


文/缺月
随着深度学习的发展,智能化已经开始赋能各行各业,前端作为互联网中离用户最近的一环,也希望借助 AI 的能力大幅提高效率,减少人力成本,给用户创建更好的体验,因此,前端智能化也被看作是前端的未来的重要发展方向。然而,当实际和前端工程师交流的时候,我们往往会得到这些疑问:
- 我这业务已经很成熟了,也一直体验很好,为啥要机器学习?
- 听说需要海量数据和人工标注,还不如弄一堆 if else 好使。
- 好像算法需要较高的数学功底?
- 听说要学习Python等语言,有些犯怵。
从这些疑问出发,我们希望能有一种方案可以让 AI 助力前端这个职能角色提效的同时,可以尽最大可能的减少前端工程师使用机器学习的成本和负担。从这一点出发,我们诞生了开发一种 JS 框架的想法,这个框架应该是对前端工程师友好的,可以让前端快速收集,处理数据,进行机器学习实验而又不必掌握高深的数学和深度学习的知识,同时这个框架应该是灵活的,可扩展的,能达到工业级可用的。从这些目标出发,我们推出了 pipcook 这个基于 tfjs-node 的前端算法工程框架。
问题分解
通过实际的交流和调研下来,我们总结阻碍前端进入人工智能领域的原因主要有以下几点:
1. 语言门槛:在传统的机器学习和深度学习领域,Python,R,C++ 更多,前端使用的 JavaScript 语言涉及很少并且语言本身不适合密集型运算
2. 算法门槛:数学知识和算法知识的要求对前端来讲是一个巨大的挑战。
3. 场景门槛:前端领域可以应用智能化技术的场景相对比较缺乏,阻碍了前端进入该领域的动机。换句话讲前端缺少清晰定义智能化相关问题的能力,在考虑问题的时候并不会往这个方向思考
4. 数据门槛:高质量数据的获取是整个智能化领域共同的难题。 另外一个就是这些数据的格式,规范对前端并不友好。我们认为上述提到的问题是阻碍前端工程师朝着智能化方向前进的关键,那么下面我们就来从上述提到的几个方面详细分析以下我们应该怎样解决每个问题

落地场景
如之前提到的,在目前人工智能高速发展的情况下,智能化已经在赋能很多行业。我们认为不存在没有应用的场景,但是很多时候非算法人士并不能有效的辨别和判断出哪些场景是可以应用机器学习的技术解决的。同时,由于缺乏对模型和算法深入的学习,很多非算法开发者也不能确定深度学习究竟能多大程度的解决某个问题,解决的效果是否会比传统的规则引擎更好。解决这个问题的方法可以有两种:
- 可以使前端工程师去深入学习算法知识,了解每个算法背后的原理从而判断出哪一类问题可以用什么技术来解决,但是这种方式对于前端来说成本过高,而且可能并不会有很高的积极性
- 第二种方案是在我们的框架中总结出一套前端的业务和领域可能遇到的场景,对这些场景进行分类,这样实际上就形成了一种案例库,前端工程师通过这些案例库,很容易找到相似的场景,对哪些问题可以被机器学习解决有了更好的体感,最终将这些案例或者类似的案例以一种形象的,低学习成本的方式运用到自己的业务上去
数据处理
我们知道,深度学习的核心就是数据和模型,如果说模型是一种火箭发动机的话那么数据就是发动机所必需的燃料。机器学习需要高质量的和数量巨大的燃料才能发挥出它的优势。而实际上,在前端的手中,很多年来已经积累了一些数据,并且前端作为离用户最近的一环,也是收集数据方面非常有优势的一环
我们回过头来看看,前端手里有什么数据:
• UI 数据,沉淀了一些视觉稿,一些模块库,质量参差不齐。
• 代码数据:天天都在沉淀。
• 业务上线后的日志数据(性能,报错,其他定制采集的数据, .etc)
• 其它特定业务所具有的特定数据。
这些数据基本上可以归类为计算机视觉的数据和一部分文本数据,而 CV 和 NLP 也是机器学习重点解决的问题。那么现在的问题便是在有了数据之后,前端工程师往往不知道怎么处理这些数据从而让这些数据可以成为模型的燃料,相应的,我们的框架应该提供快速并且简单的处理相应的数据,并且提供数据质量评估,数据可视化等便捷的能力
算法
可能对于非算法工程师来说,另一个巨大的障碍就是模型或者说算法本身了。往往同学们心中有这样的疑虑,我也不懂这个模型的数学原理,相应的也不会用 tensorflow 等深度学习框架, 我怎么办?这个问题好解决,也不好解决。
好解决的是:在现阶段,一些传统深度学习的领域已经积累的很多年的经验,几乎每个领域都有当前最热门,最成熟,工业级可用的模型,我们在框架中只需要提供好这些的实现,开箱即用就好,不需要关心内部实现。不好解决的是,可能有一些同学觉得模型过于黑盒,自己知道一些算法的知识,想要对模型进行一些微调,所以我们在框架中也应该提供干预和调整的能力
语言

这个问题即简单也复杂, 说简单,便是说对于前端来说,用 JS 不就好了,这是前端最熟悉的语言,我们也是这么想的,所以 pipcook 采用纯 ts 开发,并且提供 js 的 api,几乎绝大多数的数据处理和模型的插件都是基于 tfjs-node 实现的。 但是说复杂,就是现阶段 js 的机器学习生态并不成熟,短时间内让 js 实现和 python 同等的生态也很不现实,这样一来,如果仅仅局限于 js 的话,这个框架势必从某种程度上来说是一个残缺的体系,所以我们的解决方案是像 swift 那样实现一个 node 版的 python,可以在 nodejs 里调用 python 的类库,从而为前端助力。
小结
通过解决以上的几个问题,我们基本解决了为什么要用,能不能用,和怎么用等几个问题,而每个问题都是紧贴这前端工程师这一视角而提供解决方案的,这样一来,随着 pipcook 的逐渐成熟和整个 js 的机器学习生态的逐渐成熟,我们相信,前端工程师也会迈上智能化的新台阶
技术方案
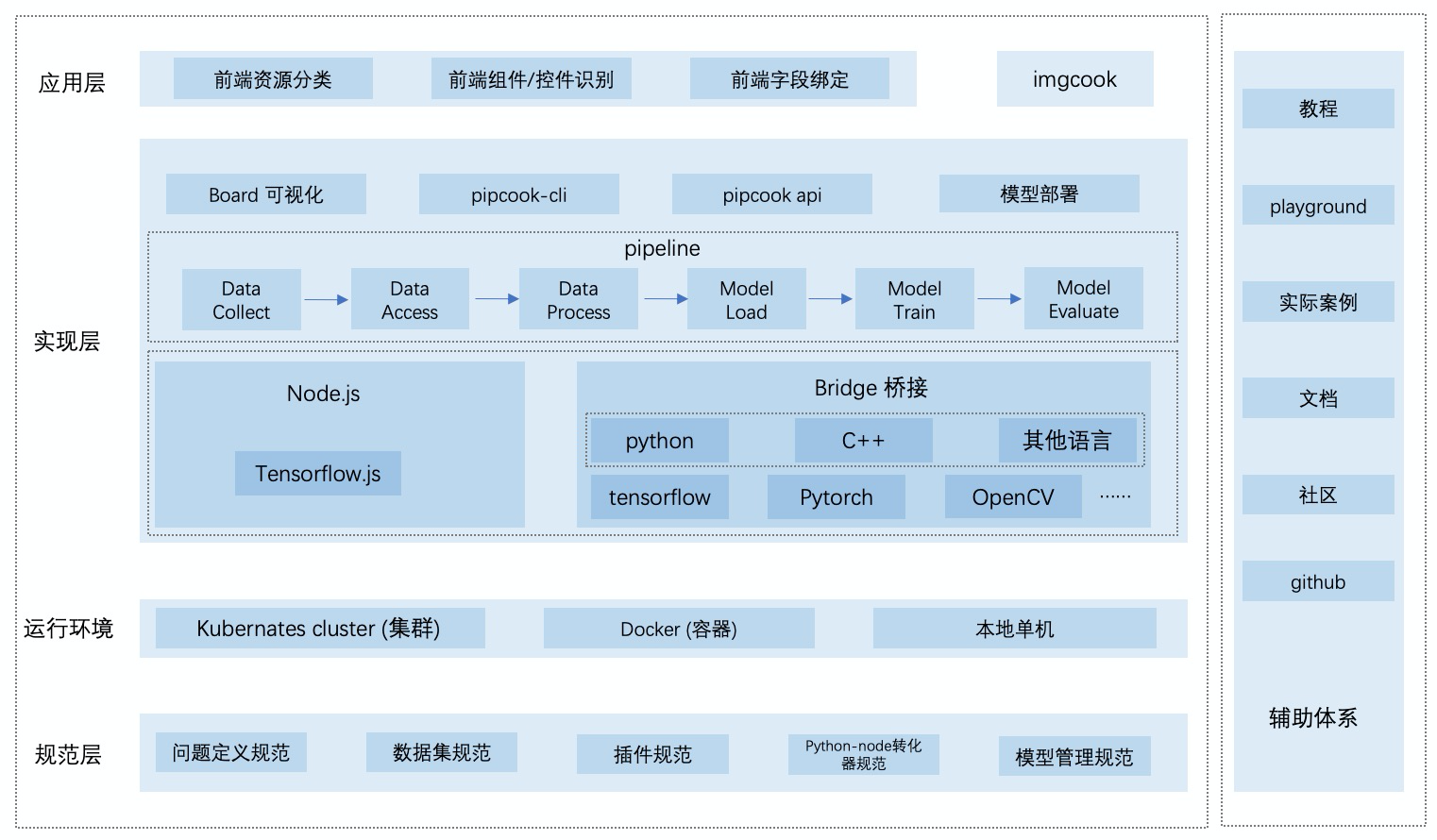
如上图所示,通过对落地场景,算法,数据和语言的问题的回答,我们设计了一套基于管道 (pipeline) 的流式前端机器学习框架,模型和数据流通于这条管道内,在管道中,可以嵌入插件对模型和数据进行某种处理,并继续流往下游。每个插件应该有明确的分工,负责具体的机器学习周期的某一任务。 pipcook 通过一系列规范的定义确保了第三方开发者可以开发插件从而扩展 pipcook 的能力。同时,我们的框架是基于 tfjs 进行机器学习训练的, 我们也可以通过 python 桥接的方式用上 python 生态。下面我们就这个架构中几个重点部分分别介绍
pipeline 和插件
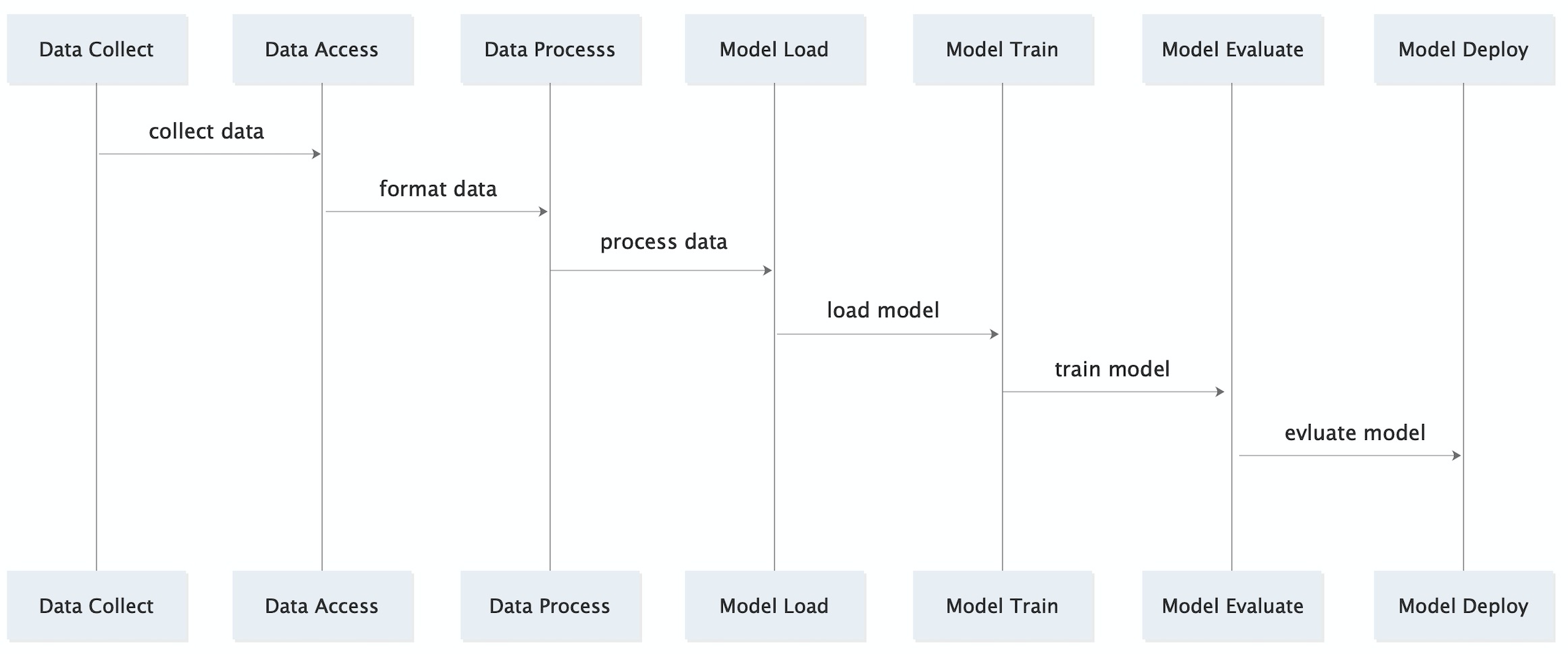
pipcook 是基于管道的框架,包括数据收集、数据接入、数据处理、模型配置、模型训练、模型服务部署、在线训练七个部分, 每个部分由某一具体的插件负责,用插件的方式提供每个环节的定制化能力,用 pipline 串联插件实现算法工程。整个流程基于 Node.js 的技术体系,插件以 NPM 生态进行管理维护,尤其在数据和模型服务部署可以和既有的前端技术体系深度结合。
数据收集、接入和处理
pipcook 定义了一套数据集规范,在数据收集、接入和处理的插件中避免了不同数据集标准带来的接入和使用数据成本,同时,保证数据在不同的 pipline 之间能够共享。这些数据插件背后的协议标准,可以支撑在不同的标注工具下产生标准统一的数据集。数据处理的插件大幅度降低数据集理解优化的难度。
tfjs-node
pipcook 的底层模型和算法能力是由知名机器学习框架 tensorflow 的 node 版本提供的,由于 tfjs-node 的出现,大大提高了 js 这门语言用作机器学习的能力,我们作为基于 js 的机器学习工程平台,也可以很方便的使用 tfjs-node,无论是其官方提供的一些成熟模型 (mobilenet 等),还是通过基本算子去搭建一个新的模型,甚至只使用其 tensor 的能力也可以弥补 js 平台没有一个类似于 numpy 包的劣势。、
未来展望
实际上作为一个全新的基于 js 的机器学习工程平台并且开源不久,pipcook 势必还有很多不完善的地方,基于推动整个前端行业朝着智能化发展的大目标,我们也会不断完善这个平台
模型能力
目前 pipcook 内置的插件支持一条图片分类和目标检测的管道,其中目标检测的管道借用了 python 的能力,未来,本着扩大 js 机器学习生态的原则,我们还是希望可以基于原生的 tfjs-node 进行模型开发,同时,未来,pipcook还会继续支持诸如 nlp 自然语言处理,图片分割等一些热门的深度学习任务做相应的插件支持,当然,我们也欢迎第三方开发者来为我们贡献这些模型
分布式计算
随着数据数量的增大和模型的复杂度增加,可能会带来算力不足的问题,未来我们会增加对模型部署到多个设备上进行训练的能力,支持数据并行,分布式并行和异步训练等工作,支持利用集群解决算力的问题
部署完善
目前,pipcook 还仅支持本地部署等简单的方案,未来,pipcook 将会和各个云服务 (阿里云,AWS,Gcloud等) 合作,直接在流水线中部署到云计算的机器学习部署服务上,从而可以在训练完成之后直接开始进行预测服务。
小结
未来我们希望通过阿里内部前端智能化小组和整个开源社区的力量结合在一起,不断完善 pipcook 和 pipcook 背后所代表的前端智能化战役,让前端智能化技术方案普惠化,沉淀更具竞争力的样本和模型,提供准确度更高、可用度更高的代码智能生成服务;切实提高前端研发效率,减少简单的重复性工作,不加班少加班,一起专注更有挑战性的工作内容!
如何贡献?
如果您对我们的项目有兴趣并且想要为前端智能化贡献一份力量,欢迎您前往我们的 github 开源仓库
