

导语:Apache Kafka凭借其高吞吐、高可靠等特性在实时数据或流式数据架构中扮演着重要角色,受到了众多企业用户的青睐。但是随着云时代来临,公有云厂商纷纷推出消息队列服务,很多用户也逐渐从自建消息集群过渡到使用云上消息队列服务。本文将以蘑菇街Kafka服务迁移上云为例,阐述腾讯云消息队列CKafka如何对用户产生价值。 (编辑:中间件小Q妹)
Apache Kafka 简介
Apache Kafka官网用这样一句话描述最新版本的Kafka:A distributed streaming platform。即分布式流式计算平台,并对其做了如下阐述:
Kafka® is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
译文:Kafka®用于构建实时数据管道和流式应用程序。它具有水平可伸缩性、容错性、超快速性,可在数千家公司中投入生产。
升级到2.0+的Kafka给自身加了一层定义,即流计算平台。但是在企业级使用场景下,Kafka还是被经常当作数据管道来使用,履行消息队列的基本职能。其典型的使用场景如下:
- 数据管道和系统解耦。
- 异步处理和事件驱动。
- 流量削峰。
- 事务消息和分布式事务的最终一致性。
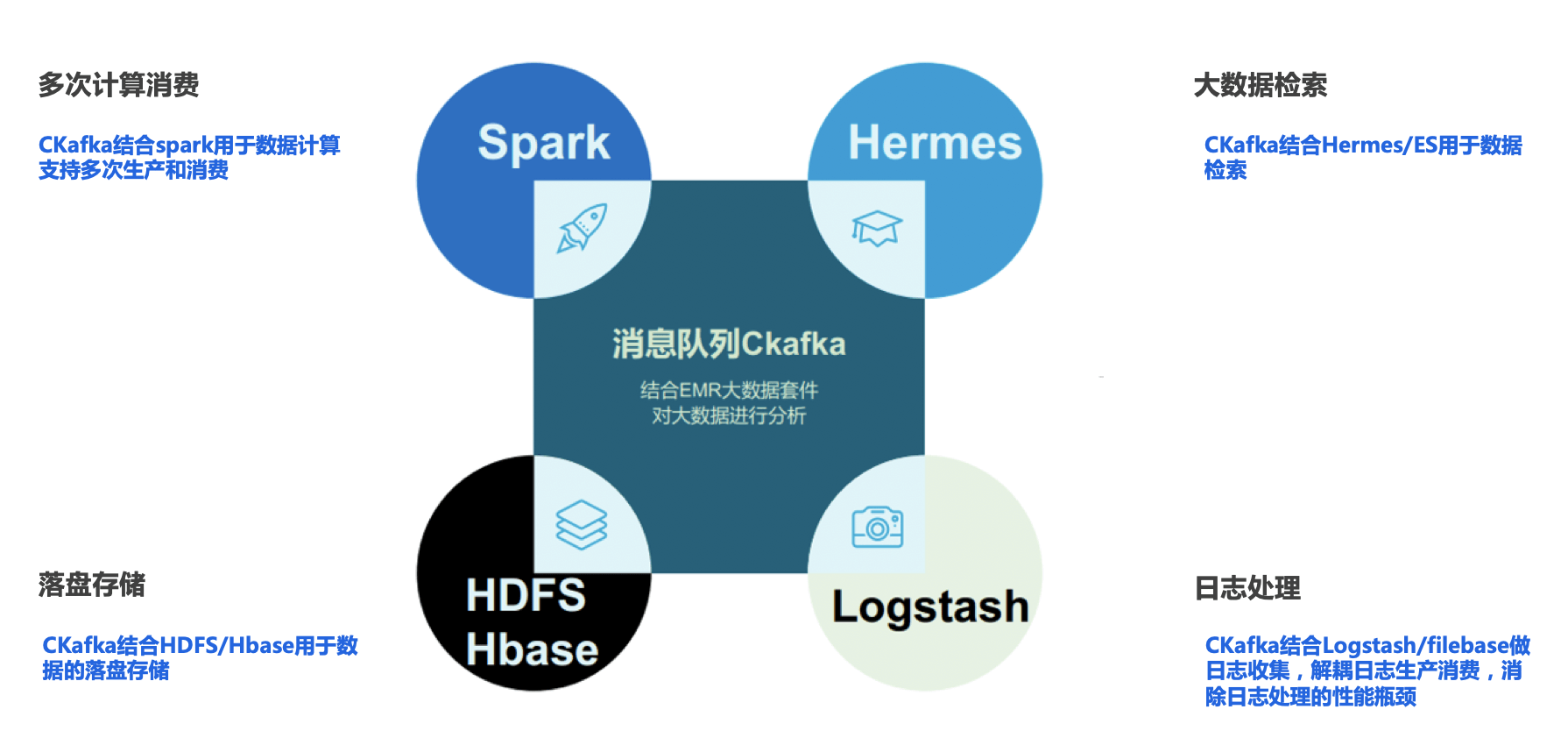
自建Kafka集群的痛点
由于Kafka的搭建方式简单方便,且其性能高效稳定,很多企业用户选择自建Kafka集群。但这样看似完美的可行方案背后却有一个隐型风险:当业务的消息数据量到达一定程度后,自建的消息队列集群就会引发各种各样的问题,那么如何解决问题呢?
我们都知道Kafka入门简单,进阶却有一定的门槛。解决问题的研发人员需要具备扎实的计算机功底(熟悉计算机网络、IO等),并且对Kafka的底层原理、各种配置参数项等具有深刻理解,可以进行Kafka集群参数调优,快速处理突发故障、恢复集群抖动和动态进行集群扩缩容等。正因如此,引发了一些问题:企业一方面需要投入更多的人力、物力成本,另一方面需要时刻监控集群的健康状况,及时排除问题以保障业务的稳定运行。所以自建Kafka集群虽然简单,但需要承担日益加重的研发和运维成本。
蘑菇街上云背景
蘑菇街的业务场景和软件架构决定了它对Kafka有着强大的依赖,作为电商领域的佼佼者,其消息总量达到了日均千亿条,生产峰值带宽达每秒GB级别。其主要的业务场景为分布式大数据处理场景,如广告、交易、安全、离线处理等。
在意识到自建Kafka集群的痛点后,为了保证数据的安全性和集群的稳定性,蘑菇街选择使用云上消息队列服务CKafka。CKafka不仅支持多可用区容灾,还可以帮助客户实现冷热数据分离,解决频繁读取磁盘IO瓶颈,为业务的稳定运行提供良好的保障。接下来我们来分析阐述CKafka是如何做到可用区容灾和高性能的集群服务器IO。
集群跨可用区容灾方案
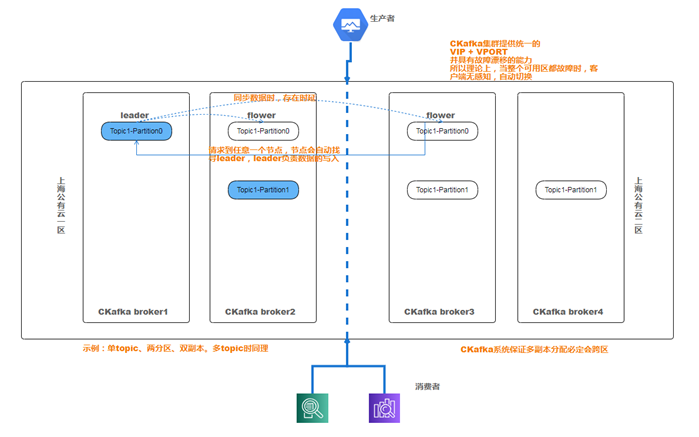
在Kafka消息系统中,客户端感知服务端最核心的操作就是生产和消费。跨可用区容灾的目标是:当一个可用区发生故障(如火灾,断电等)时,能够做到客户端无感知的进行生产和消费,保证业务的稳定运行。而满足可用区容灾需要在技术层面解决如下问题(以上面示意图为例):
- 分区副本的跨可用区分布,即保证每个分区的副本分布在不同可用区。比如,当集群跨上海二区和四区两个可用区时,分区有四个副本,则需要保证每个可用区都分布两个副本;
- Kafka强依赖Apache Zookeeper,当Zookeeper不能正常提供服务时,Kafka集群也会受到影响,故实现kafka的跨区容灾,也要实现zookeeper的跨区容灾。Apache Zookeeper和Kafka 一样,具有跨区容灾的能力。
- Broker节点的IP对客户端需要透明化。即客户端不能感知Broker的地址。这样当后端Borker故障,切换机器IP发生改变时,客户端无感知,依然可以正常运行。
解决上述问题需要下面4个技术方案。
透明可漂移的Broker节点IP
为什么Broker的节点IP和端口需要对用户端透明呢?我们先来看如下一段代码:
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.10.10:9092,192.168.10.11:9092,192.168.10.12:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i),
Integer.toString(i)));
producer.close();
这是一段最简单的Kafka Produce代码。192.168.10.10:9092、192.168.10.11:9092、192.168.10.12:9092是三台真实Kafka Broker 的IP和端口获取Server端Metadata信息,开始进行生产消息操作。我们来设想一下如下的情况:
当其中一台192.168.10.10机器故障无法恢复时,我们重新启动了另外一台Borker,比如192.168.10.13:9092提供服务。此时就需要通知所有客户端,将Kafka地址从: "192.168.10.10:9092,192.168.10.11:9092,192.168.10.12:9092" 修改为 "192.168.10.13:9092,192.168.10.11:9092,192.168.10.12:9092"。若IP配置硬编码到客户端代码中,则需要修改代码,然后打包并发布。**由于服务端调整而导致客户端修改配置、重启,这简直是灾难!**那要怎么解决这个问题呢?
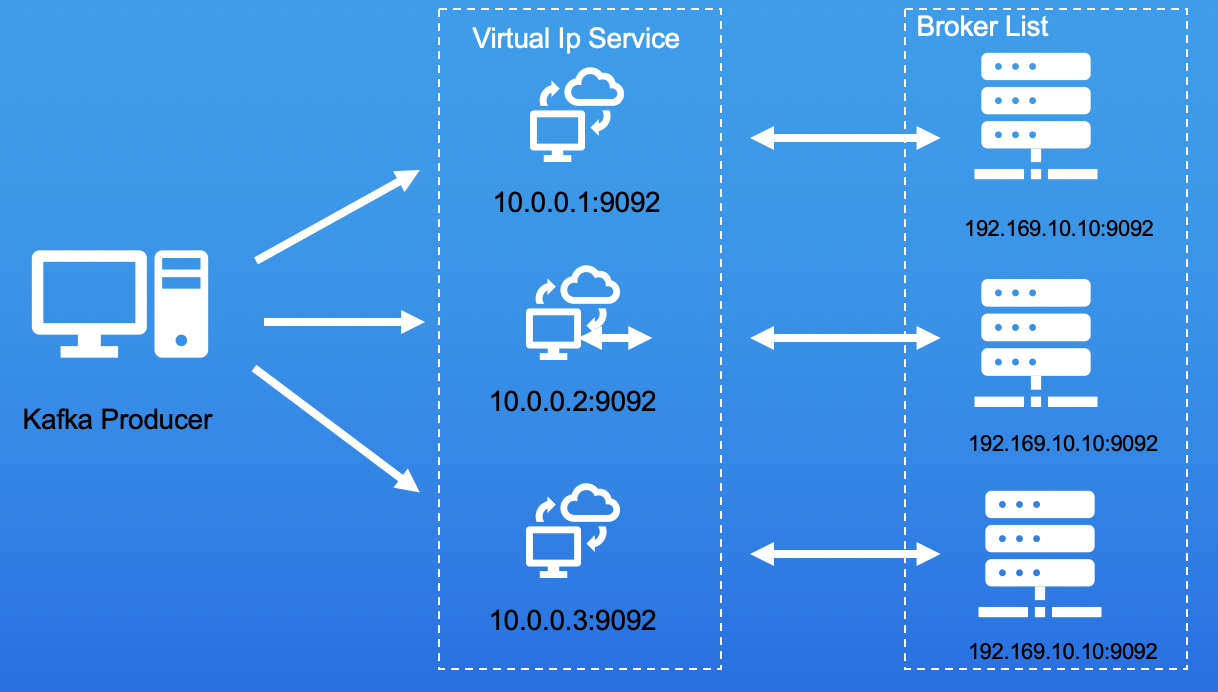
解决问题的思路就是: Virtual IP Address。如下图所示,我们会在每台提供的Broker之前挂载一个四层的Virtual IP(VIP)和Virtual Port(VPORT),用户通过访问VIP和VPORT来访问实际的Broker服务。如10.0.0.1:9092对应的是真正的Broker服务192.169.10.10.9092。这样就达到了实际Broker IP对用户透明化的目的。
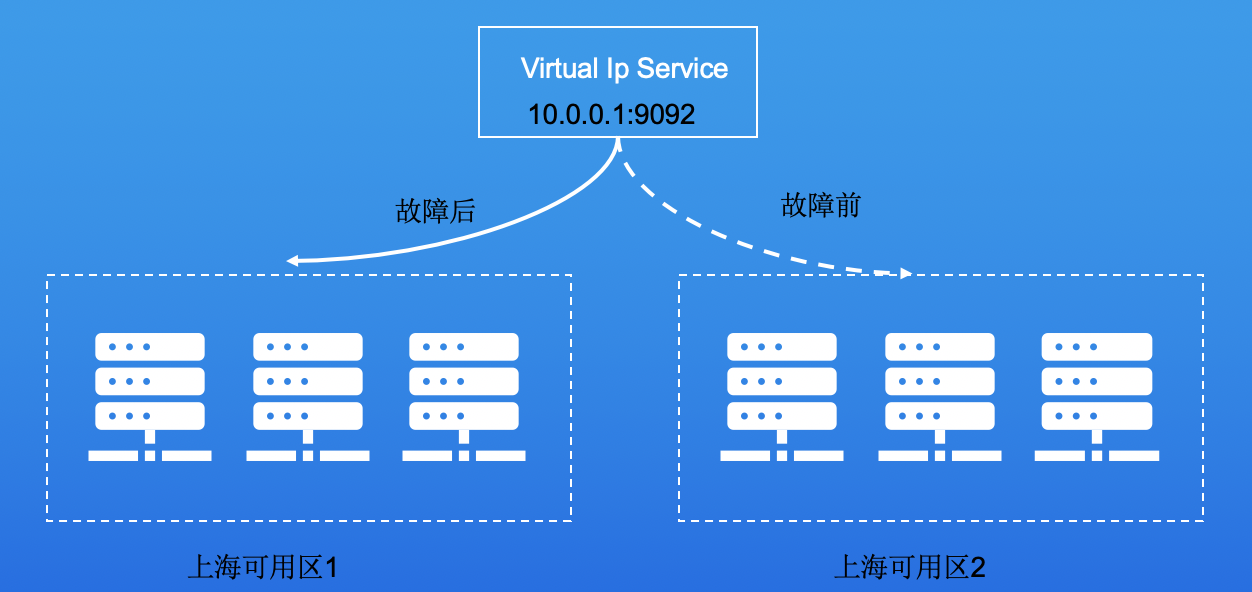
那什么是漂移呢?服务需要做到跨可用区容灾。即我们提供的Virtual IP Address能够在可用区之间进行切换的,当该可用区故障,该VIP可以迅速切换漂移至另一个可用区,继续提供服务。那么该VIP应该是可以访问所有可用区的。如下图,当上海可用区2发生故障后,Virtual Ip Service迅速自动切换到上海可用区1可用的broker实例,保证客户端的正常使用。
分区副本的跨区分布
原生的Kafka按照同一个可用区的副本不能分配在同一台机器上的原则,进行副本随机分配。副本分布逻辑是无感知可用区。即当集群里面哪台broker有空闲的空间,就将副本分布在Broker上。则有可能将同一个partiton的分区分布在同一个分区。
如上面的跨可用区Virual IP切换示意图所示,当创建一个3个Replication(副本)的Partition时,很有可能该Partition的Replication都落在了上海可用区2。如果此时上海可用区2发生故障,那么该Partition就不能正常提供服务,直接影响业务。怎么解决这个问题呢?
CKafka会在broker上添加可用区标记,当发现客户创建的主题是跨可用区主题时,会将同一个分区的副本分配在多个可用区,保证一个可用区故障时分区仍然有存活的副本。通过修改Kafka源码的分区分配逻辑,添加了可用区标记逻辑,根据需求将不同的Replicatiton分配到不同的Broker上。而这些Broker则属于不同的可用区。实现原理如下:
首先来看一下Zookeeper上的节点/broker/topics/test-topic的内容,内容如下:
{"version":1,"partitions":{"0":[10840,10839],"1":[10838,10840],"2":[10839,10838]}}
这段内容意思是:test-topic这个主题有0、1、2三个分区,0分区分布在broker[10840,10839]上,1分区分布在broker[10838,10840],依次类推。所以,只需要修改该内容的生成逻辑就可以控制Partiton的分布,即可实现该逻辑。
Zookeeper的跨区部署
被Kafka强依赖的Zookeeper组件,它也需要跨区部署保证其可用性。首先来看一下Zookeeper的选举策略:半数以上的节点都同意后才能当选leader,如果是偶数节点可能导致票数相同的情况,会使leader选取失败,最终导致集群失效。另外当Zookeeper集群故障节点数超过半数时,Zookeeper集群将无法正常工作。
由Zookeeper分布式一致性算法的特点,可以得出一个结论:假如每个zone部署一个zk节点,zk要支持n区容灾(同时挂掉n个区的zk节点),需要部署2n+1个分区才能保证Zookeeper的分区可用。即在n=1的情况下,需要部署3个可用区,才能保证zookeeper集群的单可用区可用。
Broker配置优化
根据设计方案,在不同的可用区部署Broker时,需要调整一些参数。这些参数保证了服务跨区容灾的最大可用性。需要修改如下三个配置:
unclean.leader.election.enable=true
min.insync.replicas=1
offsets.topic.replication.factor=3
这三个配置什么意思呢? 依次来看一下:
unclean.leader.election.enable
官方描述: Indicates whether to enable replicas not in the ISR set to be selected as leader as a last resort, even though doing so may result in data loss。
解释:该字段默认值为False。默认情况下leader不能从非ISR的副本列表里选择;因为在非ISR副本列表里选择leader,很有可能会导致部分数据丢失。既然这样,那为什么还要打开这个字段呢?因为在很异常情况下,比如ISR内的副本都不可用了,此时如果该字段设置为False,服务会直接挂掉;如果该字段设为True,即允许从非ISR列表中选择leader,那么服务尽管有可能丢失数据,却依然可以继续使用。所以这个参数必须参考业务特性来决定是否打开。
min.insync.replicas
官方描述: When a producer sets acks to "all" (or "-1"), min.insync.replicas specifies the minimum number of replicas that must acknowledge a write for the write to be considered successful。
解释:该字段默认值为1。上述英文翻译为:表示当在acks=-1时,最少有一个Replica进行确认回执,才确认数据写入成功。这个参数在集群搭建时,为了保证数据的完整性,经常会被改为2。这里改为1的原因是:在只有一个副本在工作 、其他都挂掉的极端情况下,保证客户端能够正常提供服务。如果设置为2,当只有一个副本在工作的时候,就会出现生产端一直生产失败的情况,会影响业务。
offsets.topic.replication.factor
官网描述: The replication factor for the offsets topic (set higher to ensure availability). Internal topic creation will fail until the cluster size meets this replication factor requirement.
解释:该值默认为1。表示kafka的内部topic consumer_offsets副本数。当该副本所在的broker宕机,consumer_offsets只有一份副本,该分区宕机。使用该分区存储消费分组offset位置的消费者均会收到影响,offset无法提交,从而导致生产者可以发送消息但消费者不可用。所以需要设置该字段的值大于1。
集群IO压力优化方案
自建消息集群的用户常常会遇到一个问题:在流量峰值时,集群IO压力很大,用户只能通过扩容来暂时解决问题。但这毕竟是权宜之计,为了帮助用户真正解决该问题,腾讯云CKafka团队对客户服务器端的各项指标及业务场景进行了深入分析。我们发现集群的IO压力占比最大的是磁盘读压力。但是为什么磁盘读压力大呢?我们首先来看一下Kafka底层的磁盘存储设计原理。
Kafka磁盘存储设计原理
Kafka的磁盘存储设计可以用三个词来概括:磁盘顺序读写、Page Cache和零拷贝。
- 磁盘顺序读写:即Kafka数据的写入和读取是顺序的。而根据局部性原理,在实际测试中,磁盘顺序写入和随机写入的性能比相差最大可达6000倍。
- Page Cache:它是Kafka能够实现顺序读写的关键技术。另外,它也是操作系统主要实现的一种磁盘缓存,用来减少磁盘的 I/O 操作。具体做法是把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。Page Cache中的数据会按照一定的策略更新到磁盘。
- 零拷贝:将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手。这样做大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换。对 Linux 操作系统而言,零拷贝技术依赖于底层的 sendfile() 方法实现。对于 Java 语言,FileChannal.transferTo() 方法的底层实现也是 sendfile() 方法
为什么服务器读压力大?
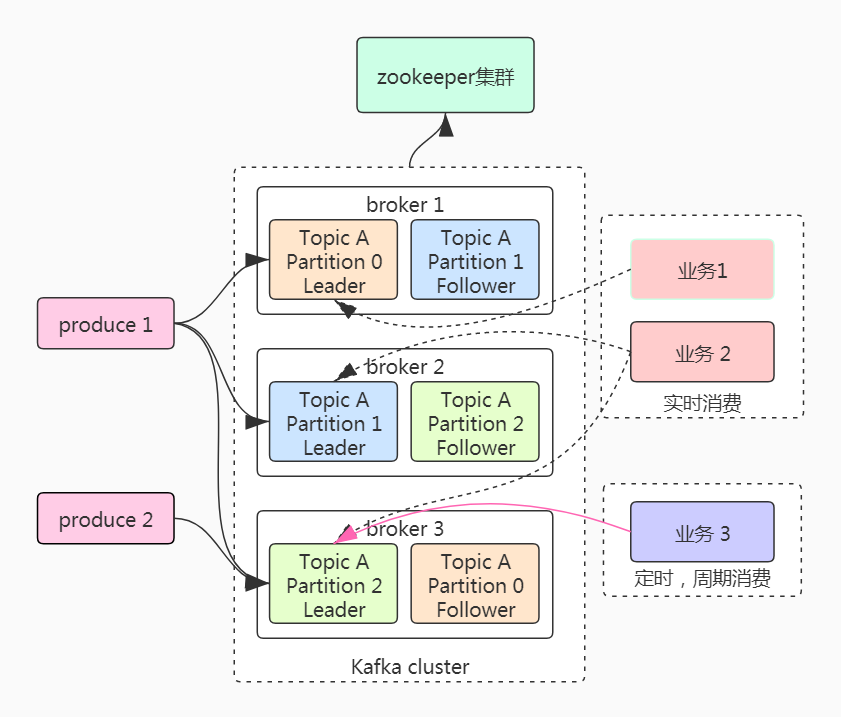
从上面的存储原理图来分析:理论上集群的读压力不应该这么大,因为大部分的读压力应该命中Page Cache,不应该再从磁盘里面读取。然而实际情况中确实存在大量的磁盘读取行为。经过分析,客户存在多个业务消费同一份消息的业务场景,根据消费的实时性可以将消息消费者行为划分两类:实时消费者和离线消费者。
- 实时消费者:对数据实时性要求较高,需要采用实时消费消息的方式。在实时消费的场景下,Kafka会利用系统的page cache缓存,生产消息到broker,然后直接从内存转发给实时消费者,磁盘压力为零。通常称上述操作为热读,常见的业务场景有广告、推荐等。
- 离线消费者:又名定时周期性消费者,消费的消息通常是数分钟前或是数小时前的消息。而这类消息通常存储在磁盘中,消费时会触发磁盘的IO操作。通常称其为冷读,适合报表计算、批量计算等周期性执行的业务场景。
在消息量非常大的情况下,实时和离线消费者同时消费一个集群,会导致两个问题:
-
实时消费者受到离线消费者影响:由于离线消费者消费,导致落盘数据和实时数据会频繁的换入换出内存,直接影响实时业务的实时性,增加实时业务的响应时延;
-
离线数据会导致繁重的磁盘IO操作:当离线任务读取的数据量非常大时,会触发磁盘的高IO,磁盘的IO util 甚至达到100%,影响集群的稳定性。
优化之道:冷热数据分离方案
针对用户集群中存在的数据冷读和热读并存问题,我们认为将集群的数据进行冷热数据分离是当前较优的解决方案。而在不改变生产端行为的情况下,怎么对冷热数据进行分离呢?腾讯云CKafka推出了基于开源Kafka Connector的数据同步服务来解决上述问题。架构图如下图所示:
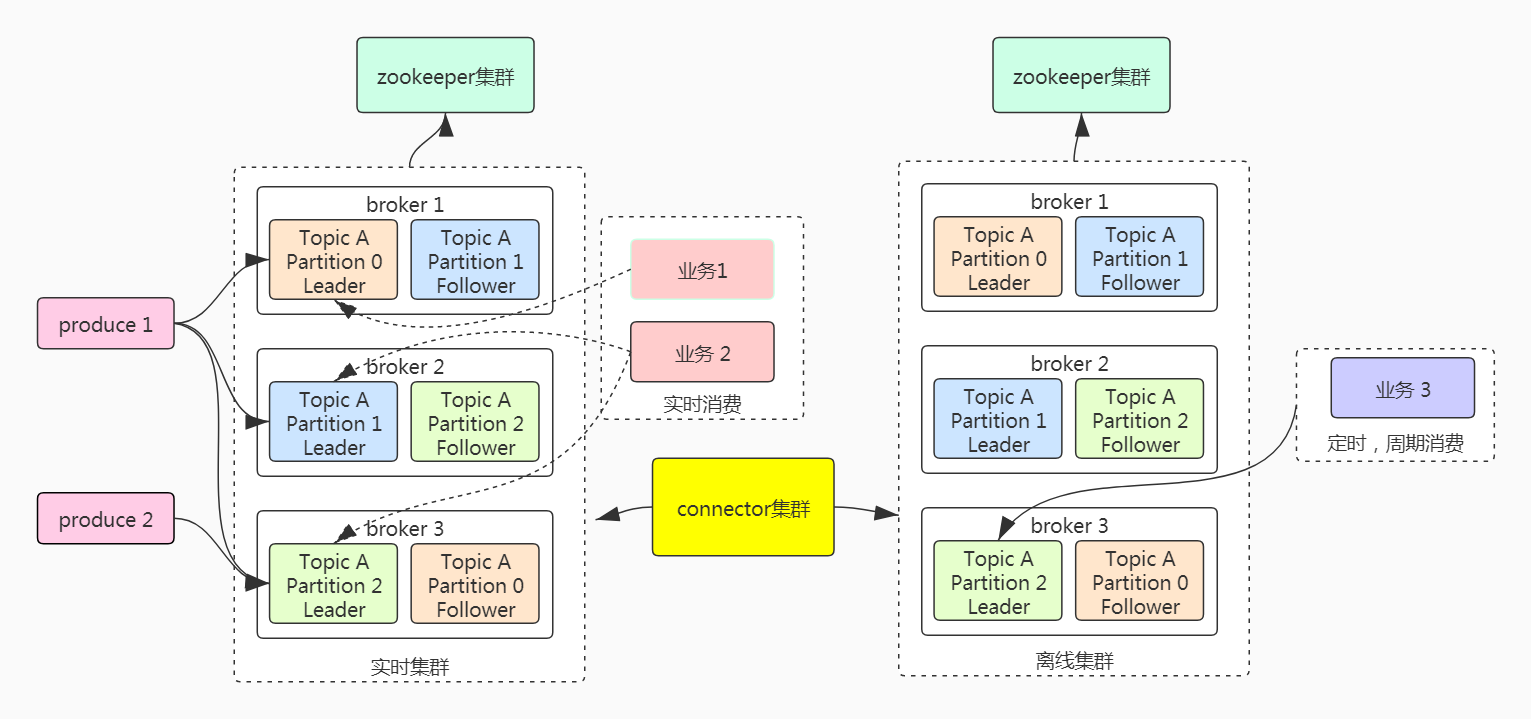
broker集群被拆分为实时集群和离线集群。两个集群分别负责同时引导离线业务消费离线集群。CKafka 在两个集群中间添加了connector集群。connector集群将离线业务订阅的消息(按照主题维度同步)从实时集群同步到离线集群中,connector集群实时进行数据同步,和实时消费者保持一致。这样操作不仅对磁盘IO没有影响,也不会对其他的实时消费者造成影响。
CKafka对业务的价值
CKafka提供高吞吐性能、高可扩展性的消息队列服务。在性能、扩展性、业务安全保障、运维等方面具有超强优势,让用户在享受低成本、超强功能的同时,免除繁琐运维工作。
欢迎扫码关注我们的微信公众号,期待与你相遇~

