

监控报警是服务稳定的基础,是性能优化的重要依据,是可以未雨绸缪的重大利器。现代系统赋予了监控报警重要地位,近年来随着微服务设计理念不断成熟与广泛使用,做为系统方案的设计者,监控的选择和使用将是搭建系统不可或缺的一个环节。
Prometheus和Grafana像一组黄金搭档一样出现在了历史的洪流中,就像当年PHP和MYSQL一样。这两个系统以其明确的分工以及简单易用的特性、高度可扩展性,在这个领域赢得了一席之地。
可谓如果对指标收集、监控、报警毫无头绪,那选择Prometheus和Grafana就一定没有错。
1. Prometheus
Prometheus 是一个集监控(图表) + 报警 + 时序数据库于一体的开源项目。它采用定期拉取接口的方式来采集需要统计的指标。
1.1 结构和运作方式
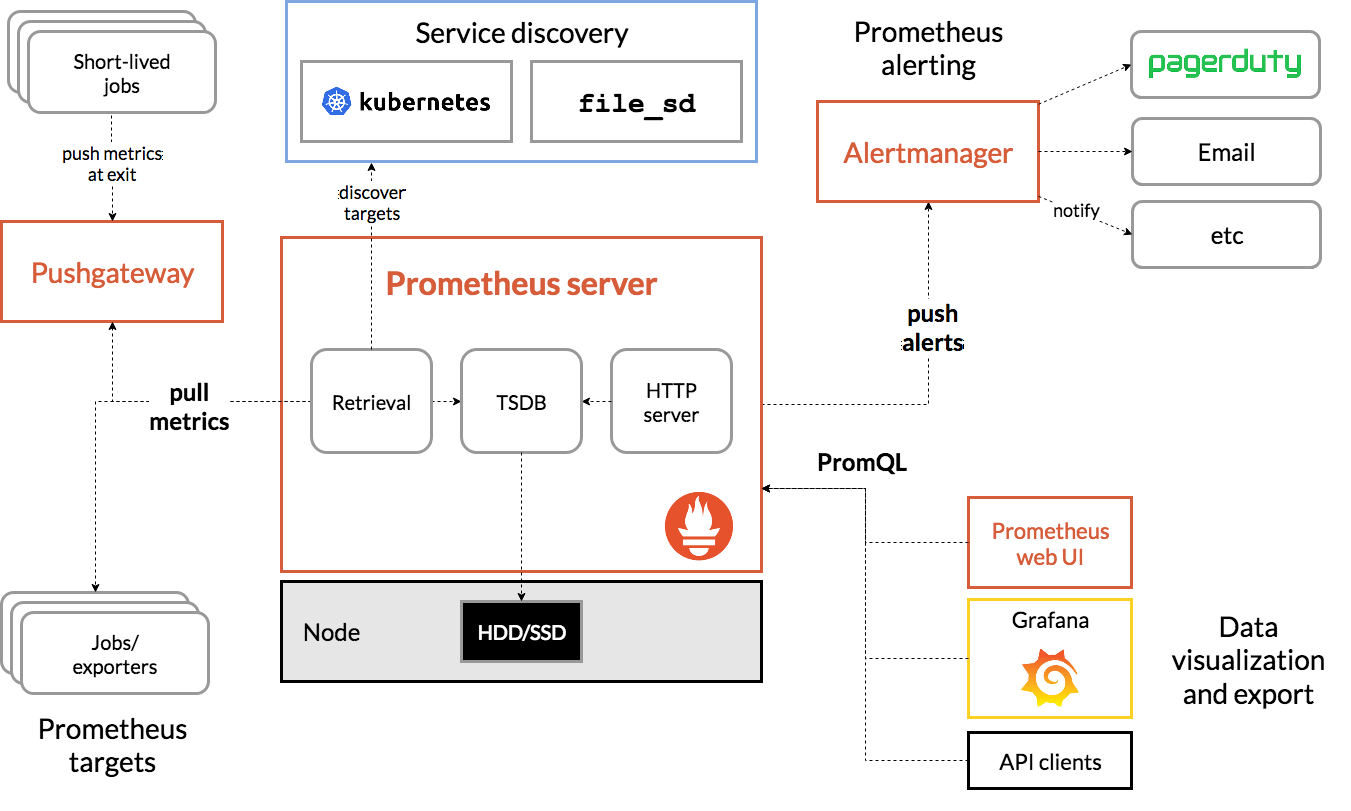
| 组成部分 | 说明 |
|---|---|
| Prometheus Server | 核心组件,只负责数据收集和查询支持, 并不直接监控目标服务。它会周期性地从 exporter 抓取监控数据 |
| Exporter | 采集组件,一种统称。在目标系统中采集数据,并暴露http接口,供 Prometheus Server 拉取 |
| Push Gateway | 一个特殊的 Exporter。如果系统无法支持拉取,可将主动数据push到一个PushGateway,该 gateway 作为一个exporter供 Prometheus Server 拉取 |
| Alert Manager | 用于定制报警策略和报警方式 |
| WebUI | 用于查询的交互界面 |
关于Exporter
一般来说,指标数据的提供就需要改造现有业务组件做为Exporter。像go或者Java这种长驻进程类的语言,都提供了Promethues客户端包来暴露服务的常用指标。如与Spring Boot结合使用的Micrometer Registry Prometheus,它不仅提供了JVM的统计数据(如GC的各代的堆大小,线程数量等),还提供了接口请求的响应时间,QPS等等;当然自定义指标是肯定可以支持的。go语言也有对应的包Prometheus Go client library,虽不及Java的强大,但该有的功能也一个不少。
对于PHP这种并非常驻内存的编程语言来说,实现指标的暴露就比较麻烦了。有一种方案是使用如redis的本地存储,将指标记录下来,以便Prometheus Server来拉取的时候可以采集到完整的指标。但这个方案的缺点很明显,与业务耦合了。
Prometheus提供了Pushgateway的方案,像PHP这样的服务往Pushgateway上打点,再由Pushgateway提供Exporter的功能暴露指标。
1.2 数据的存储
Prometheus将拉取到的指标数据保存于时间序列数据库中(TSDB),默认提供了本地文件式的TSDB,可以直接使用,一般可满足大部分监控场景。
但考虑到持久化、高可用、迁移相关事宜,Prometheus 通过支持配置 remote_read/remote_write接口的方式,可以很方便地使用外部的存储,如InfluxDB,甚至Elasticsearch等等。
1.3 统计实践
通过访问 exporter 暴露的http接口,可采集到如下格式的样本数据:
# HELP task_execute_count task执行计数
# TYPE task_execute_count counter
task_execute_count{task="test1",instance="host1.huajiao.com",} 10
task_execute_count{task="test1",instance="host2.huajiao.com",} 20
# HELP system_load_average_1m 1分钟内机器负载
# TYPE system_load_average_1m gauge
system_load_average_1m{application="system-java"} 0.06
# HELP task_consume_all 接口耗时分布
# TYPE task_consume_all histogram
task_consume_all_bucket{le="10"} 100
task_consume_all_bucket{le="20"} 200
task_consume_all_bucket{le="+Inf"} 100
task_consume_all_sum 10000
task_consume_all_count 400
# HELP go_gc_duration_seconds GC耗时统计
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.326e-05
go_gc_duration_seconds{quantile="0.25"} 3.9552e-05
go_gc_duration_seconds{quantile="0.5"} 4.9175e-05
go_gc_duration_seconds{quantile="0.75"} 6.5348e-05
go_gc_duration_seconds{quantile="1"} 0.000909402
go_gc_duration_seconds_sum 132.156493338
go_gc_duration_seconds_count 2.217437e+06
该样本数据中包含四种指标类型,以下一一介绍。
指标类型
指标类型由Exporter做标记。上面示例中以 # 开头的注释标识了采集到样本的信息:HELP是描述。TYPE标识了样本的指标类型。
指标的类型分为四大类:
- Counter 计数器,可用于接口请求数,任务完成数等。可用来展示QPS类数据。
- Gauge 实时值。可用于展示系统负载,内存使用
- Histogram 直方图(柱状图)。 用于将数据分组,如:耗时分布
- Summary 概括分布。类似直方图,但是支持按百分比划分结果。可展示出:“95%接口耗时都在200毫秒以下”的效果。
前两中用于反应当前系统运行状态,后两种用于分析数据分布。
样本
统计样本一般由一个 metric(指标) 和N个label(标签)。如:
main_api{api="main/index",code="200"} 100
其中main_api是指标,并包含2个标签api code,最后的100是样本值。
标签相当于维度,相同指标、相同标签的数据构成一条时间序列。
查询 PromQL
其全称是 Prometheus Query Language。是 Prometheus 提供的一种特殊表达式,来查询监控数据。
交互界面是Prometheus 提供的可视化的 Web操作界面——Graph 。
瞬时向量
简单的可以查询某项指标、某标签下的指标。如:
main_api #列出该指标所有数据
main_api{instance="host1.huajiao.com", code="200"} #过滤出指定标签下的数据
main_api{code=~"5.*"} #支持正则过滤规则 =~
以上查询只列出最新的一个样本,样本集被称为 瞬时向量 instant vector。如果要列出一批样本,需要指定时间范围,筛选出区间向量 range vector。
区间向量
区间向量用于指定时间范围的时间单位有:s-秒 m-分 h-小时 d-天 w-周 y-年
main_api{code="200"}[1m] #最近1分钟内http响应码为200的样本
如果想查询之前样本还可以指定偏移 offset
main_api{code="200"}[1m] offset 5m #5分钟前 1分钟内http响应码为200的样本
结合操作符的查询
Prometheus 内对于样本的操作符有以下几类:
- 数学操作符:加减乘除、取模等
- 比较操作符:
==,>,<等 - 三个逻辑操作符:
andorunless - 聚合操作符:
sum,count,topk等
通过这些操作符以及一些内置函数,可以实现一些直观的数据统计:
a.统计接口的QPS
rate(main_api[5m])
该指标为 counter 类型,所以要用 rate 获取其平均增长值。
rate是计算每秒速率。其中
[5m]表示按取每5分钟内的值计算平均值,数值越大,曲线越平滑
b.按api标签分组 获取QPS
sum(rate(main_api{api=~"live/.*"}[1m])) by(api)
c.按api标签分组,获取QPS的Top30
topk(30, sum(rate(main_api[1m])) by(api))
d.统计各个接口的99%的响应时间
histogram_quantile(0.99, sum(rate(api_consume_all_bucket[1m])) by (le))
rate
对于counter这种只增不减的指标类型,展示时要将数值转换为单位时间内的增长值。这就要用到 rate 函数。
rate(counter[5s]) = (样本值 - 5s前的样本值) / 5s
2. 结合 Grafana
PromQL 的查询虽然强大,然而展示太简陋。Grafana 很好的弥补了这个短板。它可以和 Prometheus 完美结合,并支持多种展现方式。
Grafana 支持 Prometheus 作为数据源,Prometheus对外也提供了api用于进行查询。只需要在grafana操作界面做简单配置即可。
2.1 部分图表展示
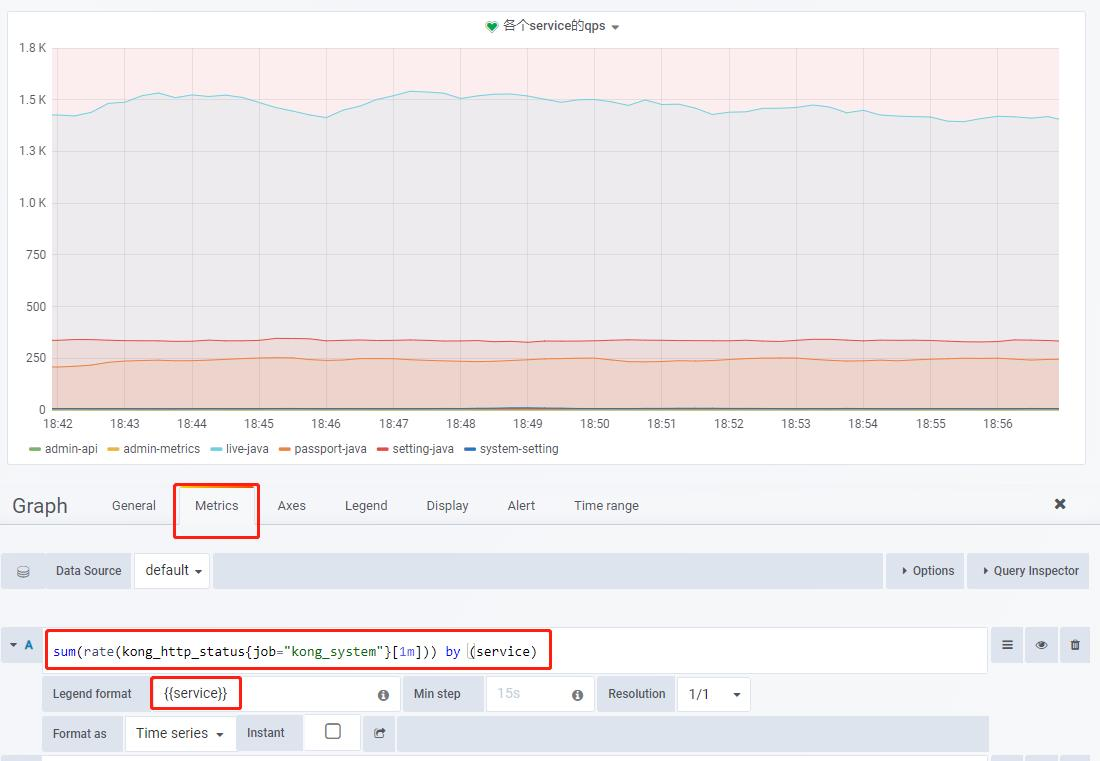
QPS
Grafana 中配置图表使用就是在Prometheus后台的查询。如各服务接口的QPS:
sum(rate(kong_http_status{job="kong_system"}[1m])) by (service)
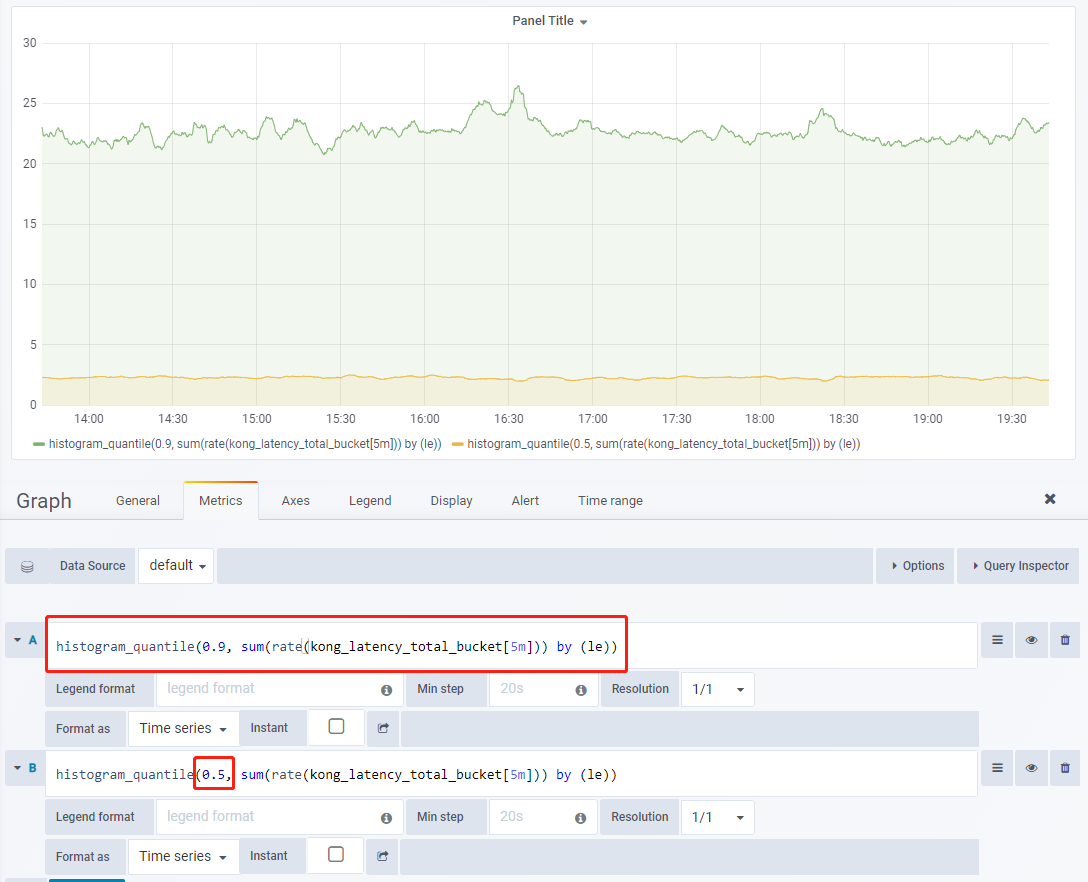
耗时分布
90%的耗时和50%的耗时分布
histogram_quantile(0.9, sum(rate(kong_latency_total_bucket[5m])) by (le))
histogram_quantile(0.5, sum(rate(kong_latency_total_bucket[5m])) by (le))
2.2 报警
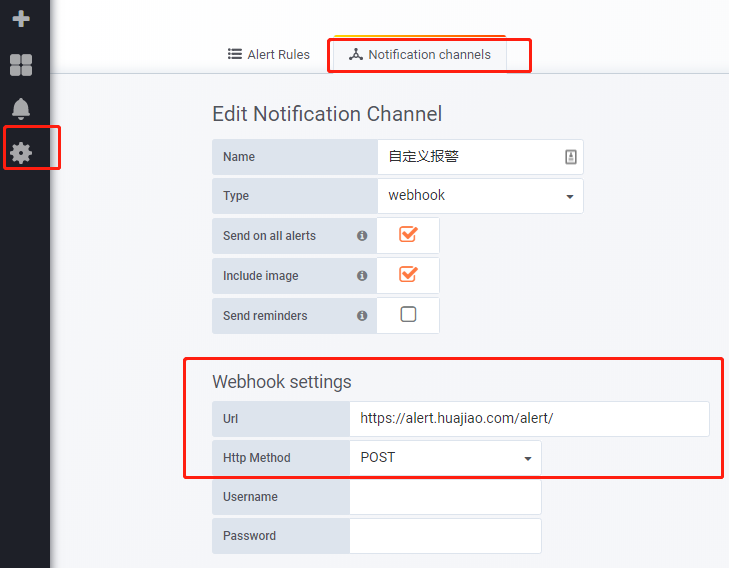
Prometheus自带AlertManager组件用于监控报警,然而 Grafana 的报警功能操作更方便,学习成本更低。在特定图标上点击编辑,即可见到 alert 报警选项卡。
报警方式
grafana 支持多种报警方式,最为方便的就是 webhook。当触发报警条件时,以http请求的方式调用报警接口,继而实现自定义的报警方式。
报警条件
grafana 定义了一些函数用来检测触发条件。如阈值检测,变化检测。而且支持自定义时间区间。如:
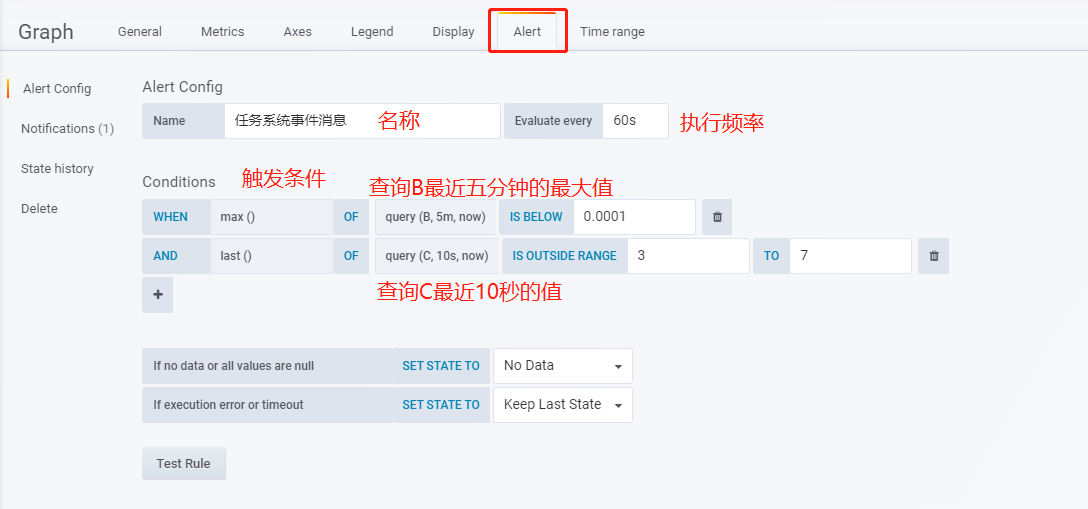
上述报警条件为:查询语句B最近五分钟的最大值低于 0.0001 并且 查询语句C最近10s的值不在于3~7之间,就触发报警。
阈值判断除了max()函数外,还有 sum(), count(), median(), avg() 。此外还有可用于进行变化检测的 diff() 函数,用于检测QPS突增等情况。
3. 花椒中的应用
3.1 Gateway
花椒系统中有PHP的项目,考虑到PHP无法内置exporter,必须用到 PushGateWay。官网 Prometheus 的插件 声明了几个缺点:
- 容易成为单点
- Prometheus无法对服务的监控
- 数据没有淘汰机制,旧数据不会自动清理
然而除外还有一个严重缺点:新数据覆盖旧数据,推送到gateway的值,即为最终值。这样就无法支持打点方式计数。
因此花椒同事自行研发了一套用于接入 Prometheus 的高性能方案,包括一个Gateway和配套SDK。基本解决了所有缺点:
- 多集群部署,避免单点故障,数据存储到 Redis
- 支持打点方式计数
- 打点请求使用UDP协议,最大程度减小对业务的性能影响
此外包括 Gateway和配套SDK。SDK与receiver的通信采用UDP协议,最大限度减小对业务的性能影响。
3.2 高可用方案
Prometheus的数据默认存储于本地,一旦故障服务不可用,甚至数据都会丢失,存在单点风险。
因此最好将数据远程保存,并做主从备份。此外还要搭建两个Prometheus实例,保证Prometheus本身的高可用性。
花椒选用了时序数据库 TimescaleDB。这是基于 PostGRESQL实现的。文档丰富,部署简单。
Prometheus 支持通过配置 remote_write 和 remote_read 的方式进行远程读写。本身其实是http请求。因此需要一个实现该操作的中间件Prometheus PostgreSQL Adapter.
中间件启动如下:
docker run -d -p 9201:9201 timescale/prometheus-postgresql-adapter:latest \
-pg-host=host.to.pgsql \
-pg-password=pwd2pg
配置如下:
remote_write:
- url: "http://127.0.0.1:9201/write"
remote_read:
- url: "http://127.0.0.1:9201/read"
3.3 优化查询
当PromeQL较为复杂或数据量很大时,查询可能超时。此类统计不能实时计算,必须提前制定规则,在后台定时计算。查询时只需要获取当前查询结果即可。
如下配置中,rule_files的每一个元素都是一个统计脚本配置。
rule_files:
- rule1.yml
- rule2.yml
rule1.yml中的配置可以是
groups:
- name: example
rules:
- record: job:http_inprogress_requests:sum
expr: sum(http_inprogress_requests) by (job)
其定时计算的频率设置字段为 global.evaluation_interval
4.结束语
Prometheus 最近风头正盛,明显感觉到使用的人越来越多。本文只是简单介绍了其部分功能。其他诸如与docker、K8s的配合,服务发现、集群等功能,因为没有涉及到,所以并未细述。
目前感觉 Prometheus比一些老牌监控系统如Nagios 更适用于如今的生产场景,而其开箱即用的便捷性,也使得切换到该系统变动简单可行。
5. 参考资料
- 官方参考文档: prometheus.io/docs/promet…
- Prometheus Book yunlzheng.gitbook.io/prometheus-…
