

1. 写在前面
首先看个 🌰
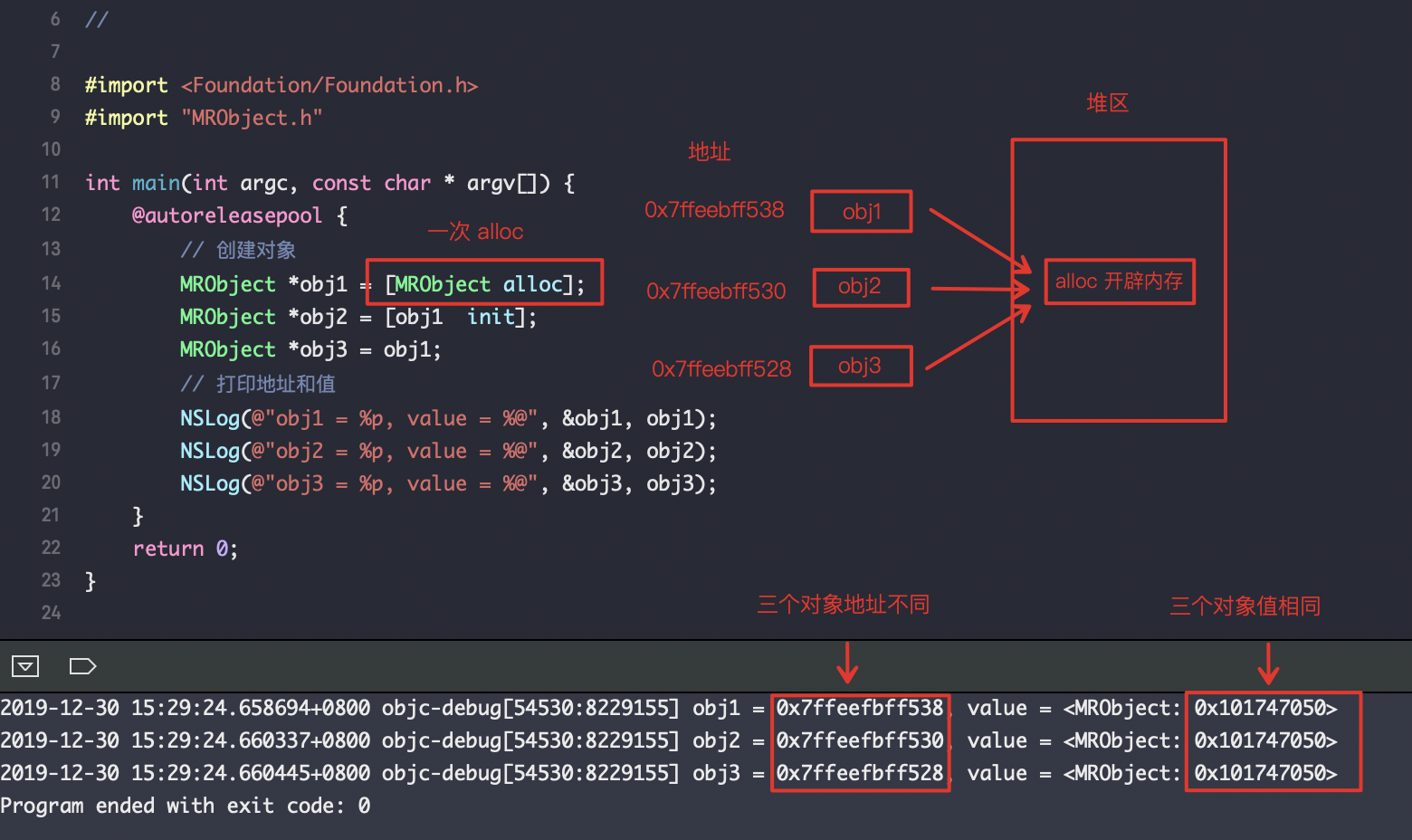
从图中我们可以看出,三个对象的地址都不相同,因为这是声明的三个不同的对象,但是值都是指向的同一个地址,而是由于他们都是通过 obj1 这个对象赋值,指向的都是同一个对象,而这个对象是通过 alloc 方法创建的,而且 obj2 调用了 init方法之后还是相同的值,说明这个对象就是被alloc方法创建然后返回的。
NSObject 对于 iOSer 来说或许已经熟悉得不能再熟悉,开发中大部分的对象都是继承子它,创建的对象都是基于 NSObject 类,同时也提供了很多方法;万物皆有出处,深入思考后我们可能会疑惑到底这个对象是怎么生成的,底层做了什么处理,有哪些不一样的设计思想和实现方式;因此让我们一起开启三顾 alloc 旅程。
2. 探索姿势
要探险首先也得做好攻略,准备生存装备和技能;那么探索源码,也需要正确的知(姿)识(势),才不会导致摸不到方向,无功而返,这里介绍三种姿势供大家入门 ^_^ 。
普通断点设置 + 跟踪调试
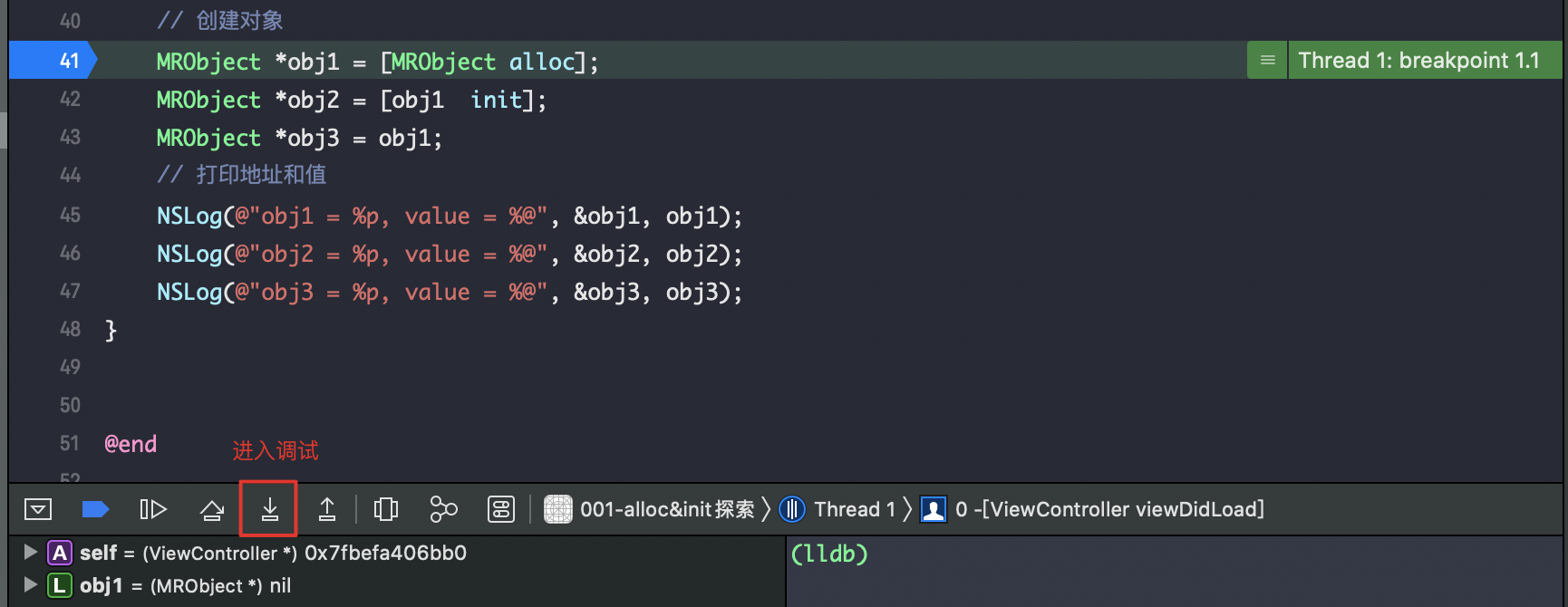
按住control + in 进入调试查看汇编调用信息;这里没有以为是模拟器环境,所以没有跟踪到objc_alloc的相关信息;使用真机情况下能看到定位到 libobjc.A.dylib objc_alloc,所以是要探究的方法在 libobjc.A.dylib 这个库中。
符号断点设置
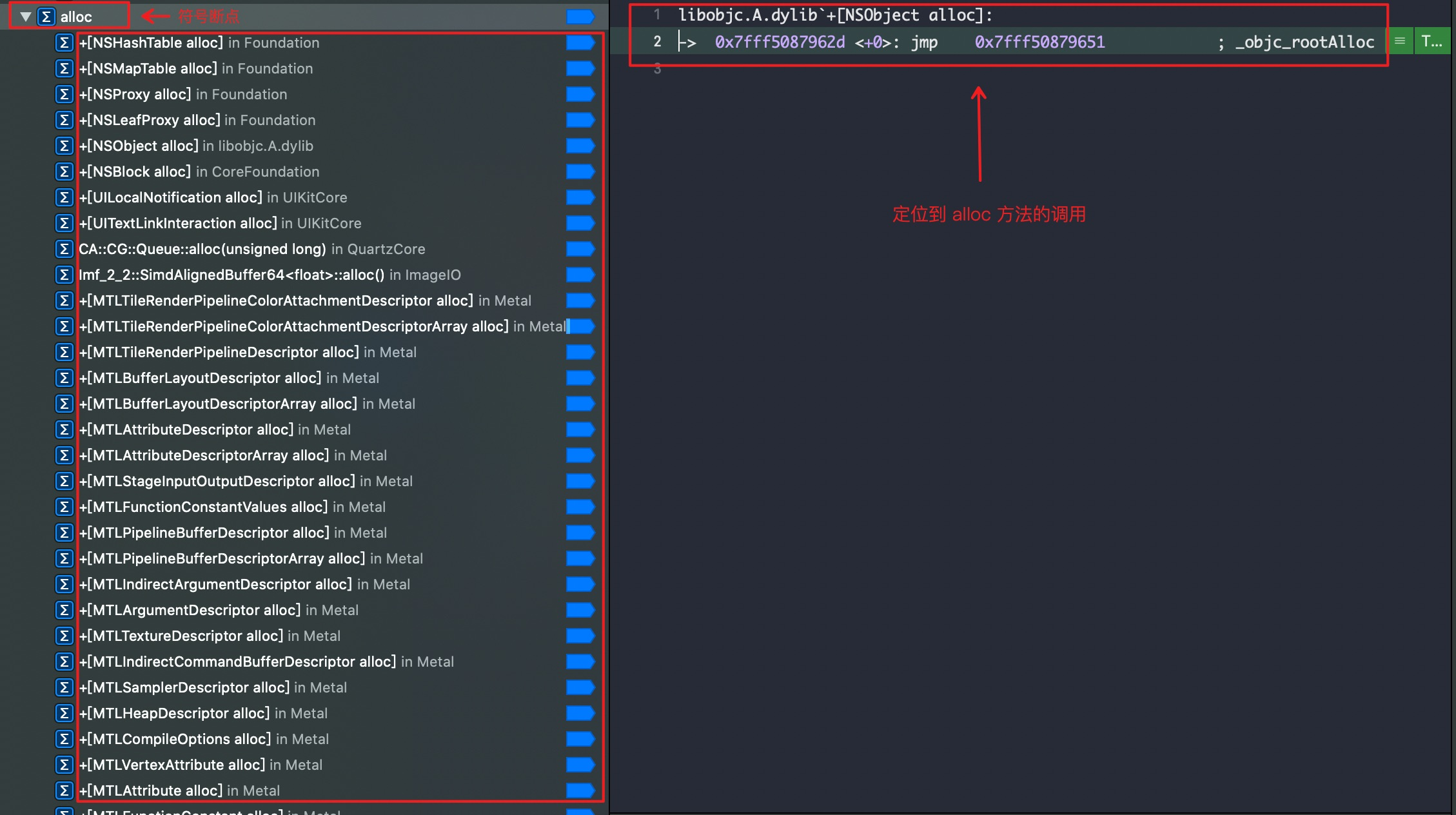
要探究alloc方法,所以我们添加一个alloc的符号断点,这时候会显示断到很多类的alloc方法,但是没有关系,因为我们断点了代码所在对象,所以我们直接调试就行;断点执行下一步,就能看到 libobjc.A.dylib + [NSObject alloc],说明是调用了libobjc.A.dylib库中的NSObject 的 alloc 类方法。
汇编跟踪
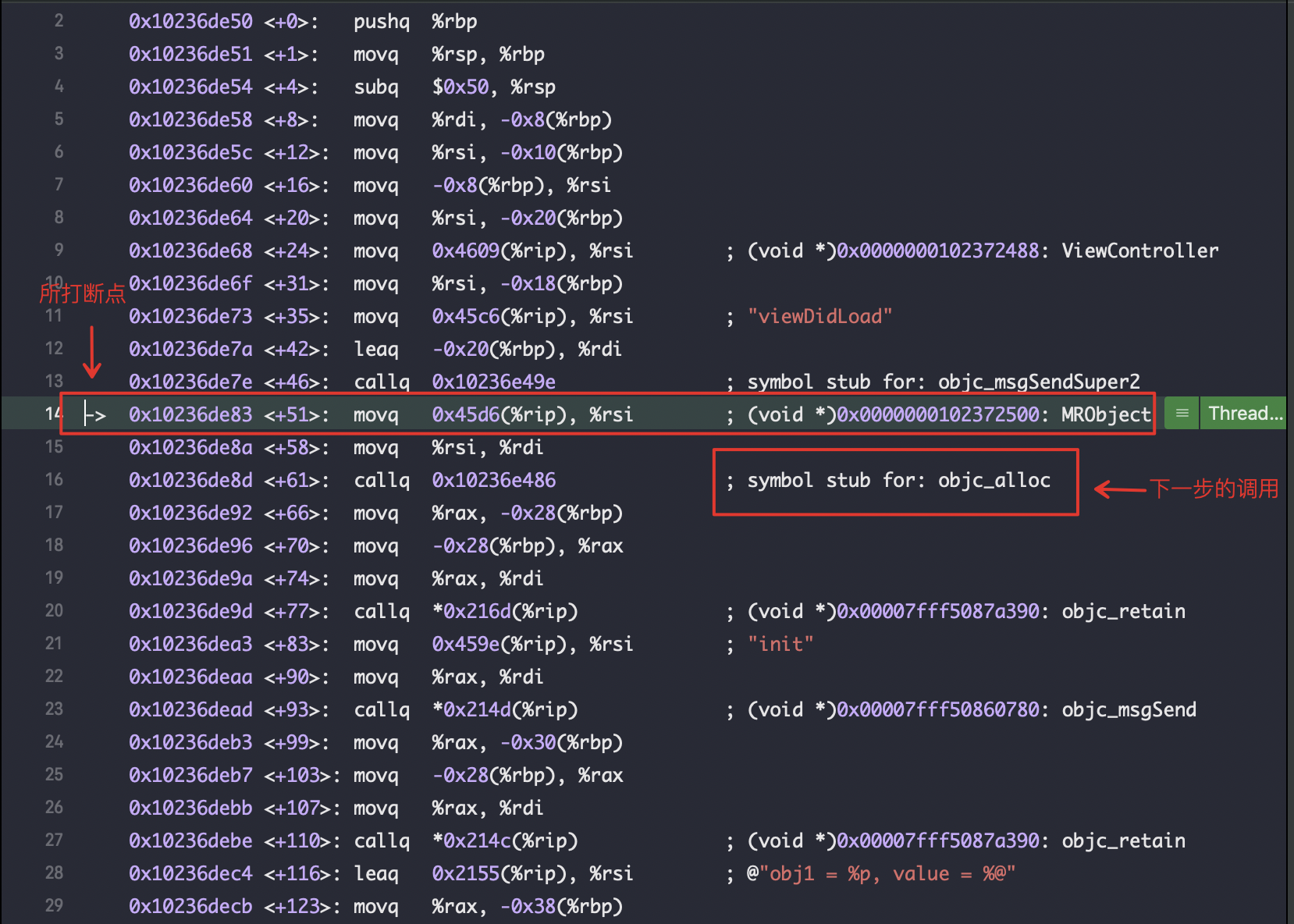
[MRObject alloc]的汇编代码下一步是调用objc_alloc; 所以我们需要研究objc_alloc方法即为alloc的底层实现方法!
objc 源码
苹果开源源码地址 => opensource.apple.com/tarballs/
搜索 objc 即可看到 objc 源码地址 当前 objc4-756.2 为最新版本!
ps: 在objc源码中我们看到很多 old 和 new 的文件命名标识,这代表objc在迭代过程中过渡了两个版本,一个新版,一个旧版,现在我们都是使用的新版本api,所以查看源码逻辑的时候只需要定位 objc2 或者 new标识的新版本~
源码调试准备条件
通过查看objc源码和汇编的指令查看 objc_alloc 的流程发现很难定位跟踪,不能直观的跟踪到具体的调用方法路径;所以将objc源码集成到我们的调试工程中,通过打断点调试跟踪才能一目了然,畅通无阻,所向披靡...以上一切都是理想YY,hahaha... ^_^;如何集成objc源码,移步 => iOS_objc4-756.2 最新源码编译调试
流程调试
alloc => objc_rootAlloc
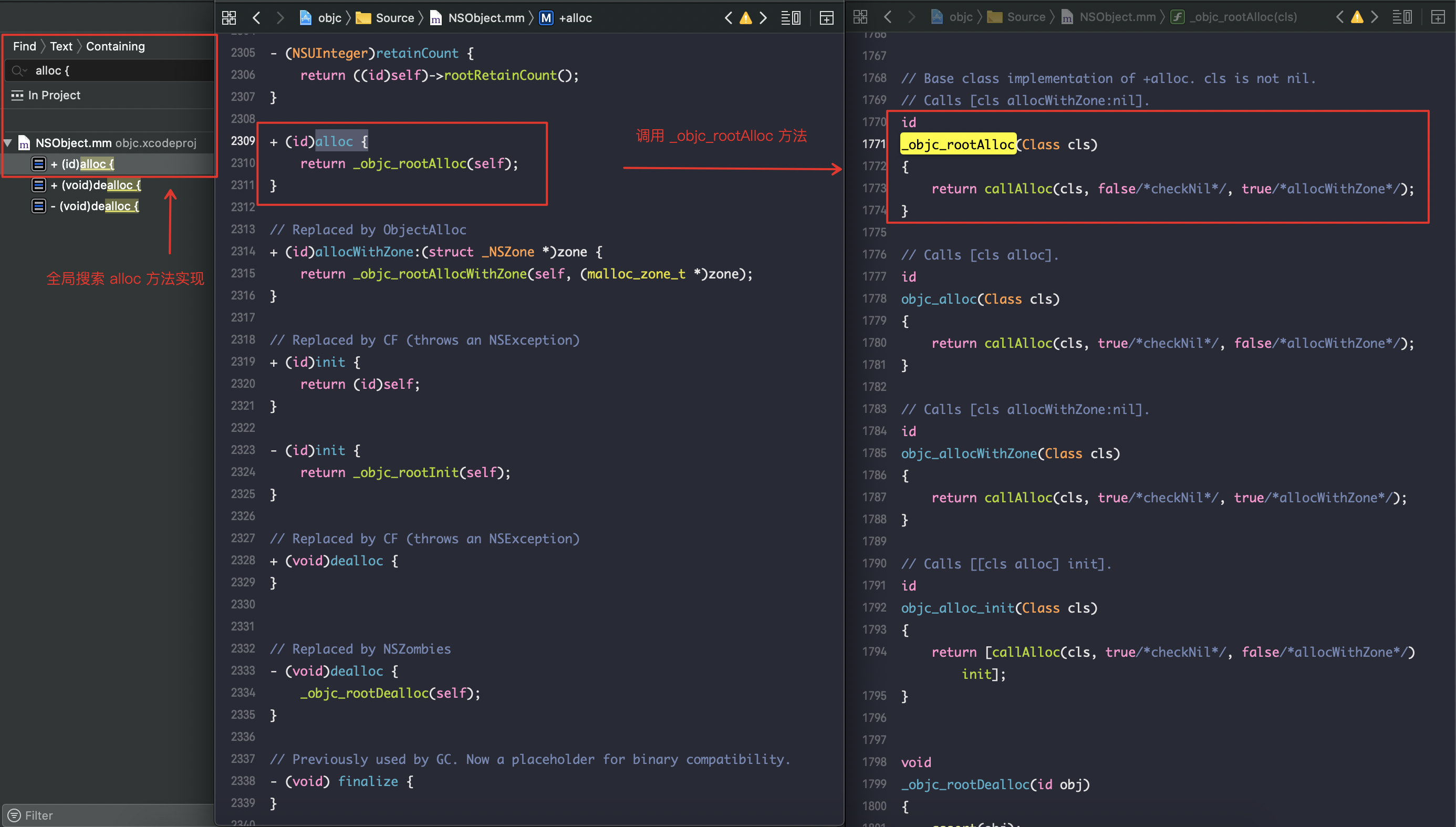
callAlloc
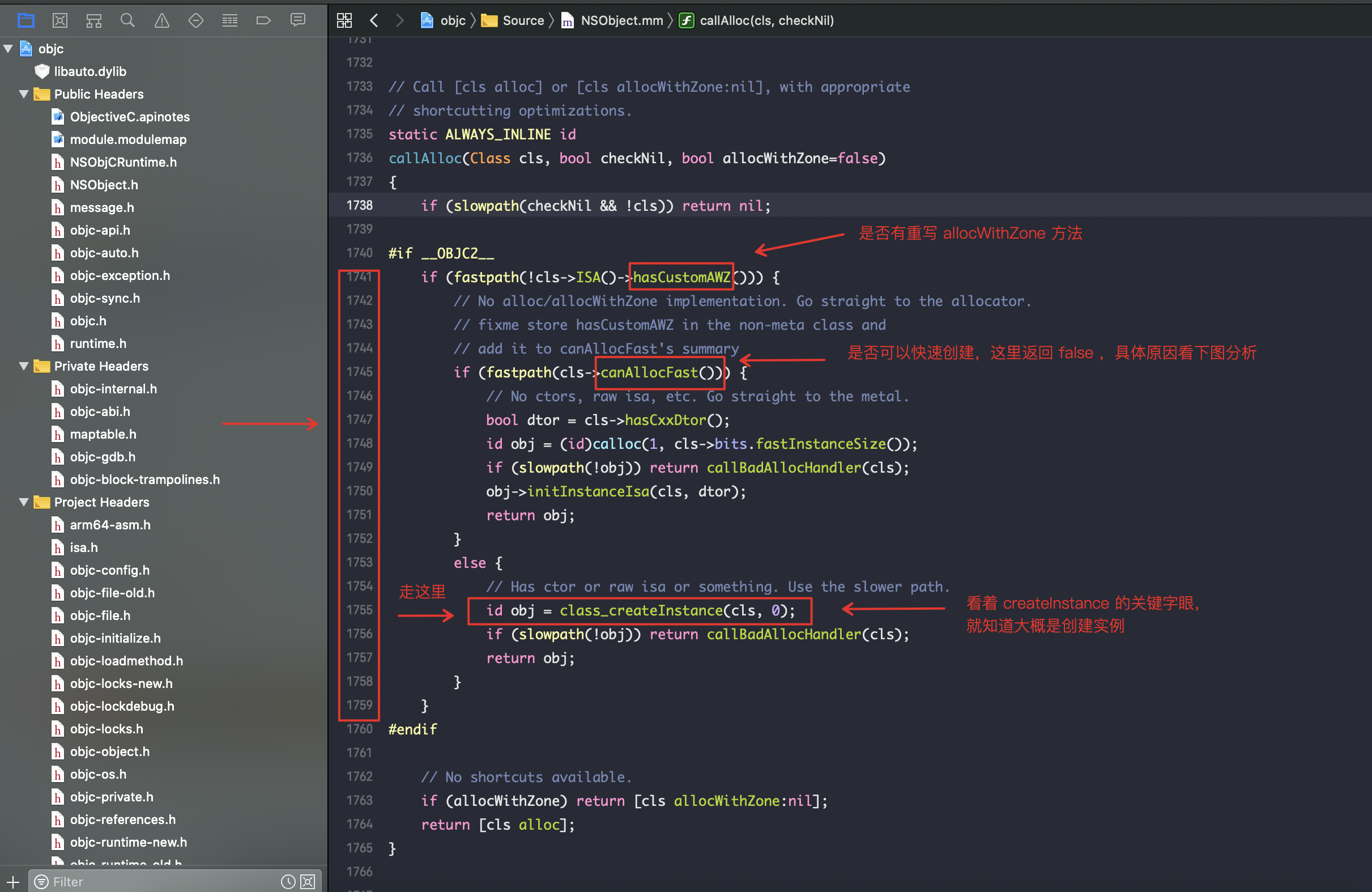
首先看 __OBJC2__的分支,现在是使用的新版本;然后看第一个判断fastpath(!cls->ISA()->hasCustomAWZ()),这里是判断该类是否有重写initWithZone;第二层判断 fastpath(cls->canAllocFast()),是否可以快速创建,这里会返回false,具体实现见下分析。
canAllocFast
调用 bits.canAllocFast方法
bool canAllocFast() {
assert(!isFuture());
return bits.canAllocFast();
}
跟踪 canAllocFast 实现
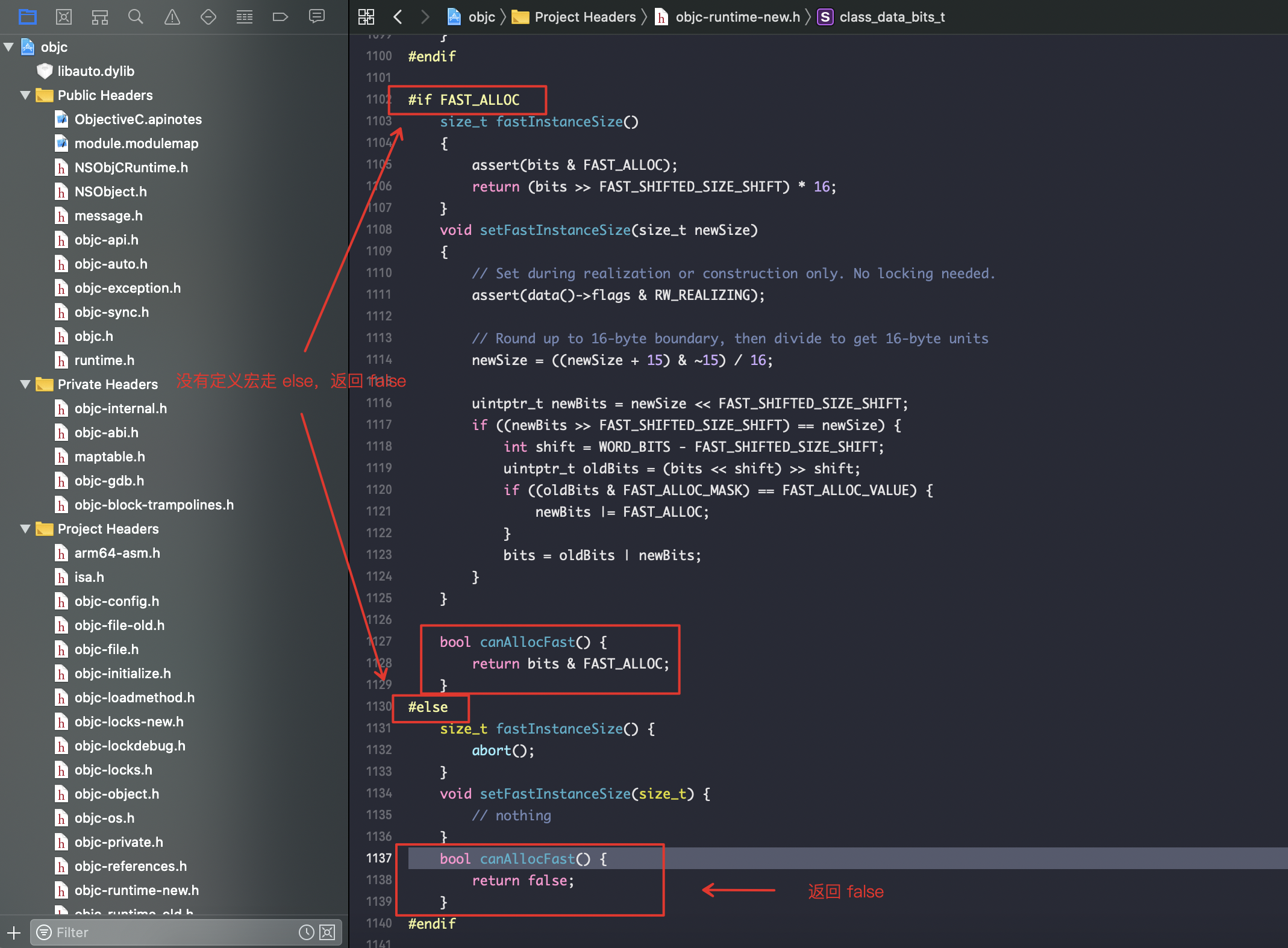
查看 FAST_ALLOC 宏定义
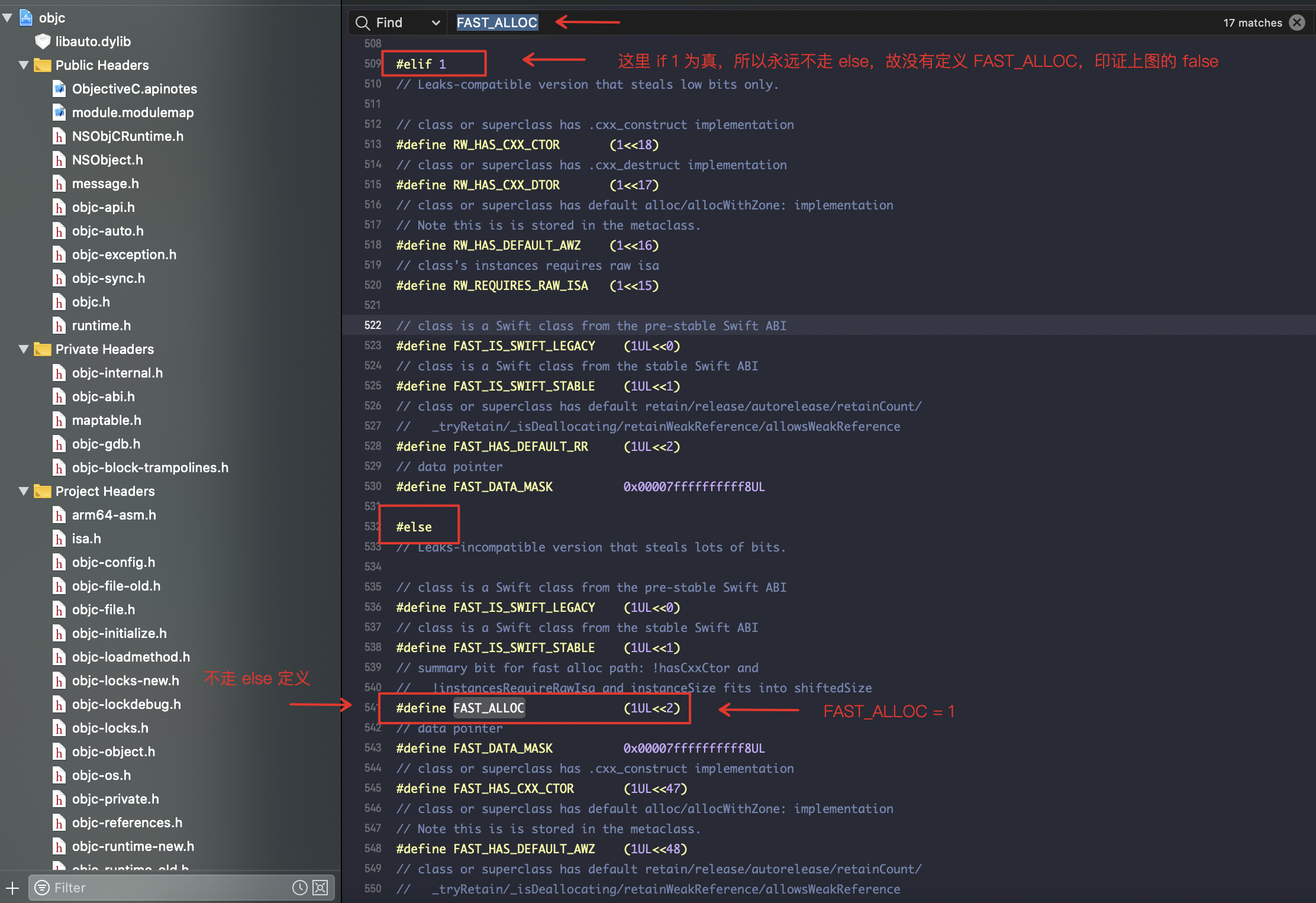
class_createInstance
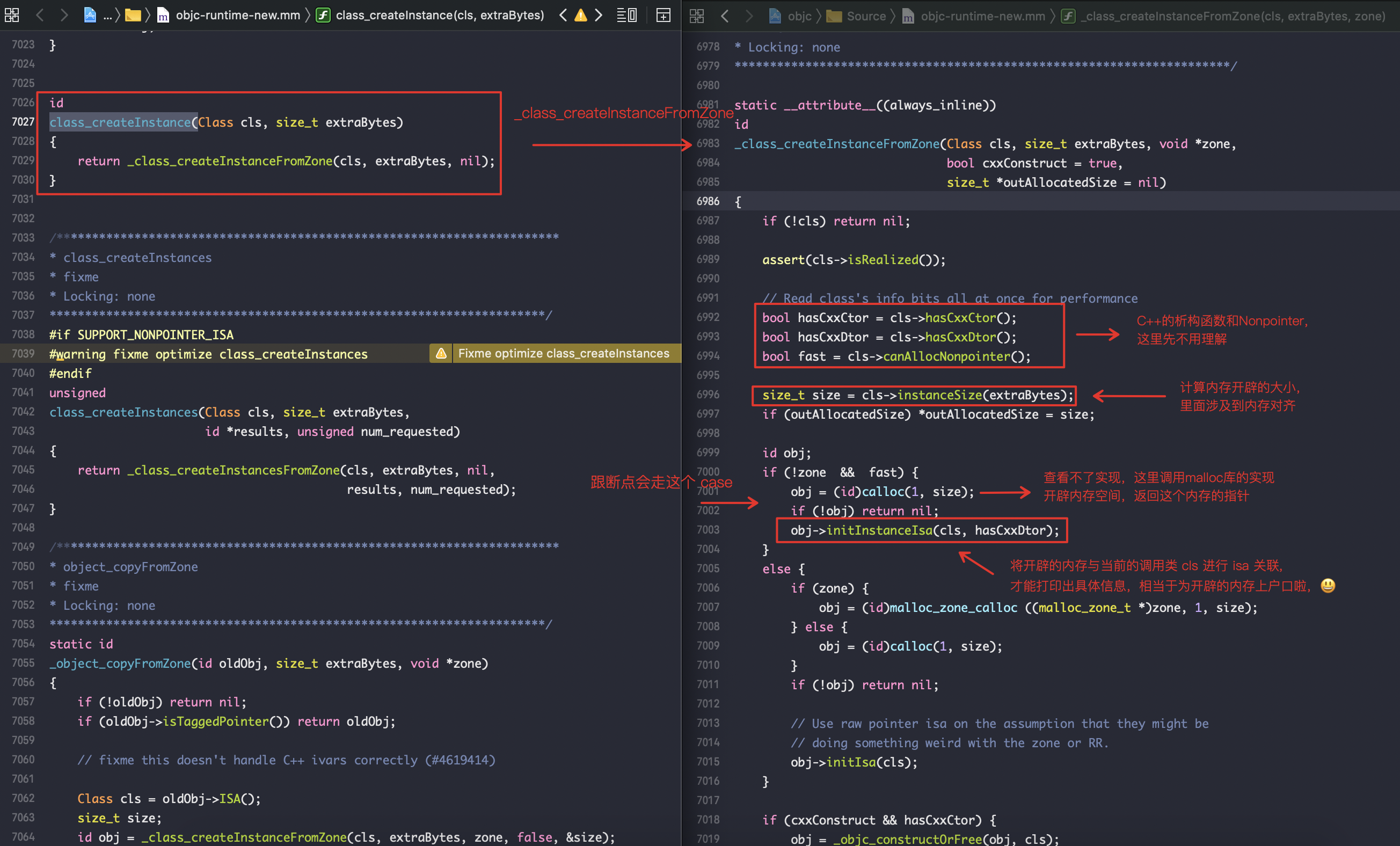
打印obj的值,印证流程
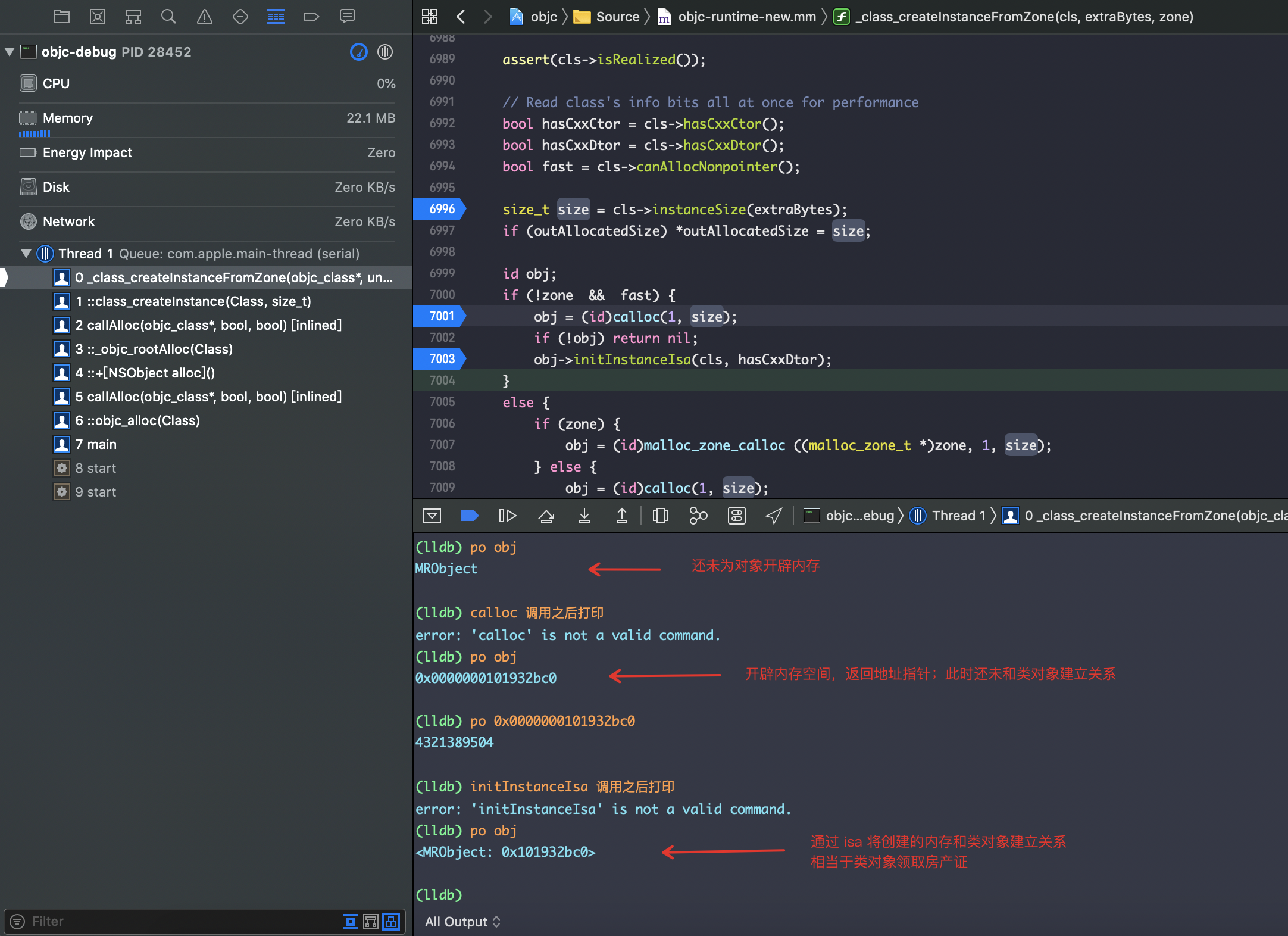
申请内存之字节对齐
什么是字节对齐
现代计算机中,内存空间按照字节划分,理论上可以从任何起始地址访问任意类型的变量。但实际中在访问特定类型变量时经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序一个接一个地存放,这就是字节对齐。
对齐的原因和作用
不同硬件平台对存储空间的处理上存在很大的不同。某些平台对特定类型的数据只能从特定地址开始存取,而不允许其在内存中任意存放。例如Motorola 68000 处理器不允许16位的字存放在奇地址,否则会触发异常,因此在这种架构下编程必须保证字节对齐。
但最常见的情况是,如果不按照平台要求对数据存放进行对齐,会带来存取效率上的损失。比如32位的Intel处理器通过总线访问(包括读和写)内存数据。每个总线周期从偶地址开始访问32位内存数据,内存数据以字节为单位存放。如果一个32位的数据没有存放在4字节整除的内存地址处,那么处理器就需要2个总线周期对其进行访问,显然访问效率下降很多。
因此,通过合理的内存对齐可以提高访问效率。为使CPU能够对数据进行快速访问,数据的起始地址应具有“对齐”特性。比如4字节数据的起始地址应位于4字节边界上,即起始地址能够被4整除。
此外,合理利用字节对齐还可以有效地节省存储空间。但要注意,在32位机中使用1字节或2字节对齐,反而会降低变量访问速度。因此需要考虑处理器类型。还应考虑编译器的类型。在VC/C++和GNU GCC中都是默认是4字节对齐。
对齐原则
1.数据类型自身的对齐值:char型数据自身对齐值为1字节,short型数据为2字节,int/float型为4字节,double型为8字节。
2.结构体或类的自身对齐值:其成员中自身对齐值最大的那个值。
3.指定对齐值:#pragma pack (value)时的指定对齐值value。
4.数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中较小者,即有效对齐值=min{自身对齐值,当前指定的pack值}。
instanceSize 获取实例对象内存大小
size_t instanceSize(size_t extraBytes) {
// 对齐的大小 + extraBytes(额外加的字节数)
size_t size = alignedInstanceSize() + extraBytes;
// CF requires all objects be at least 16 bytes.
// 这里选择最小16,因为已经至少8字节了,为了防止在读取或者存储的时候多线程越界之类的安全性;16处于一个基本的合理节约的大小,cup读取的时候比较合理
if (size < 16) size = 16;
return size;
}
字节对齐
// alignedInstanceSize
// Class's ivar size rounded up to a pointer-size boundary.
uint32_t alignedInstanceSize() {
// 调用 unalignedInstanceSize 获取内存字节大小,然后调用 word_align 方法对齐
return word_align(unalignedInstanceSize());
}
#ifdef __LP64__
# define WORD_SHIFT 3UL
# define WORD_MASK 7UL // 7
# define WORD_BITS 64
#else
# define WORD_SHIFT 2UL
# define WORD_MASK 3UL
# define WORD_BITS 32
#endif
// 对齐算法 (8字节对齐)
// ps: &与运算,同为1则为1,否为0;|或运算,一个为1则为1,否为0;^异或运算,两个不相同则为1,否为0;~非运算,取反
static inline uint32_t word_align(uint32_t x) {
// WORD_MASK = 7,先非运算,然后与运算,二进制
// 例如这里是 x = 8; 因为 MRObject 类结构我们没有声明其他属性之类的,只有默认包含的 isa 属性结构,占用8字节
// x+mask = 8 + 7 = 15 => 0000 1111
// mask => 0000 0111
// ~7 非运算,取反
// a => 1111 1000
// & 与运算,同时为1则为1
// x+mask => 0000 1111
// return 8 => 0000 1000
// 本质就是 mask = 7 操作 => 得到8的倍数,8字节对齐,以8为倍数;相当于 x >> 3 << 3, 右移三位,左移三位 (枚举定义也是如此,计算快速)
return (x + WORD_MASK) & ~WORD_MASK;
}
// May be unaligned depending on class's ivars.
uint32_t unalignedInstanceSize() {
assert(isRealized());
// 对象的实例内存字节大小,是根据类的ivarList、methodList、propertyList、protocolList 等相关的属性相加计算出来的
// 这些数据存储在类结构中的 data 段的 ro 结构中,这里通过 ro 获取具体需要创建的字节数大小
return data()->ro->instanceSize;
}
可能会疑惑为什么需要8字节对齐,(⊙o⊙)…???
cpu读取的时候不知道连续的内存开辟的大小,访问的时候可能一个1字节,4字节,8字节...,然后读取的时候需要先判断多长然后在读取,比较麻烦;因此cpu就想着如果每一段都是8字节那么读取的时候就比较方便,空间换取时间。
印证字节对齐
怎么印证自己对齐呢,那么我们通过LLDB调试打印对象内存结构,查看信息来验证。
首先类声明几个属性:
@property (nonatomic, copy) NSString *name; // 8个字节
@property (nonatomic, assign) int age; // 4个字节
@property (nonatomic, assign) long height; // 8个字节
@property (nonatomic, copy) NSString *hobby; // 8个字节
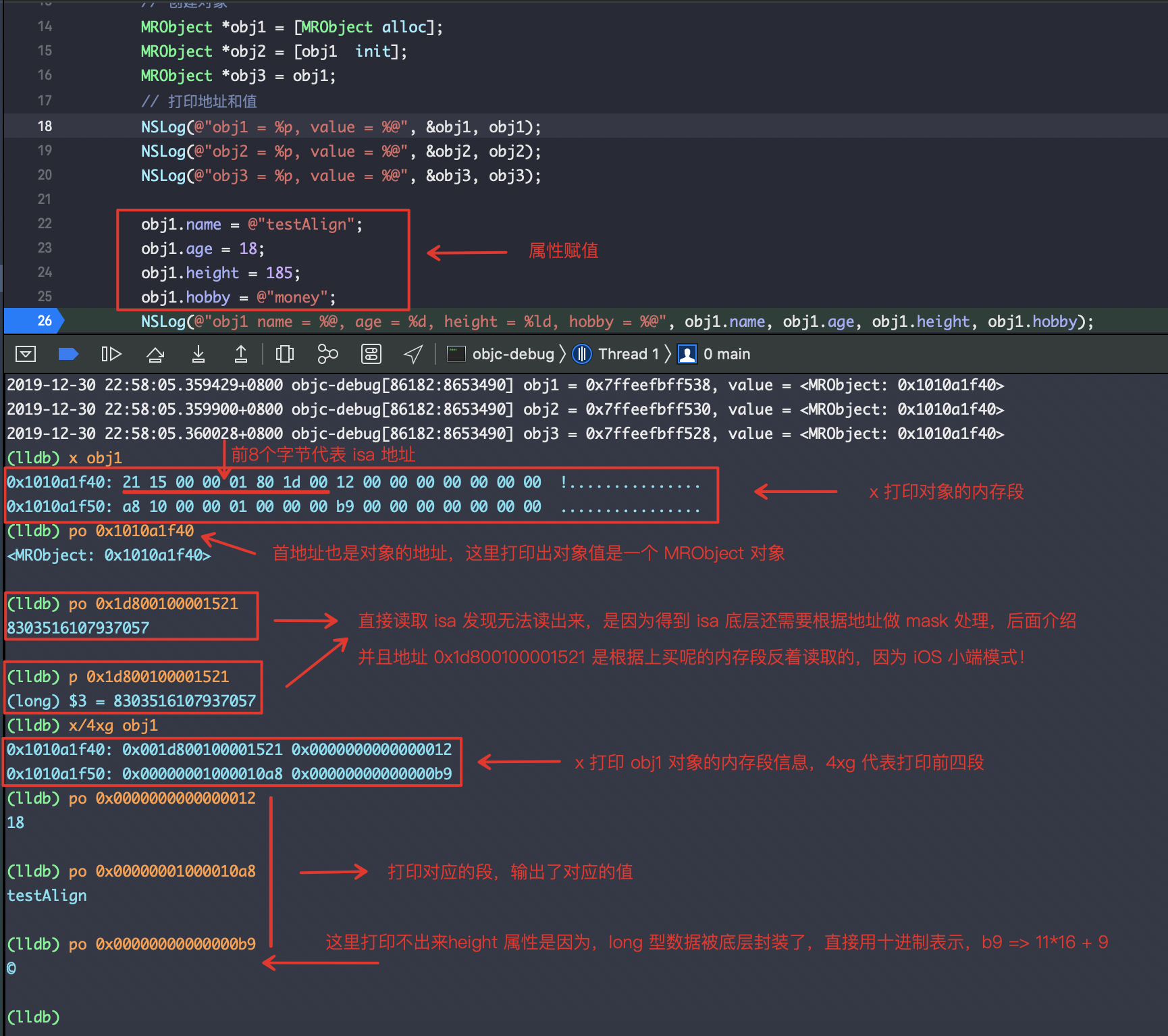
😤说好的能全部打出呢,嗯哼?为啥没能访问到hobby呢?这是因为我们只打印了四段内存地址,而加上isa 一共是默认5个属性,所以hobby在第五段内存,下面是打印日志信息😺。
(lldb) x/5xg obj1
0x1010a1f40: 0x001d800100001521 0x0000000000000012
0x1010a1f50: 0x00000001000010a8 0x00000000000000b9
0x1010a1f60: 0x00000001000010c8
(lldb) po 0x00000001000010c8
money
alloc 流程图

结束语
以上为简要分析alloc流程,有歧义欢迎指出,持续更新进阶之旅,未完待续。。。
