

一、前言
我在上一篇文章 类的结构 已经分析大多数类结构的内容,但是还遗留了一些内容,比如 cache_t ,这篇文章我们主要分析 cache_t 是一个什么东西。
二、cache_t 结构分析
1. cache_t 的源码结构
首先我们来到类的结构源码,点到 cache_t 结构体里面发现,cache_t 由 bucket_t、_mask、_occupied 三部分以及一些方法组成。
struct objc_class : objc_object {
// Class ISA;
Class superclass;
cache_t cache;
class_data_bits_t bits;
}
struct cache_t {
struct bucket_t *_buckets;
mask_t _mask;
mask_t _occupied;
public:
struct bucket_t *buckets();
mask_t mask();
mask_t occupied();
void incrementOccupied();
void setBucketsAndMask(struct bucket_t *newBuckets, mask_t newMask);
void initializeToEmpty();
mask_t capacity();
bool isConstantEmptyCache();
bool canBeFreed();
static size_t bytesForCapacity(uint32_t cap);
static struct bucket_t * endMarker(struct bucket_t *b, uint32_t cap);
void expand();
void reallocate(mask_t oldCapacity, mask_t newCapacity);
struct bucket_t * find(cache_key_t key, id receiver);
static void bad_cache(id receiver, SEL sel, Class isa) __attribute__((noreturn));
};
从 cache_t 的结构体中好像没什么发现,就是一个很普通的结构体,既然在 cache_t 的结构体没有发现什么,那我们就更加深入的点进去瞧一瞧,所以我在点进 bucket_t 的结构体中发现了新的大陆,源码如下,而 mask_t 就是一个 typedef uint32_t mask_t;,没什么好分析的。
struct bucket_t {
private:
// IMP-first is better for arm64e ptrauth and no worse for arm64.
// SEL-first is better for armv7* and i386 and x86_64.
#if __arm64__
MethodCacheIMP _imp;
cache_key_t _key;
#else
cache_key_t _key;
MethodCacheIMP _imp;
#endif
public:
inline cache_key_t key() const { return _key; }
inline IMP imp() const { return (IMP)_imp; }
inline void setKey(cache_key_t newKey) { _key = newKey; }
inline void setImp(IMP newImp) { _imp = newImp; }
void set(cache_key_t newKey, IMP newImp);
};
小结: 在 bucket_t 结构体中发现了 _imp 和 _key,由此可以推断出 cache_t 通过 bucket_t 缓存的是方法而不是属性,如果是属性的话,可能会有一些 ivars、property 这些之类的属性。所以cache_t 就是对方法进行缓存,从加快之后的方法调用速度,接下来我就通过 LLDB 调试打印出 bucket_t 里面的内容,来证明我的推断。
2. LLDB 打印 bucket_t
在我的源码工程下,新建一个 Person 类,然后调用一下方法sayHello,按照上一篇文章的逻辑在 LLDB 调试台上,打印一下 bucket 的内容,可以看出 bucket 中的确保存了方法 sayHello 的 imp。
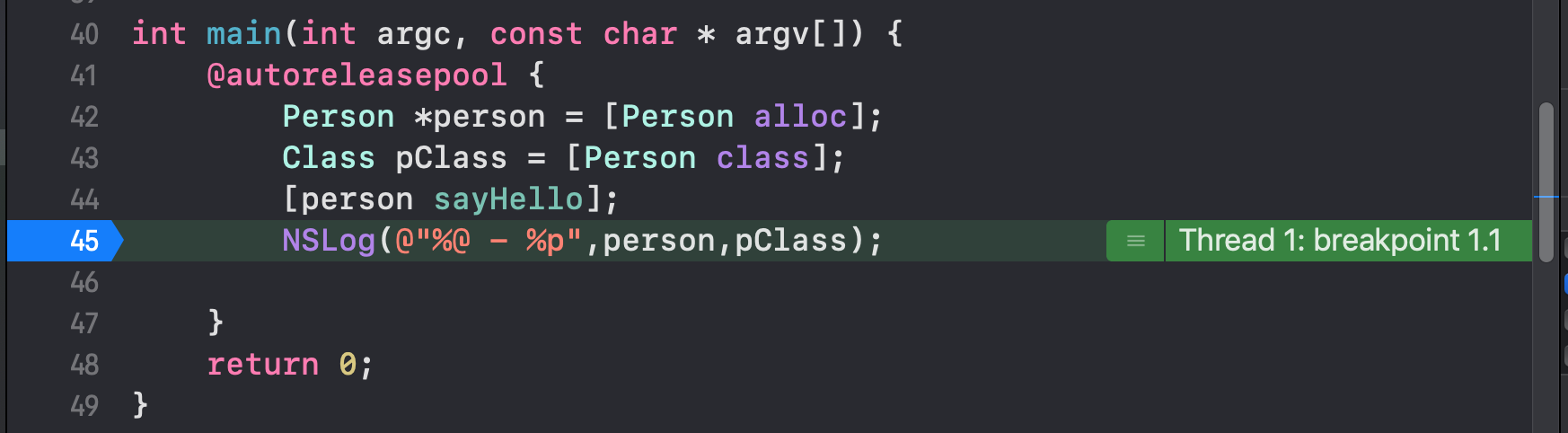
2020-01-07 16:40:53.472504+0800 Test[9751:17573108] Person say : -[Person sayHello]
(lldb) x pClass
0x1000013d0: a9 13 00 00 01 80 1d 00 40 d1 af 00 01 00 00 00 ........@.......
0x1000013e0: c0 ff f2 00 01 00 00 00 03 00 00 00 01 00 00 00 ................
(lldb) p (cache_t *)0x1000013e0
(cache_t *) $1 = 0x00000001000013e0
(lldb) p *$1
(cache_t) $2 = {
_buckets = 0x0000000100f2ffc0
_mask = 3
_occupied = 1
}
(lldb) p $2._buckets
(bucket_t *) $3 = 0x0000000100f2ffc0
(lldb) p *$3
(bucket_t) $4 = {
_key = 0
_imp = 0x0000000000000000
}
(lldb) p *$3(1)
error: called object type 'bucket_t *' is not a function or function pointer
(lldb) p *$3[1]
error: indirection requires pointer operand ('bucket_t' invalid)
(lldb) p $3[1]
(bucket_t) $5 = {
_key = 0
_imp = 0x0000000000000000
}
(lldb) p $3[2]
(bucket_t) $6 = {
_key = 4294971182
_imp = 0x0000000100000a90 (LGTest`-[Person sayHello] at Person.m:12)
}
疑问点
- 为什么
bucket_t可以通过数组的下标拿到?但是又为什么不是数组第一个呢? cache_t里面的_mask和_occupied到底是什么东西?他们的值又是如何来的呢?
3. bucket_t 探索
inline cache_key_t key() const { return _key; }
inline IMP imp() const { return (IMP)_imp; }
inline void setKey(cache_key_t newKey) { _key = newKey; }
inline void setImp(IMP newImp) { _imp = newImp; }
void set(cache_key_t newKey, IMP newImp);
通过查看 bucket_t 里面的方法,分析得出,bucket_t 维护了一个 hash表,以 _key 为 key,_imp 为 value,这也就能说明上面 LLDB 调试的时候为什么通过首地址取不到 sayHello 方法,因为 hash表 是不规律存储的,存储方法的 imp 不知道具体在哪。这也就解释了上面的疑问点1(注:hash表不是本文重点,需要更深入了解的可以自行搜索)
4. _mask、_occupied 深入探索以及方法缓存流程分析
接下来我通过调用方法,打印 cache_t 的内容,又发现了新的问题。
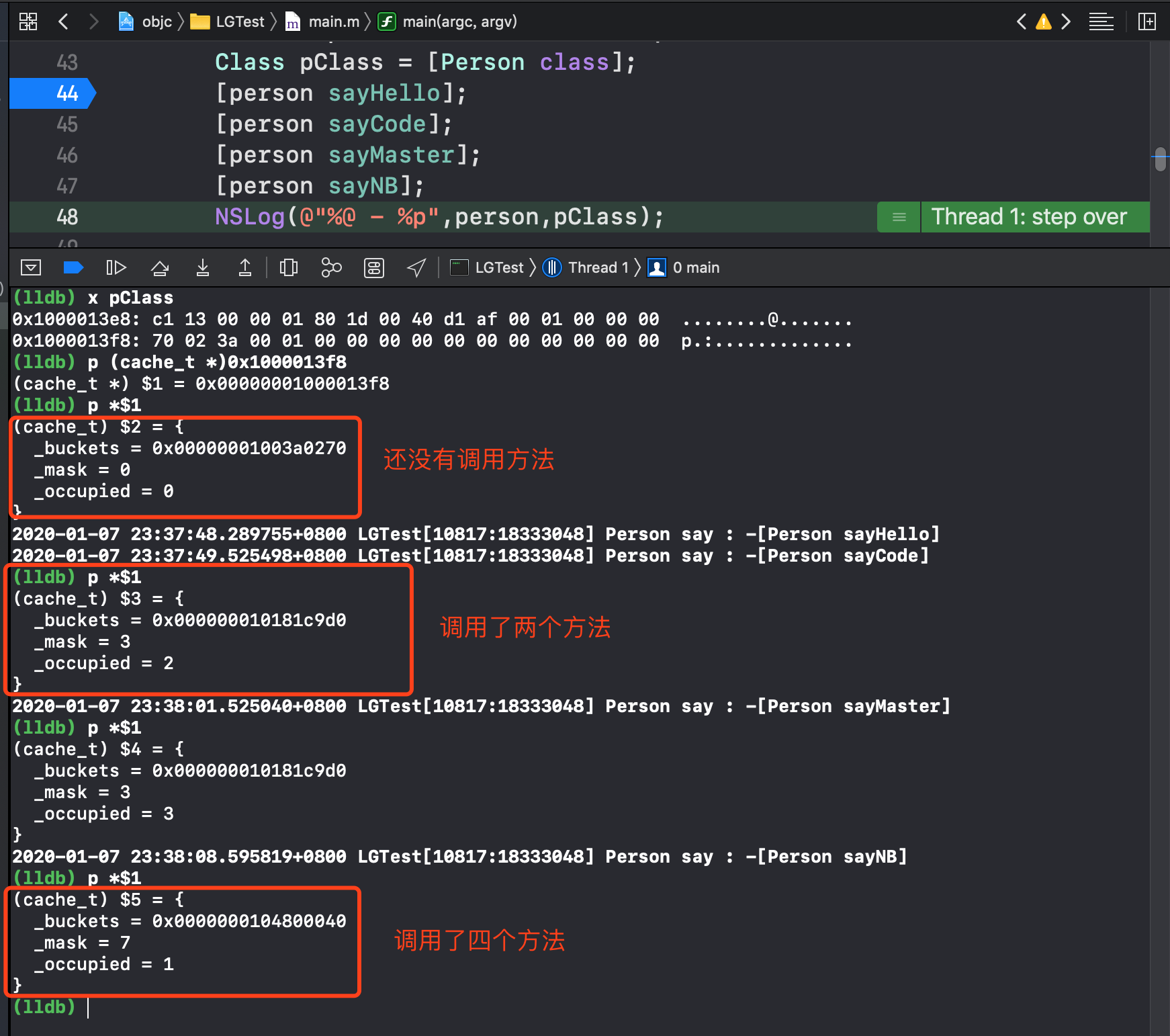
_mask 为0,这可以理解,那为什么调用两个方法或者三个方法之后 _mask 的值为一直3,调用了四个方法之后 _mask 又变成7了呢?这是不是意味着方法的缓存并不是来一个我就存一个,而是底层有自己的一套算法处理方法缓存呢?别急,接下来,我都会一一解答,解答了这个问题,上面的疑问点2也就自然出来了。
- 我来到
cache_t结构体中寻找线索,发现下面三个有关于bucket_t、mask、occupied的方法,然后点进去看一下,都是返回自己的属性,没什么太多研究的,那我们是不是可以搜索一下这些方法在哪里调用了,看能不能找出一点点线索呢?
struct bucket_t *buckets();
mask_t mask();
mask_t occupied();
struct bucket_t *cache_t::buckets()
{
return _buckets;
}
mask_t cache_t::mask()
{
return _mask;
}
mask_t cache_t::occupied()
{
return _occupied;
}
- 接下来我通过全局搜索
mask()方法发现在capacity()里面调用了。
mask_t cache_t::capacity()
{
return mask() ? mask()+1 : 0;
}
- 然后又全局搜索
capacity(),又在扩容expand()的方法里找到了。
enum {
INIT_CACHE_SIZE_LOG2 = 2,
INIT_CACHE_SIZE = (1 << INIT_CACHE_SIZE_LOG2) //等于4
};
void cache_t::expand()
{
cacheUpdateLock.assertLocked();
uint32_t oldCapacity = capacity();
uint32_t newCapacity = oldCapacity ? oldCapacity*2 : INIT_CACHE_SIZE;
if ((uint32_t)(mask_t)newCapacity != newCapacity) {
// mask overflow - can’t grow further
// fixme this wastes one bit of mask
newCapacity = oldCapacity;
}
reallocate(oldCapacity, newCapacity);
}
-
稍微的分析一下这个方法,通过三目运算符判断从
capacity()取出来oldCapacity的值,如果为0则直接返回INIT_CACHE_SIZE也就是4,如果有值则用oldCapacity*2作为newCapacity进行扩容,这就是方法缓存扩容的逻辑。 -
又进行搜索
expand()最终来到了cache_fill_nolock方法,我们来看看这个方法里面都有啥。
static void cache_fill_nolock(Class cls, SEL sel, IMP imp, id receiver)
{
cacheUpdateLock.assertLocked();
// Never cache before +initialize is done
if (!cls->isInitialized()) return;
// 从缓存中查找,有就直接返回
if (cache_getImp(cls, sel)) return;
// 通过 cls 获取当前类的 cache_t
cache_t *cache = getCache(cls);、
// 通过 sel 强转为 key
cache_key_t key = getKey(sel);
mask_t newOccupied = cache->occupied() + 1;
mask_t capacity = cache->capacity();
// 判断当前 cache 是否为空
if (cache->isConstantEmptyCache()) {
// 如果为空,则根据 capacity 开辟空间
// INIT_CACHE_SIZE = (1 << INIT_CACHE_SIZE_LOG2)
// INIT_CACHE_SIZE 的值为 4
cache->reallocate(capacity, capacity ?: INIT_CACHE_SIZE);
}
else if (newOccupied <= capacity / 4 * 3) {
// 什么都不做
}
else {
// 如果 cache 容量大于 3/4 ,就进行扩容
cache->expand();
}
// 通过 key 取出 bucket
bucket_t *bucket = cache->find(key, receiver);
// _occupied++
if (bucket->key() == 0) cache->incrementOccupied();
// 将 imp 通过 key 缓存起来
bucket->set(key, imp);
}
- 分析完这个方法之后,感觉这就是方法缓存流程,于是乎我调用
sayHello方法,然后又通过LLDB走了一遍cache_fill_nolock的流程。 - 总结如下:
当对象第一次调用方法,newOccupied 为1,capacity 为0,则需要进行开辟缓存空间 cache->reallocate(capacity, capacity ?: INIT_CACHE_SIZE);
void cache_t::reallocate(mask_t oldCapacity, mask_t newCapacity)
{
bool freeOld = canBeFreed();
bucket_t *oldBuckets = buckets();
bucket_t *newBuckets = allocateBuckets(newCapacity);
assert(newCapacity > 0);
assert((uintptr_t)(mask_t)(newCapacity-1) == newCapacity-1);
// newCapacity 为 4
setBucketsAndMask(newBuckets, newCapacity - 1);
if (freeOld) {
cache_collect_free(oldBuckets, oldCapacity);
cache_collect(false);
}
}
void cache_t::setBucketsAndMask(struct bucket_t *newBuckets, mask_t newMask)
{
mega_barrier();
_buckets = newBuckets;
mega_barrier();
_mask = newMask;
_occupied = 0;
}
在这个方法里面开辟了为4大小的 newBuckets,然后进行设置 _mask 和 _occupied,所以这就是上面 _mask 为3的原因。当开辟完空间之后,会先通过 key 去 cache 里面查找,找到了就返回 bucket_t,如果没有找到 key 对应的 bucket_t ,或者是空的 bucket_t, 就会调用 bad_cache,找到了之后在最后会将这个方法加入进缓存 bucket->set(key, imp);。
当调用多个不相同的方法,newOccupied 超出了 capacity 的 3/4时,就需要进行扩容,扩容的逻辑在上面已经写明,此处不再重复。但是这里需要注意的一点是,再进行扩容的时候,会将之前的数据全部抹掉,然后把超出扩容时调用的方法存进缓存。
三、总结
- 类结构中的
cache_t是进行方法缓存的,为了调用相同的方法而不需要去进行慢速查找流程,直接通过key找到imp,加快方法调用效率,当然在进行缓存的时候使用了非常经典的LRU算法,使得读取和写入更加迅速。
