

说到数据库,以前我老师有一句很经典的话。你可以不会写SQL,但是一定不能不知道ACID。
在工业领域,SQL可以说是应用最广泛的技术。从后端到算法,从数据到DBA,再到产品,甚至连一些运营也会基本的SQL。所以如果你现在还不太会的话,我建议你用一个下午的时间找个网站好好学一下。
原本我是想直接写些Hbase相关的内容,但是我发现要想讲清楚Hbase,必须要讲noSQL数据库。如果将noSQL,则又离不开最传统的关系型数据库。所以我们一步一步来,先从基础的关系型数据库讲起。或许我这么说并不准确,因为数据库并不基础,相反它十分复杂。从索引到各种优化和设计原理,再到内部的各种算法和数据结构,涉及到的内容非常多。我们先把浩如烟海的知识放一放,先从最核心的数据库四大原则开始说起。
数据库事务ACID四大原则,A代表Atomicity,即原子性。C表示Consistency,即一致性。I表示Isolation,即隔离性。D表示Durability,即持久性。
这四个原则了解过数据库的应该都如雷贯耳。可是真正面试的时候被问起来,能一个不落说得上来,并且讲得清楚原委的就不多了。我觉得主要是因为我们的翻译过于文雅,不像英文那么直观,所以很难顾名思义。另一个原因是我们在学习的时候理解不够深入,只知道原因,不知道原因的究竟。所谓知其然,不知其所以然。

原子性
让我们先从其中最简单的原子性开始。
原子性理解起来最简单,也最常用。我就在面试当中遇见过不止一次,还有一次让我用Java写一个转账的功能,其实就是想看看我知不知道原子性。
原子两个字看起来一头雾水,其实这里不是指物理学上的基本粒子,而是指的不可分割的意思。也就是说在一个事务当中的所有操作应该被视为一个不可分割的整体,要么全成功,要么全部失败。这点用转账这个问题举例最合适。A将银行卡里的钱转100给B,很明显,数据库需要做两件事情,一件事A账户扣款100,另一件是B账户收入100。但问题来了,计算机系统并不是100%可靠的,可能会存在极小的可能失败。如果A扣款之后,发生网络延迟或者系统down机,导致B账户的钱没有增加,那怎么办?A不是白白扣了钱?
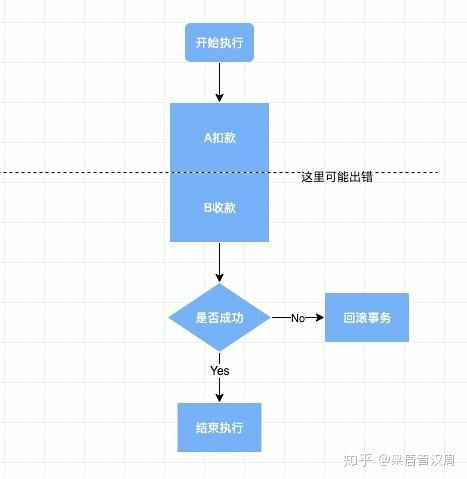
A白白扣了钱是小事,一个金融系统如此不稳定,显然是不能接受的。所以,在数据库的事务当中,应该保证原子性。扣钱和收钱虽然是两个操作,但是应该被视为一个。要么一起成功,要么一起失败。失败了还可以重试,如果成功了一半,那都不知道该怎么修复了。
事务的一种实现方法是在执行的时候先不将最终的结果更新到数据库,而是先写在事务日志上。等整个事务执行成功之后,再将事务日志上的内容同步到数据库当中。如果失败了,则将事务日志删除,完成回滚。
持久性
第二个要介绍的是持久性。
持久性指的是数据的持久性,指的是事务完成了之后,这个事务对数据库所作出的修改就被持久地保存进了数据库当中,不会再被回滚操作影响。即使出现了各种事故,比如机房断电、网络故障等等意外情况,数据库当中的数据也不能丢失。
但是前文当中说了,计算机系统很难做到100%可靠。如果万一的情况发生了,数据库当中的数据丢了,那么应该怎么办呢?
没关系,之前在介绍原子性的时候介绍过了。所有的事务操作在执行之前,都会先把数据记录到事务日志当中,再同步到数据库。即使是数据库里的数据丢失了,那么只要根据事务日志重新执行一遍对应的操作,就可以恢复数据库当中的数据,维持数据库的持久性。实际上,现在的数据库默认会将所有的操作都当做事务来执行,因此基本上不用担心数据丢失的情况。
隔离性
然后,介绍的是隔离性。
在我们理解了原子性之后,隔离性就很好理解了。当我们同时有多个事务一起执行的时候,如果隔离性做得不好,很有可能导致很多问题。
以下四种问题最常见:
1. 脏读
脏读是指一个事务读到了另一个事务执行的中间结果。还用我们刚才的转账的例子举例:
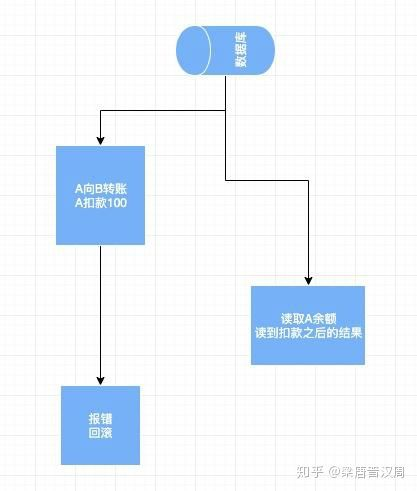
当我们转账的事务没有执行完,另一个事务就读取了它的中间结果,很有可能就造成脏读。因为万一之前的事务回滚,那么新读取到的结果就是错的,和A账号回滚之后的余额不一致。如果这个数据应用在其他的系统当中,就会引起大规模的数据问题。
2. 不可重复读
不可重复读的意思是说,如果在一个事务当中,我们读取了某个数据两次。刚好在这中间,有另一个事务修改了这条数据,那么同样会引起数据错误,因为这两次读取到的结果不一致。
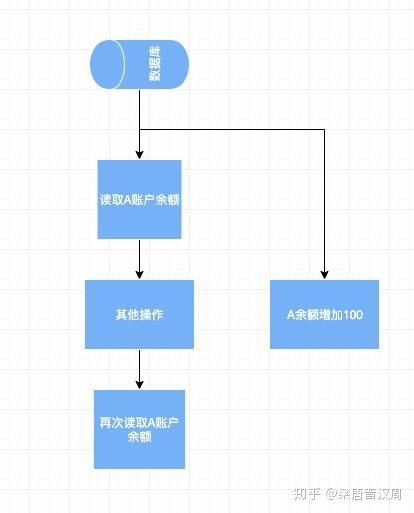
比如我们对A账户的一个事务还没有结束,这时候它的结果就被其他事务修改了。那么程序就会发生错乱,因为读到了它没有预料到的修改。
解决方法是针对当前修改的数据进行隔离,同一时刻只允许一个事务对该条数据进行修改,以保证数据的一致性。
3. 幻读
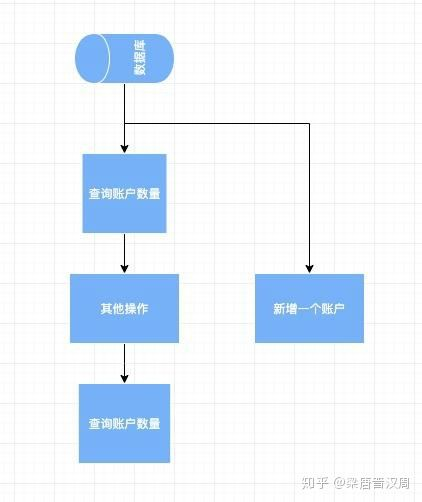
幻读的概念也很简单,就是一个事务读取两次,读到的数据条数不一致。这点和不可重复读非常类似,不过不同的是不可重复读针对的是确定的某一条数据,而幻读指的是对整个数据库或者是整个表而言。
要解决也很简单,因为幻读是其他事务修改新增或者修改其他数据产生的,所以要排除掉这种情况,只针对我们修改的数据进行加锁和隔离是不够的。我们需要将整个数据库,或者是分区进行隔离,同一时刻,只允许一个事务对一个分片或者是数据表进行修改。
4. 更新丢失
更新丢失的定义很直观,当我们针对一条数据进行修改的时候。同时也有另一个事务在修改同一条内容,会导致后者覆盖前者的内容。比如说账户里原本100元,A事务往账户里添加10元,B事务往账户里扣除20元。A修改成110的同时,被B事务的80所覆盖,导致A的操作就像是没有执行过一样,引起更新丢失。这个问题在并发场景当中也最为经典。
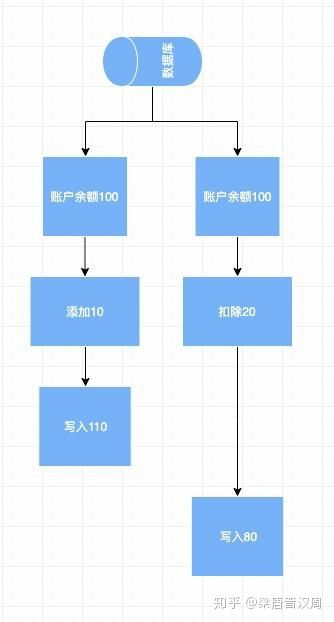
解决的办法同样是做好隔离操作,在一个写入完成之前,禁止其他事务的读入。事实上更新丢失是并发场景下最容易出现的错误,而且如果设计不合理,出现了错误也会非常难排查。
数据库解决隔离性问题的办法就是设置不同的隔离级别,不同的隔离级别对应不同的隔离策略,可以保证不同级别下的隔离性。不同的隔离级别意味着使用不同级别的锁,显然隔离级别越高意味着性能越差。所以这就需要数据库管理员(DBA)对于当前的应用场景,以及并发量和数据风险有一个非常清楚的认知。能够在性能和安全性之间做一个权衡。这里,我们不多做具体的探究,观察一下下图,简单了解一下即可:
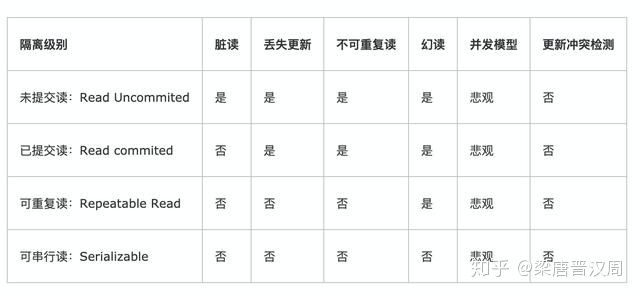
从上到下以此是四种隔离级别,越往下隔离级别越高,能够解决的隔离性问题也就越多。同样的,用到的锁也就越多,系统的性能也就越差。
最上面未提交读是最低的隔离级别,在读取的时候并不会判断是否可能会读取到没有提交的数据。所以它的隔离性最差,连最简单的脏读都无法解决。
已提交读则是通过锁限制了只会读取已经提交的数据,读数据的时候使用的共享锁,在读取完成之后立即释放。这种隔离级别只能够解决最常见的脏读问题,它也是SQL server数据库的默认隔离级别。
可重复读的读取过程和已提交级别一样,但是在读取的时候会保持共享锁,一直到事务结束。也就是说只要一个事务没有结束,锁就不会释放。其他的事务无法更新数据,保证了不会出现不可重复读的情况。
最后是可串行读,它是在可重复读的基础上进一步加强了隔离性。在事务进行当中,不仅会锁定受影响的数据本身,而且还会锁定整个范围。这就阻止了其他事务影响整体的情况出现。在这个隔离级别下,保证了事务之间不会有任何踩踏。
到这里,数据库事务四大原则当中的三个就介绍完了,内容看起来不少,但其实还没有结束,关于隔离的实现会牵扯到锁的使用,这块深挖下去,又会牵扯许多内容。不过对于我们算法从业者而言,能够了解到这一层,也差不多够了。
四原则当中还剩下一个一致性原则,一致性这个单词在很多地方都出现过,比如分布式存储系统、多副本的一致性等等。但是这些概念的意思并不相同,不可以简单地理解成同一回事。数据库的一致性表示数据的状态是正确的,在转移的时候,是从一个正确的状态转移到了另一个正确的状态。正确的状态其实就是指不出错的状态,也就是和程序员预期一致的状态。之前在介绍隔离性时谈到的种种问题,总结起来都是数据和程序员的预期不一致。也就是说如果和程序员的预期一致,就可以认为满足了一致性。
虽然一致性是数据库的四原则之一,但数据库系统当中并没有专门针对一致性的部分。其实在数据库眼中,满足了其他三原则,那么自然也就达成了一致性。一致性是目的,并不是手段。举个例子,还是以刚刚转账的情景距离。A向B转账100,我们都知道,前提条件是A的账户里的金额大于等于100,如果A账户里小于100,我们开发的时候没有做校验还强行转账成功。那么这个结果显然是错误的,也是和我们预期不一致的,但是这个问题发生的原因并不是因为数据库没有做好一致性,而是开发人员忽略了限制条件。
所以数据库的教材上才会写着“Ensuring the consistency is the responsibility of user, not DBMS.", "DBMS assumes that consistency holds for each transaction”。
“保证一致性是开发的责任,而不是数据库的,数据库假设每一个事务都符合 一致性。”
到这里,数据库事务的四原则就介绍完了,衷心祝大家,日拱一卒,每天都有收获。
喜欢本文的话,请顺手给个关注吧~

