

前言:
以前看过许多关于B+ Tree的文章,当时看了总觉得明白了,可是没过多久就又要忘了。直到我看了掘金小册:Mysql是怎么运行 第7,第8章才终于明白了B+ Tree到底是怎么回事。如果对Mysql内部具体如何实现感兴趣的可以去看小册,我自己看这2章,每章都花了2个小时,毕竟介绍的概念有点多。 我这篇文章相当于对这2章内容的概况总结吧,也可以当导读看,看完这个,再去看小册子可能就没那么吃力了。(ps, 这本小册子是我见过最详细介绍Mysql内部原理的系列文章。)
问题:
1.数据是怎么存储在InnoDB中的
2.如果快速找到一条记录?
3.搜索查找记录的流程是怎么样的?
4.页分裂是什么?
准备工作
没错,首先忘了什么数据结构。
在介绍Buffer Pool时提到过
InnoDB 是以 页(一般为大小为16K) 为单位,从磁盘文件中读取数据 到内存的。 一页 包含多条记录(每页至少要有2条记录)
CREATE TABLE `school` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
delimiter;;
CREATE PROCEDURE idata ( ) BEGIN
DECLARE
i INT;
SET i = 1;
WHILE
( i <= 25 ) DO
INSERT INTO school
VALUES
( i, 'school' );
SET i = i + 1;
END WHILE;
END;;
delimiter;
CALL idata ( );
现在我们创建了一张school 表格,并且插入了25条记录。
现实场景中,一页可以记录几百上千条记录。这里为了方便理解,我们假设一页只能存放5条记录。那么存放情况就如图:
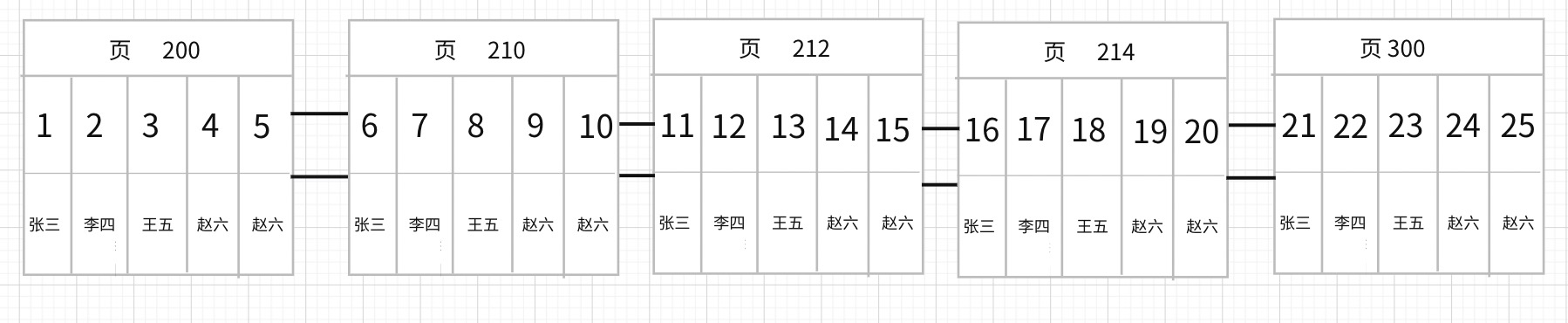
- 页与页之间是个
双向链表,这样方便范围查找。 - 页号
不一定连续 - 页中的记录是按Key进行排序的。记录之间也是
链表
知道了记录的存储情况,那么要查找某个id的记录,就变成了2个问题:
- 怎么
快速定位某个Key(这里为id) 存在在哪个页面中? - 怎么在页中快速找到对应Key 的记录?
如何快速定位页
为了快速定位,最容易想到的就是建立字典了,比如(1,200),(2,200),(6,210) 这样的确能够满足快速查找的需求,但是比较浪费空间。
所以转换一下方法:
- 我们用 key,value 的形式,key 记录每一页的
最小值,value 记录对应数据页的页号。这样形成了目录项。例如,现在我们有25条记录,每5条记录存放在1页中,那么至少有5页,所以至少有5个目录项。 目录项管理也通过页的形式进行。5条记录为1页,那么5个目录项就形成了1个目录页。目录页中的记录(即目录项)也是按照顺序排列
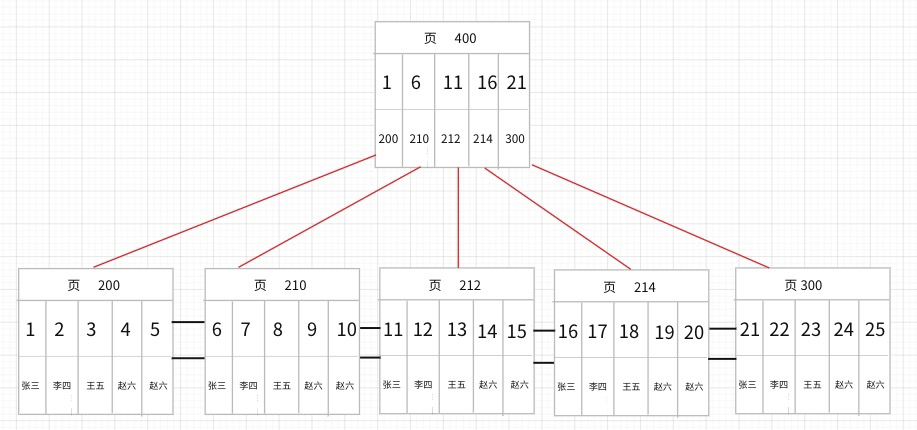
这就是最简单的一个B+Tree 了。叶子节点为数据页,存放数据。(为什么说对于聚簇索引,索引即数据?)而非叶子节点存放的是目录项。
搜索流程
select * from student where id = 14
我们要从查id = 14 的数据。那么从根节点``(这里是页400)开始查找,页400有5个记录,通过二分查找算法进行查找,因为11 < 14 < 16 所以 14记录对应的页和11记录对应的页一样。(请牢记下面2个特性: 目录项中的key 记录的是对应页中key的最小值。并且不管数据页还是目录页其中的记录都是有序的。)
那么14 对应的页就是212号页。然后再到页212号中进行二分查找找到对应数据。
页分裂
如果这个时候再插入一条数据。
insert into student values (28,'王五')
由于数据页都满了,所以必须新开一个页面来存放28这条记录。假如这个页面为310页。但同时由于目录页400页也满了,没法记录(28,310)这个目录项,所以又必须加个新的目录页例如410页来存放新的目录项。这个时候由于有2个目录页了,所以需要新建新的目录页来管理目录页,``没错,目录页中的记录不一定是指向数据页的,也可能指向目录页。
看起来会变成下面这样:(图有点丑,有好的画图软件麻烦推荐下)
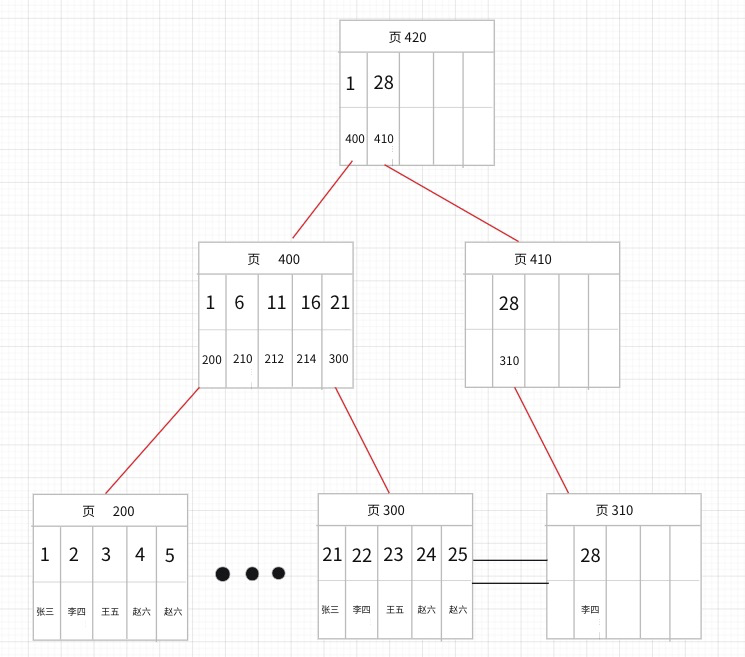
通过页分裂,B+Tree 变成了3层。根节点从页400 变成了页420。 看到这里也许你会疑惑你看过的一些文章,B+Tree 的构建并不是这样的。我想说明的是:InnoDB
构建过程跟我上面所提的过程是不同的。上面的过程是为了让大家首先了解下随着数据插入,页面(不管是数据页还是目录页)是会增加的。我做出这个流程是为了让大家知道有这么一个流程,但是具体实施,InnoDB的大神考虑的当然比我们要多,可以说是殊途同归吧,方法不同,但要达到的目的是一样的:就是现有页面存放不了新插入的数据时会进行页分裂。具体流程感情的小伙伴可以查看小册子。我介绍最重要的点:
根节点确定后是不会变的。(上面说的根节点从400 变成页420在真实数据库中是不会存在的。)真实的流程类似于:假设一开始只有5条数据都存放在页10当中,那么这个时候页10即是数据页又是根节点。这个时候又新插入一条数据,Innodb会把页10复制得到数据页20,然后对数据页20进行分裂,把数据页20中的部分数据迁移,得到数据页30,然后新插入的数据根据索引的大小插入到对应的页20或页30中。这个时候原来的页10变成了目录页,记录的目录项对应页20,和页30。但是页10还是根节点。
总结
- 数据记录按页为单位存储,每页包含多条记录。
- 为了方便从众多
数据页中找到对应的记录,设计了目录页。目录页和数据页 构成了一棵B+ Tree。 - B+ Tree 个根节点固定,会随着数据插入进行
页分裂。 - 也许通篇文章都没有提B+ Tree的数据结构到底是什么,但希望通过B+ Tree 在InnoDB 中现实场景应用,让你对B+ Tree 的作用,以及B+ Tree 中叶子节点和非叶子节点到底是什么有个具体的概念。好好理解下文中的搜索过程,和插入流程。再回过头去瞧那些介绍B+Tree的数据结构的文章相信你会更容易懂。任何数据结构都是为某些场景服务而存在的,
了解应用场景后再去看具体实现更容易懂而且印象深刻。
