

Flink的Transformation转换主要包括四种:单数据流基本转换、基于Key的分组转换、多数据流转换和数据重分布转换。本文主要介绍基于Key的分组转换,关于时间和窗口将在后续文章中介绍。读者可以使用Flink Scala Shell或者Intellij Idea来进行练习:

数据类型的转化
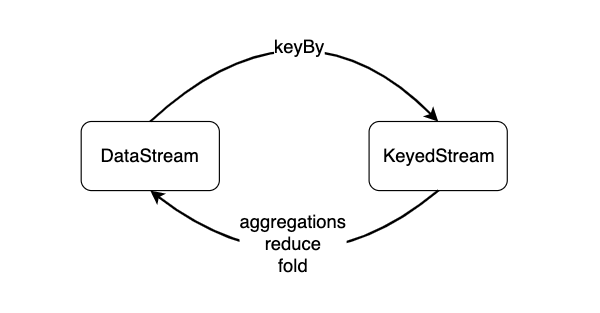
对数据分组主要是为了进行后续的聚合操作,即对同组数据进行聚合分析。keyBy会将一个DataStream转化为一个KeyedStream,聚合操作会将KeyedStream转化为DataStream。如果聚合前每个元素数据类型是T,聚合后的数据类型仍为T。
本文涉及的完整的代码在github上:github.com/luweizheng/…
keyBy
绝大多数情况,我们要根据事件的某种属性或数据的某个字段进行分组,对一个分组内的数据进行处理。如下图所示,keyBy算子根据元素的形状对数据进行分组,相同形状的元素被分到了一起,可被后续算子统一处理。比如,多支股票数据流处理时,可以根据股票代号进行分组,然后对同一股票代号的数据统计其价格变动。又如,电商用户行为日志把所有用户的行为都记录了下来,如果要分析某一个用户行为,需要先按用户ID进行分组。
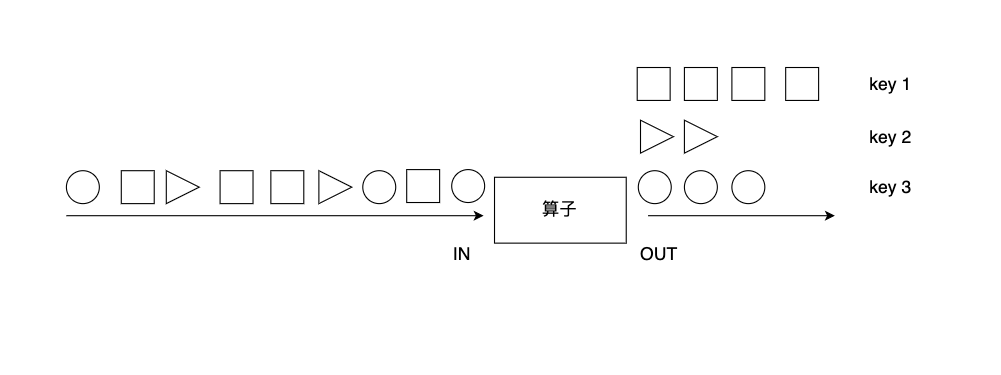
keyBy算子将DataStream转换成一个KeyedStream。KeyedStream是一种特殊的DataStream,事实上,KeyedStream继承了DataStream,DataStream的各元素随机分布在各Task Slot中,KeyedStream的各元素按照Key分组,分配到各Task Slot中。我们需要向keyBy算子传递一个参数,以告知Flink以什么字段作为Key进行分组。
我们可以使用数字位置来指定Key:
val dataStream: DataStream[(Int, Double)] = senv.fromElements((1, 1.0), (2, 3.2), (1, 5.5), (3, 10.0), (3, 12.5))
// 使用数字位置定义Key 按照第一个字段进行分组
val keyedStream = dataStream.keyBy(0)
也可以使用字段名来指定Key,比如StockPrice里的股票代号symbol:
val stockPriceStream: DataStream[StockPrice] = stockPriceRawStream.keyBy(_.symbol)
一旦按照Key分组后,我们后续可以按照Key进行时间窗口的处理和状态的创建和更新。数据流里包含相同Key的数据都可以访问和修改相同的状态。关于如何指定Key,时间窗口和状态等知识,本专栏后续将有专门的文章来介绍。
aggregation
常见的聚合操作有sum、max、min等,这些聚合操作统称为aggregation。aggregation需要一个参数来指定按照哪个字段进行聚合。跟keyBy相似,我们可以使用数字位置来指定对哪个字段进行聚合,也可以使用字段名。
与批处理不同,这些聚合函数是对流数据进行数据,流数据是依次进入Flink的,聚合操作是对之前流入的数据进行统计聚合。sum算子的功能对该字段进行加和,并将结果保存在该字段上。min操作无法确定其他字段的数值。
val tupleStream = senv.fromElements(
(0, 0, 0), (0, 1, 1), (0, 2, 2),
(1, 0, 6), (1, 1, 7), (1, 2, 8)
)
// 按第一个字段分组,对第二个字段求和,打印出来的结果如下:
// (0,0,0)
// (0,1,0)
// (0,3,0)
// (1,0,6)
// (1,1,6)
// (1,3,6)
val sumStream = tupleStream.keyBy(0).sum(1).print()
max算子对该字段求最大值,并将结果保存在该字段上。对于其他字段,该操作并不能保证其数值。
// 按第一个字段分组,对第三个字段求最大值max,打印出来的结果如下:
// (0,0,0)
// (0,0,1)
// (0,0,2)
// (1,0,6)
// (1,0,7)
// (1,0,8)
val maxStream = tupleStream.keyBy(0).max(2).print()
maxBy算子对该字段求最大值,maxBy与max的区别在于,maxBy同时保留其他字段的数值,即maxBy可以得到数据流中最大的元素。
// 按第一个字段分组,对第三个字段求最大值maxBy,打印出来的结果如下:
// (0,0,0)
// (0,1,1)
// (0,2,2)
// (1,0,6)
// (1,1,7)
// (1,2,8)
val maxByStream = tupleStream.keyBy(0).maxBy(2).print()
同样,min和minBy的区别在于,min算子对某字段求最小值,minBy返回具有最小值的元素。
其实,这些aggregation操作里已经封装了状态数据,比如,sum算子内部记录了当前的和,max算子内部记录了当前的最大值。由于内部封装了状态数据,而且状态数据并不会被清理,因此一定要避免在一个无限数据流上使用aggregation。
注意,对于一个KeyedStream,一次只能使用一个aggregation操作,无法链式使用多个。
reduce
前面几个aggregation是几个较为特殊的操作,对分组数据进行处理更为通用的方法是使用reduce算子。
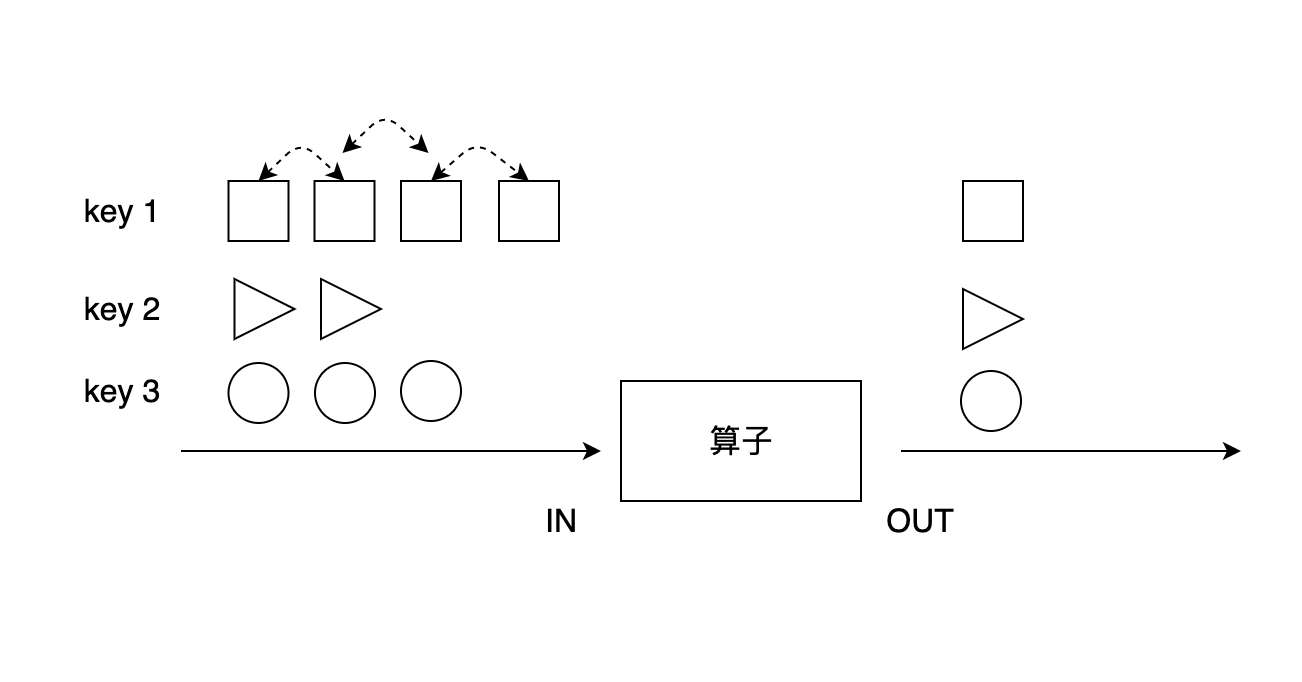
上图展示了reduce算子的原理:reduce在按照同一个Key分组的数据流上生效,它接受两个输入,生成一个输出,即两两合一地进行汇总操作,生成一个同类型的新元素。
case class Score(name: String, course: String, score: Int)
val dataStream: DataStream[Score] = senv.fromElements(
Score("Li", "English", 90), Score("Wang", "English", 88), Score("Li", "Math", 85),
Score("Wang", "Math", 92), Score("Liu", "Math", 91), Score("Liu", "English", 87))
class MyReduceFunction() extends ReduceFunction[Score] {
// reduce 接受两个输入,生成一个同类型的新的输出
override def reduce(s1: Score, s2: Score): Score = {
Score(s1.name, "Sum", s1.score + s2.score)
}
}
val sumReduceFunctionStream = dataStream
.keyBy("name")
.reduce(new MyReduceFunction)
使用Lambda表达式更简洁一些:
val sumLambdaStream = dataStream
.keyBy("name")
.reduce((s1, s2) => Score(s1.name, "Sum", s1.score + s2.score))

