

来源:www.cyningsun.com/01-12-2020/…
源代码:github.com/cyningsun/g…
目录
了解一门语言的高级特性,仅仅从浮于表面,是无法把握住语言的精髓的。学习过 C++ 的高阶开发者,一定读过神书《Inside The C++ Object Model》,本文的目标是一样的:通过对象模型,掌握 Go 语言的底层机制,从更深层次解释语言特性。
编译与执行
众所周知,Go 源码并不能直接运行,所有代码必须一行行,通过“编译”——“汇编”——“链接” 阶段 转化为低级的机器语言指令,即可执行程序。

“汇编”和“链接”阶段各种语言并无区别,所以一般通过“编译”和“执行”阶段来支持各种语言特性。对于 Go 语言,执行过程并无法直接修改执行指令,因此所有语言特性都是“编译”相关的。理解这一点很重要,因为下面依赖“编译”的产物 汇编代码 来解读对象模型。
什么是对象模型?
何为 Go 对象模型? Go 对象模型可以概括为以下两部分:
-
支持面向对象程序设计的部分
- 封装
- 继承
- 多态
-
各种特性的底层实现机制
- 反射
下面分别从 struct 和 interface 来解释模型如何支持以上两部分。
Struct 语意学
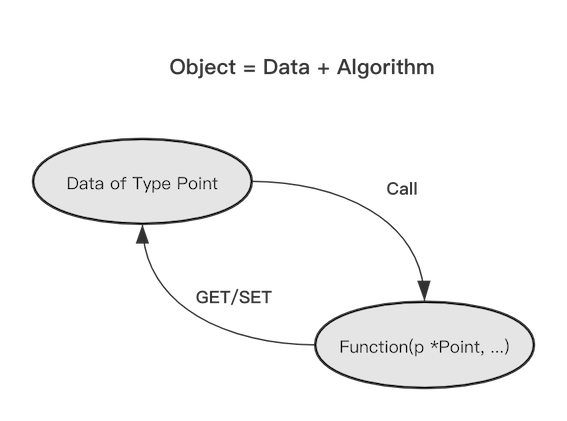
面向对象编程,把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数,前者为成员变量,后者为成员函数。所以研究对象需要分别从成员变量和成员函数入手。
成员变量
以下有三段程序:
// First: global varible
var (
X,Y,Z float32
)
// Second: simple type
type point3d struct {
X, Y, Z float32
}
// Third: inherit type
type point struct {
X float32
}
type point2d struct {
point
Y float32
}
type point3d struct {
point2d
Z float32
}
从风格来看,三段程序截然不同。有许多令人信服的讨论告诉我们,为什么“数据封装”(Second & Third)要比使用“全局变量”好。但,从程序员的角度看,会有几个疑问:
- “数据封装” 之后,内存成本增加了多少?
- “数据封装” 之后,在执行过程中,变量的存储效率是否降低了?
内存布局
先看内存变化。了解内存变化最好的办法就是通过代码打印对象的内存大小,先看全局变量大小
var (
X, Y, Z float32
)
func main() {
fmt.Printf("X size:%v, Y size:%v, Z size:%v\n", unsafe.Sizeof(X), unsafe.Sizeof(Y), unsafe.Sizeof(Z))
fmt.Printf("X addr:%v, Y addr:%v, Z addr:%v\n", &X, &Y, &Z)
}
执行程序输出为:
$ go run variable.go
X size:4, Y size:4, Z size:4
X addr:0x118ee88, Y addr:0x118ee8c, Z addr:0x118ee90
可以看到,X、Y、Z三个字段大小均为4字节,且三个字段内存地址顺序排列。
再看第二段代码的输出
func TestLayout(t *testing.T) {
p := point3d{X: 1, Y: 2, Z: 3}
fmt.Printf("point3d size:%v, align:%v\n", unsafe.Sizeof(p), unsafe.Alignof(p))
typ := reflect.TypeOf(p)
fmt.Printf("Struct:%v is %d bytes long\n", typ.Name(), typ.Size())
fmt.Printf("X at offset %v, size=%d\n", unsafe.Offsetof(p.X), unsafe.Sizeof(p.X))
fmt.Printf("Y at offset %v, size=%d\n", unsafe.Offsetof(p.Y), unsafe.Sizeof(p.Y))
fmt.Printf("Z at offset %v, size=%d\n", unsafe.Offsetof(p.Z), unsafe.Sizeof(p.Z))
}
执行程序输出为:
$ go test -v -run TestLayout
=== RUN TestLayout
point3d size:12, align:4
Struct:point3d is 12 bytes long
X at offset 0, size=4
Y at offset 4, size=4
Z at offset 8, size=4
可以看到,X、Y、Z三个字段大小一样为4字节,内存排列也与上一个版本一样。
继续,第三段代码
func TestLayout(t *testing.T) {
p := point3d{point2d: point2d{point: point{X: 1}, Y: 2}, Z: 3}
fmt.Printf("point3d size:%v, align:%v\n", unsafe.Sizeof(p), unsafe.Alignof(p))
typ := reflect.TypeOf(p)
fmt.Printf("Struct:%v is %d bytes long\n", typ.Name(), typ.Size())
fmt.Printf("X at offset %v, size=%d\n", unsafe.Offsetof(p.X), unsafe.Sizeof(p.X))
fmt.Printf("Y at offset %v, size=%d\n", unsafe.Offsetof(p.Y), unsafe.Sizeof(p.Y))
fmt.Printf("Z at offset %v, size=%d\n", unsafe.Offsetof(p.Z), unsafe.Sizeof(p.Z))
}
执行程序输出为:
$ go test -v -run TestLayout
=== RUN TestLayout
point3d size:12, align:4
Struct:point3d is 12 bytes long
X at offset 0, size=4
Y at offset 4, size=4
Z at offset 8, size=4
可以看到,X、Y、Z三个字段大小一样为4字节,内存排列也与之前两个版本一样。
综上所述,我们可以看到,无论是否封装,还是多深的继承层次,对成员变量的内存布局都并无影响,均按照字段定义的顺序排列(不考虑内存对齐的情况)。即内存布局类似如下:

变量存取
成员变量有两种读取方式,既可以通过对象读取,也可以通过对象的指针读取。两种读取方式与直接变量读取会有什么不同么?使用一段代码再看下:
type point struct {
X float32
}
type point2d struct {
point
Y float32
}
type point3d struct {
point2d
Z float32
}
func main() {
var (
w float32
)
point := point3d{point2d: point2d{point: point{X: 1}, Y: 2}, Z: 3} // L25
p := &point // L26
w = point.Y // L27
fmt.Printf("w:%f\n", w)
w = p.Y // L29
fmt.Printf("w:%f\n", w)
}
还记得之前提过的“编译”阶段么?我们使用 go tool 可以查看源代码汇编之后的代码
data_access.go:25 0x10948d8 f30f11442444 MOVSS X0, 0x44(SP)
data_access.go:25 0x10948de f30f11442448 MOVSS X0, 0x48(SP)
data_access.go:25 0x10948e4 f30f1144244c MOVSS X0, 0x4c(SP)
data_access.go:25 0x10948ea f30f10055ab50400 MOVSS $f32.3f800000(SB), X0
data_access.go:25 0x10948f2 f30f11442444 MOVSS X0, 0x44(SP)
data_access.go:25 0x10948f8 f30f100550b50400 MOVSS $f32.40000000(SB), X0
data_access.go:25 0x1094900 f30f11442448 MOVSS X0, 0x48(SP)
data_access.go:25 0x1094906 f30f100546b50400 MOVSS $f32.40400000(SB), X0
data_access.go:25 0x109490e f30f1144244c MOVSS X0, 0x4c(SP)
data_access.go:26 0x1094914 488d442444 LEAQ 0x44(SP), AX
data_access.go:26 0x1094919 4889442450 MOVQ AX, 0x50(SP)
data_access.go:27 0x109491e f30f10442448 MOVSS 0x48(SP), X0 // 读取 Y 到寄存器 X0
data_access.go:27 0x1094924 f30f11442440 MOVSS X0, 0x40(SP) // 赋值 寄存器 X0 给 w
...
data_access.go:29 0x10949c7 488b442450 MOVQ 0x50(SP), AX // 读取 对象地址 到寄存器 AX
data_access.go:29 0x10949cc 8400 TESTB AL, 0(AX)
data_access.go:29 0x10949ce f30f104004 MOVSS 0x4(AX), X0 // 从对象起始地址偏移4字节读取数据到寄存器 X0
data_access.go:29 0x10949d3 f30f11442440 MOVSS X0, 0x40(SP) // 赋值 寄存器 X0 给 w
可以看到,每个成员变量的偏移量在编译时即可获知,不管其有多么复杂的继承,都是一样的。通过对象存取一个data member,其效率和存取一个非成员变量是一样的。
函数调用
前面的例子提过,对象的总大小刚好等于所有的成员变量之和,也就意味着成员函数并不占用对象的内存大小。那成员函数的调用是怎么实现的呢?我们通过一段代码看下
type point3d struct {
X, Y, Z float32
}
func (p *point3d) Println() {
fmt.Printf("%v,%v,%v\n", p.X, p.Y, p.Z)
}
func main() {
p := point3d{X: 1, Y: 2, Z: 3} // L14
p.Println() // L15
}
同样使用 go tool获取对应的汇编代码
call.go:14 0x1094a7d 0f57c0 XORPS X0, X0
call.go:14 0x1094a80 f30f1144240c MOVSS X0, 0xc(SP)
call.go:14 0x1094a86 f30f11442410 MOVSS X0, 0x10(SP)
call.go:14 0x1094a8c f30f11442414 MOVSS X0, 0x14(SP)
call.go:14 0x1094a92 f30f100592b30400 MOVSS $f32.3f800000(SB), X0
call.go:14 0x1094a9a f30f1144240c MOVSS X0, 0xc(SP)
call.go:14 0x1094aa0 f30f100588b30400 MOVSS $f32.40000000(SB), X0
call.go:14 0x1094aa8 f30f11442410 MOVSS X0, 0x10(SP)
call.go:14 0x1094aae f30f10057eb30400 MOVSS $f32.40400000(SB), X0
call.go:14 0x1094ab6 f30f11442414 MOVSS X0, 0x14(SP)
call.go:15 0x1094abc 488d44240c LEAQ 0xc(SP), AX //将对象 q 的起始地址保存到寄存器AX
call.go:15 0x1094ac1 48890424 MOVQ AX, 0(SP) //将对象 q 的起始地址 压栈
call.go:15 0x1094ac5 e8d6fdffff CALL main.(*point3d).Println(SB) // 调用 struct point 的 Println() 函数
可以看到成员函数的调用都是先把参数压栈,然后调用对应的的函数。可见,成员函数与普通的函数调用并无不同。那么函数的内存在哪里呢?
还记得进程的内存分布么?
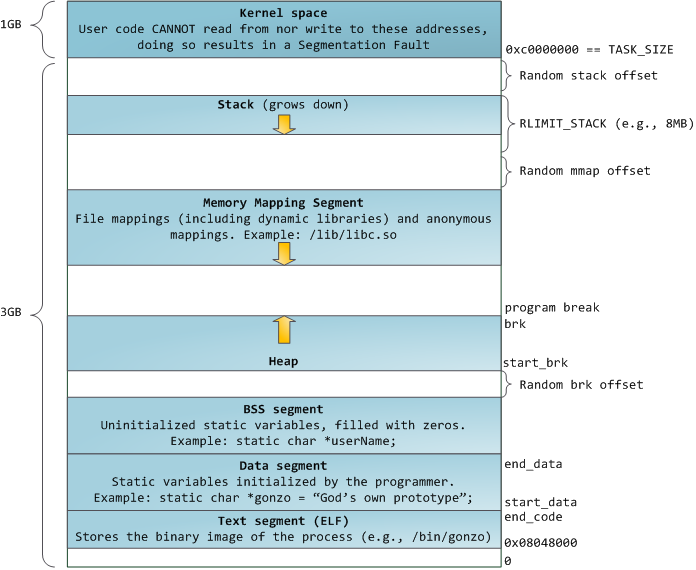
没错,所有的函数都在进程的代码段(Text Segment)
Interface 语意学
第一部分讲了,封装和继承的影响,剩下这部分会讲清楚 Go 如何使用 interface 实现多态和反射。其中interface又有两种形式,一种是有函数的非空interface,一种是空的interface(interface{})。话不多说,直接上代码,看下这两种类型的interface的变量在内存大小上有何区别:
type Point interface {
Println()
}
type point struct {
X float32
}
type point2d struct {
point
Y float32
}
type point3d struct {
point2d
Z float32
}
func TestPolymorphism(t *testing.T) {
var (
p Point
)
p = &point{X: 1}
fmt.Printf("point size:%v\n\n", unsafe.Sizeof(p))
p = &point2d{point: point{X: 1}, Y: 2}
fmt.Printf("point2d size:%v\n\n", unsafe.Sizeof(p))
p = &point3d{point2d: point2d{point: point{X: 1}, Y: 2}, Z: 3}
fmt.Printf("point3d size:%v\n\n", unsafe.Sizeof(p))
}
执行程序输出为:
$ go test -v -run TestPolymorphism
=== RUN TestPolymorphism
p size:16, nilP size:16
p size:16, nilP size:16
p size:16, nilP size:16
可以看到两种类型的interface 变量大小并无不同,均为16字节。可以明确一点:interface 变量中存储的并非对象的指针,而是特殊的定义类型的变量。那么 interface 是怎么支持多态和反射的呢?
通过 reflect 包,我们找到了答案。原来,针对以上两种类型的interface, Go 语言底层定义了两个结构分别为 iface 和 eface。两者实现是类似的,以下我们仅针对非空interface进行分析
interface 底层
type iface struct {
tab *itab // 类型信息
data unsafe.Pointer // 接口指向对象的指针
}
// 类型信息
type itab struct {
inter *interfacetype // 接口的类型信息
_type *_type // 接口指向对象的类型信息
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
fun [1]uintptr // 接口方法实现列表,即函数地址列表,按字典序排序
}
// 接口类型信息
type interfacetype struct {
typ _type
pkgpath name
mhdr []imethod // 接口方法声明列表,按字典序排序
}
通过代码,可以看到,iface 类型包含两个指针,刚好为16字节(64位机器)。iface 不但包含了指向对象、指向对象的类型,还包含了接口类型。如此
- iface 就可以在其中扮演粘结剂的角色,通过 reflect 包在对象、接口、类型之间进行转换了。
- iface 的变量可以在
编译阶段,在变量赋值处,增加拷贝指向对象(父类或者子类)的类型信息的指令,就可以在运行期完成多态的支持了
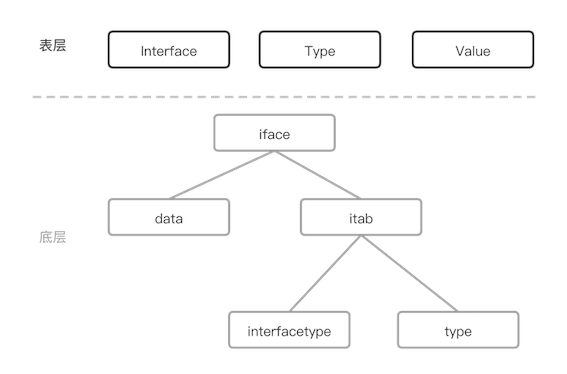
理论验证
下面我们还是通过测试代码来验证我们的理论,我们自己定义底层的相关类型,然后通过强制类型转换,来尝试解析interface变量中的数据:
type Iface struct {
Tab *Itab
Data unsafe.Pointer
}
type Itab struct {
Inter uintptr
Type uintptr
Hash uint32
_ [4]byte
Fun [1]uintptr
}
type Eface struct {
Type uintptr
Data unsafe.Pointer
}
func TestInterface(t *testing.T) {
var (
p Point
nilP interface{}
)
point := &point3d{X: 1, Y: 2, Z: 3}
nilP = point
fmt.Printf("eface size:%v\n", unsafe.Sizeof(nilP))
eface := (*face.Eface)(unsafe.Pointer(&nilP))
spew.Dump(eface.Type)
spew.Dump(eface.Data)
fmt.Printf("eface offset: eface._type = %v, eface.data = %v\n\n",
unsafe.Offsetof(eface.Type), unsafe.Offsetof(eface.Data))
p = point
fmt.Printf("point size:%v\n", unsafe.Sizeof(p))
iface := (*face.Iface)(unsafe.Pointer(&p))
spew.Dump(iface.Tab)
spew.Dump(iface.Data)
fmt.Printf("Iface offset: iface.tab = %v, iface.data = %v\n\n",
unsafe.Offsetof(iface.Tab), unsafe.Offsetof(iface.Data))
}
执行程序输出为:
$ go test -v -run TestInterface
=== RUN TestInterface
eface size:16
(uintptr) 0x111f2c0
(unsafe.Pointer) 0xc00008e250
eface offset: eface._type = 0, eface.data = 8
point size:16
(*face.Itab)(0x116ec40)({
Inter: (uintptr) 0x1122680,
Type: (uintptr) 0x111f2c0,
Hash: (uint32) 960374823,
_: ([4]uint8) (len=4 cap=4) {
00000000 00 00 00 00 |....|
},
Fun: ([1]uintptr) (len=1 cap=1) {
(uintptr) 0x10fce20
}
})
(unsafe.Pointer) 0xc00008e250
Iface offset: iface.tab = 0, iface.data = 8
下面我们再通过汇编代码看下,赋值操作做了什么?
type Point interface {
Println()
}
type point3d struct {
X, Y, Z float32
}
func (p *point3d) Println() {
fmt.Printf("%v,%v,%v\n", p.X, p.Y, p.Z)
}
func main() {
point := point3d{X: 1, Y: 2, Z: 3} // L18
var (
nilP interface{} // L20
p Point // L21
)
nilP = &point // L23
p = &point // L24
fmt.Println(nilP, p)
}
通过 go tool 查看汇编代码如下:
TEXT main.main(SB) /Users/cyningsun/Documents/go/src/github.com/cyningsun/go-test/20200102-inside-golang-object-model/main/build.go
build.go:17 0x1094de0 65488b0c2530000000 MOVQ GS:0x30, CX
build.go:17 0x1094de9 488d4424b0 LEAQ -0x50(SP), AX
build.go:17 0x1094dee 483b4110 CMPQ 0x10(CX), AX
build.go:17 0x1094df2 0f86b9010000 JBE 0x1094fb1
build.go:17 0x1094df8 4881ecd0000000 SUBQ $0xd0, SP
build.go:17 0x1094dff 4889ac24c8000000 MOVQ BP, 0xc8(SP)
build.go:17 0x1094e07 488dac24c8000000 LEAQ 0xc8(SP), BP
build.go:18 0x1094e0f 488d05ea1e0200 LEAQ type.*+137216(SB), AX // point := point3d{X: 1, Y: 2, Z: 3}
build.go:18 0x1094e16 48890424 MOVQ AX, 0(SP)
build.go:18 0x1094e1a e81160f7ff CALL runtime.newobject(SB)
build.go:18 0x1094e1f 488b442408 MOVQ 0x8(SP), AX
build.go:18 0x1094e24 4889442458 MOVQ AX, 0x58(SP)
build.go:18 0x1094e29 0f57c0 XORPS X0, X0
build.go:18 0x1094e2c f30f11442434 MOVSS X0, 0x34(SP)
build.go:18 0x1094e32 f30f11442438 MOVSS X0, 0x38(SP)
build.go:18 0x1094e38 f30f1144243c MOVSS X0, 0x3c(SP)
build.go:18 0x1094e3e f30f1005a6b80400 MOVSS $f32.3f800000(SB), X0
build.go:18 0x1094e46 f30f11442434 MOVSS X0, 0x34(SP)
build.go:18 0x1094e4c f30f100d9cb80400 MOVSS $f32.40000000(SB), X1
build.go:18 0x1094e54 f30f114c2438 MOVSS X1, 0x38(SP)
build.go:18 0x1094e5a f30f101592b80400 MOVSS $f32.40400000(SB), X2
build.go:18 0x1094e62 f30f1154243c MOVSS X2, 0x3c(SP)
build.go:18 0x1094e68 488b442458 MOVQ 0x58(SP), AX
build.go:18 0x1094e6d f30f1100 MOVSS X0, 0(AX)
build.go:18 0x1094e71 f30f114804 MOVSS X1, 0x4(AX)
build.go:18 0x1094e76 f30f115008 MOVSS X2, 0x8(AX)
build.go:20 0x1094e7b 0f57c0 XORPS X0, X0 // nilP interface{}
build.go:20 0x1094e7e 0f11442470 MOVUPS X0, 0x70(SP)// nilP 开始地址为0x70
build.go:21 0x1094e83 0f57c0 XORPS X0, X0 // p Point
build.go:21 0x1094e86 0f11442460 MOVUPS X0, 0x60(SP)
build.go:23 0x1094e8b 488b442458 MOVQ 0x58(SP), AX // nilP = &point ;0x58(SP) 为 point 的地址
build.go:23 0x1094e90 4889442448 MOVQ AX, 0x48(SP) // SP 指向 point 地址
build.go:23 0x1094e95 488d0da4860100 LEAQ type.*+98368(SB), CX // ;从内存加载 Point类型地址 到 CX 寄存器
build.go:23 0x1094e9c 48894c2470 MOVQ CX, 0x70(SP) // ;将 Point类型地址(8字节) 保存到 0x70(即eface._type)
build.go:23 0x1094ea1 4889442478 MOVQ AX, 0x78(SP) // ;将 point 对象地址(8字节) 保存到 0x78(即eface.data)
build.go:24 0x1094ea6 488b442458 MOVQ 0x58(SP), AX // p = &point
build.go:24 0x1094eab 4889442448 MOVQ AX, 0x48(SP) // ;SP 指向 point 地址
build.go:24 0x1094eb0 488d0d09d50400 LEAQ go.itab.*main.point3d,main.Point(SB), CX // ;从内存加载 Point类型 itab 地址 到 CX 寄存器
build.go:24 0x1094eb7 48894c2460 MOVQ CX, 0x60(SP) // ;将 Point类型地址(8字节) 保存到 0x70(即iface.tab)
build.go:24 0x1094ebc 4889442468 MOVQ AX, 0x68(SP) // ;将 point 对象地址(8字节) 保存到 0x78(即iface.data)
build.go:25 0x1094ec1 488b442468 MOVQ 0x68(SP), AX // fmt.Println(nilP, p)
...
事实正如理论一般,在编译阶段,赋值命令被转化为类型信息和对象指针的拷贝,保存下来执行期转换所需要的一切信息。
综述
从底层代码和汇编出发,分析 struct 和 interface 的 对象模型,理清了Go 语言高级特性的底层机制。再去学习反射等表层细节,事半功倍。
参考链接:
