作为阿里经济体前端委员会四大技术方向之一,前端智能化项目经历了 2019 双十一的阶段性考验,交出了不错的答卷,天猫淘宝双十一会场新增模块 79.34% 的线上代码由前端智能化项目自动生成。在此期间研发小组经历了许多困难与思考,本次 《前端代码是怎样智能生成的》 系列分享,将与大家分享前端智能化项目中技术与思考的点点滴滴。
文/缺月
概述
在一个常见的开发周期中往往遵循着产品需求到交互稿到设计稿再到前端开发的过程。所以在 Design2Code (简称D2C) 项目过程中,设计师负责来设计产品视觉效果和产出视觉设计稿,而前端开发工程师以设计稿为输入进行开发。 所以同样地,在前端智能化的过程中,我们需要一种能自动解析设计稿信息的能力来替代传统的人工分析和抠图等繁琐的工作。同时,随着近几年主流设计工具(Sketch、PS、XD 等)的三方插件开发能力逐渐成熟,借助官方提供的 API 能够比较好得还原一些基本的结构化信息和样式信息,从而完成对设计稿原始信息的提取。在此篇文章中,我们将以前端智能化的落地产品 imgcook 的 Sketch 插件为例子,详细介绍我们是如何通过插件对设计稿做处理,最终导出以绝对布局为基础的元素信息,供下游布局算法使用。
所在分层
如图所示,链路中的第一层为物料识别层,设计稿将作为这一层的输入。这一层主要是用来识别页面和模块中包含的物料的,比如对基础组件,业务组件和基础控件的识别,从而辅助进行页面分割并对下游输入关于某一元素的相关信息。随后,设计稿的原始信息 (文件) 将会进入到图像处理层,这一层主要是通过这篇文章所介绍的插件实现,因为插件可以注入到 Sketch 或者 Photoshop 等设计工具中从而借助官方提供的一些能力完成对原始设计稿信息的提取。这一层提取的结果将是一个符合 imgcook 规范的 JSON 结构的数据,内容主要是提取出所有元素的相关信息,包含元素的绝对位置和 CSS 可表达的属性,最终可以理解以绝对定位为基础的模块和页面。同时,由于不同设计师可能遵循一些不同于传统前端开发的规范来组织设计稿的图层和结构,在图像再加工层中我们还将借助计算机视觉和智能化的能力对原始设计稿中出现的图层再加工。例如过滤掉一些无用的图层或是合并一些可以当作一个整体的图层等。
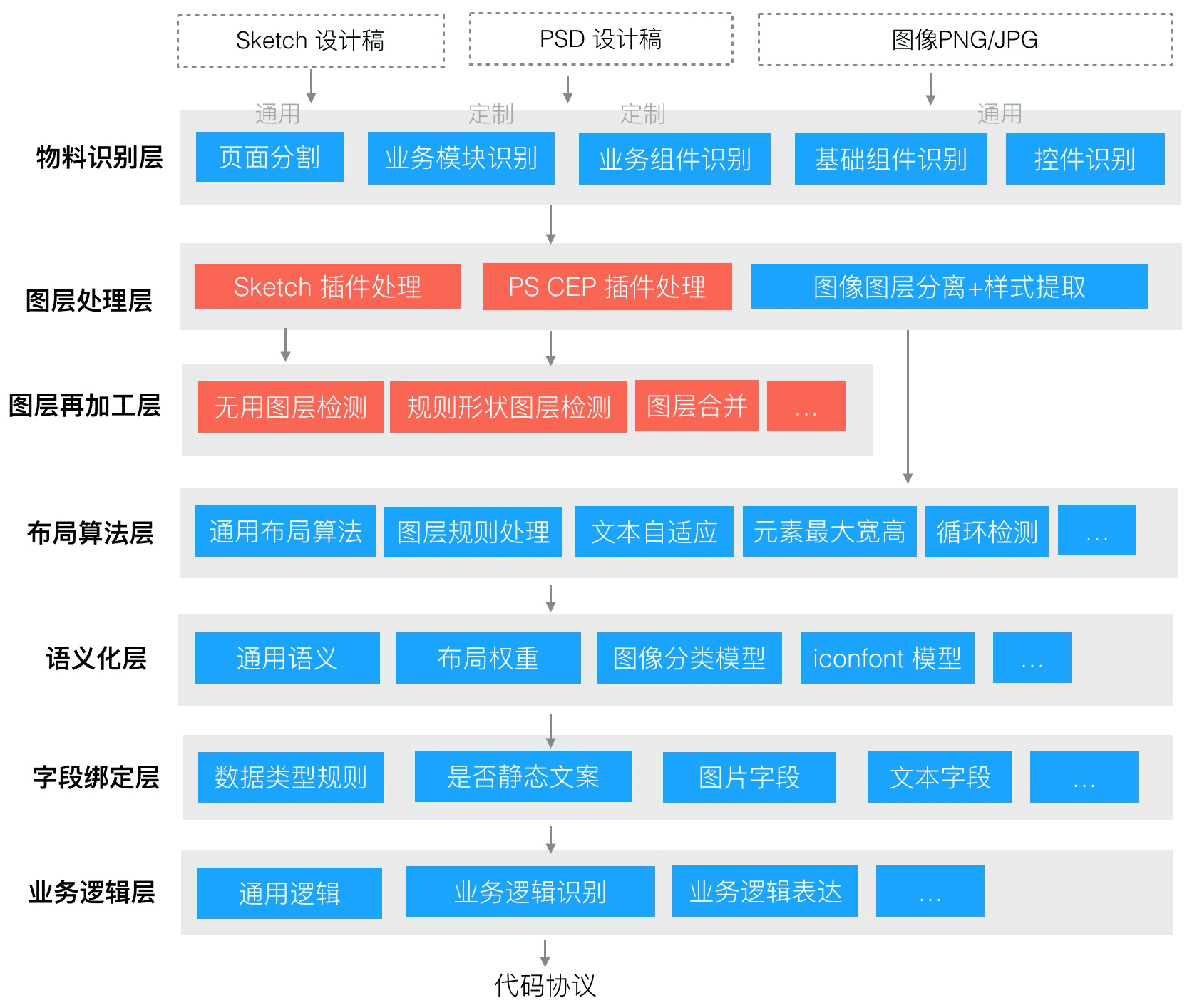
(D2C 技术能力分层)
技术选型
如图所示,在对接原始设计稿和获取原始设计稿信息的过程中,我们主要是使用了 Sketch 官方提供的 JS API 进行开发,对于一些官方没有包装 JS 接口的功能,我们借助于 CocoaScript 对原始 Objective-C 接口进行调用。同时,我们使用了 Webview 技术可以使用前端技术栈来渲染插件界面。我们采用 Skpm Sketch 的插件管理工具的脚手架能力和插件发布能力。
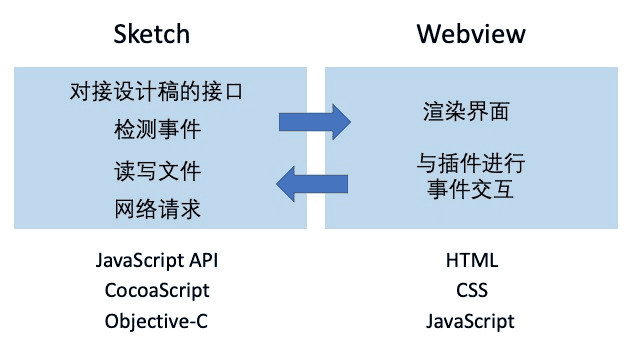
(插件技术选型示意图)
插件图层处理
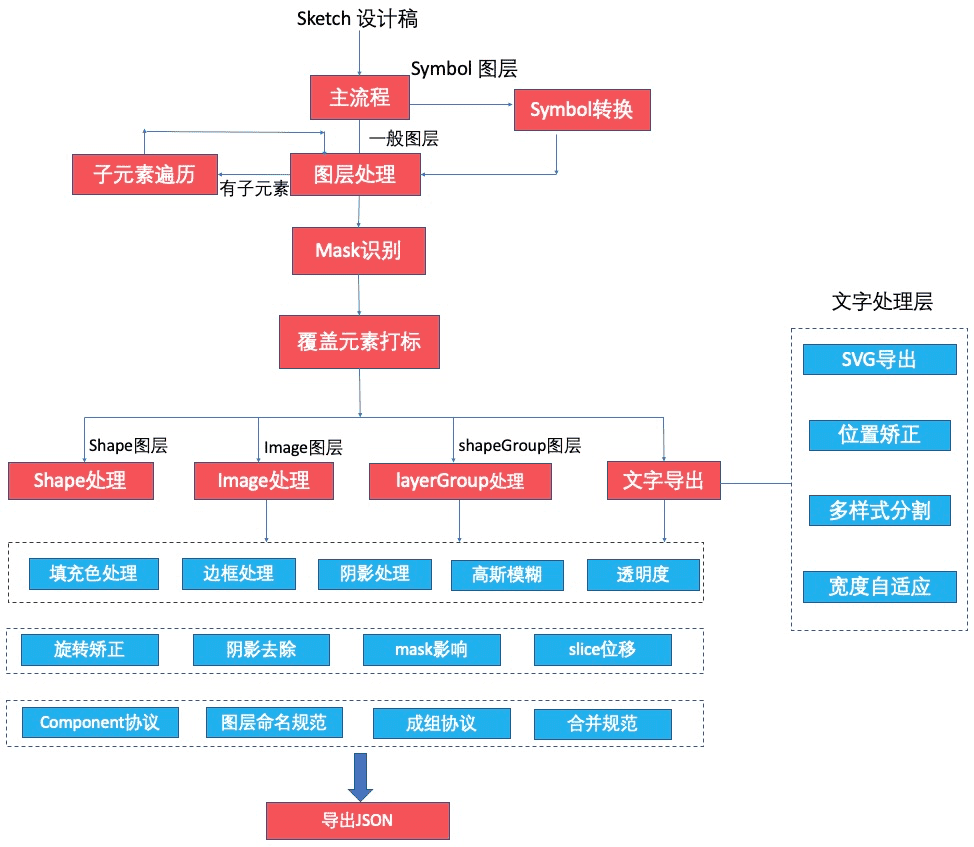
(插件图层处理流程)
总体流程
如结构图所示,imgcook Sketch 插件将读取设计稿,按 Depth-first Search (DFS) 的方式循环遍历所有类型的图层,提取图层的基本信息,包括位置和大小。值得注意的是由于 Sketch 里 Symbol 的概念相当于它的 Symbolmaster 的子类,可以覆盖它的 Symbolmaster 的部分属性,所以对于 Symbol 类型的图层,我们要找到它的 Symbolmaster,提取相关信息。之后我们会对所有会被蒙层影响的或者被其他图层覆盖的元素打标,因为这两者会影响到当前图层的视觉输出。之后因为各个类型具体的所拥有的样式不相同,我们会对 Shape, Image, Text 和其他图层分别做处理,把相关的 Sketch 属性转化为 CSS 理解的形式。我们对设计师约定了一些设计协议,可以通过在设计稿中不同的命名给图层指定为成组或者组件,同时带出相关组件信息。下面我们挑取这个过程中两个值得注意的难点进行分别讲解。
蒙层处理
在 Sketch 里蒙层的作用是相当于一个底板,所有在结构上位于其之上的图层如果区域超出了蒙层,这部分超出的区域就会被截断。对于蒙层的处理主要有以下几个不同于正常图层的点:
- 由于在 HTML 和 CSS 领域并没有直接对应的概念,蒙层并不能直接导出相关 CSS 属性或者 HTML 属性
- Mask 图层不但会影响自己本身的处理,也会影响其他图层的视觉,所以遇到 Mask 需要多图层一起处理
- 由于 Mask 的形状可能是不规则形状,所以需要考虑如何判断合理的区域进行截断
针对以上难点和精准还原视觉的目的,我们开发了一套算法计算 Mask 和其影响的所有图层的区域计算和形状计算,针对区域规则且形状规则的做 CSS 属性上的常规截取处理,对于无法使用 CSS 属性表示的情况对 Sketch 视觉可见的区域进行截图处理。其中,我们会进行无用图层检测,如果一个图层在它的 Mask 区域之外,则此图层将被视为无用图层被删除,同时,如果一个图层完全在它的 Mask 区域内,则此图层不会被 Mask 影响,按照原有逻辑处理。
智能文字位置校准
相对于其他诸如 Shape 和 Image 图层的处理, 文字图层会更复杂一点,原因主要有:
- 对于 Shape 和 Image 的每一个图层,我们往往也只需要对应导出一个节点,这个节点包括位置和样式等属性,但是对于文字图层,如果包含多样式,比如颜色,字号,行高等不同,则需要将一个文字图层拆分为多个节点导出
- Sketch 有定宽类型的文本框,但是对于 HTML 中 span 等标签为行内元素,没有宽度等信息,所以需要对 Sketch 中的多行文本做拆分
- 目前 Sketch 中文字图层想要得到位置和样式,需要依赖导出的 SVG 信息,而 SketchSVGExporter 接口导出的 SVG 信息经常出现位置不准的情况
针对第一个问题,我们对 SVG 信息进行循环检测,判断每个 SVG 子节点是否有 CSS 相关的属性发生了变化,如果有变化,就会新建立一个子节点存储相关信息。针对第二个问题,我们会对定宽的文本框导出准确的宽度信息还有行数信息,布局算法会针对此信息作出正确的判断。重点来讲一下第三个问题,由于 svg 信息在对于富文本的情况下会不准确的情况,我们设计了一套基于计算机视觉的算法会对文本框的基线进行矫正,整体流程如下:
- 对文字图层进行检测是否存在富文本文本框
- 由于在 Sketch 里单个文本框不同样式的文本基线一定在一条水平线上,我们的校准目标便是基于此。首先我们会对当前文本框做截图处理
- 借助 OpenCV 库分析截图
- 使用 Canny 边缘检测,分析出字体轮廓,确定基线位置
- 计算不同样式的文本之间的基线位置差
- 传回插件关于位置差的信息,插件对位置以最大字体为基准进行矫正
图层再加工
智能图层合并
设计稿的图层和前端开发之间还有一个差异就是图层合并的问题。往往设计师关注的焦点是能否在设计稿中实现想要的视觉效果,而不会像前端工程师一样关注元素结构和嵌套的合理性。所以有时候在设计稿中,设计师为了实现一个诸如 icon 或者氛围图等视觉效果时,会使用若干的小图层拼接起来,但是从结构角度来讲,这个拼接起来的图形应该是一个整体,在这种情况下我们就需要合并图层(将若干个图层作为一个图层,截图导出)。我们实现了一套自动合并图层的算法,算法会自动检测一个组下是否有若干个应该被合并的图层,然后自动在导出的过程中合并,以便后续链路可以处理结构。
无用图层检测
在设计稿中,设计师有时会添加一些对最终布局和视觉没有影响的图层,为了结构的合理性和精简性,我们需要对这部分图层进行筛除。如下的情况下图层会被处理:
- 如果有两个 Image 图层视觉是一样的但是引用的 url 不同,则统一到相同的 url
- 如果图层没有 backgroundImage, backgroundColor 和 borderWidth 属性,则图层没有视觉效果,直接过滤掉
- 如果有无某图层没有对图像矩阵产生影响,则过滤掉此图层
- 如果图层被非透明图层覆盖,则过滤掉此图层
- 如果有透明区域小于某个阈值的图片,则过滤掉此图层
插件测试和度量
单元测试体系
由于 Sketch 插件是 imgcook智能生成代码体系的上游,在每一次代码更改和发布之前,需要对插件做严格的测试以确保功能可用,所以我们使用 Skpm-Test, 一个 Skpm 体系下的类 Jest 测试框架建立了单元测试体系,覆盖率达到 95%左右。
绝对定位布局查看
如之前讲到的,Sketch 插件导出的信息是包含每个子节点的绝对定位的位置和相关的 CSS 属性,每个节点的属性和类型和 HTML 一一映射,所以我们可以将导出 JSON 直接转化为 HTML + CSS 查看导出效果,使用者可以直接通过 imgcook.taobao.org/design-rest… 粘贴导出的 JSON 查看效果
视觉还原度量体系
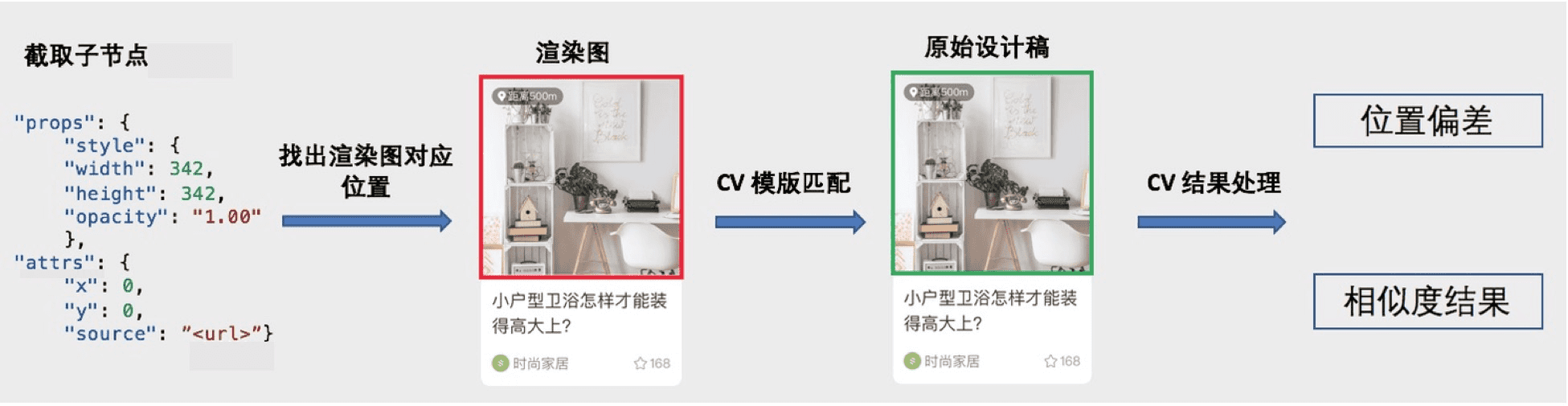
(插件视觉度量流程)
我们借助计算机视觉处理库 OpenCV 开发了一套算法用于衡量导出的 JSON 数据是否完全还原了原设计稿的视觉效果。
OpenCV 计算视觉还原分数主要分为以下几个步骤
- 图层预处理
- 如果原始图像和导出图像大小不一致,重置到相同大小
- 将图像转成灰白图
- 图层对比主逻辑
- 分析导出的 JSON 信息,对 JSON 里每个子元素进行如下操作:
- 获取子元素的宽高和位置: x, y, w, h
- 记录此元素的内部有多少子元素和横跨的元素
- 对于每个子元素,取出原设计稿图相对应的区域
- 模版匹配:使用 OpenCV 模版匹配找出此区域在总还原图中的位置和相似度
- 如果有元素跨越了此元素并且那个元素已经被处理过,则忽略此元素
- 如果此元素有子元素并且子元素已经被处理过,则忽略此元素
- 处理完成导出 JSON
- JSON 元素集合的一个数组,对于每个数组中的元素有如下属性
- originPosition: 原始设计稿此元素的位置
- exportPosition: 导出图层此元素的位置
- similarity: 导出图层和原始设计稿相似度
- width: 原始宽度
- height: 原始高度
可以看出,我们通过计算机视觉已经分析出了每个图层的原始位置和还原后的位置,同时度量了每个图层的相似度,综合的度量分数应该综合考虑以下三个指标:
- 总图层数量
- 还原图层相似度
- 还原图层的位置
从这三个指标出发,我们设计如下公式计算还原度:

其中 P 表示 restore 分数, n 表示图层的总数量,



未来展望
去规范继续升级
目前我们出了一些设计协议要求设计师按照一定的规范来制作设计稿,以便可以达到更好的还原效果;对设计稿的约束规范曾经高达 20+ 条,我们通过智能图层加工层去掉了大部分规范,目前主要剩下 3 条约束,接下来,我们将进一步通过智能化的手段逐步的去掉这些对设计师和前端的约束,达到 0 约束还原。
还原能力升级
我们将在未来的 Sketch 版本中继续提高 Sketch 插件的视觉还原度,目前阶段根据度量体系 Sketch 还原的能力平均在 95% 左右,我们将在之后的版本中继续提高这个能力。
还原效率升级
目前由于在插件中设计到大量的极速过程,导致导出速度有的时候不尽理想,我们也对这个问题进行了一定的调研,发现目前插件的确是在处理多图层,尤其是包含多张图片上传的场景速度比较慢,未来我们也会对还原速度进行一次大幅度的升级。
在科技飞速发展的今天,前端智能化的浪潮已经到来,未来一些简单的、重复性、规律性强的开发一定会逐渐地被机器取代,在这样的过程中,机器对设计稿的理解也一定会更上一个台阶。我们也会保证插件在未来达到更高的智能化水平,从而准确地理解设计师的意图从而更好的为前端服务!
更多推荐:
- imgcook 官网 体验一键智能生成代码
- imgcook 知乎专栏 为你带来前端智能化前沿资讯
- 钉钉交流