

ELK初探
什么是ELK?
ELK又被称为ELK Stack,既然被称为Stack,说明它并不是某一种技术,它是Elastic公司推出的一整套日志收集、分析和展示的解决方案。ELK分别为3个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。下面我们分别来介绍这三个项目。
Elastic Search
Elastic Search(简称ES)毫无疑问是ELK的核心,他是一个分布式的开源搜索和分析引擎,适用于几乎所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。说到Elastic Search就不能不提Apache Lucene。Lucene是一个高性能、全功能的全文检索引擎库,但其仅仅是一个库,需要使用Java将Lucene集成到应用程序中,并且需要一定的信息检索学知识才能了解其工作原理。
而Elasticsearch 同样使用 Java 编写,其内部使用 Lucene 做索引与搜索,但它隐藏了Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API,从而使全文搜索变得简单。同时,针对大数据场景,ES可以分布式部署于上千台节点,处理PB级数据。下面介绍几个ES的基本概念
集群(Cluster)
集群是一个或多个节点(服务器)的集合,这些节点负责保存全部数据,并在所有节点之间提供联合索引和搜索功能。
节点(Node)
节点是一台服务器,它是群集的一部分,存储数据并参与群集的索引和搜索功能。
索引(Index)
索引是具有相似特征的文档的集合。 例如,可以为客户数据创建索引,为产品目录创建另一个索引,为订单数据创建另一个索引。 索引由名称标识(必须全为小写),并且对该索引中的文档执行索引,搜索,更新和删除操作时,该名称用于引用索引。
倒排索引(inverted index)
Elasticsearch 使用倒排索引(也称为反向索引)来进行全文本搜索。倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。而一般关系型数据库所用的正向索引(forward index)如果需要通过关键词来所某个文档,需要遍历全部文档,对于全文检索来说,效率低下。
Logstash
Logstash是一个开源的数据收集引擎,可以为ES收集来自不同数据源的数据,并利用其丰富的过滤器,对数据进行实时解析和转换,而ES并不是logstash的唯一输出选择,它同样可以为数据库、消息队列、云存储等多种应用提供数据。
工作原理
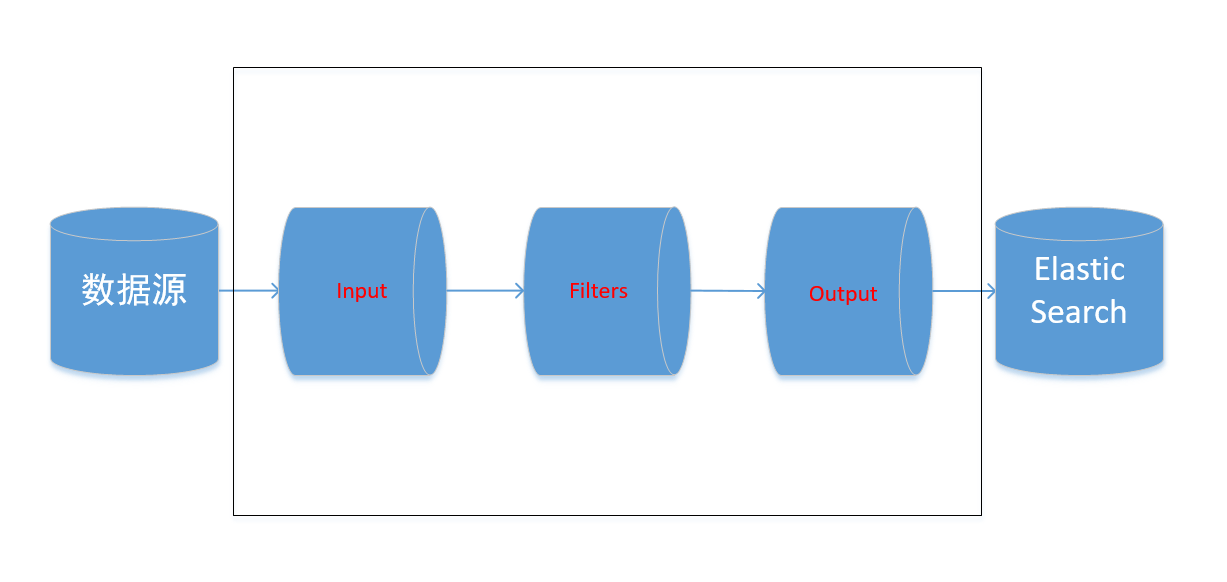
如上图,Logstash事件处理管道包括三个阶段:输入→过滤→输出。输入会生成事件,过滤器会对其进行修改,输出会将它们发送到其他地方。输入和输出支持编解码器,使您可以在数据进入或退出管道时对其进行编码或解码,而不必使用单独的过滤器。
输入(Input)
Logstash可以在同一时间从不同的常用来源捕捉数据,比如日志、指标、Web应用和数据存储等。
筛选器(Filter)
筛选器是Logstash管道中的中间处理设备。如果事件符合特定条件,则可以将过滤器与条件语句结合使用,对事件执行操作。比如常用的过滤器插件grok,它可以将非结构化的日志机构化,将日志消息分解成逻辑命名的字段,便于查询、分析和可视化。
输出(Output)
输出是Logstash管道的最后阶段。一个事件可以通过多个输出,但是一旦完成所有输出处理,该事件就完成了执行。根据不同的用途,logstash的输出到不同的下游,比如这些经过筛选的数据如果用于分析,就会被输出到Elastic Search或者MongoDB,如果用于监控就会被输出到Nagios或者Zabbix,如果用于存档就会被输出到HDFS或者S3。
Kibana
Kibana是一个开源的分析和可视化平台,用来搜索、查看储存在ES所以含中的数据。Kibana强大的交互功能可以使用户轻松地执行高级数据分析,并且以各种图表、表格和地图的形式可视化数据,其展示界面基于浏览器,简单易懂,能够快速创建和共享动态仪表板,实时显示ES查询的变化。
Beats
Beats是ELK stack中后来加入的一个组件,它是一个轻量级的数据采器,我们知道logstash也具有数据采集功能,但由于logstash是基于java开发,需要依赖虚拟机,同时又要进行数据处理,因此在性能方面并不令人满意。而beats在数据收集层面上并不进行过于复杂的数据处理,只是进行数据采集并传输给下游,另一方便,由于beats采用go语言开发,go是一种系统编程语言,具有并发友好以及部署方便的特点,能够在不依赖虚拟机的情况下运行,因此在数据采集方面性能优于logstash。
Beats以libbeat为核心库的架构,方便用户创建出适合于不通类型数据采集的Beats。目前官方负责维护的Beats和所收集的数据有以下几种。
Auditbeat|审计数据|
Filebeat|日志文件|
Functionbeat |云端数据|
Heartbeat |可用性监测数据
Journalbeat |系统日志
Metricbeat |系统或服务的轻量型指标
Packetbeat |网络数据
Winlogbeat |Windows事件日志
通过Beats采集的数据可以直接传输到ES,如果需要事先处理,也可以先发送到Logstash进行解析,然后再传输给ES,下图是Beats的常见使用方法。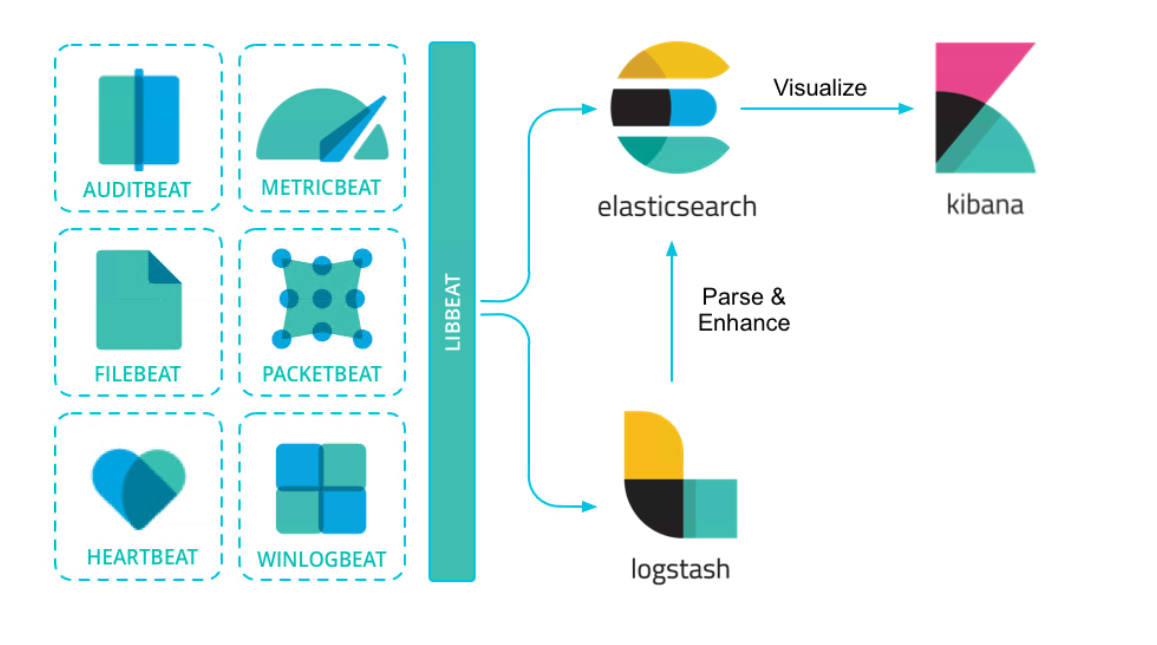
部署一个ELK
本例使用了滴滴云的虚拟机,因为是一个简单的demo,我们会把所有组件部署到一个虚机上,所以采用了配置较高的虚机,4核8G,40G高效云盘,操作系统为Centos 7.5。登陆后首先用sudo su命令切换到root用户。
1 2 3 | <font size=5> [dc2-user@dc2-user ~]$ sudo su [root@dc2-user]# |
- 安装JDK8并设置环境变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | <font size=5> <line-height=24> tar -zxvf jdk-8u101-linux-x64.tar.gz mv jdk1.8.0_101/ /usr/local/jdk1.8 # 设置环境变量 vim /etc/profile # 加入如下内容 export JAVA_HOME=/usr/local/jdk1.8 export JRE_HOME=/usr/local/jdk1.8/jre export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$PATH # 使得环境变量生效 source /etc/profile # 打印java版本号 java -version # 看到如下输出java环境安装完成 java version "1.8.0_101" Java(TM) SE Runtime Environment (build 1.8.0_101-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode) |
- 安装Elastic Search
1 2 3 4 | <font size=5> wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.3.0.tar.gz tar -zxvf elasticsearch-5.3.0.tar.gz mv elasticsearch-5.3.0 /usr/local/ |
编辑配置文件/usr/local/elasticsearch-5.3.0/config/elasticsearch.yml。
1 2 3 4 5 6 7 8 9 | <font size=5> # 服务监听IP地址 network.host: localhost # 服务监听端口 http.port: 9200 # 索引文件和日志文件存储地址默认是在安装目录 path.data: /data/elasticsearch/data path.logs: /data/elasticsearch/logs |
一定要用非root用户来启动ES,这里用滴滴云默认的登录用户dc2-user,将ES文件的属组和属主变为dc2-user。
1 2 | <font size=5> chown -R dc2-user:dc2-user /usr/local/elasticsearch-5.3.0/ |
启动ES并在后台运行。
1 2 3 | <font size=5> /usr/local/elasticsearch-5.3.0/bin/elasticsearch & |
访问本机的9200端口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | <font size=5> curl localhost:9200 { "name" : "Fo6Reo2", "cluster_name" : "elasticsearch", "cluster_uuid" : "kNFPTL6lSe6XlcRiJnQJ6Q", "version" : { "number" : "5.3.0", "build_hash" : "3adb13b", "build_date" : "2017-03-23T03:31:50.652Z", "build_snapshot" : false, "lucene_version" : "6.4.1" }, "tagline" : "You Know, for Search" } |
说明ES已经正常运行。
安装Kibana
1 2 3 4 | <font size=5> wget https://artifacts.elastic.co/downloads/kibana/kibana-5.3.0-linux-x86_64.tar.gz tar -zxvf kibana-5.3.0-linux-x86_64.tar.gz mv kibana-5.3.0-linux-x86_64 /usr/local/kibana-5.3.0 |
出于安全考虑,我们现在配置文件中设置仅允许访问本机地址。
1 2 3 4 | <font size=5> server.port: 5601 server.host: "127.0.0.1" elasticsearch.url: "http://localhost:9200" |
启动Kibana并在后台运行。
1 2 | <font size=5> /usr/local/kibana-5.3.0/bin/kibana & |
如果看到以下输出,说明kibana启动成功。
1 2 3 4 5 6 7 8 9 | <font size=5> log [02:01:09.422] [info][status][plugin:kibana@5.3.0] Status changed from uninitialized to green - Ready log [02:01:09.484] [info][status][plugin:elasticsearch@5.3.0] Status changed from uninitialized to yellow - Waiting for Elasticsearch log [02:01:09.512] [info][status][plugin:console@5.3.0] Status changed from uninitialized to green - Ready log [02:01:09.706] [info][status][plugin:timelion@5.3.0] Status changed from uninitialized to green - Ready log [02:01:09.727] [info][listening] Server running at http://127.0.0.1:5601 log [02:01:09.729] [info][status][ui settings] Status changed from uninitialized to yellow - Elasticsearch plugin is yellow log [02:01:10.258] [info][status][plugin:elasticsearch@5.3.0] Status changed from yellow to green - Kibana index ready log [02:01:10.259] [info][status][ui settings] Status changed from yellow to green - Ready |
这里之所以没有放开Kibana的外方访问是因为Kibana本身无法鉴权,任何人都可以直接访问,因此这里我们用nginx来做身份验证,可以直接用yum install nginx来安装。
编辑配置文件/etc/nginx/nginx.conf,在http模块中添加以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | <font size=5> upstream kibana_web { server 127.0.0.1:5601 weight=1 max_fails=2 fail_timeout=30s; } server { listen 8081; server_name 127.0.0.1:8081; location / { proxy_set_header Host $host; auth_basic "secret"; auth_basic_user_file /etc/nginx/passwd.db; proxy_pass http://kibana_web; proxy_redirect off; } |
生成用户名和密码文件。
1 2 | <font size=5> htpasswd -c /etc/nginx/passwd.db admin |
如果没有htpasswd命令,需要安装httpd-tools,yum install -y httpd-tools。
启动nginx,systemctl start nginx,通过外网IP的8081端口访问kibana。注意,在滴滴云上如果需要外网访问某端口,需要在安全组中打开相应端口。
输入用户名和密码后可以看到Kibana的页面。
我们现在尝试在ES中插入一条日志。
1 2 3 | <font size=5> curl -XPUT 'localhost:9200/test-log-2019-12-21?pretty' curl -XPUT 'localhost:9200/test-log-2019-12-21/log/1?pretty' -d '{"msg":"滴滴云测试日志"}' |
成功后,在Kibana中创建索引匹配规则。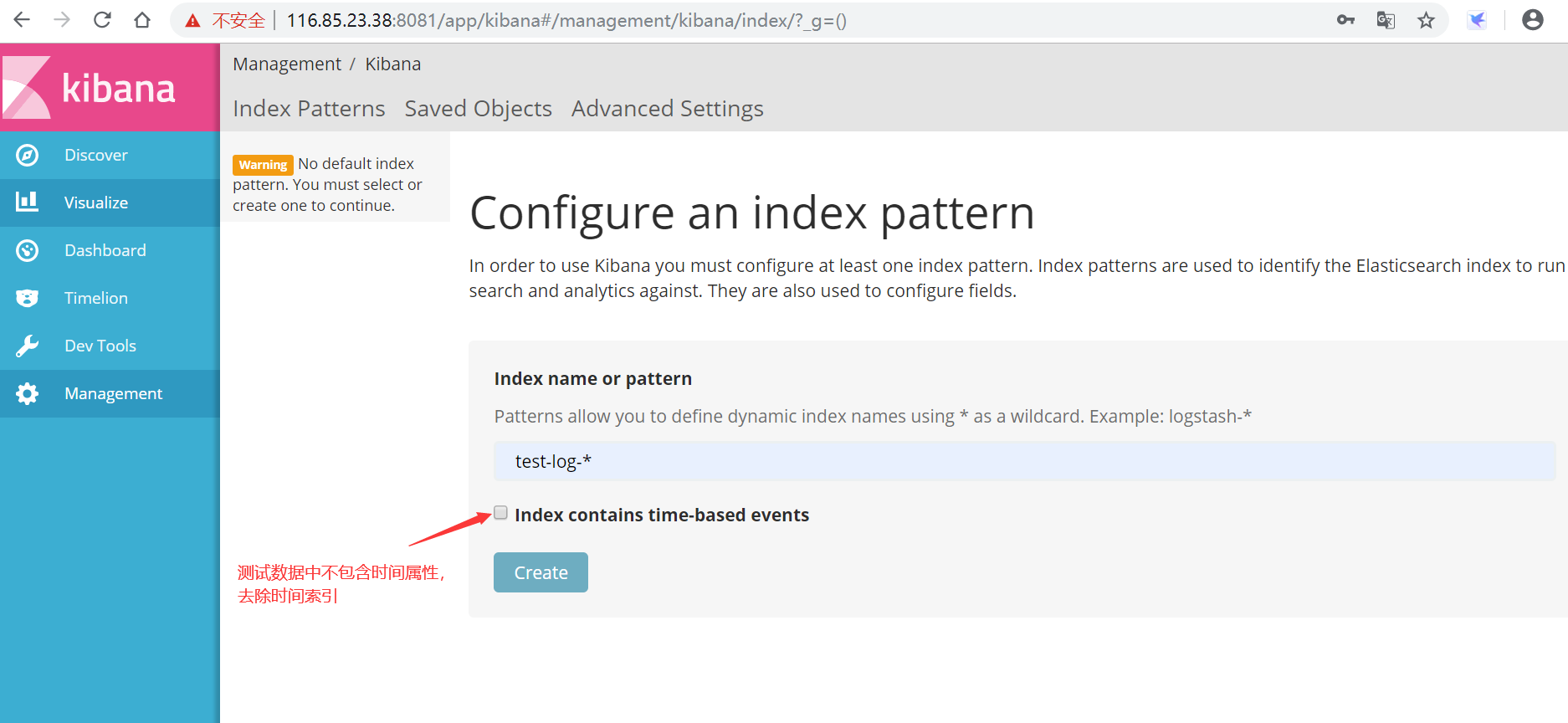
创建完成后可以在discover中可以查看到这条日志。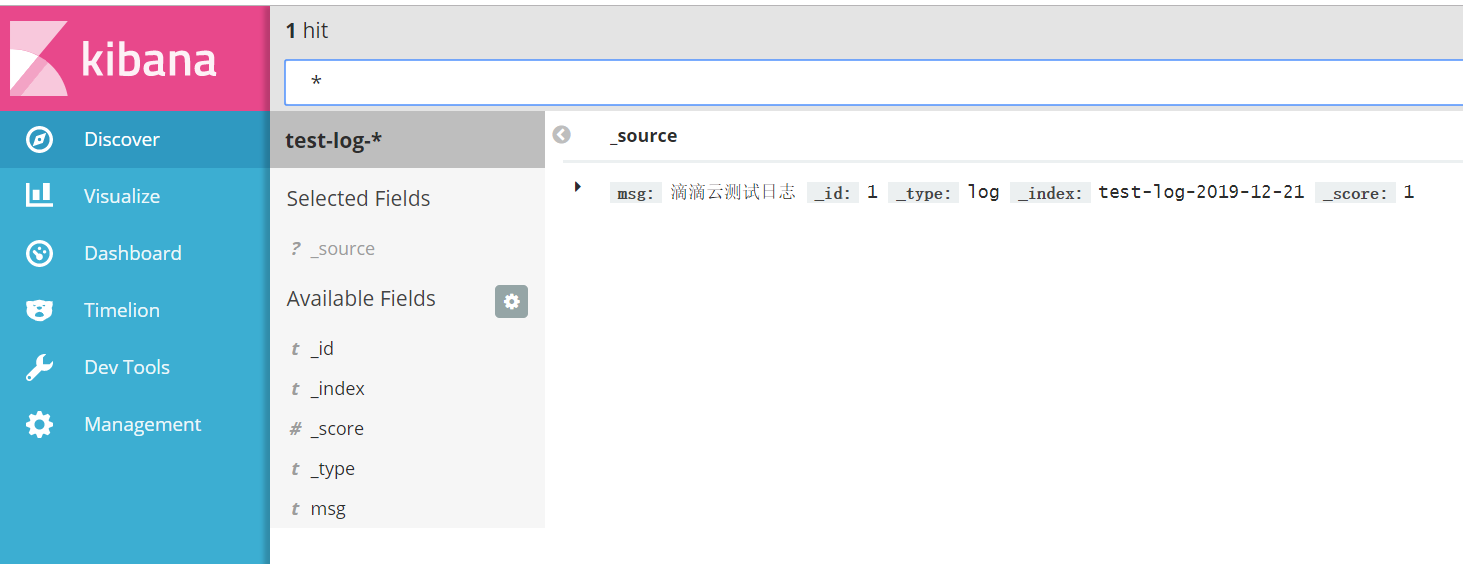
安装Logstash
1 2 3 4 | <font size=5> wget https://artifacts.elastic.co/downloads/logstash/logstash-5.3.0.tar.gz tar -zxvf logstash-5.3.0.tar.gz mv logstash-5.3.0 /usr/local/ |
Logstash的主要功能就是对输入的数据进行处理然后输出,因此就要为这些数建立一个通道,通过修改一下配置文件来创建通道:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | <font size=5> vim /usr/local/logstash-5.3.0/config/test-pipeline.conf # 指定输入源为beats 通过9011端口接收数据 input { beats { port => 9011 } } # 指定数据输出到elasticsearch 并且指定index名称,此例中我们来收集nginx的日志 output { elasticsearch { hosts => [ "localhost:9200" ] index => "nginx-pipeline-%{+YYYY.MM.dd}" } } |
启动Logstash。
1 2 | <font size=5> /usr/local/logstash-5.3.0/bin/logstash -f /usr/local/logstash-5.3.0/config/nginx-pipeline.conf |
如果看到以下信息,说明Logstash启动成功。
1 2 3 4 5 | <font size=5> [2019-12-22T22:44:45,118][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>4, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>500} [2019-12-22T22:44:45,611][INFO ][logstash.inputs.beats ] Beats inputs: Starting input listener {:address=>"0.0.0.0:9011"} [2019-12-22T22:44:45,648][INFO ][logstash.pipeline ] Pipeline main started [2019-12-22T22:44:45,780][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600} |
安装Filebeat
本例中的Beats我们选择Filebeat来收集本机的/var/log/nginx/以.log结尾的日志。
下载安装Filebeat。
1 2 3 4 | <font size=5> wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.3.1-linux-x86_64.tar.gz tar -zxvf filebeat-5.3.1-linux-x86_64.tar.gz mv filebeat-5.3.1-linux-x86_64 /usr/local/filebeat-5.3.1 |
配置数据采集和输出属性:
1 2 | <font size=5> vim /usr/local/filebeat-5.3.1/filebeat.yml |
默认配置是向ES输出:
1 2 3 4 5 | <font size=5> #-------------------------- Elasticsearch output ------------------------------ output.elasticsearch: # Array of hosts to connect to. hosts: ["localhost:9200"] |
修改为向logstash输出。
1 2 3 4 5 | <font size=5> #-------------------------- Elasticsearch output ------------------------------ output.logstash: # Array of hosts to connect to. hosts: ["localhost:9011"] |
配置文件中采集/var/log/nignx下以.log结尾的文件。
1 2 3 4 | <font size=5> input_type: log paths: - /var/log/nginx/*.log |
启动Filebeat。
1 2 | <font size=5> /usr/local/filebeat-5.3.1/filebeat -c /usr/local/filebeat-5.3.1/filebeat.yml |
在Kibana中创建新的pattern。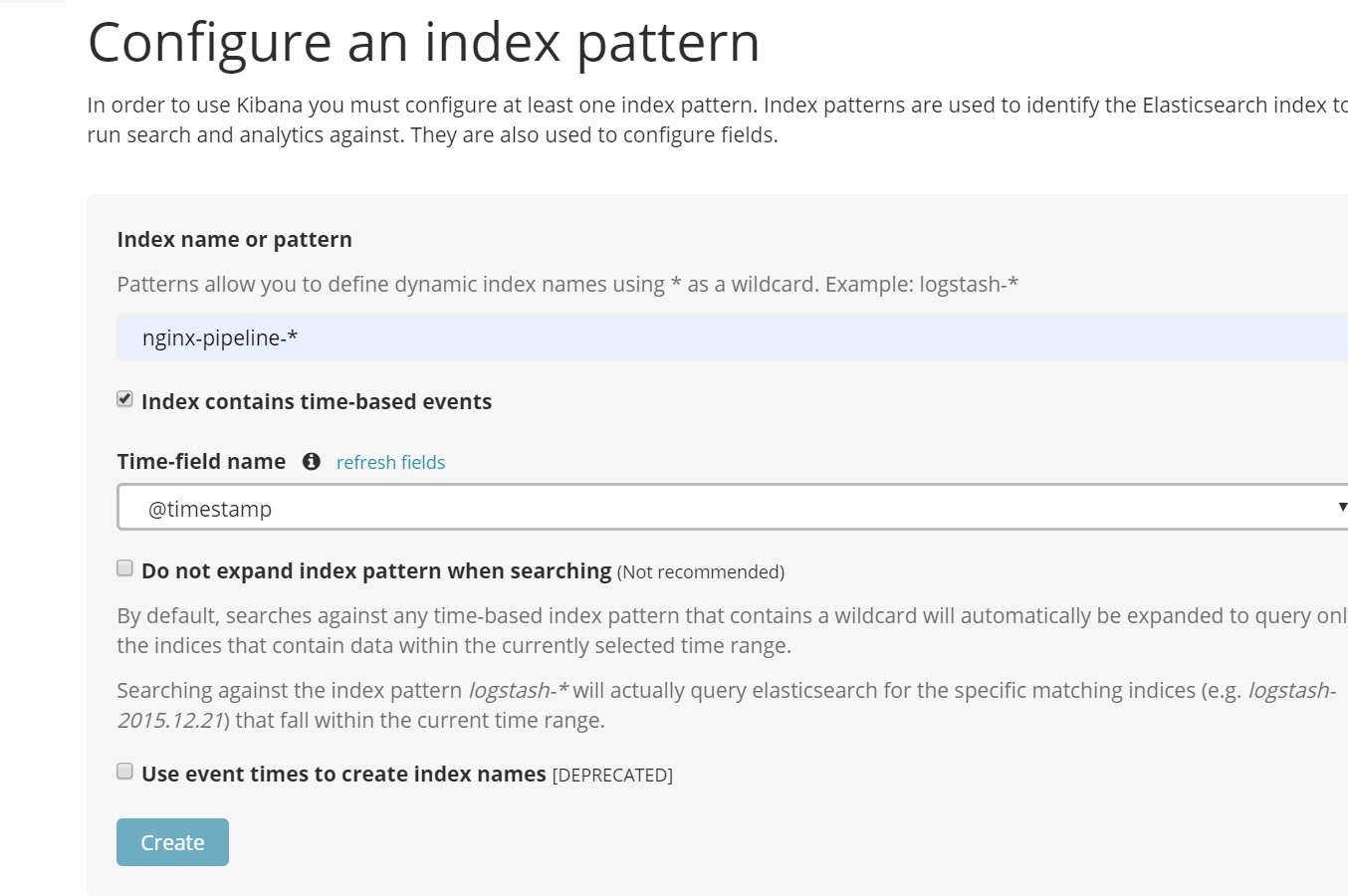
创建完成后可以到Discover中看到日志信息。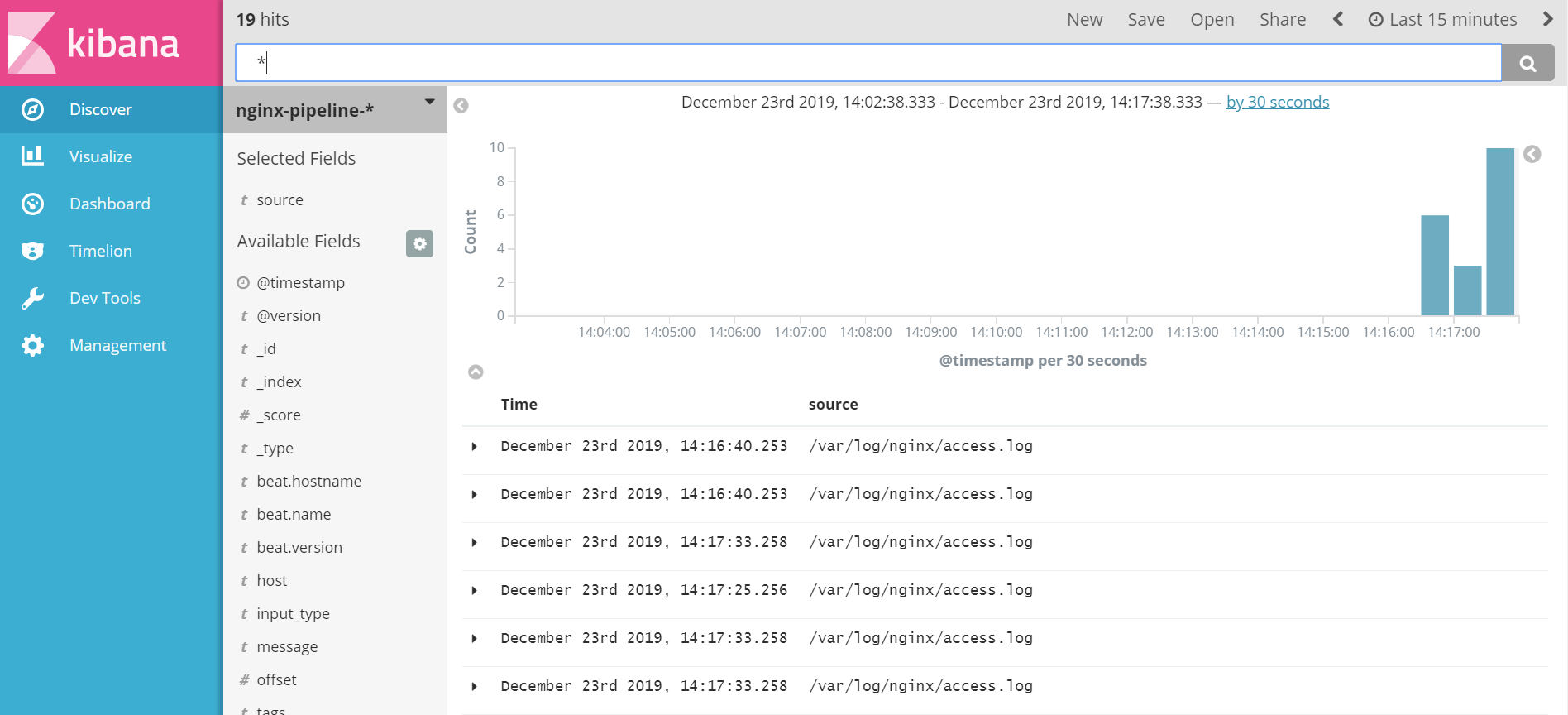
点击source可以看到总共收集了2个日志,access.log和error.log。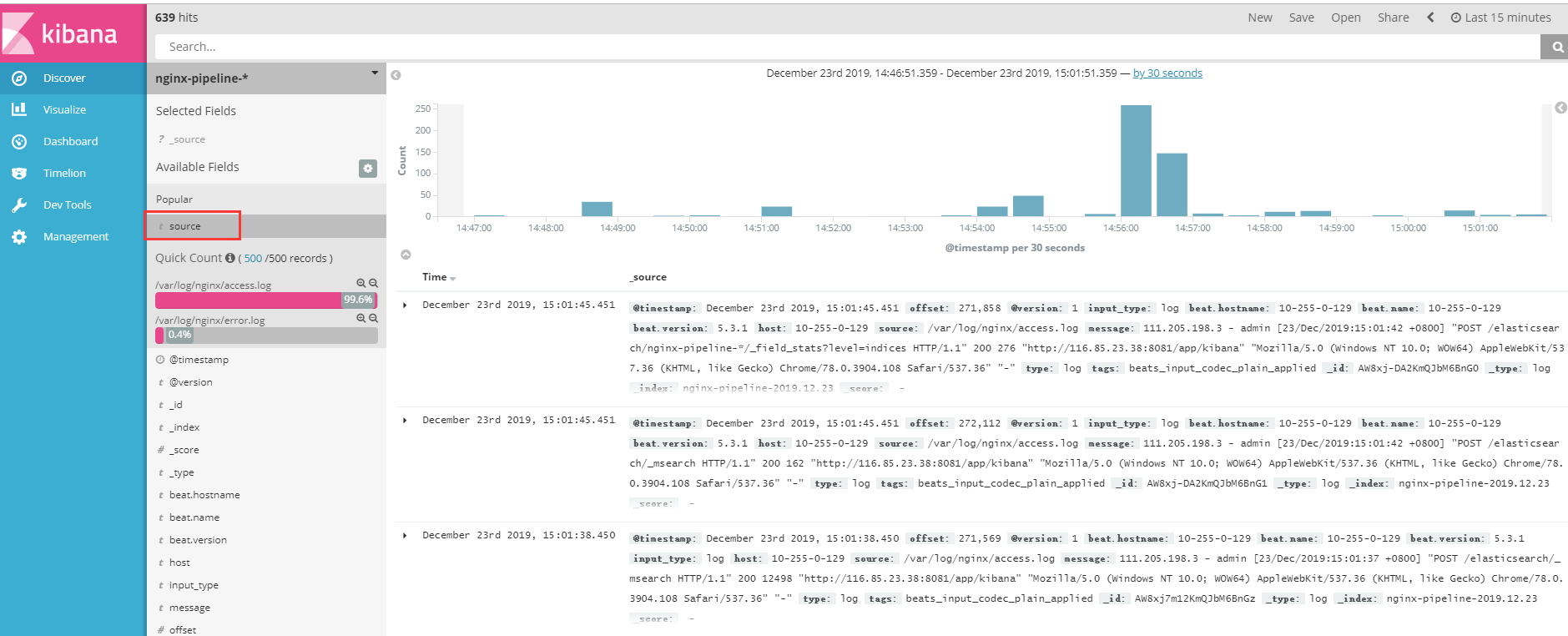
展开可以看到日志的详细信息,比如我们要看error.log的详细信息。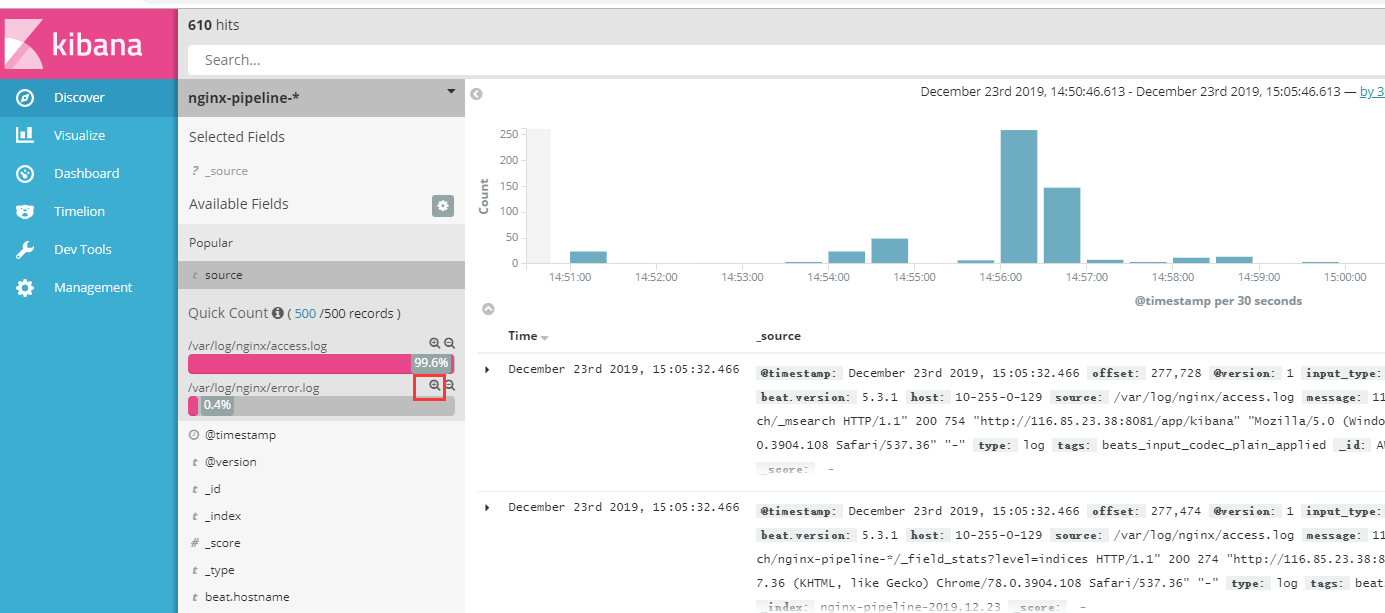
这样error.log的详细信息就展示出来了。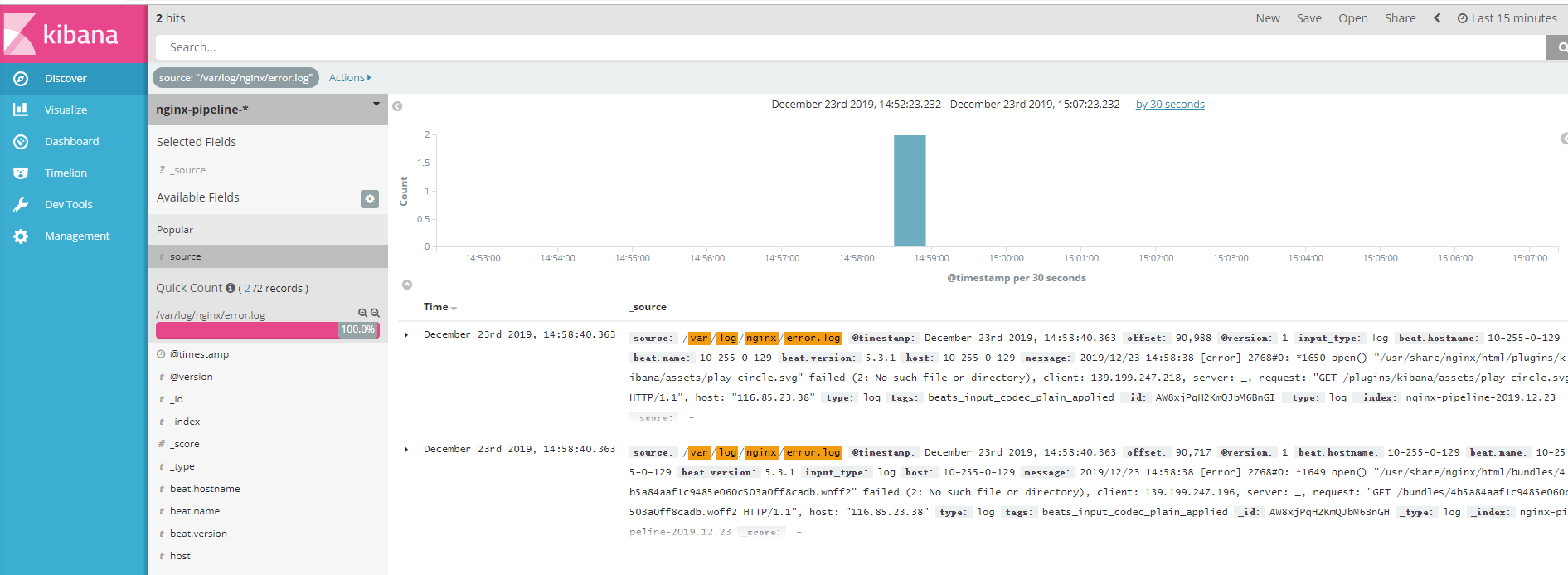
总结
至此,我们完成了一个简单的ELK应用,其中还包含了Filebeat,符合官网的标准ELK+beat架构。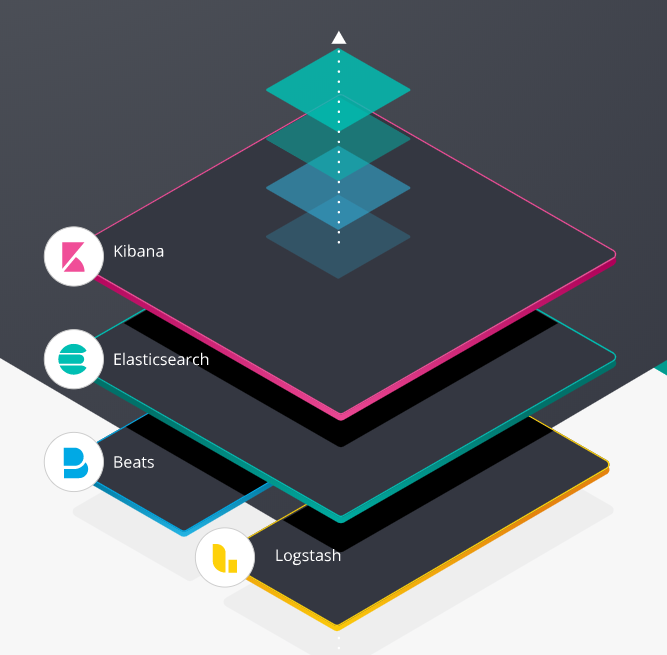
参考链接:
https://www.elastic.co/
https://blog.csdn.net/u011142688/article/details/78499332
https://blog.csdn.net/u011142688/article/details/78499348
