:React 是怎样炼成的,文中历史部分内容很多摘抄与此。
总结
传统前端的编程方式是命令式的,直接操纵DOM,告诉浏览器该怎么干。这样的问题就是,大量的代码被用于操作 DOM 元素,且代码可读性差,可维护性低。
React 的出现,将命令式变成了声明式,摒弃了直接操作 DOM 的细节,只关注数据的变动,DOM 操作由框架来完成,从而大幅度提升了代码的可读性和可维护性。
在初期我们可以看到,数据的变动导致整个页面的刷新,这种效率很低,因为可能是局部的数据变化,但是要刷新整个页面,造成了不必要的开销。
所以就有了 Diff 过程,将数据变动前后的 DOM 结构先进行比较,找出两者的不同处,然后再对不同之处进行更新渲染。
但是由于整个 DOM 结构又太大,所以采用了更轻量级的对 DOM 的描述—虚拟 DOM。
不过需要注意的是,虚拟 DOM 和 Diff 算法的出现是为了解决由命令式编程转变为声明式编程、数据驱动后所带来的性能问题的。换句话说,直接操作 DOM 的性能并不会低于虚拟 DOM 和 Diff 算法,甚至还会优于。
这么说的原因是因为 Diff 算法的比较过程,比较是为了找出不同从而有的放矢的更新页面。但是比较也是要消耗性能的。而直接操作 DOM 就是有的放矢,我们知道该更新什么不该更新什么,所以不需要有比较的过程。所以直接操作 DOM 效率可能更高。
React 厉害的地方并不是说它比 DOM 快,而是说不管你数据怎么变化,我都可以以最小的代价来进行更新 DOM。 方法就是我在内存里面用新的数据刷新一个虚拟 DOM 树,然后新旧 DOM 进行比较,找出差异,再更新到 DOM 树上。
框架的意义在于为你掩盖底层的 DOM 操作,让你用更声明式的方式来描述你的目的,从而让你的代码更容易维护。没有任何框架可以比纯手动的优化 DOM 操作更快,因为框架的 DOM 操作层需要应对任何上层 API 可能产生的操作,它的实现必须是普适的。
如果你想了解更多的虚拟 DOM 与性能的关系,请看下面公众号里面的两篇文章和那个知乎话题,会让你对虚拟 DOM 又更深层次的理解。
另外再提一个点,很多人会把 Diff 、数据更新、提升性能等概念绑定起来,但是你想想这个问题:React 由于只触发更新,而不能知道精确变化的数据,所以需要 diff 来找出差异然后 patch 差异队列。Vue 采用数据劫持的手段可以精准拿到变化的数据,为什么还要用虚拟DOM?
虚拟DOM 的作用
要想回答上面那个问题,真的不要仅仅以为虚拟 DOM 或者 React 是来解决性能问题的,好处可还有很多呢。下面我总结了一些虚拟 DOM 好作用。
- Virtual DOM 在牺牲(牺牲很关键)部分性能的前提下,增加了可维护性,这也是很多框架的通性。
- 实现了对 DOM 的集中化操作,在数据改变时先对虚拟 DOM 进行修改,再反映到真实的 DOM中,用最小的代价来更新DOM,提高效率(提升效率要想想是跟哪个阶段比提升了效率,别只记住了这一条)。
- 打开了函数式 UI 编程的大门。
- 可以渲染到 DOM 以外的端,使得框架跨平台,比如 ReactNative,React VR 等。
- 可以更好的实现 SSR,同构渲染等。这条其实是跟上面一条差不多的。
- 组件的高度抽象化。
既然虚拟 DOM 有这么多作用,那么上面的问题,Vue 采用虚拟 DOM 的原因是什么呢?
Vue 2.0 引入 vdom 的主要原因是 vdom 把渲染过程抽象化了,从而使得组件的抽象能力也得到提升,并且可以适配 DOM 以外的渲染目标。 来自尤大文章:Vue 的理念问题
虚拟 DOM 的缺点
- 首次渲染大量 DOM 时,由于多了一层虚拟 DOM 的计算,会比 innerHTML 插入慢。
- 虚拟 DOM 需要在内存中的维护一份 DOM 的副本(更上面一条其实也差不多,上面一条是从速度上,这条是空间上)。
- 如果虚拟 DOM 大量更改,这是合适的。但是单一的,频繁的更新的话,虚拟 DOM 将会花费更多的时间处理计算的工作。所以,如果你有一个DOM 节点相对较少页面,用虚拟 DOM,它实际上有可能会更慢。但对于大多数单页面应用,这应该都会更快。
总结
本文在介绍虚拟 DOM 并没有像其他文章一样去解释它的实现以及相关的 Diff 算法,关于 Diff 算法可以看这篇 虚拟 DOM 到底是什么?文中介绍了很多库的 diff 算法,可见其实 React 的 diff 算法并不算太快。
而是通过历史来得出他的价值体现,从历史怎么看大牛们是怎么一步一步的去解决问题,从历史中看为什么别人能做出这么伟大的东西,而我们不能?
每个伟大的产品都会有非常多的背景支持,都是一步一步发展而来的。
另外洗清了一个错误观念:很多人认为虚拟 DOM 最大的优势是 diff 算法,减少 JavaScript 操作真实 DOM 的带来的性能消耗。
虽然这一个虚拟 DOM 带来的一个优势,但并不是全部。虚拟 DOM 最大的优势在于抽象了原本的渲染过程,实现了跨平台的能力,而不仅仅局限于浏览器的 DOM,可以是安卓和 IOS 的原生组件,可以是近期很火热的小程序,也可以是各种 GUI。
最后希望大家多思考,跟随者浪潮站在浪潮之巅。
参考链接
后记
我是桃翁,一个爱思考的前端er,想了解关于更多的前端相关的,请关注我的公号:「前端桃园」,如果想加入交流群关注公众号后回复「微信」拉你进群

