

前言
我们上一篇的时候说了这篇会把Kafka的网络模型给梳理一下,这个和 NIO 的那篇关系就非常非常大了,所以如果对这块不了解的朋友可以跳转过去瞧瞧,起码对你理解起来会有一定的帮助
那我们就接着上一篇的流程继续,标题中的RecordAccumulator很快就讲到
回顾上一讲 Kafka 拉取元数据的流程
上一讲我们虽然码了大概有7600多字,可是其实根本就没跳出第一步,所以这东西真的工程量挺大的
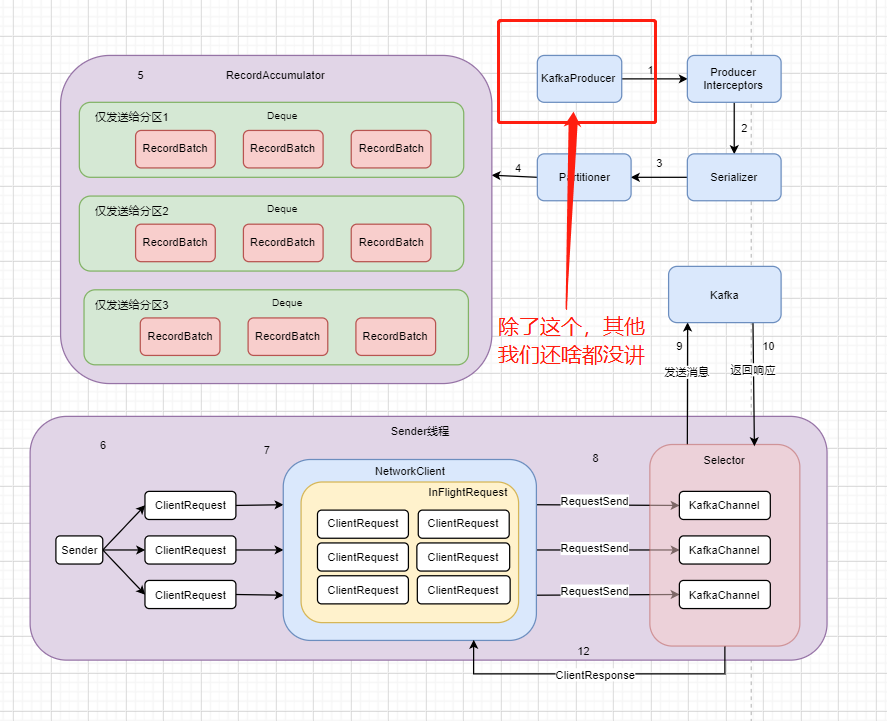
现在让我们用一个流程图去把那7000多字给浓缩一下吧
首先我们的 KafkaProducer 作为主线程,它要去发送消息给我们的 Kafka 集群,可是发送给集群需要什么?需要元数据呀!不知道元数据,那我就不知道leader partition是哪个了
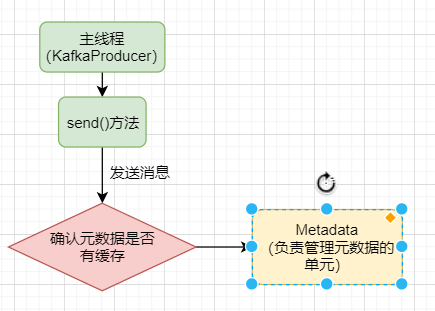
此时主线程就会从 Metadata 那里去找看有没有元数据的缓存,也就是是否曾经拉取过了,但是我们假设现在我们是第一次启动,所以明显是没有的,那没有元数据的情况
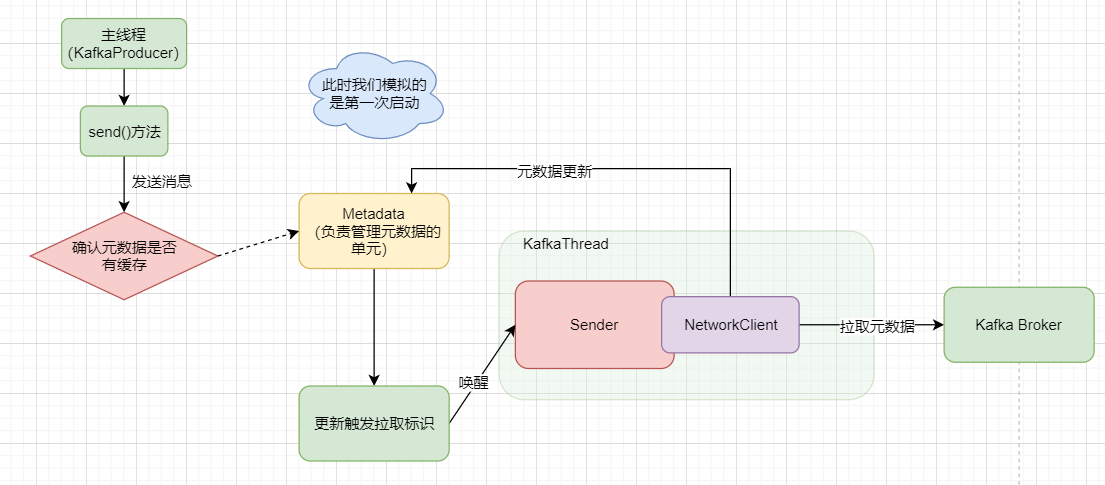
此时我们要拉取一个version的值,并把一个 needUpdate 参数修改为true,然后去唤醒 Sender 线程去拉取元数据,而这需要通过一个网络组件 NetworkClient 和Broker通信。
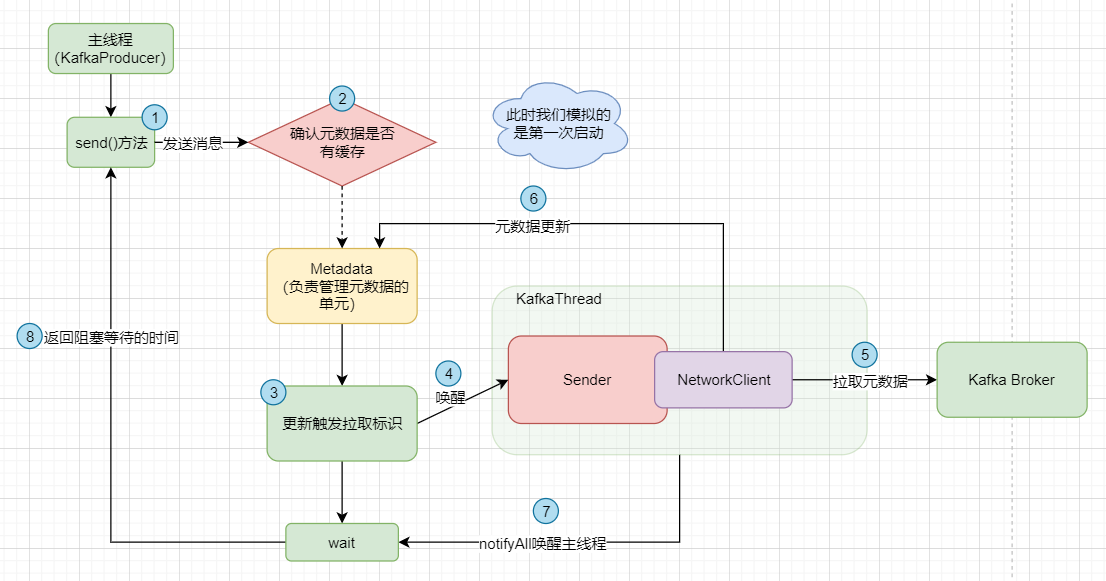
在此同时,主线程会进行阻塞,等待元数据的到来。而当元数据拉取完成后,会通过 notifyAll 唤醒主线程,返回阻塞等待的时间。
好的,图中已经标好了逻辑顺序,其实大致的步骤就是这样,至于更多的细节,那就跳转到上一篇:Kafka源码篇 --- 小白也能看懂的Producer的初始化及元数据获取流程,在本地的idea导入源码去跟着走一遍吧😁
一、ProducerInterceptors
那我们上一篇其实就是讲了 KafkaProducer 这一个东西,此时有小伙伴就要问了,这图不是中间还画着个 ProducerInterceptors 吗,其实它是存在于 KafkaProducer 的初始化流程中的,这个拦截器的作用其实就是过滤掉一些不必要的请求,
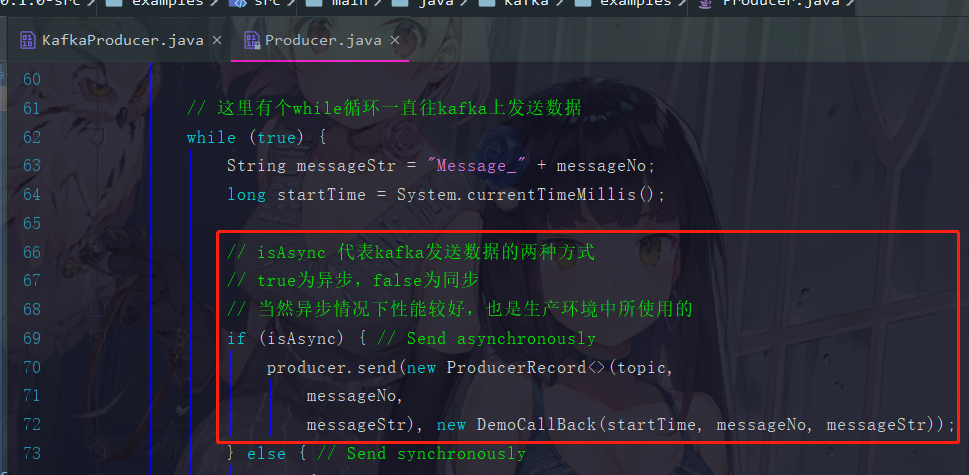
但是这个 “不想发送某些消息” 的功能我在这个发送消息的时候进行判断也就可以了,所以就显得比较鸡肋,就直接跳过了。
二、Serializer
那序列化的那部分
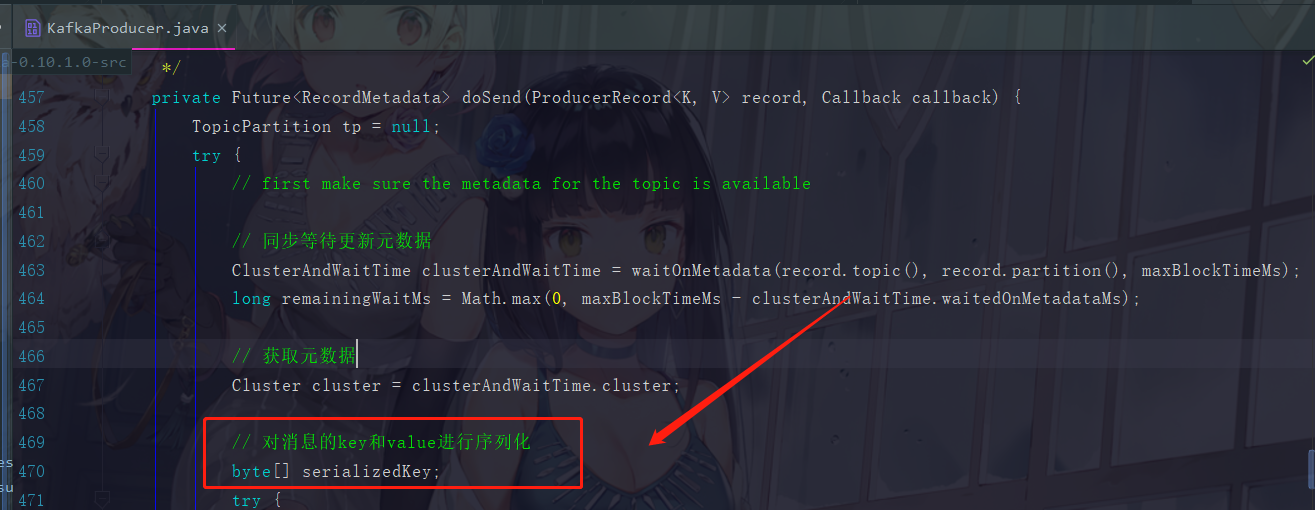
这个序列化的功能在example包里面的Producer.java进行了设置
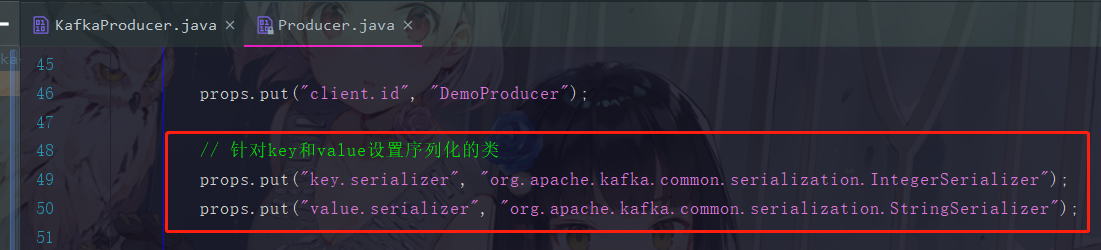
这两个一个Integer类型,一个String类型的,也是Kafka自己定制好的,且正常情况下,根本就不需要自己去自定义一些序列化格式。
三、Partitioner
回到 KafkaProducer 中获取到元数据后的下一句

点进去 partition() 方法
3.1 分区方法 partition() 流程
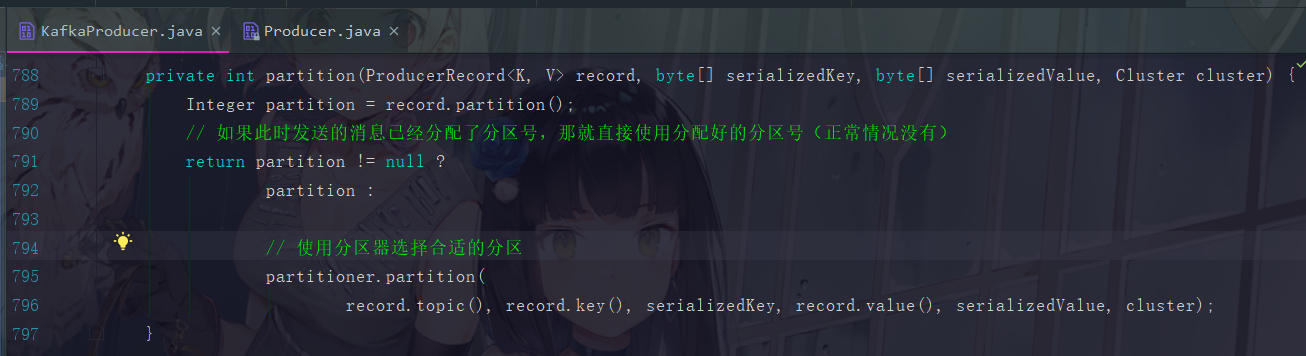
我们可以看到这里对 “ 是否已经存在分区号 record ” 进行了判断,正常来说消息过来这里的时候都是自身并不自带分区号的,那要这个判断做啥子用?
这也是因为重试机制的问题,如果一条消息之前已经走过了这里,那就分配上分区号了,可是由于种种原因这条消息没发送成功,但因为Kafka的重试机制重新发送了,那这时我们就不再给它分配了,直接用上一次的分区号即可。
根据我们的场景驱动,现在是第一次进来,所以肯定是要走下方的分支,也就是消息肯定都还是没有分区号的。所以第一句
Integer partition = record.partition();
这个结果肯定是null,然后执行
partitioner.partition(record.topic(), record.key(),
serializedKey, record.value(), serializedValue, cluster);
这个 partitioner 参数就是 Kafka 自带的分区器,点进去可以看到
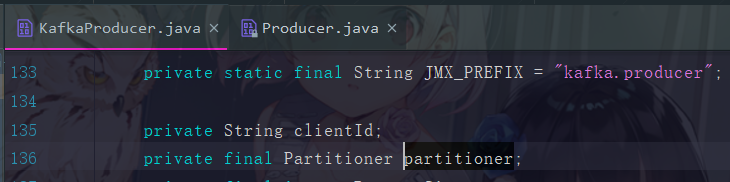
这个 Partitioner 接口有一个 partition 方法和一个 close 方法,如果真的想自定义分区器,也可以直接模仿 DefaultPartitioner ,也就是默认的分区器中的代码来自行实现
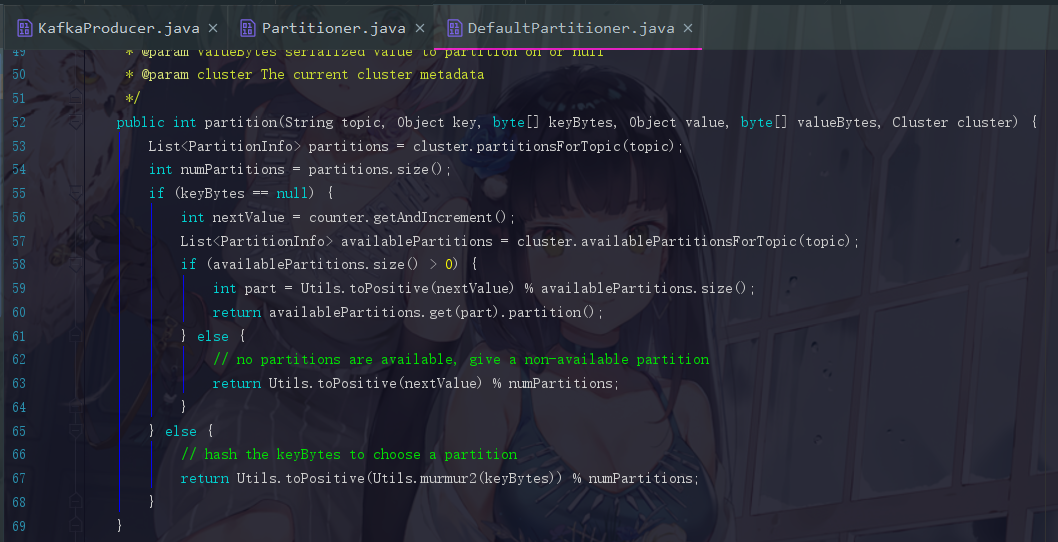
3.2 DefaultPartitioner的分区逻辑
DefaultPartitioner的默认处理方式在这里展开一下
3.2.1 定义一个随机数
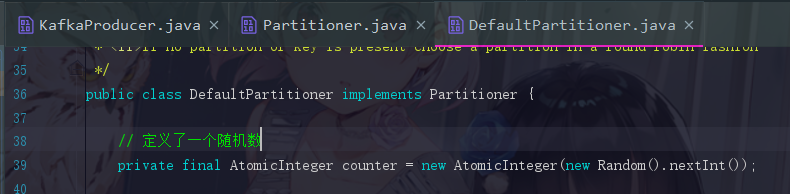
这个实现类的一开始就定义好了一个随机数,是用于处理不指定key的消息的,怎么用后面会提到
3.2.2 主要的 partition 方法
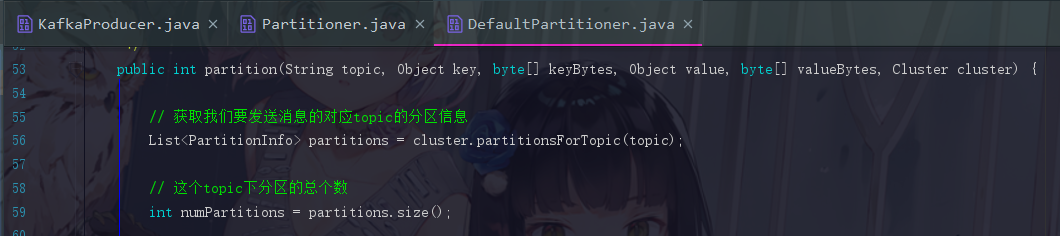
这个方法一开始先把分区数获取过来。然后就是两个分支,这两个分支为 “消息是否指定key” 的不同方案
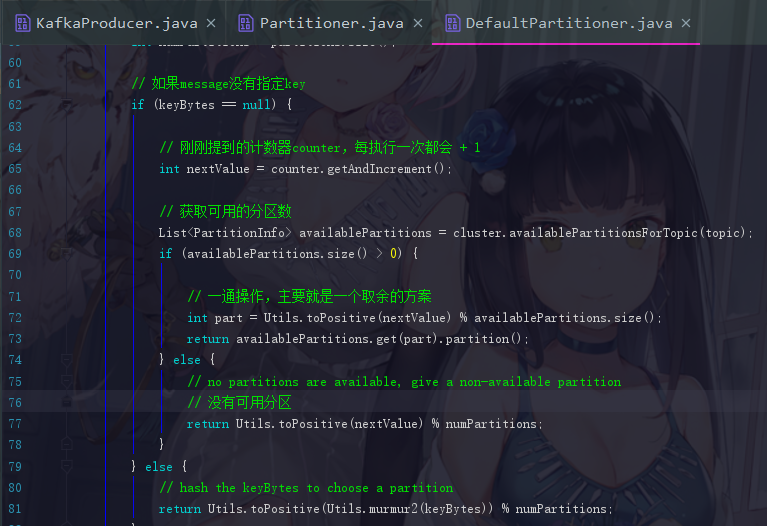
现在来结合实际的数字说明一下那一通操作到底是怎么操作的,假设我们刚刚取得的 counter 就是10(此时 counter 随机到负数也没关系,toPositive()方法会将负数取绝对值),可用分区数也是10,那 nextValue 就是11,那11 % 10 = 1,那我们的第一条消息就是丢到第一个分区下的。然后下一次,nextValue 变为12,对 10 取余结果为 2 ,那就丢到第二个分区下···依次类推,就是 通过一个简单的轮询来达到负载均衡的效果 ,因为消息基本都会按顺序地去填到分区中。
而如果指定了 key ,就直接对 key 取得一个 hash 值,然后用 hash值 % 可用分区总数 取模,这种方法如果 key 相等,那计算出来的一定会是同一个分区,所以如果当我们想要把某类消息都发送至同一个分区时,就可以指定 key 来实现。
四、验证消息的大小
在分区完成后,我们要进行消息大小的验证
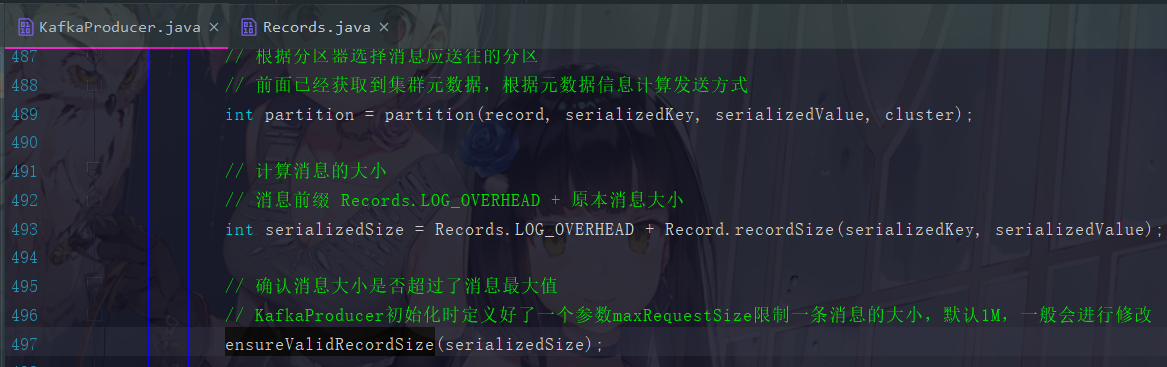
这里一条消息的大小是 Records.LOG_OVERHEAD + 消息本身的大小,然后进行一个ensure的验证方法
4.1 Records.LOG_OVERHEAD
消息前缀固定为12个字节大小,这个可以点进去 Records.java 查看
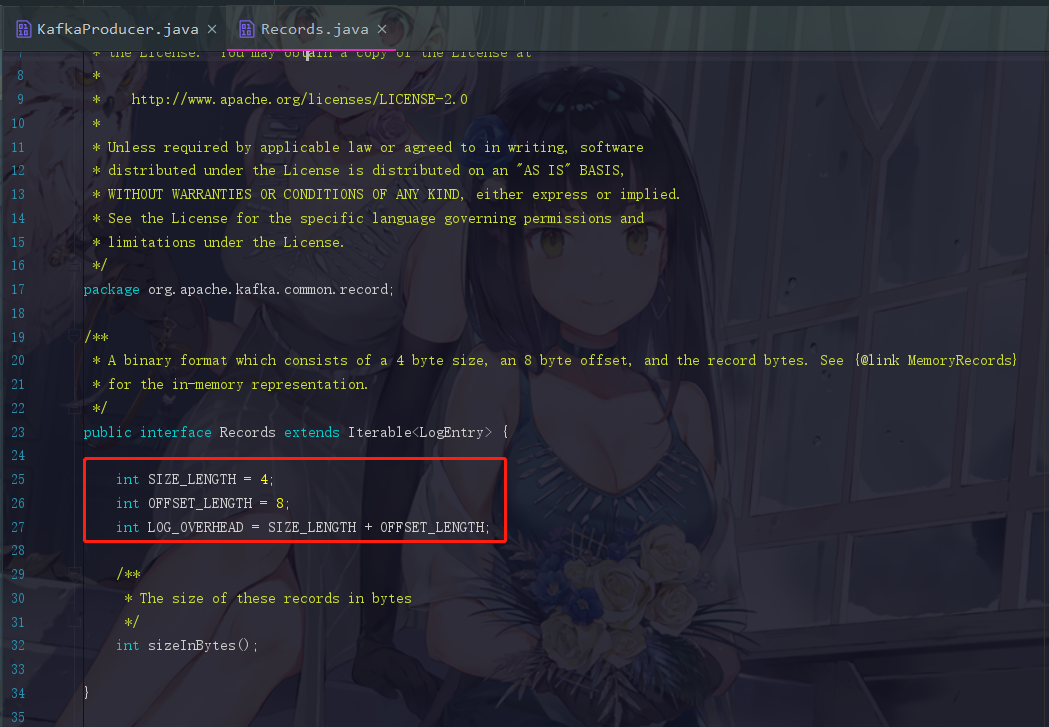
这里可以看到 Records.LOG_OVERHEAD = 4 + 8 = 12 字节
4.2 ensureValidRecordSize
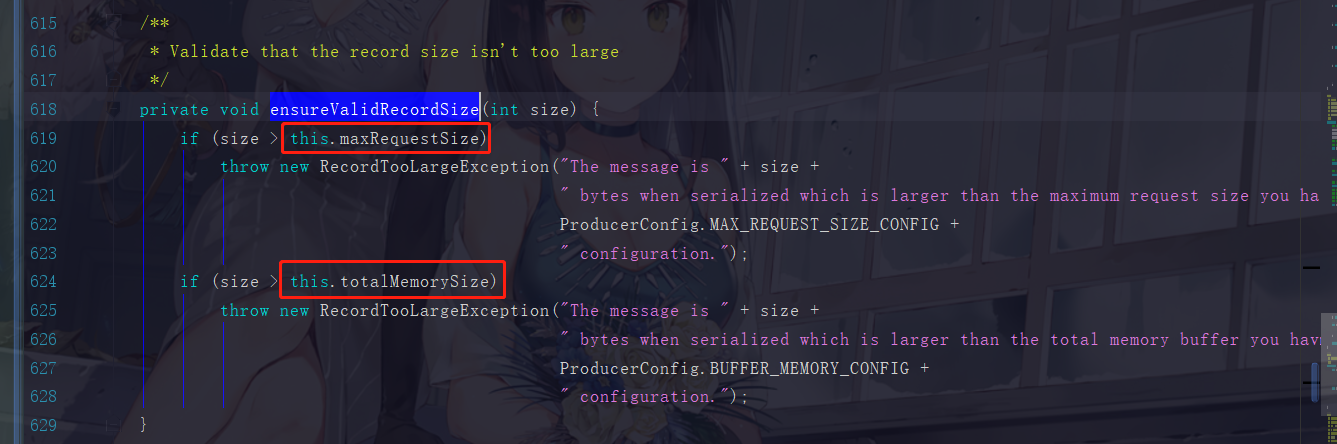
这里需要注意,maxRequestSize 是我们在 KafkaProducer 初始化时设置好的参数,如果超过的话会有一个自定义的异常 RecordTooLargeException 。而 totalMemorySize 是指缓冲区的大小,我们知道,消息的发送是先送往缓冲区打包好再发送出去的,一条消息就超过了32M那就撑爆整个缓冲区了。所以这些消息,它们不能大于整一个缓冲区的大小。
此步骤过去后会封装分区对象,这个并不重要所以就不展开了。

五、给消息绑定回调函数

因为我们现在是使用异步的方式来发送消息,通过回调函数得知消息的发送是否成功
六、重头戏:RecordAccumulator
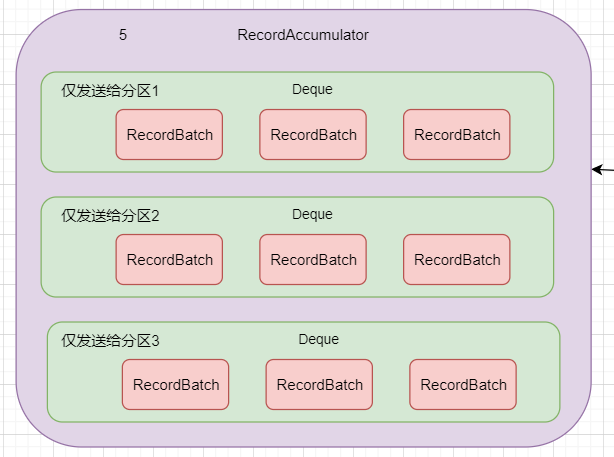
最最最重要的 RecordAccumulator ,也就是这块东西,我们来详细再详细地说!
// 消息放入缓冲区并打包发送
RecordAccumulator.RecordAppendResult result =
accumulator.append(tp, timestamp, serializedKey,
serializedValue, interceptCallback, remainingWaitMs);
这个 RecordAccumulator 里面是一个怎样的结构呢?它里面存在一个个 Batches
毕竟是重头戏,图也不省了,直接截了吧

此时我们点进去 append 方法
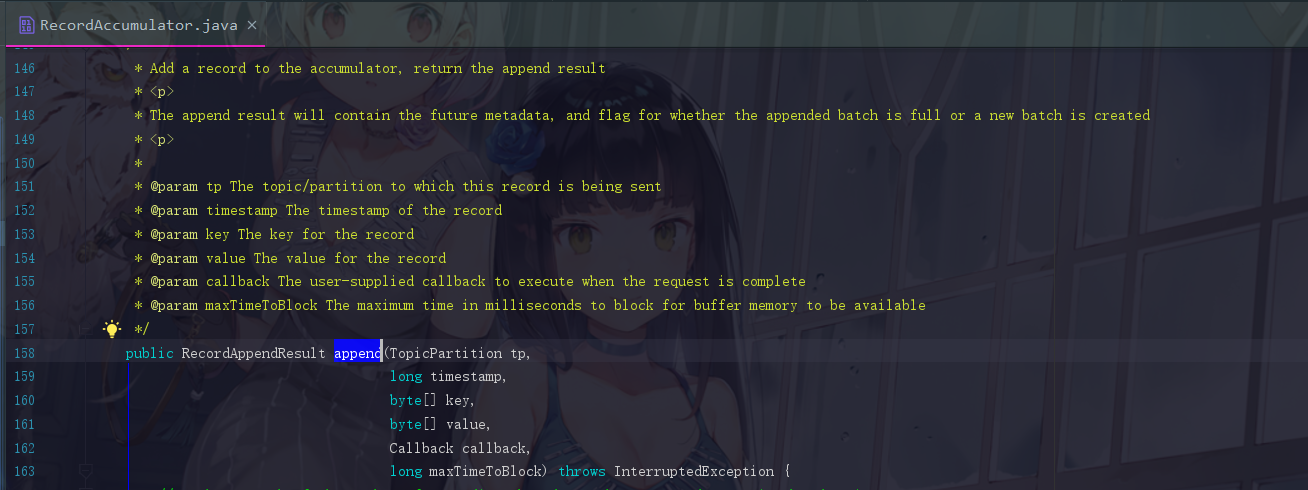
代码非常长,我们一一解读
6.1 append方法解读
6.1.1 步骤一:获取或创建队列
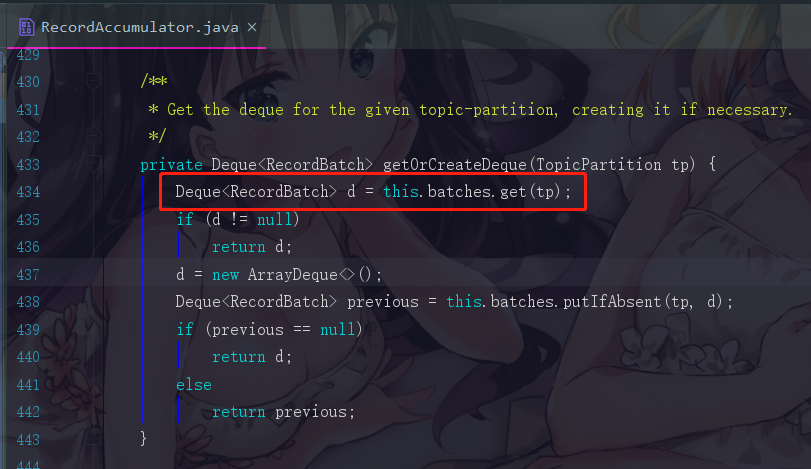
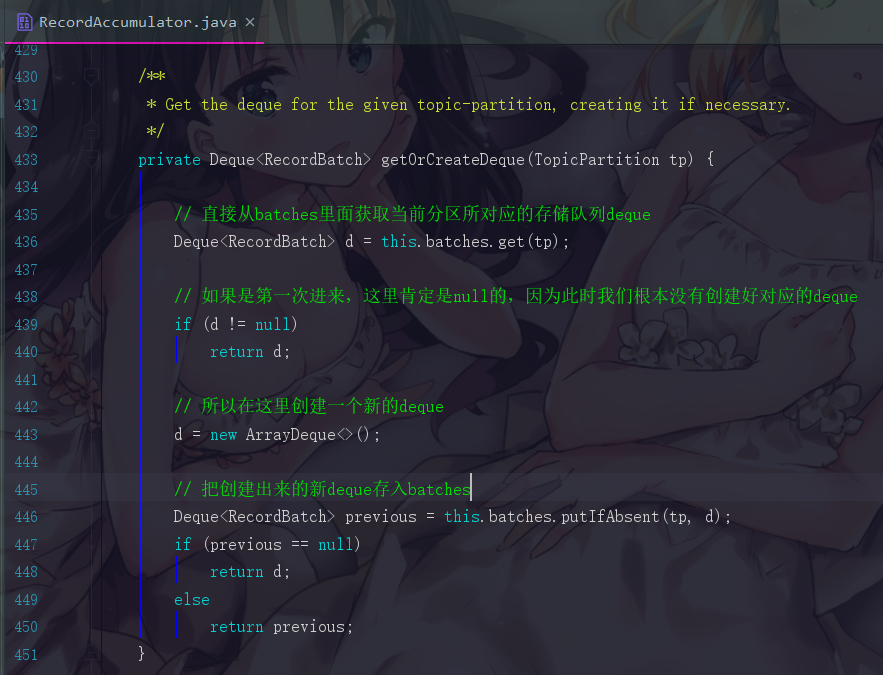
首先是第一句:Deque dq = getOrCreateDeque(tp);
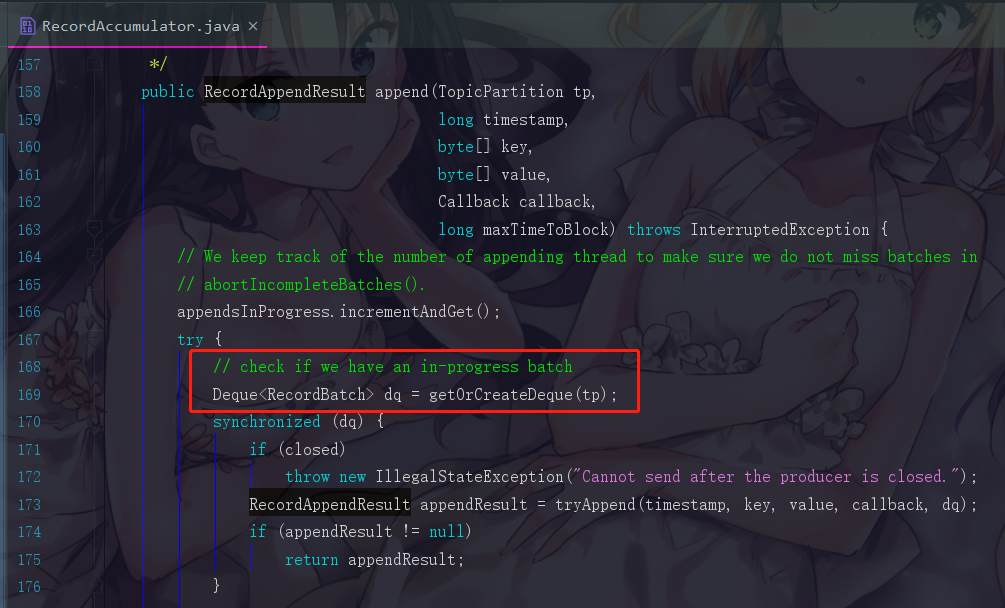
我们会先根据分区找到应该把消息插入到哪个队列里面,如果这个分区的对应队列已经存在,那我们就使用那个已存在的队列,但是我们现在在模拟的是第一次进来,所以相应的队列是一定还没有被创建出来的,所以为什么这个方法会命名为 getOrCreateDeque ,就是代表,存在即获取,不在即创建,所以就是get或者create。
6.1.2 步骤二:尝试往队列中添加数据
RecordAppendResult appendResult =
tryAppend(timestamp, key, value, callback, dq);
但是这个操作明显会失败,因为此时我们第一次进来,虽然队列是已经创建了,可是队列里面是没有 batch(批次) 的,Kafka中的消息是会打包成一个个批次发送的,第一条消息进来会无法形成一个批次而操作失败。
6.1.3 步骤三:计算batch大小
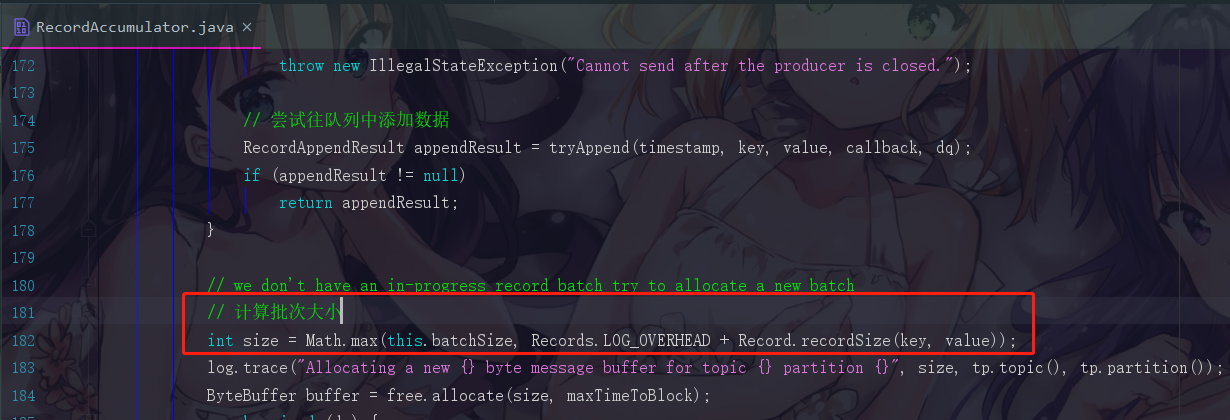
我们现在要把消息封装在批次里面,所以现在我们必须要创建批次出来,创建批次那就要先申请内存,那申请内存就必须知道这个批次的大小,而且此时我们要注意,一条消息是不能超过你设置的批次的大小限制的,默认16K,而且假如我们的消息一条就是16K,每个批次都发送一条消息出去,那批次存在的意义就没有了,所以要结合实际情况去调整这些消息大小和批次大小的限制
补充:批次也不是一定要存满才发送的,100毫秒后也会自动发送,这个在我们之前的文章也提到过这个参数了
Records.LOG_OVERHEAD + Record.recordSize(key, value) 这个东西之前就解释过了,就是消息前缀加上消息本体才是一条消息的大小。
6.1.4 步骤四:根据batch的大小分配内存

6.1.5 步骤五:根据内存大小封装batch并放入队列
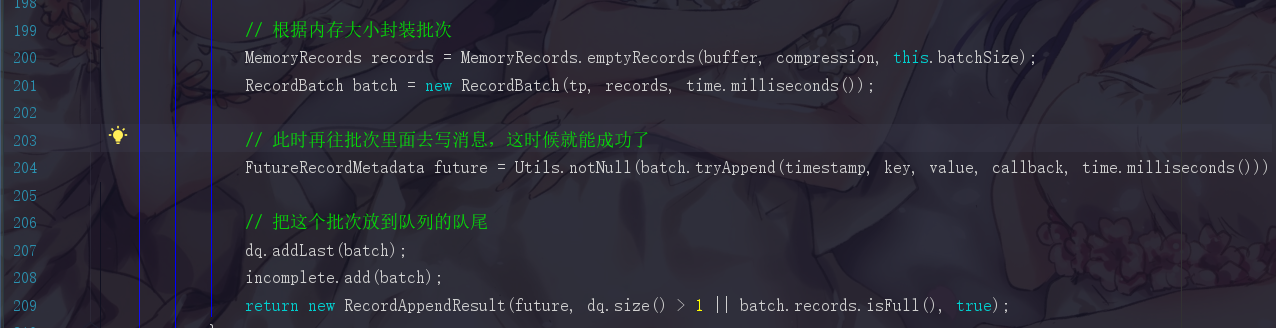
6.1.6 假设第二次进来append()方法的情况
因为append方法是死循环,第二次进来的时候,队列就已经是直接存在的了,所以此时就不用再create,而是get,批次也已经存在了,第二条消息就会直接追加到上一次初始化好的批次里面。
6.1.7 补充6.1.1中getOrCreateDeque的具体实现
可以直接点进去getOrCreateDeque()方法
这里的batches我们点进去看看

你可以清晰地看到,一个TopicPartition对应一个Deque,也就是一个分区对应一个队列,这个队列里面的元素是 RecordBatch,直译过来就是“消息批次”。
所以,整一个流程就是如下图注释的一样,按照场景驱动,我们此时就获取到一个空的队列了
6.1.8 补充6.1.2中tryAppend的具体实现
注意,我们的append()方法中一共尝试写入batch尝试了3次,其中一次是队列未创建,一次是batch未创建,还有最后的一次才是成功的
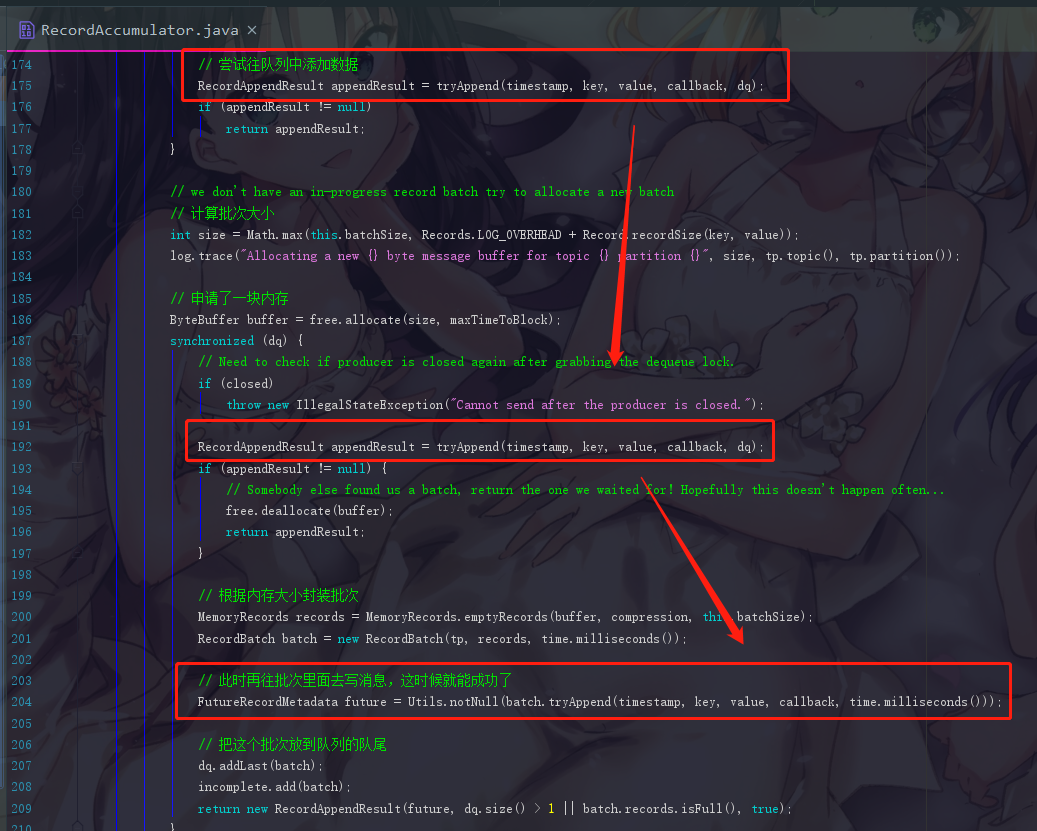
我们现在先来看看,第一次我们执行程序,前两次写入失败的情况。也是直接点进去tryAppend即可,看到如下代码
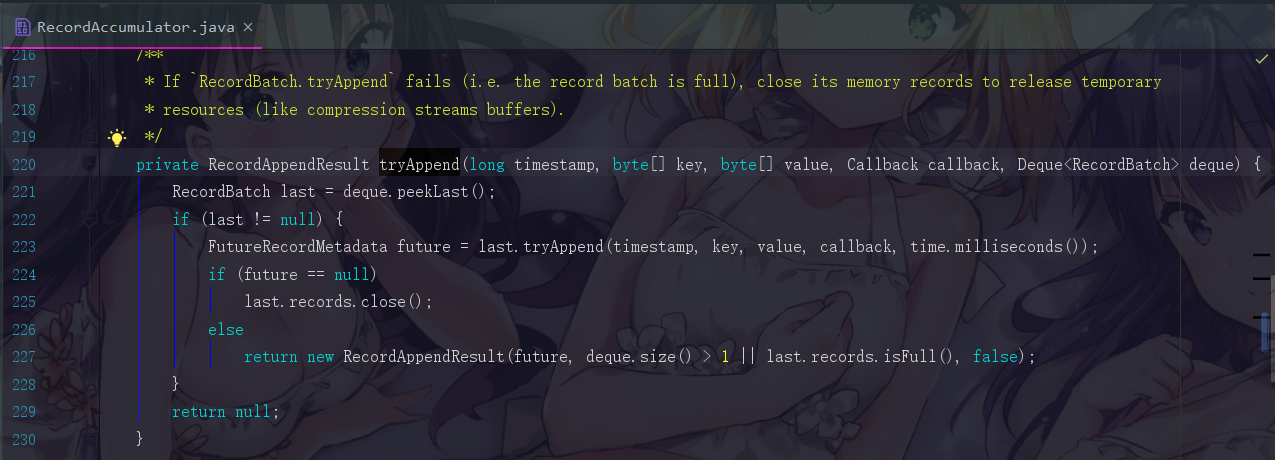
我给大家注释一下,就很好懂了
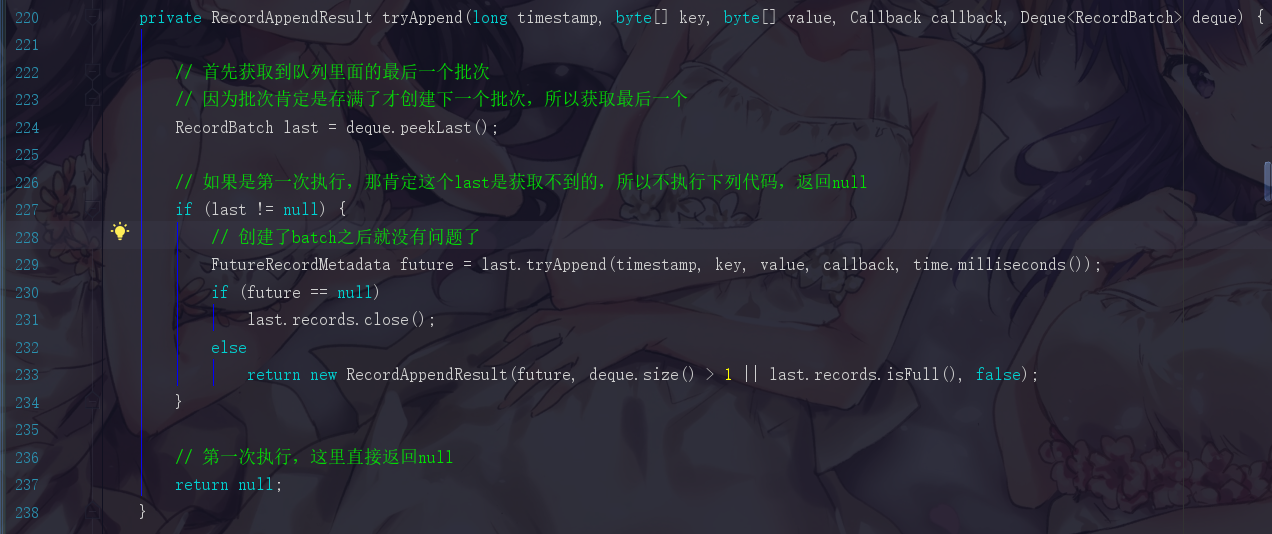
如果此时是第二次程序进来,在判断 if (last != null) 时会直接执行下面的插入,然后在append方法中的第一次尝试插入会成功。直接return
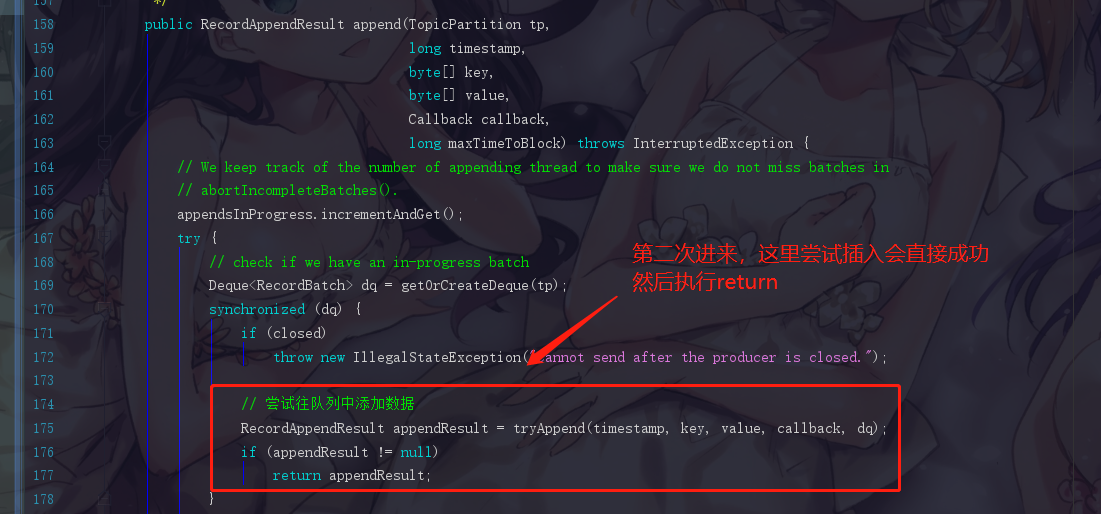
但是如果此时是第一次执行,那我们必须等到创建好队列与批次之后的tryAppend才会成功,现在我们点进去这个tryAppend(),也就是这个
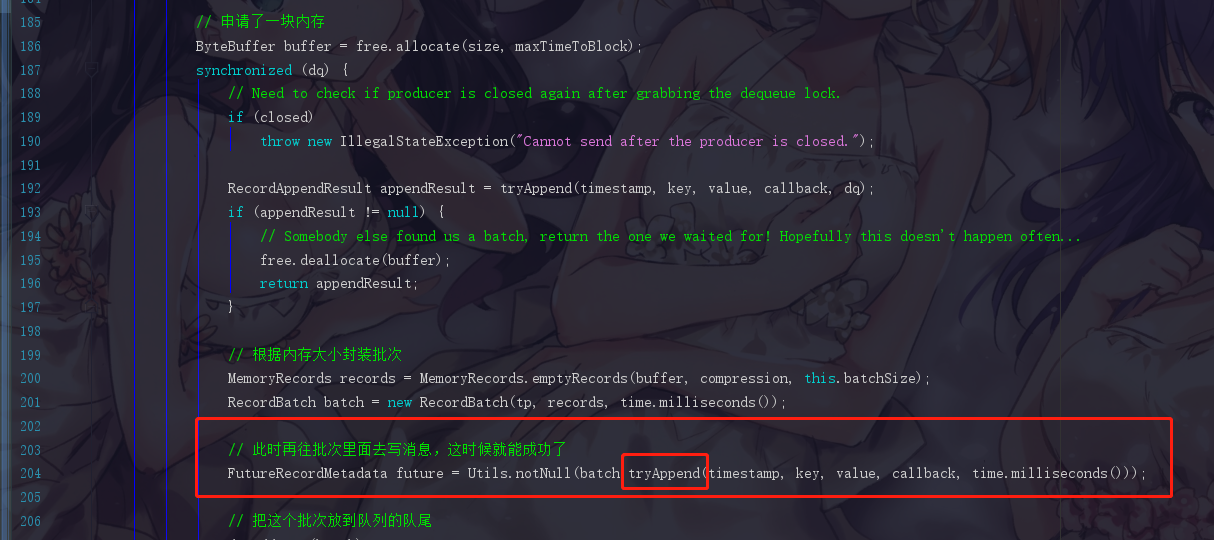
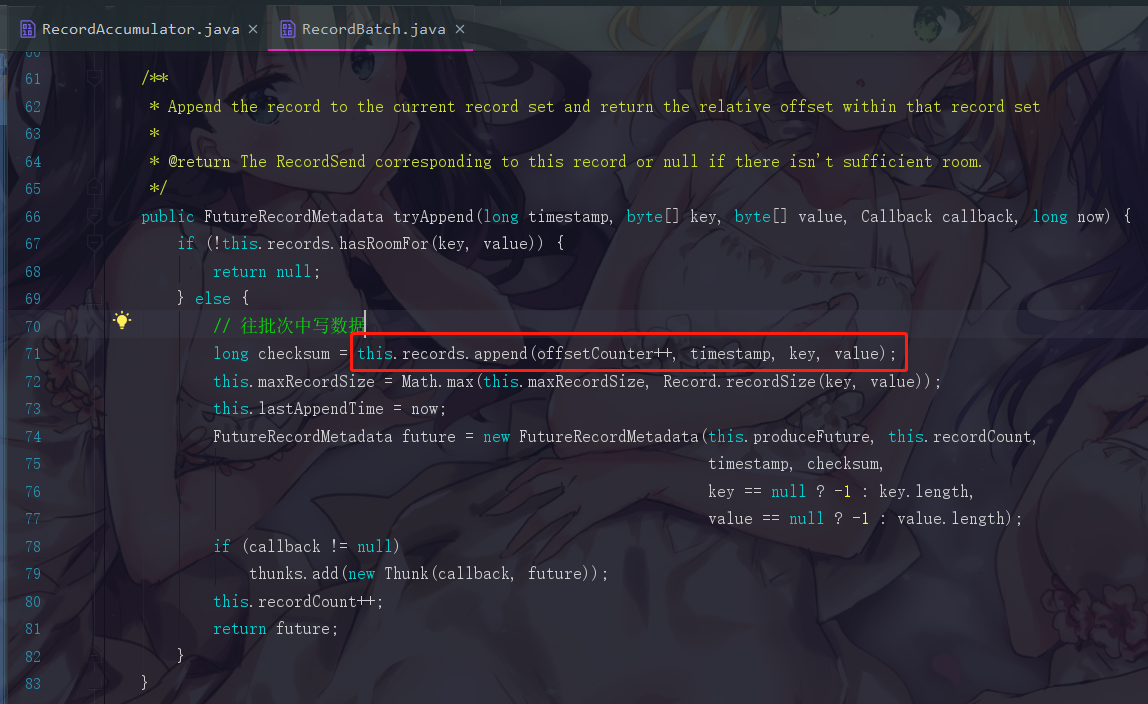
此时我们会跳转到 RecordBatch.java的tryAppend()方法,点进去append
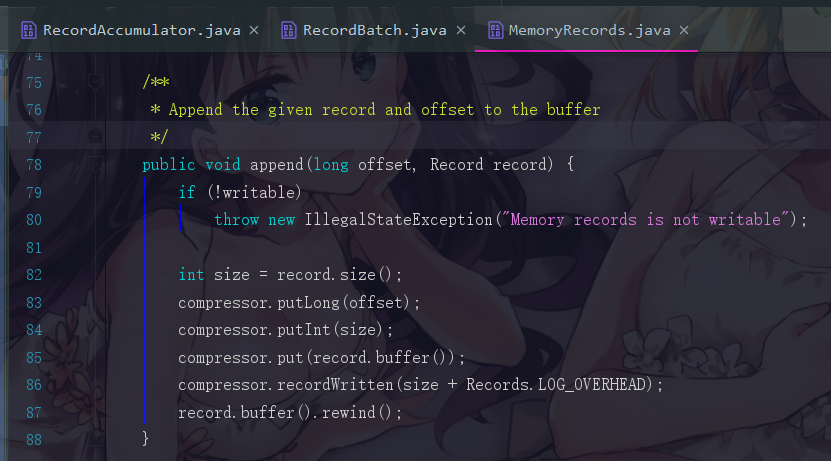
跳转到 MemoryRecords.java,这个逻辑就不再说明了,知道有这么回事即可。
6.1.9 为什么会有一个释放内存的操作
观察仔细的小伙伴们应该看到了,它中间先是申请了一块内存,然后在尝试写入过后立刻又把这个内存给释放掉了
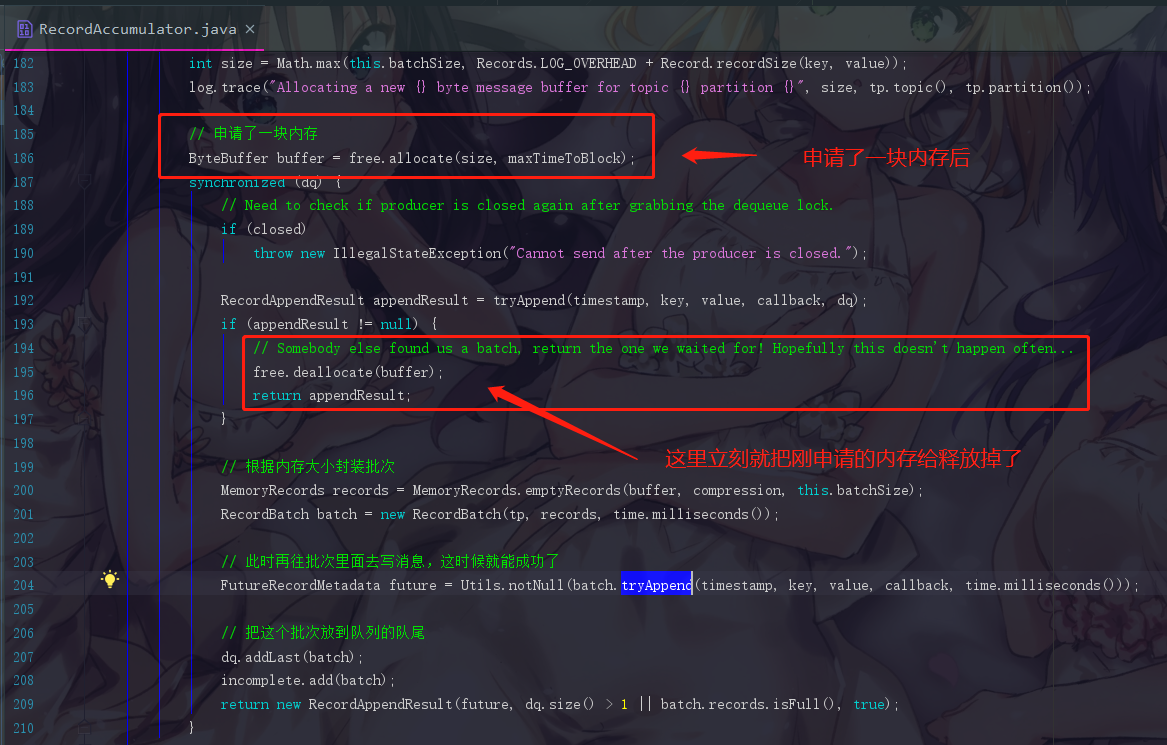
生产者是一个高并发的场景。假设我们现在线程1先进来,它经过以上图中的所有步骤,申请到了一个队列并创建了批次,假设线程2也是和线程1发送到同一个分区的,那么线程2在getOrCreateDeque中获取到了相应deque后,也会经过计算消息大小并申请内存的步骤,可是此时线程1早就已经申请好了响应的内存,而线程2申请的内存就没用了。所以需要把线程2申请的内存释放掉
而且append()方法整一段代码采用了分段加锁的做法,把没有必要加锁的地方都没有加上锁,append()方法也没有直接使用synchronized关键字修饰,这都是为了性能的考虑。比如申请内存,就没有加锁。这个做法在 HDFS 的源码中也有体现,在 Hadoop源码篇 --- 面试常问的Namenode元数据管理及双缓冲机制 中的双缓冲机制也有体现。所以Kafka的源码真的非常不错,它各方面的考虑都是非常周到且合理。
6.1.10 getOrCreateDeque是否线程安全?
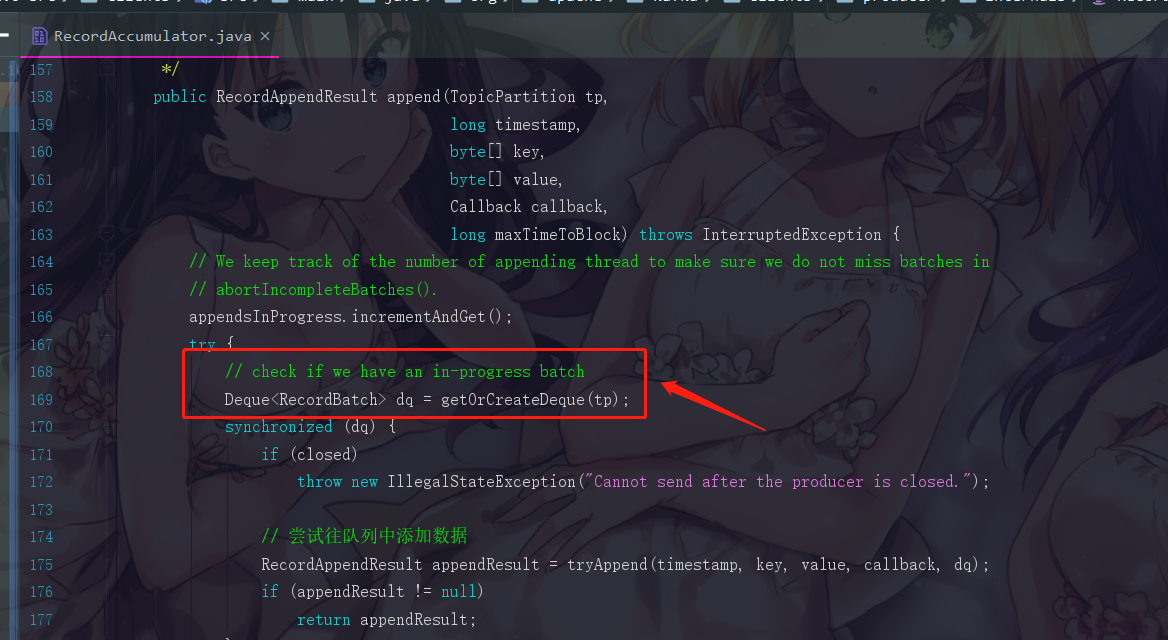
此时有小伙伴可能要说了,这个 getOrCreateDeque 也没有加锁呀,它会不会存在线程安全的问题?
答案是不会的,我们可以点进去看看batches的结构
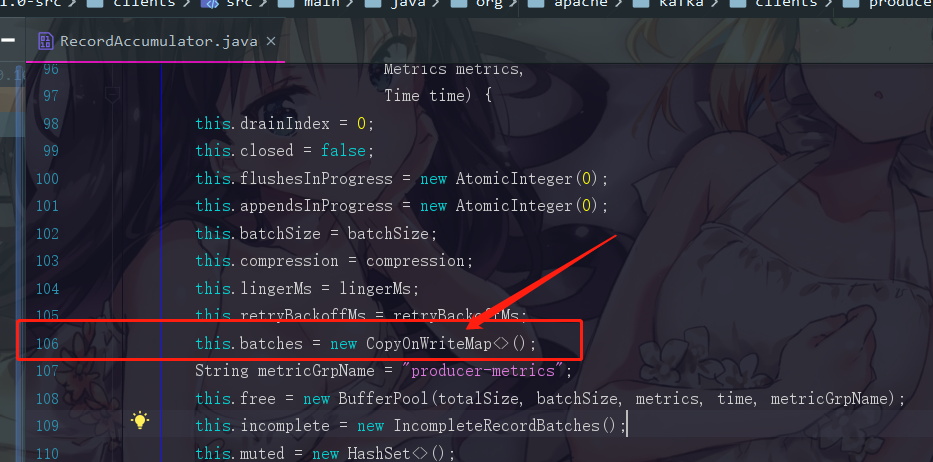
看到这个 CopyOnWriteMap 没有,在JUC下面是不是存在着一个CopyOnWriteArrayList这样的数据结构?它们这名字起得十分类似,我们现在知道CopyOnWriteMap是Kafka专门定义好的一个数据结构,我们点进去看看
--- CopyOnWriteMap

首先这里定义了一个map
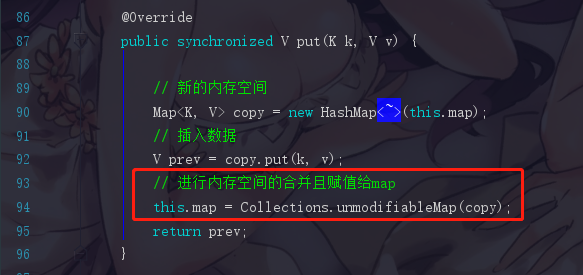
这个map的put方法是线程安全的,会将数据插入到一个新的内存空间里面,然后在之后把内存空间合并再赋值到map

读是直接读map里面的数据,而写的时候是写到新的一个内存空间hashMap。而且此时因为map是volatile关键字修饰的,所以map的值的改变对于它来说是可见的
这种数据结构的设计非常适合于读多写少的应用场景,它为了保证数据安全采用了读写分离的做法,每次新增数据都要开辟新的内存空间,也就是说写数据对于它来说是一件又耗时间又耗内存的事儿,好处就在于读数据的时候不需要加锁,保证了读的高性能。
而回到我们的batches,它是不是读多写少的呢?
batches是存deque所使用的一个存储单元,而deque的数量和分区数是有关的,所以它写的场景仅存在于,此时不存在这个分区对应的deque,需要创建这个分区对应的deque。而读的场景那就再多不过了,每次消息写过来,我都需要跑一次 getOrCreateDeque,此时deque已经存在那就是get,也就是读操作。那我假设有1W条消息,那就要读1W次,所以batches明显就是读多写少的
6.1.11 allocate()是如何去申请内存的
/ 申请了一块内存
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);

为了创建批次而申请的内存,而当这些批次发送到服务端以后,是否就要进行释放内存的工作,就是垃圾回收,可是垃圾回收是又导致fullgc的可能的,这会让代码的性能下跌。所以Kafka考虑到这些问题,还专门设计了一个内存池。
Java里面有一个东西叫做连接池,我们的应用程序连接到mysql数据库,读取完数据之后就需要释放连接,但是创建连接和释放连接对于mysql的性能来说耗费会较大,所以就会有一个连接池,在它里面存好连接,之后应用程序就通过从连接池里获取连接去访问mysql,使用完成又丢回连接池供下一次使用。这样就省去了创建和释放的流程
Kafka的内存池里面就会存放着许多的内存块,当我们要申请内存去创建批次的时候,把内存从内存池申请出来,等待消息发送成功后,把内存中的数据清空,不释放这个内存而是丢回到内存池中,供下一次使用,这样就会避免了 fullgc 的问题
补充:简单看看allocate和deallocate的源码
1. allocate
直接点进去allocate()方法,会跳转到 BufferPool.java,代码非常长
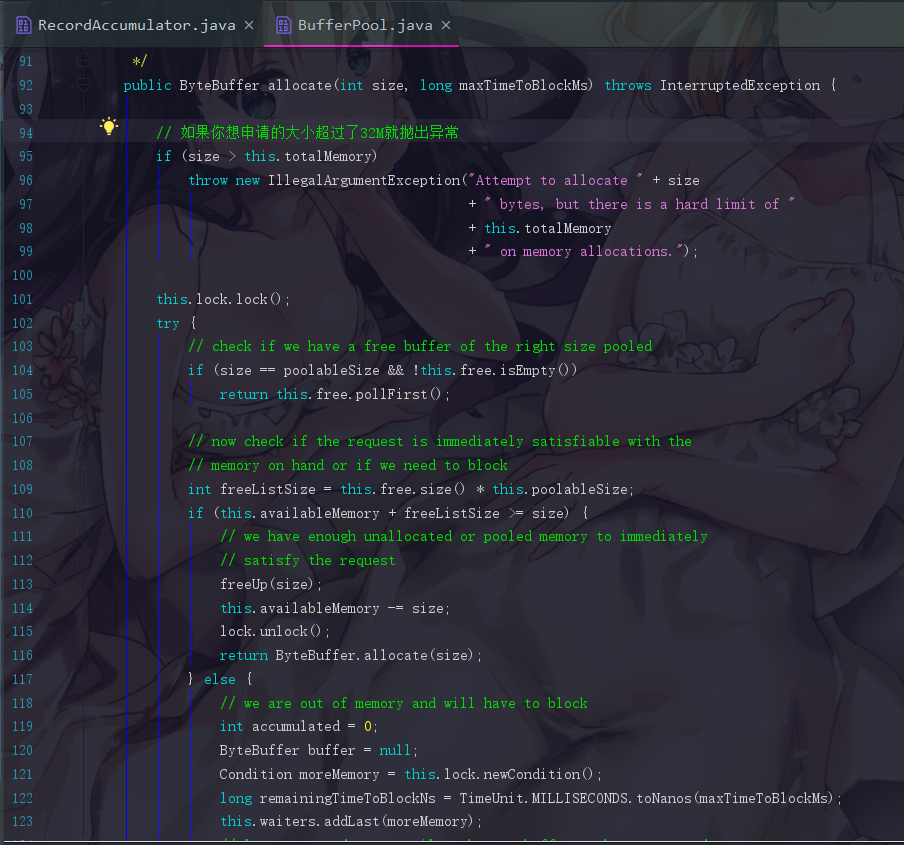
① 第一次尝试从内存池中获取内存
这里我们直接看try里面的代码,首先它会先进行一个判断

我们的场景驱动也是假设我们现在是第一次进来,而内存池不像连接池一样会事先初始化好连接,所以这个return是获取不到内存空间的
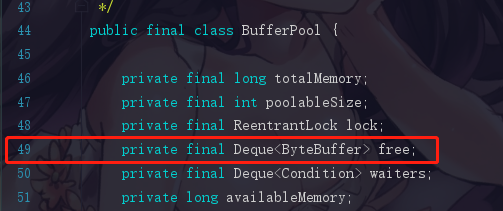
这里的free就是指内存空间
② 计算内存池的大小
this.availableMemory(可用内存) + freeListSize(内存池)如果大于我们要申请的内存,那我们就判断就有足够的空间让你申请
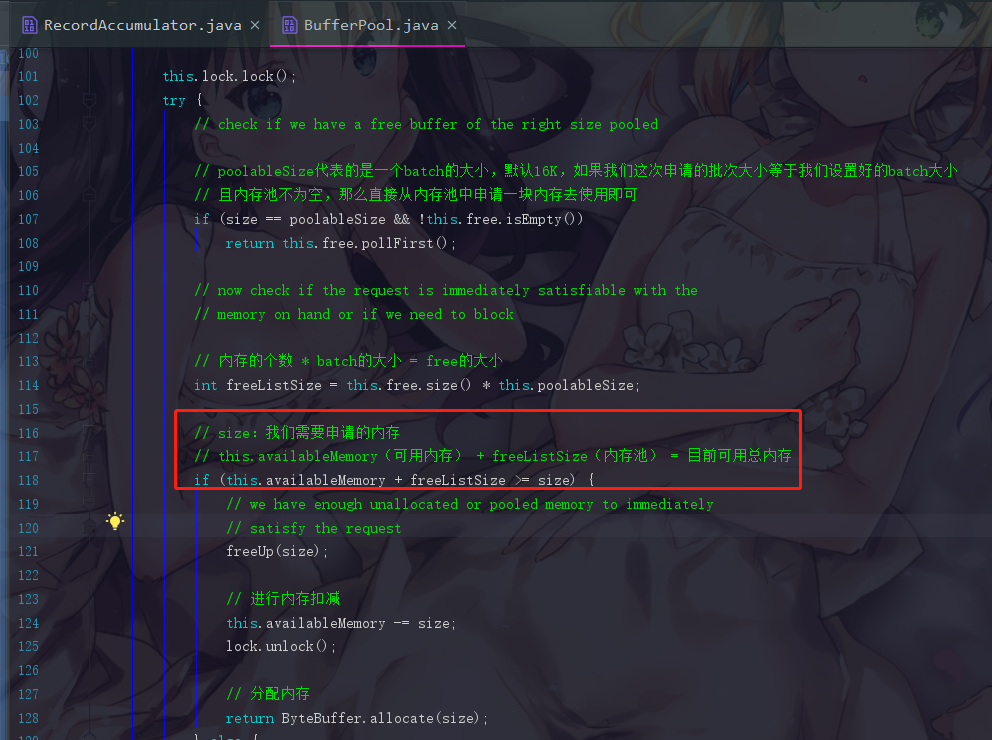
此时进行内存的削减,并成功申请内存进行返回
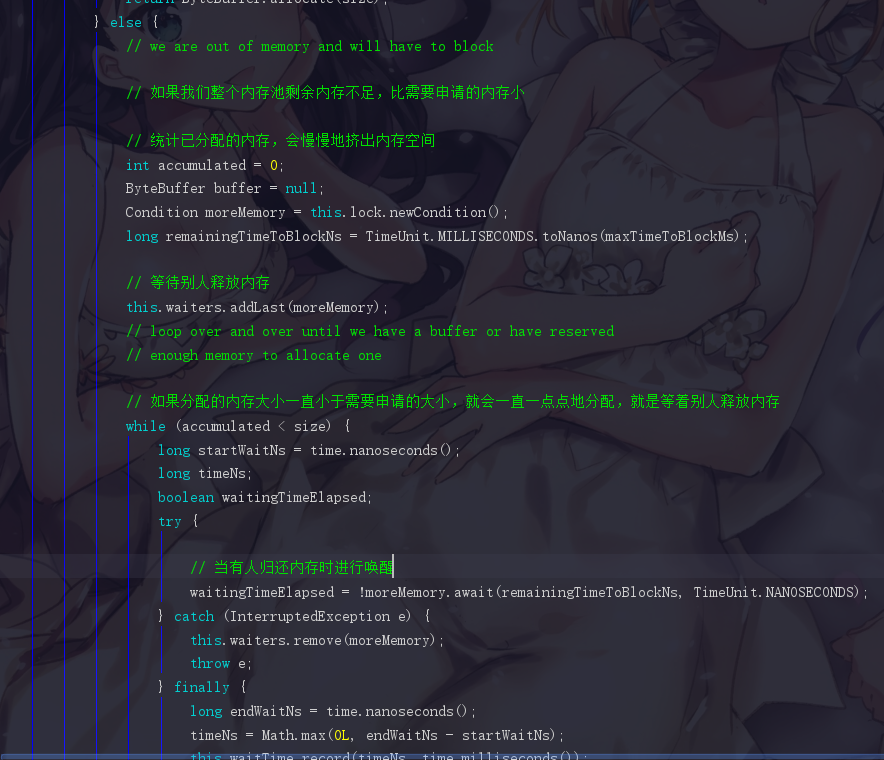
如果不够,那就采用有多少给你多少的方式,一点一点地分配给你,这一块的代码不难看懂,有兴趣可以自己去读一下
2. deallocate
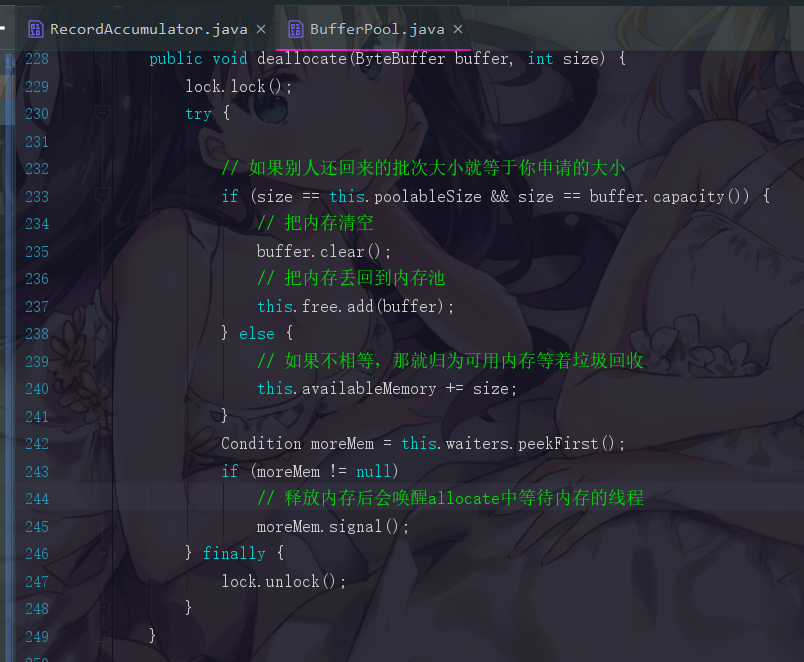
这里提醒一句,为了提升复用率,我们一般都会让申请的内存空间就等于我们batch的默认大小。而且我们会让和batch默认大小的直接回到内存池,而不相等的直接等待垃圾回收。
finally
刚刚我们不仅解释了RecordAccumulator的流程,并把一些设计细节进行了大致展开,这些都是值得我们去学习的地方
经过这一系列的说明,相信你已经差不多get到了这整一个逻辑了。
接下来还有唤醒Sender线程发送数据的流程,咱们下一篇再阐述,如果觉得本文对你有帮助,欢迎关注我的公众号,一起努力探索技术的本质,谢谢

