

常见的目标检测算法缺少了定位效果的学习,IoU-Net提出IoU predictor、IoU-guided NMS和Optimization-based bounding box refinement,将IoU作为一个新分支融入到模型的学习和推理中,带来了新的性能优化方法,值得学习和参考
论文: Acquisition of Localization Confidence for Accurate Object Detection

Introduction
目前大部分的目标检测算法主要是two-stage架构,将目标检测转化为多任务的学习:
- 预测foreground object proposals以及label
- 通过bndbox regression对识别的框进行精调
- 通过NMS对冗余的框进行过滤

目标定位和识别是由两个不同的分支进行的,对于一个预测的框,仅有分类置信度,没有定位置信度,这会导致以下两个问题:
- 由于缺失定位置信度,在做NMS时,只能以分类置信度作为指标,从图a可以看出,候选框的IoU与分类的置信度并没有正相关的关系
- 由于缺少定位置信度,bounding box regression变得难以解释,如图b所示,重复进行bounding box regression将可能导致定位精度降低
基于以上的发现,作者提出了IoU-Net,预测当前框的IOU分数作为定位模块的准则,从而从另一个角度解决之前提到的两个问题:
- IoU是定位准确率的最佳标准,做NMS的时候使用预测的IOU而不是分类置信度,文中称为 IoU-guided NMS
- 文中提出optimization-based bounding box refinement procedure的bndbox优化方法。在预测的时候,将预测的IoU作为优化的指标,通过Precise RoI Pooling layer使用梯度上升的方法对框进行回归。实验表明optimization-based的方法要比 regression-based的方法好,optimization-based的方法也能够移植到其它CNN-based的detector
#Delving into object localization
目前的目标定位存在两个问题,一个是分类置信度与定位置信度不一致,一个是非单调性的bounding box regression
Misaligned classification and localization accuracy
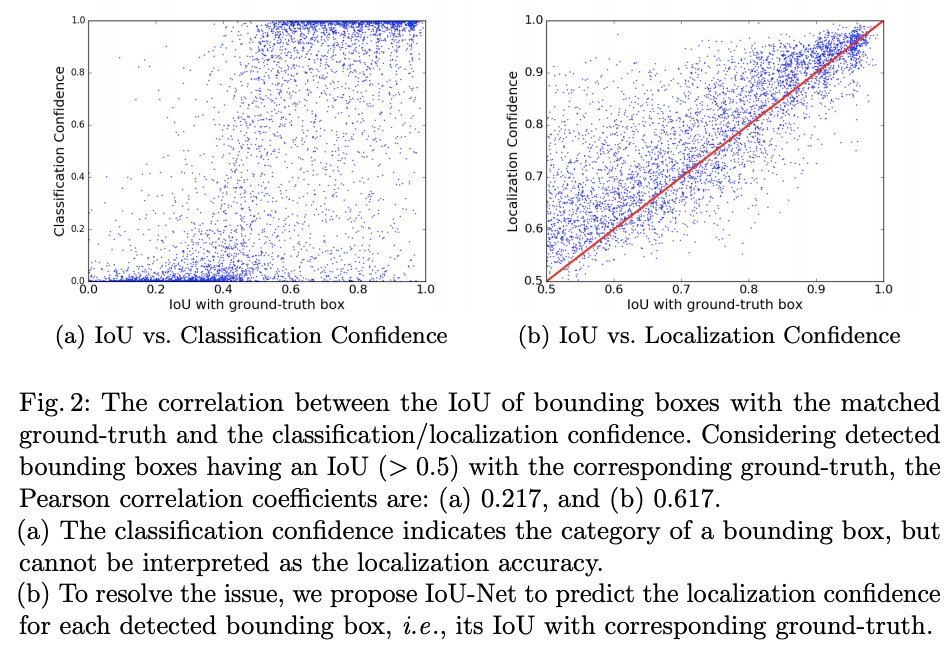
目前的定位方法大都用NMS移除冗余的bndbox,在每轮迭代中,分类置信度较高的bndbox予以保留,这显然是不合理的。近期有很多新的NMS变种出现,但最终仍然采用分类置信度作为标准。文中画出了NMS前的IoU和分类置信度的散点图,从图2可以看出,文中提出的定位置信度与IoU有更强的相关性
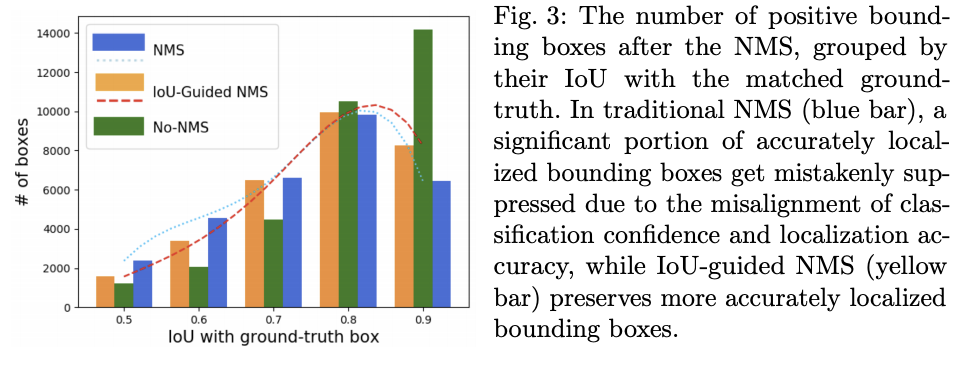
此外,文中对比了IoU-Guided NMS与传统NMS的表现,从图3可以看出,IoU-Guided NMS能保留更多高质量的框,特别是在Iou>0.9的时候
Non-monotonic bounding box regression
bounding box regression task的核心思想是通过网络直接预测bndbox和gt之间的变换,大多数的detector对bndbox进行二次回归来达到优化的目的。Cascade-RCNN指出,连续使用两次以上的bounding box regression将不会带来太大的收益,于是提出了multi-stage bounding box regression
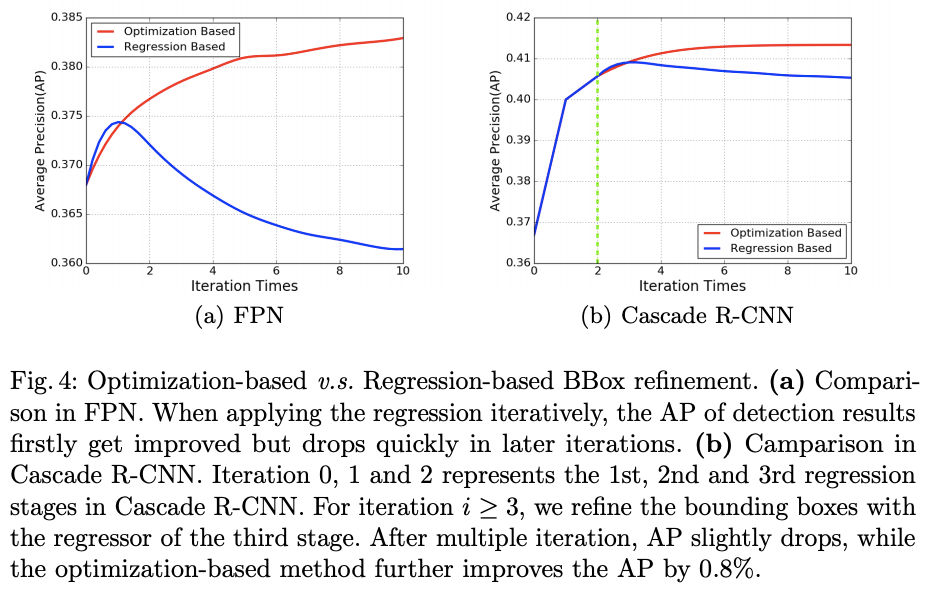
文中的在FPN和Cascade-RCNN框架下对比了多次Regression Based和多次Optimization Based的效果。如图4,随着迭代次数的增加,Optimization Based的AP曲线依然保持着单调性
#IoU-Net
Learning to predict IoU
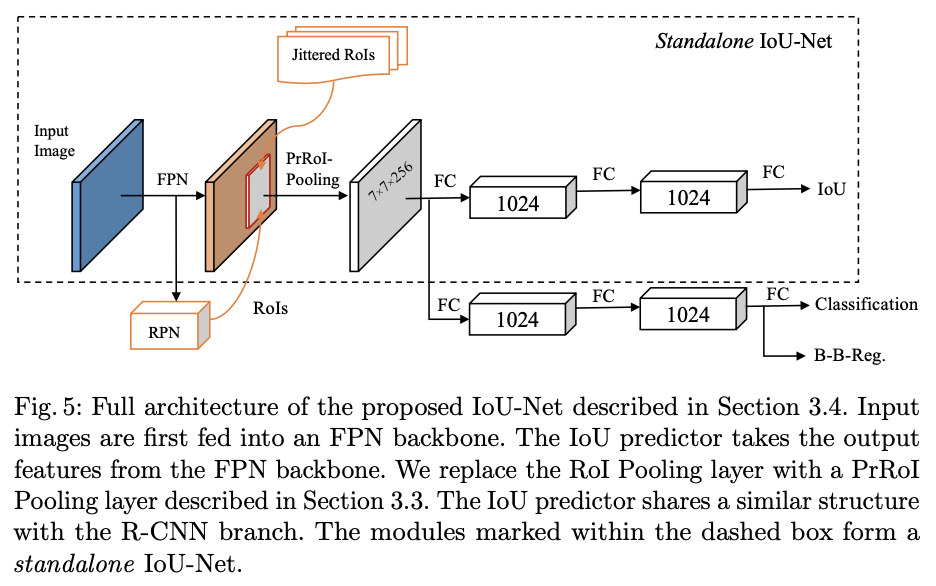
如图5,IoU predictor使用FPN的feature map进行每一个bnbbox的IoU的预测,但不会使用FPN的候选框进行训练,而是人工对GT进行一系列的变换获得新的候选框(去掉与GT重叠小与0.5的候选框)。IoU predictor能与大多数的RoI-based detector兼容,因为该模块是相对独立的。值得注意的是,文中提到为了更好的性能,IoU predictor是class-aware,即能预测出每个分类IoU
IoU-guided NMS
IoU-Net使用预测的IoU来作为NMS中bndbox排序的标准,只保留冗余的box中IoU最高的

文中给出了IoU-guided NMS的伪代码,逻辑比较简单,取出候选框中IoU分数最高的框,在剩余的框中取出与
重叠大于
的框
,将重叠的框中的最大的分类置信度以及
加入到输出中,遍历直到不再有候选框
Bounding box refinement as an optimization procedure
bndbox的精调问题可以公式化地表示为的优化问题
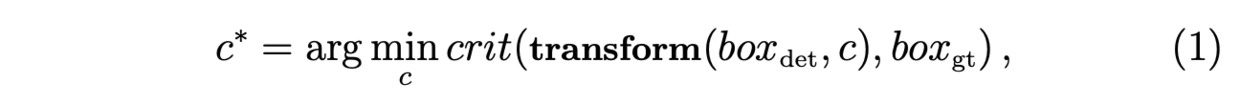
在推理的时候,Regression-based的算法直接预测最优的。然而 iterative bounding box regression是不稳定的,因此,文中提出了 optimization-based bounding box refinement
IoU-Net直接评估预测框与GT之间的IoU,Precise RoI Pooling layer使得IoU的梯度能够回传到box的坐标值上,因此可以利用梯度上升的方法来优化公式1

如算法2,将IoU的预测作为优化的目标,迭代式的用计算出的梯度对预测框进行精调,使预测的IoU值接近1(即GT)。此外,预测的IoU能用于评价中间产生的所有bndbox的优劣
在实现时,对于精调后的bndbox预测的IoU,若收益小于预期,甚至退化了,则提前结束该bndbox的精调。比较有趣的是,如第六行,算法会对回传的梯度进行scale up操作,例如,文中解释为这相当于box regression中对坐标进行log变换 (x/w, y/h,
,
)后再优化
####Precise RoI Pooling
前面提到optimization-based bounding box refinement的关键在于使用了Precise RoI Pooling layer,使得梯度得以回传,文中列出几种主要的Pooling层的比较
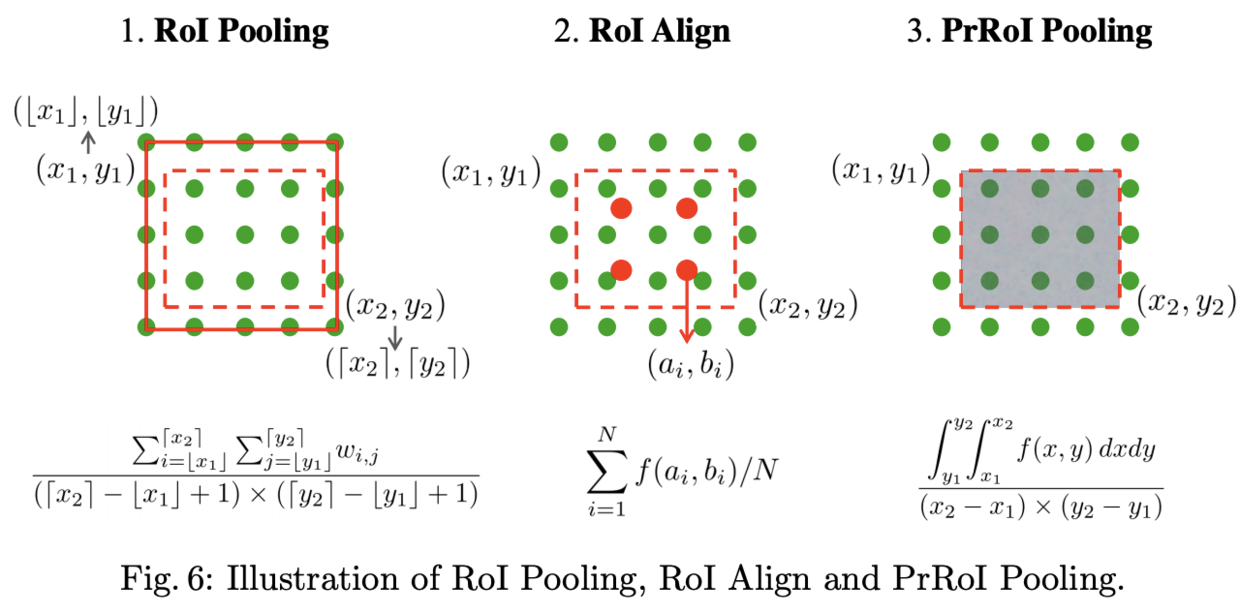
- RoI Pooling
对于经典的RoI Polling,若坐标信息为非整数则需要先进行量化成整数,变成具体的点,再计算bin内的响应值。这样做会导致原来的RoI区域变形,结果不准确
- RoI Align
为了去除量化的影响,RoI Align从bin中采样N=4个点(,
),每个采样点都是用其最近的4个特征点进行双线性插值所得,Pooling在采样点上进行
- PrRoI Pooling
RoI Align虽然避免了量化的误差,但N是预设的超参,不会根据bin的大小进行改变,在梯度回传的时候,只有采样过的点才能回传梯度。Precise RoI Pooling不进行任何的量化和采样,直接计算连续的特征图内的二阶积分
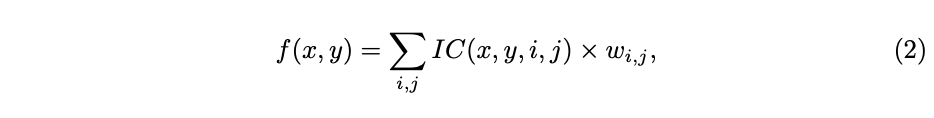
首先定义特征图上的任意的点的特征值可通过附近离散的点双线性插值计算,
是双线性插值的因子,从公式可以看出限定了只使用
的最近四个点
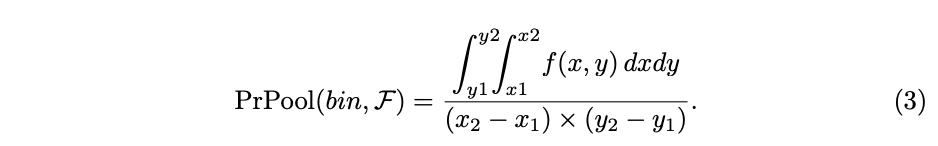
当需要计算bin的pooling时,直接使用二阶积分进行计算,这里应该表达的是avg pooling,分母是bin的面积
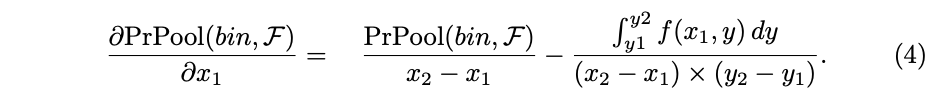
由于二阶积分推理时使用是连续可微的,因此可以求坐标的偏导数进行bndbox的精调,而RoI pooling layer和RoI align layer只能回传feature map的梯度
作者给出了PrPooling layer的代码,用离散的点近似地做连续函数的积分。要注意的是,公式4计算的是bin坐标的偏导数,而不是RoI坐标的偏导数,所以在坐标梯度backward的最后,作者对bin的偏导进行了权重相加到RoI的梯度中。不过这个权重公式的意义笔者还没看懂,了解的小伙伴可以留言交流下
Joint training
IoU predictoe能够整合到标准的FPN网络中进行end-to-end的训练,如图5,IoU-Net使用ResNet-FPN作为主干,FPN提取RoI区域的不同维度特征,将原来的RoI Polling layer替换为Precise RoI Pooling layer,IoU predictor与R-CNN分支并行计算
- 在训练时,使用ImageNet预训练的ResNet,其余的新层均使用0均值,标准差为0.01或0.001的高斯分布,IoU predictor使用smooth-L1进行训练。图片输入为短边800/长边1200,分类与回归分支获取每张图的512个bndbox,batch_size为16,总共进行160k次迭代,学习率初始为0.01,每120次迭代降低10倍,前10k轮以0.004的学习率进行warm up,weight decay为
,momentum为0.9
- 在推理时,先进行一轮bounding box regression作为坐标初始化,为了优化性能,第一次对所欲的bndbox进行IoU-guided NMS,挑选100个置信度最高的bndbox进行optimization-based algorithm,算法2中的
,
,
,
Experiments
IoU-guided NMS
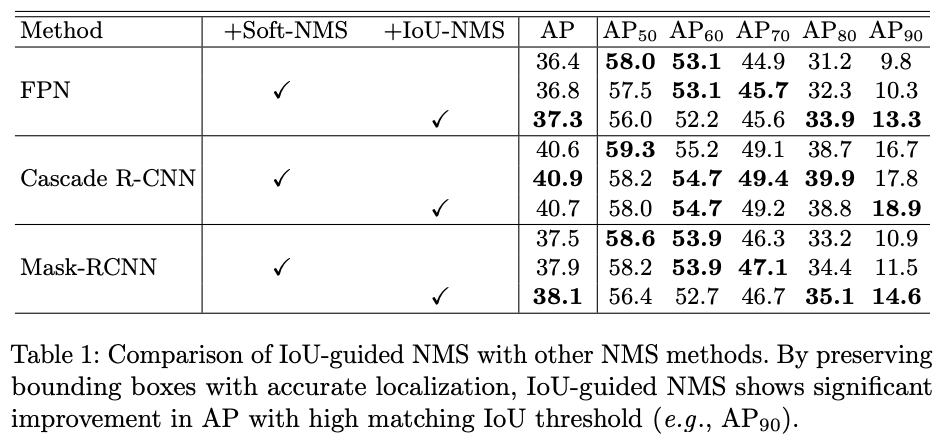
论文对比了无NMS/Soft-NMS/IoU-NMS在不同网络以及不同AP要求下的表现,在高AP,特别是上,表现较为突出
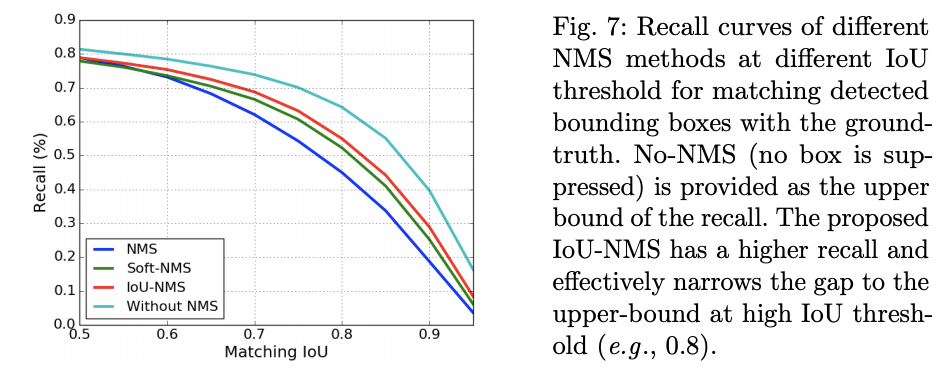
论文统计了不同IoU阈值下的recall,进一步说明IoU-NMS能保留更多优质的框
Optimization-based bounding box refinement
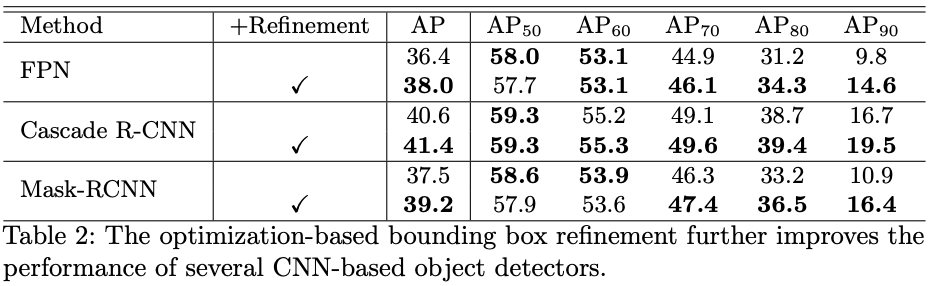
在不同的网络上,Optimization-based bounding box refinement均有较不错的表现,在
上的表现尤为明显
Joint training
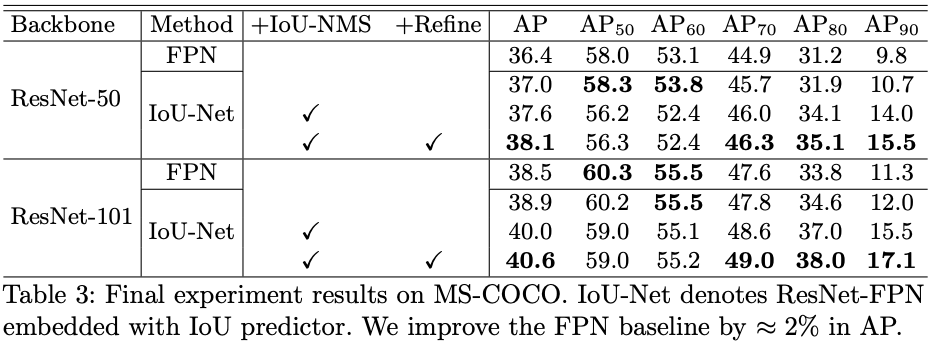
论文通过不同的组合实验,得出文中提出的创新点均有不错的效果

另外,比较意外的是,IoU-Net的速度并没有下降很多,甚至比Cascade R-CNN还要快,这可能得益于bndbox在进行Optimization-based bounding box refinement前筛剩100个
Conclusion
论文分析了当前的目标检测算法存在的问题,并提出IoU predictor来预测定位置信度,从而进行更准确的bndbox精调以及NMS。另外,论文提出的 IoU-guided NMS和Optimization-based bounding box refinement从实验看来,效果也是相当不错的,而且IoU分支可以很方便地集成到别的网络中,这是相当重要的
写作不易,未经允许不得转载~ 更多内容请关注 知乎专栏/微信公众号【晓飞的算法工程笔记】

