

一:消息队列优势
1):异步处理
2):系统解耦
解耦是消息中间队列解决的最本质问题。所谓解耦,简单一点就是一个事务,只关心核心的流程。而需要依赖其他系统但不那么重要的事情,有通知即可,无需等待结果。换句话说,关心的是“通知,而非“处理”。 比如下单过程中,需要发送短信积分,如果下游系统过慢(比如短信网关速度不好),主流程一直在等待。用户肯定不希望支付下单的过程中几分钟之后才得到结果。那么我们只需要通知短信系统“我们支付成功了”,不一定非要等待它处理完成。
3):流量削峰
试想上下游对于事件的处理能力是不同的。比如,Web前端每秒承受上千万的请求,并不是什么神奇的事情,只需要加多一点机器,再搭建一些LVS负载均衡设备和Nginx等即可。但数据库的处理能力却十分有限,即使使用SSD加分库分表,单机的处理能力仍然在万级。由于成本的考虑,我们不能奢求数据库的机器数量追上前端。 这种问题同样存在于系统和系统之间,如短信系统可能由于短板效应,速度卡在网关上(每秒几百次请求),跟前端的并发量不是一个数量级。但用户晚上个半分钟左右收到短信,一般是不会有太大问题的。如果没有消息队列,两个系统之间通过协商、滑动窗口等复杂的方案也不是说不能实现。但系统复杂性指数级增长,势必在上游或者下游做存储,并且要处理定时、拥塞等一系列问题。而且每当有处理能力有差距的时候,都需要单独开发一套逻辑来维护这套逻辑。所以,利用中间系统转储两个系统的通信内容,并在下游系统有能力处理这些消息的时候,再处理这些消息,是一套相对较通用的方式。
4):广播
消息队列的基本功能之一是进行广播。如果没有消息队列,每当一个新的业务方接入,我们都要联调一次新接口。有了消息队列,我们只需要关心消息是否送达了队列,至于谁希望订阅,是下游的事情,无疑极大地减少了开发和联调的工作量。
5):最终一致性
最终一致性指的是两个系统的状态保持一致,要么都成功,要么都失败。当然有个时间限制,理论上越快越好,但实际上在各种异常的情况下,可能会有一定延迟达到最终一致状态,但最后两个系统的状态是一样的。
业界有一些为“最终一致性”而生的消息队列,如Notify(阿里)、QMQ(去哪儿)等,其设计初衷,就是为了交易系统中的高可靠通知。
本地事务维护业务变化和通知消息,一起落地(失败则一起回滚),然后RPC到达broker,在broker成功落地后,RPC返回成功,本地消息可以删除。否则本地消息一直靠定时任务轮询不断重发,这样就保证了消息可靠落地broker。
broker往consumer发送消息的过程类似,一直发送消息,直到consumer发送消费成功确认。
总结:
消息队列不是万能的。对于需要强事务保证而且延迟敏感的,RPC是优于消息队列的。
对于一些无关痛痒,或者对于别人非常重要但是对于自己不是那么关心的事情,可以利用消息队列去做。
支持最终一致性的消息队列,能够用来处理延迟不那么敏感的“分布式事务”场景,而且相对于笨重的分布式事务,可能是更优的处理方式。
当上下游系统处理能力存在差距的时候,利用消息队列做一个通用的“漏斗”。在下游有能力处理的时候,再进行分发。
使用较多的消息队列有ActiveMQ、RocketMQ、RabbitMQ、Kafka等。
二:为什么选择RabbitMQ
1):从社区活跃度
按照目前网络上的资料,RabbitMQ 、activeM 、ZeroMQ 三者中,综合来看,RabbitMQ 是首选。
2):持久化消息比较
ZeroMq 不支持,ActiveMq 和RabbitMq 都支持。持久化消息主要是指我们机器在不可抗力因素等情况下挂掉了,消息不会丢失的机制。
3):综合技术实现
可靠性、灵活的路由、集群、事务、高可用的队列、消息排序、问题追踪、可视化管理工具、插件系统等等。 RabbitMq / Kafka 最好,ActiveMq 次之,ZeroMq 最差。当然ZeroMq 也可以做到,不过自己必须手动写代码实现,代码量不小。尤其是可靠性中的:持久性、投递确认、发布者证实和高可用性。
4):高并发
毋庸置疑,RabbitMQ 最高,原因是它的实现语言是天生具备高并发高可用的erlang 语言。
5):比较关注的比较, RabbitMQ 和 Kafka
RabbitMq 比Kafka 成熟,在可用性上,稳定性上,可靠性上, RabbitMq 胜于 Kafka (理论上)。 另外,Kafka 的定位主要在日志等方面, 因为Kafka 设计的初衷就是处理日志的,可以看做是一个日志(消息)系统一个重要组件,针对性很强,所以 如果业务方面还是建议选择 RabbitMq 。 还有就是,Kafka 的性能(吞吐量、TPS )比RabbitMq 要高出来很多。
6):选型最后总结
如果我们系统中已经有选择 Kafka ,或者 RabbitMq ,并且完全可以满足现在的业务,建议就不用重复去增加和造轮子。 可以在 Kafka 和 RabbitMq 中选择一个适合自己团队和业务的,这个才是最重要的。但是毋庸置疑现阶段,综合考虑没有第三选择。
三:AMQP协议介绍
背景
越是大型的公司越是不可避免的使用来自众多供应商的MQ产品,来服务企业内部的不同应用。如果应用已经订阅了TIBCO MQ信息,若突然需要消费来自IBM MQ的消息,则实现起来会非常困难。这些产品使用不同的api,不同的协议,因而毫无疑问无法联合起来组成单一的总线。为了解决这个问题,Java Message Service(JMS)在2001年诞生了。JMS试图通过提供公共java api的方式,隐藏单独MQ产品供应商提供的实际接口,从而跨越了壁垒和解决了互通问题。从技术上讲,java应用程序只需要对JMS API编程,选择合适的MQ驱动即可。JMS会打理好其他部分的。问题是你在尝试使用单独编准化接口来整合众多不同的接口。这就像是把不同的类型的衣服粘在一起:缝合处终究会裂开。使用JMS(Java Message Service)的应用程序会变得更加脆弱。我们需要新的消息通信标准化方案。
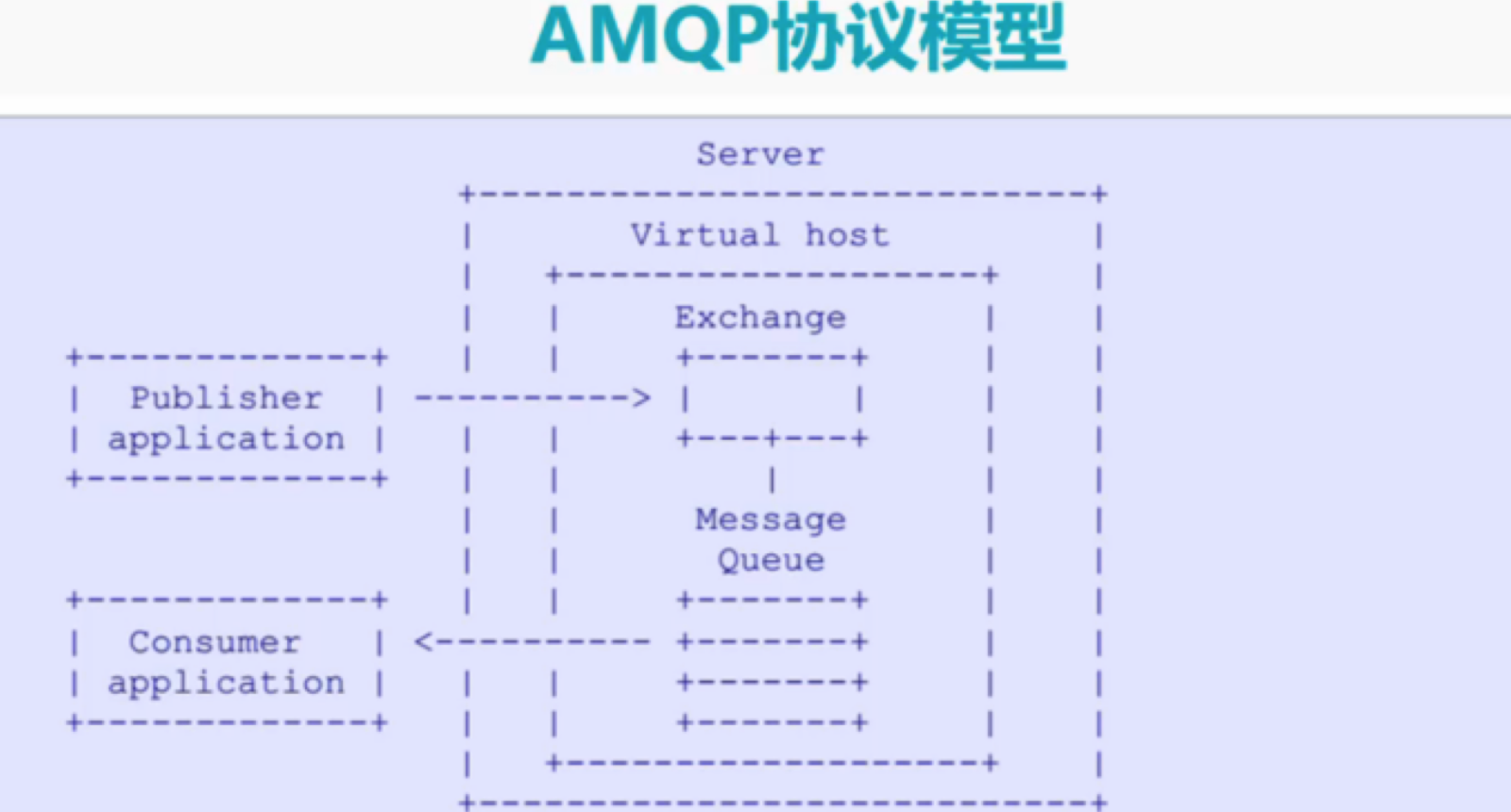
AMQP,即Advanced Message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。
- Server:又称为Broker。接收客户端连接,实现AMQP的服务器实体。
- Connection:连接,应用程序与Broker的网络连接。
- Channel:信道,几乎所有的操作都在Channel中进行,Channel是进行消息读写的通道。客户端可建立多个Channel,每个Channel代表一个会话任务。
- Message:消息。服务器和应用程序之间传递的数据,本质上就是一段数据,由Properties和Body组成。
- Exchange:交换机。接收消息,根据路由键转发消息到绑定的队列。
- Binding:Exchange和Queue之间的虚拟连接,binding中可以包含routing key。
- Routing key:一个虚拟地址,虚拟机可用它来确定如何路由一个特定消息。
- Queue:也称为Message Queue,消息队列,保存消息并将它们转发给消费者。
- Virtual Host:其实是一个虚拟概念。类似于权限控制组,一个Virtual Host里面可以有若干个Exchange和Queue,可以用来隔离Exchange和Queue。,同一个Virtual Host里面不能有相同名称的Exchange和Queue。但是权限控制的最小粒度是Virtual Host。
消费者是监听队列的,不知道是哪个生产者发送的。
